TOPS: First-Principles Visual Token Pruning via Constructing Token Optimal Preservation Sets for Efficient MLLM Inference
Pith reviewed 2026-06-26 04:21 UTC · model grok-4.3
The pith
A new method prunes 77.8 percent of visual tokens from MLLMs by constructing optimal preservation sets that satisfy task relevance, information coverage, and semantic diversity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
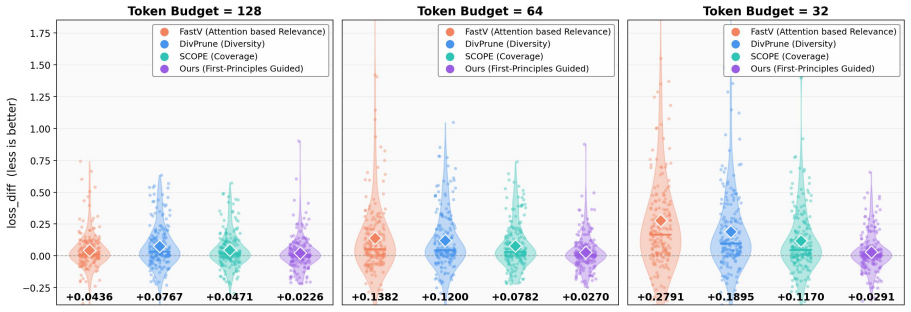
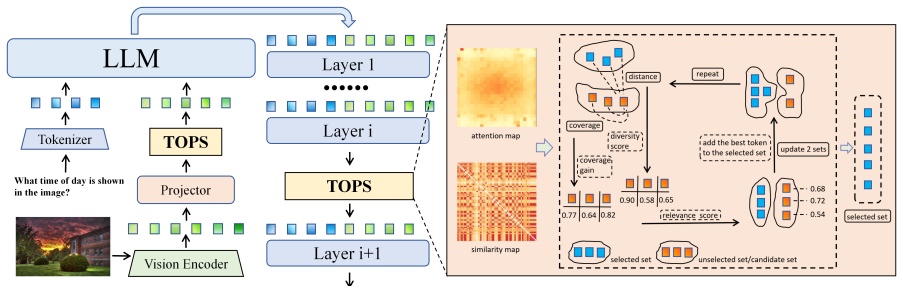
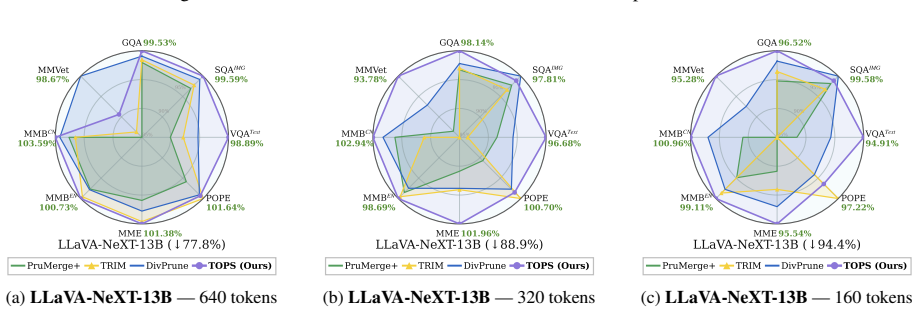
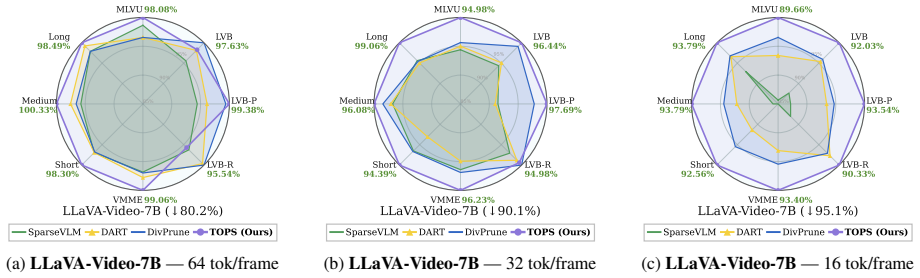
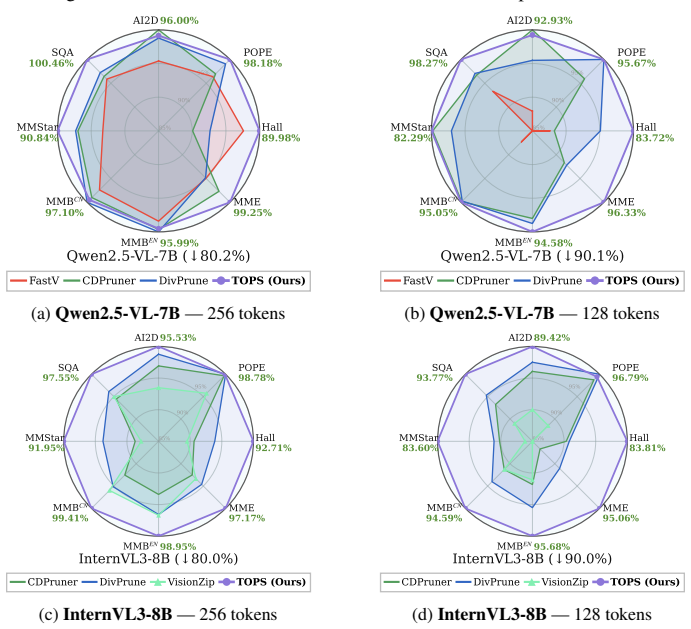
The paper claims that effective visual token pruning requires constructing Token Optimal Preservation Sets whose selection is governed by three principles identified through information-theoretic analysis: Task Relevance to the user instruction, Information Coverage of the scene, and Semantic Diversity among kept tokens. This formulation produces the TOPS pruning module, which is training-free and model-agnostic, and which removes 77.8 percent of visual tokens on LLaVA-NeXT while retaining 100.0 percent and 100.6 percent of original performance on the 7B and 13B variants across fourteen benchmarks.
What carries the argument
Token Optimal Preservation Sets, collections of visual tokens chosen to jointly maximize task relevance, information coverage, and semantic diversity, which serve as the explicit objective that replaces ad-hoc attention or diversity heuristics.
If this is right
- On LLaVA-NeXT the method removes 77.8 percent of visual tokens while preserving full or slightly higher performance on both 7B and 13B sizes.
- The same pruning module improves results over prior attention-based and diversity-based baselines on seven different MLLM backbones.
- Performance is maintained or improved across fourteen separate multimodal benchmarks.
- In some settings the removal of redundant tokens also reduces hallucination.
Where Pith is reading between the lines
- Redundant visual tokens may be a source of hallucination, so systematic removal could improve reliability as a side effect.
- Future MLLM designs could embed such selection logic at the architecture level to produce smaller models from the start.
- The three selection principles could be tested on token pruning for other modalities such as audio or video.
Load-bearing premise
The top-down information-theoretic analysis has correctly isolated task relevance, information coverage, and semantic diversity as the three fundamental principles that define the intrinsic goal of token pruning.
What would settle it
If a method using only attention scores or only diversity metrics retains the same or higher task accuracy after removing 77.8 percent of tokens on the LLaVA-NeXT 7B and 13B models, the claim that the three-principle formulation is necessary would be falsified.
Figures


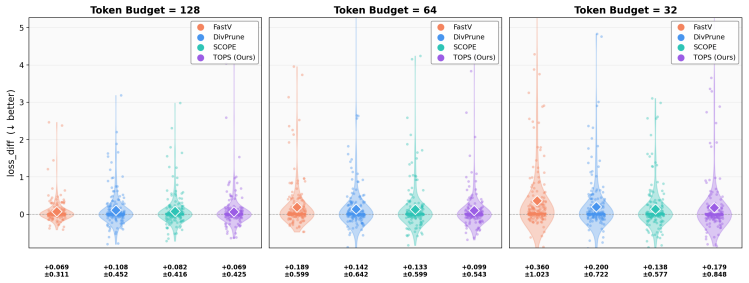
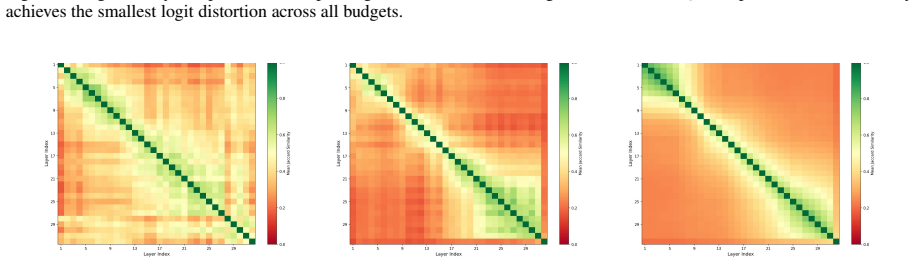
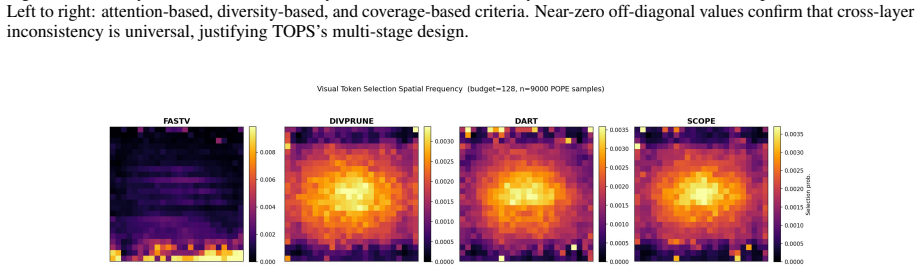
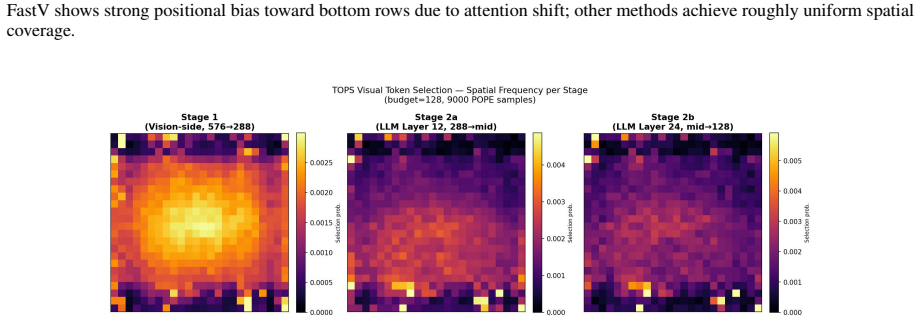





read the original abstract
Multimodal large language models (MLLMs) have achieved strong multimodal reasoning capabilities, but their efficiency is limited by the large number of visual tokens, which introduces substantial computational overhead. Visual token pruning offers a natural solution, yet existing methods are imperfect: attention-based criteria tend to retain redundant tokens, while diversity-based criteria are often agnostic to user instructions. Even methods that combine multiple criteria still lack a principled formulation of the intrinsic objective of token pruning. In this paper, we revisit visual token pruning from a first-principles perspective and formulate it as constructing Token Optimal Preservation Sets. Through a top-down information-theoretic analysis, we identify three fundamental principles for effective token selection: Task Relevance, Information Coverage, and Semantic Diversity. Based on these principles, we propose TOPS, a training-free and model-agnostic pruning module that can be applied to various MLLMs. Extensive experiments on 7 MLLM backbones and 14 benchmarks demonstrate that TOPS outperforms prior methods under diverse pruning settings. Notably, on LLaVA-NeXT, TOPS removes 77.8% of visual tokens while preserving 100.0% and 100.6% performance on its 7B and 13B models, respectively, suggesting that pruning redundant visual tokens can sometimes mitigate hallucination and inspire future lightweight MLLM design.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes TOPS, a training-free and model-agnostic visual token pruning module for MLLMs. It formulates pruning as the construction of Token Optimal Preservation Sets and derives three principles (Task Relevance, Information Coverage, Semantic Diversity) via top-down information-theoretic analysis. Experiments across 7 backbones and 14 benchmarks show TOPS outperforms prior methods; notably, on LLaVA-NeXT it prunes 77.8% of visual tokens while retaining 100.0% (7B) and 100.6% (13B) performance.
Significance. If the empirical results hold, the work supplies a principled, parameter-free pruning approach that is broadly applicable and avoids the need for task-specific retraining. The reported ability to maintain (or slightly exceed) accuracy at high pruning ratios, together with the model-agnostic design, would be a useful contribution to efficient MLLM inference and could inform future lightweight architectures.
major comments (1)
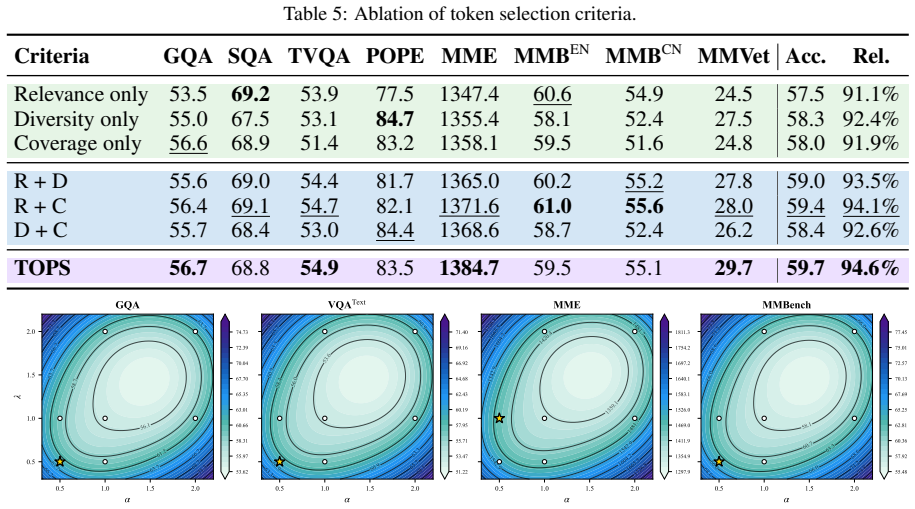
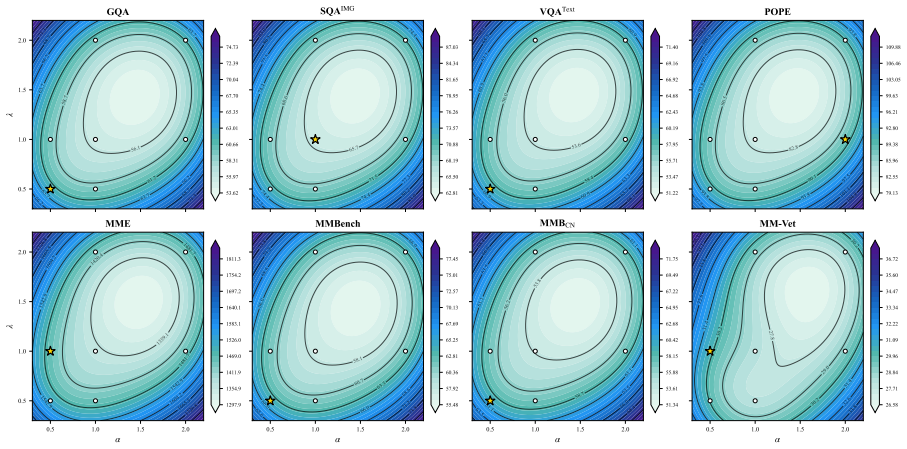
- [top-down information-theoretic analysis] The section presenting the top-down information-theoretic analysis: the claim that Task Relevance, Information Coverage, and Semantic Diversity are the three fundamental principles that define the intrinsic objective of token pruning would be strengthened by a concrete test (e.g., an ablation demonstrating that any proper subset of the three principles yields measurably inferior preservation sets on the reported benchmarks). Without such a test the selection of exactly these three criteria remains an assumption whose correctness risk affects the claimed first-principles status of the method.
Simulated Author's Rebuttal
We thank the referee for the constructive comment on the top-down analysis and for the overall positive evaluation. We address the point below.
read point-by-point responses
-
Referee: The section presenting the top-down information-theoretic analysis: the claim that Task Relevance, Information Coverage, and Semantic Diversity are the three fundamental principles that define the intrinsic objective of token pruning would be strengthened by a concrete test (e.g., an ablation demonstrating that any proper subset of the three principles yields measurably inferior preservation sets on the reported benchmarks). Without such a test the selection of exactly these three criteria remains an assumption whose correctness risk affects the claimed first-principles status of the method.
Authors: We agree that an explicit ablation would strengthen the empirical grounding of the claim. The three principles were obtained deductively by decomposing the information-theoretic objective of constructing a Token Optimal Preservation Set: Task Relevance follows from conditioning on the user query, Information Coverage from maximizing mutual information with the input, and Semantic Diversity from minimizing conditional redundancy among selected tokens. Existing attention-based and diversity-based methods can be viewed as incomplete subsets of this objective, which is consistent with their comparatively weaker results in our experiments. Nevertheless, to directly respond to the concern we will add, in the revised manuscript, an ablation that evaluates preservation sets formed from all proper subsets of the three principles on the LLaVA-NeXT and other reported benchmarks. revision: yes
Circularity Check
No significant circularity
full rationale
The paper derives its three principles (Task Relevance, Information Coverage, Semantic Diversity) via an explicit top-down information-theoretic analysis framed as first-principles reasoning, then builds the TOPS module directly from those principles. No equations or steps reduce a claimed prediction or uniqueness result to a fitted parameter or prior self-citation by construction. The approach is described as training-free and model-agnostic, with performance claims resting on external benchmarks across 7 backbones rather than internal redefinitions. This is the normal case of a self-contained derivation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The intrinsic objective of visual token pruning can be captured by the three principles of Task Relevance, Information Coverage, and Semantic Diversity derived from information-theoretic analysis.
invented entities (1)
-
Token Optimal Preservation Sets
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Advances in neural information processing systems , volume=
Visual instruction tuning , author=. Advances in neural information processing systems , volume=
-
[2]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
A convnet for the 2020s , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[3]
IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
Mini-gemini: Mining the potential of multi-modality vision language models , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
-
[4]
Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Glm: General language model pretraining with autoregressive blank infilling , author=. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[5]
MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models
Minigpt-4: Enhancing vision-language understanding with advanced large language models , author=. arXiv preprint arXiv:2304.10592 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Proceedings of the 2024 conference on empirical methods in natural language processing , pages=
Video-llava: Learning united visual representation by alignment before projection , author=. Proceedings of the 2024 conference on empirical methods in natural language processing , pages=
2024
-
[7]
Qwen technical report , author=. arXiv preprint arXiv:2309.16609 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Gemini: A Family of Highly Capable Multimodal Models
Gemini: a family of highly capable multimodal models , author=. arXiv preprint arXiv:2312.11805 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Improved baselines with visual instruction tuning , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[10]
LLaVA-OneVision: Easy Visual Task Transfer
Llava-onevision: Easy visual task transfer , author=. arXiv preprint arXiv:2408.03326 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Qwen2.5-VL Technical Report , author=. arXiv preprint arXiv:2502.13923 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Expanding performance boundaries of open-source multimodal models with model, data, and test-time scaling , author=. arXiv preprint arXiv:2412.05271 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
European Conference on Computer Vision , pages=
Sharegpt4v: Improving large multi-modal models with better captions , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[14]
Advances in Neural Information Processing Systems , volume=
Cogvlm: Visual expert for pretrained language models , author=. Advances in Neural Information Processing Systems , volume=
-
[15]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Qwen-vl: A frontier large vision-language model with versatile abilities , author=. arXiv preprint arXiv:2308.12966 , volume=
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[17]
mPLUG-Owl: Modularization Empowers Large Language Models with Multimodality
mplug-owl: Modularization empowers large language models with multimodality , author=. arXiv preprint arXiv:2304.14178 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Science China Information Sciences , volume=
How far are we to gpt-4v? closing the gap to commercial multimodal models with open-source suites , author=. Science China Information Sciences , volume=. 2024 , publisher=
2024
-
[19]
International conference on machine learning , pages=
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models , author=. International conference on machine learning , pages=. 2023 , organization=
2023
-
[20]
Gpt-4o system card , author=. arXiv preprint arXiv:2410.21276 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context , author=. arXiv preprint arXiv:2403.05530 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
OpenAI blog , volume=
Language models are unsupervised multitask learners , author=. OpenAI blog , volume=
-
[23]
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
DeepSeek LLM: Scaling Open-Source Language Models with Longtermism
Deepseek llm: Scaling open-source language models with longtermism , author=. arXiv preprint arXiv:2401.02954 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
LLaMA: Open and Efficient Foundation Language Models
Llama: Open and efficient foundation language models , author=. arXiv preprint arXiv:2302.13971 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Llama 2: Open foundation and fine-tuned chat models , author=. arXiv preprint arXiv:2307.09288 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Internlm2 technical report , author=. arXiv preprint arXiv:2403.17297 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
Instruction tuning with gpt-4 , author=. arXiv preprint arXiv:2304.03277 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
Advances in neural information processing systems , volume=
Language models are few-shot learners , author=. Advances in neural information processing systems , volume=
-
[30]
International conference on machine learning , pages=
Learning transferable visual models from natural language supervision , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[31]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Beyond text-visual attention: Exploiting visual cues for effective token pruning in vlms , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[32]
SparseVLM+: Visual Token Sparsification with Improved Text-Visual Attention Pattern , author=
-
[33]
VideoPoet: A Large Language Model for Zero-Shot Video Generation
Videopoet: A large language model for zero-shot video generation , author=. arXiv preprint arXiv:2312.14125 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
Proceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining , pages=
Deepspeed: System optimizations enable training deep learning models with over 100 billion parameters , author=. Proceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining , pages=
-
[35]
arXiv preprint arXiv:2503.11549 (2025)
Similarity-aware token pruning: Your vlm but faster , author=. arXiv preprint arXiv:2503.11549 , year=
-
[36]
Token Merging: Your ViT But Faster
Token merging: Your vit but faster , author=. arXiv preprint arXiv:2210.09461 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Aim: Adaptive inference of multi-modal llms via token merging and pruning , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[38]
, author=
Lora: Low-rank adaptation of large language models. , author=. Iclr , volume=
-
[39]
Advances in neural information processing systems , volume=
Qlora: Efficient finetuning of quantized llms , author=. Advances in neural information processing systems , volume=
-
[40]
Llavanext: Improved reasoning, ocr, and world knowledge , author=
-
[41]
LLaVA-Video: Video Instruction Tuning With Synthetic Data
Llava-video: Video instruction tuning with synthetic data , author=. arXiv preprint arXiv:2410.02713 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[42]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models , author=. arXiv preprint arXiv:2504.10479 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
European Conference on Computer Vision , pages=
An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision-language models , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[44]
PyramidDrop: Accelerating Your Large Vision-Language Models via Pyramid Visual Redundancy Reduction
Pyramiddrop: Accelerating your large vision-language models via pyramid visual redundancy reduction , author=. arXiv preprint arXiv:2410.17247 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[45]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Divprune: Diversity-based visual token pruning for large multimodal models , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[46]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Stop Looking for Important Tokens in Multimodal Language Models: Duplication Matters More , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[47]
Proceedings of the 31st International Conference on Computational Linguistics , pages=
Less is more: A simple yet effective token reduction method for efficient multi-modal llms , author=. Proceedings of the 31st International Conference on Computational Linguistics , pages=
-
[48]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Llava-prumerge: Adaptive token reduction for efficient large multimodal models , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[49]
arXiv preprint arXiv:2510.24214 , year=
SCOPE: Saliency-Coverage Oriented Token Pruning for Efficient Multimodel LLMs , author=. arXiv preprint arXiv:2510.24214 , year=
-
[50]
SparseVLM: Visual Token Sparsification for Efficient Vision-Language Model Inference
Sparsevlm: Visual token sparsification for efficient vision-language model inference , author=. arXiv preprint arXiv:2410.04417 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[51]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Visionzip: Longer is better but not necessary in vision language models , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[52]
arXiv preprint arXiv:2411.10803 , year=
Multi-stage vision token dropping: Towards efficient multimodal large language model , author=. arXiv preprint arXiv:2411.10803 , year=
-
[53]
Visual Intelligence , volume=
Efficient multimodal large language models: A survey , author=. Visual Intelligence , volume=. 2025 , publisher=
2025
-
[54]
arXiv preprint arXiv:2603.01236 , year=
AgilePruner: An empirical study of attention and diversity for adaptive visual token pruning in large vision-language models , author=. arXiv preprint arXiv:2603.01236 , year=
-
[55]
arXiv e-prints , pages=
Towards adaptive visual token pruning for large multimodal models , author=. arXiv e-prints , pages=
-
[56]
arXiv preprint arXiv:2602.13315 , year=
IDPruner: Harmonizing Importance and Diversity in Visual Token Pruning for MLLMs , author=. arXiv preprint arXiv:2602.13315 , year=
-
[57]
arXiv preprint arXiv:2602.17196 (2026)
EntropyPrune: Matrix Entropy Guided Visual Token Pruning for Multimodal Large Language Models , author=. arXiv preprint arXiv:2602.17196 , year=
-
[58]
arXiv preprint arXiv:2506.10967 (2025)
Beyond attention or similarity: Maximizing conditional diversity for token pruning in mllms , author=. arXiv preprint arXiv:2506.10967 , year=
-
[59]
arXiv preprint arXiv:2505.22654 , year=
Vscan: Rethinking visual token reduction for efficient large vision-language models , author=. arXiv preprint arXiv:2505.22654 , year=
-
[60]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Gqa: A new dataset for real-world visual reasoning and compositional question answering , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[61]
Advances in neural information processing systems , volume=
Learn to explain: Multimodal reasoning via thought chains for science question answering , author=. Advances in neural information processing systems , volume=
-
[62]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Towards vqa models that can read , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[63]
Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
Evaluating object hallucination in large vision-language models , author=. Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
2023
-
[64]
MME: A Comprehensive Evaluation Benchmark for Multimodal Large Language Models
Mme: A comprehensive evaluation benchmark for multimodal large language models , author=. arXiv preprint arXiv:2306.13394 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[65]
European conference on computer vision , pages=
Mmbench: Is your multi-modal model an all-around player? , author=. European conference on computer vision , pages=. 2024 , organization=
2024
-
[66]
MM-Vet: Evaluating Large Multimodal Models for Integrated Capabilities
Mm-vet: Evaluating large multimodal models for integrated capabilities , author=. arXiv preprint arXiv:2308.02490 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[67]
Advances in Neural Information Processing Systems , volume=
Are we on the right way for evaluating large vision-language models? , author=. Advances in Neural Information Processing Systems , volume=
-
[68]
European conference on computer vision , pages=
A diagram is worth a dozen images , author=. European conference on computer vision , pages=. 2016 , organization=
2016
-
[69]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Hallusionbench: an advanced diagnostic suite for entangled language hallucination and visual illusion in large vision-language models , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[70]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[71]
Advances in Neural Information Processing Systems , volume=
Longvideobench: A benchmark for long-context interleaved video-language understanding , author=. Advances in Neural Information Processing Systems , volume=
-
[72]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Mlvu: Benchmarking multi-task long video understanding , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[73]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Fastdrivevla: Efficient end-to-end driving via plug-and-play reconstruction-based token pruning , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[74]
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[75]
Openai gpt-5 system card , author=. arXiv preprint arXiv:2601.03267 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[76]
Qwen3. 5-omni technical report , author=. arXiv preprint arXiv:2604.15804 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[77]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[78]
Kimi-vl technical report , author=. arXiv preprint arXiv:2504.07491 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[79]
Kimi K2.5: Visual Agentic Intelligence
Kimi K2. 5: Visual Agentic Intelligence , author=. arXiv preprint arXiv:2602.02276 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[80]
Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities , author=. arXiv preprint arXiv:2507.06261 , year=
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.