When Does Personality Composition Matter for Multi-Agent LLM Teams?
Pith reviewed 2026-06-29 02:17 UTC · model grok-4.3
The pith
Personality effects on multi-agent LLM team performance depend on task structure rather than communication style alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
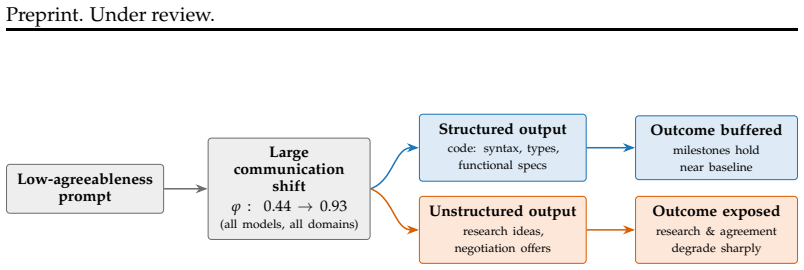
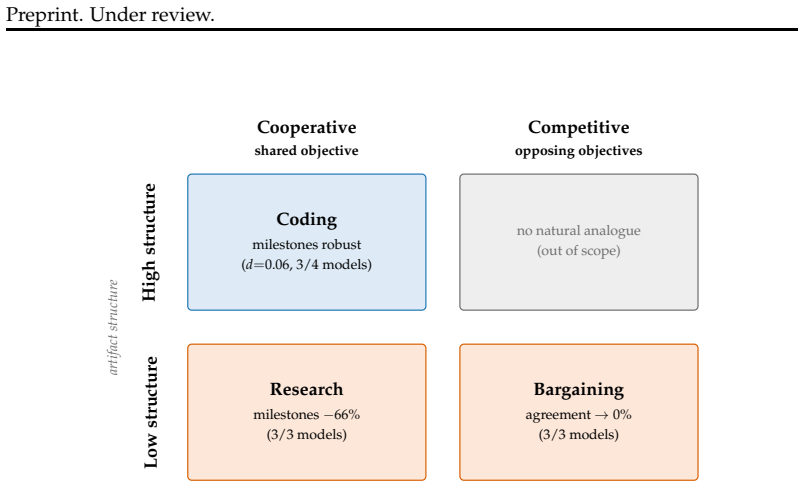
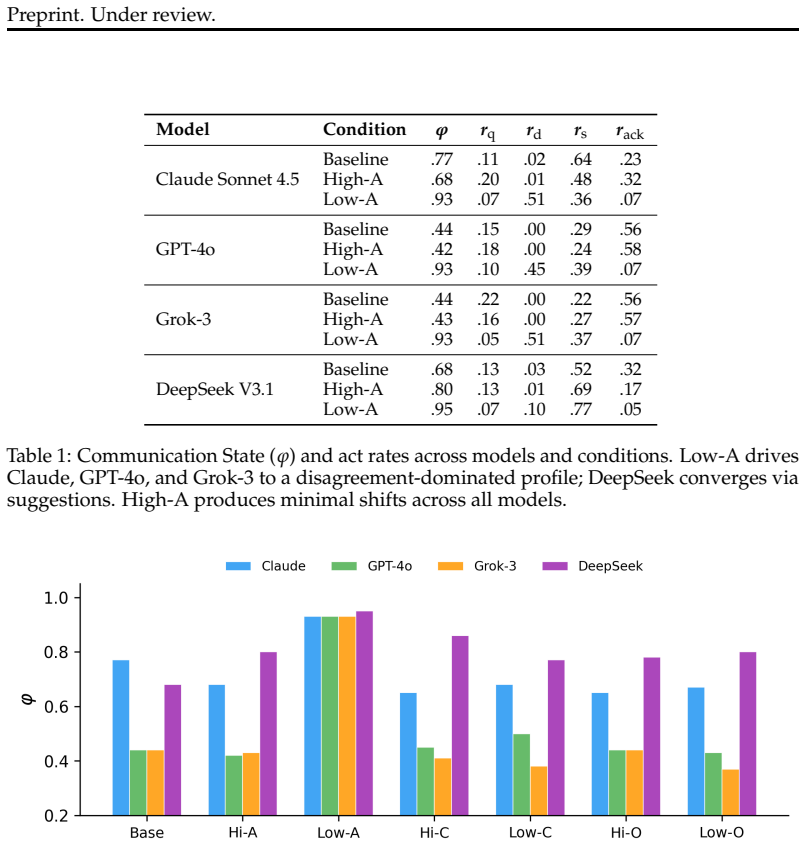
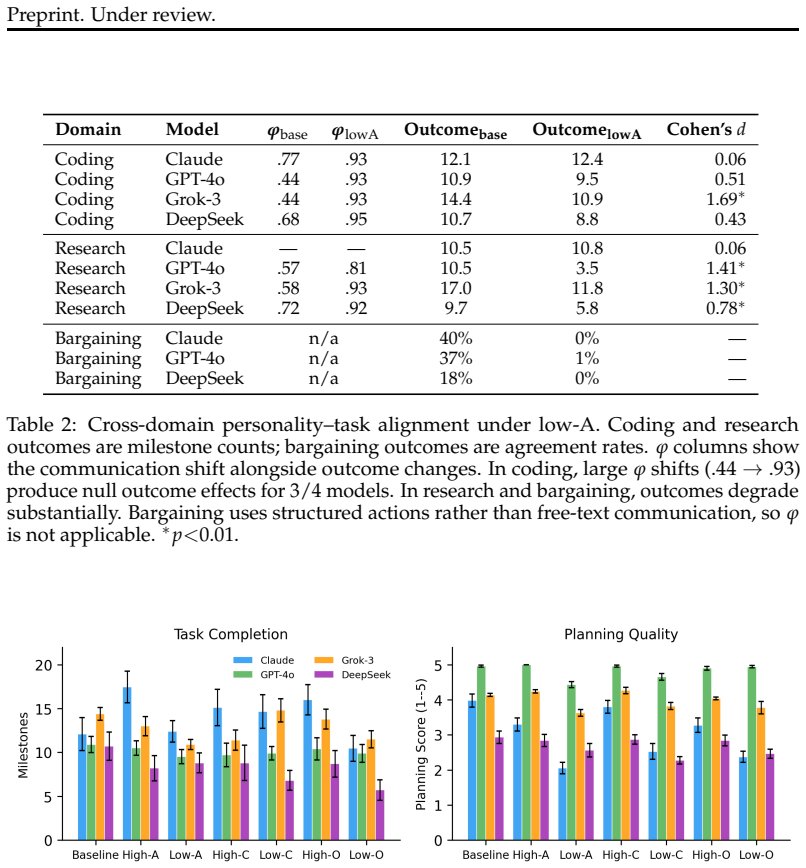
We find that personality effects depend critically on task structure. In coding tasks, low agreeableness leads to large communication shifts that have little effect on milestone completion. In open-ended collaboration and bargaining, the same manipulation substantially degrades performance. We discuss implications for multi-agent system design and the limits of personality manipulation.
What carries the argument
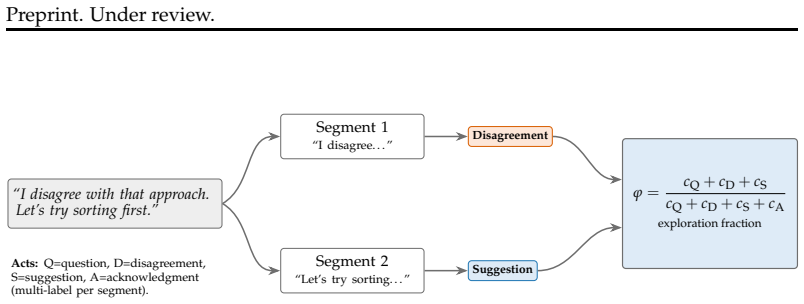
Manipulation of personality traits such as agreeableness through prompting, tested for its impact on team outcomes across structured coding, open-ended collaboration, and competitive bargaining tasks.
If this is right
- Communication style changes from personality prompts do not affect milestone completion in structured coding tasks.
- The same personality changes degrade performance in open-ended collaboration and bargaining.
- Task structure determines whether personality composition influences multi-agent outcomes.
- Design of multi-agent LLM systems should factor in task type before applying personality prompts.
Where Pith is reading between the lines
- Personality prompting may require supplementary controls to influence performance in highly structured domains like coding.
- The pattern could be tested on other task types such as creative generation or long-horizon planning where structure varies.
- Larger teams or different base models might reveal whether the task-structure dependence holds beyond the tested setups.
Load-bearing premise
The personality prompts produce consistent, measurable behavioral changes that drive any observed differences in performance.
What would settle it
Repeating the experiments on the same tasks but with new frontier models and finding no performance drop in bargaining despite identical low-agreeableness prompts.
Figures
read the original abstract
Personality prompting shapes how large language models communicate, yet whether these behavioral shifts affect objective task outcomes remains under-explored. Prior work shows that agents prompted with low agreeableness produce adversarial language, while those prompted with high agreeableness become cooperative, but the relationship between communication style and task performance has not been systematically examined across multiple domains. In this work, we investigate whether personality composition matters for multi-agent team performance by manipulating personality traits across frontier LLMs on three task domains: structured coding, open-ended research collaboration, and competitive bargaining. We find that personality effects depend critically on task structure. In coding tasks, low agreeableness leads to large communication shifts that have little effect on milestone completion. In open-ended collaboration and bargaining, the same manipulation substantially degrades performance. We discuss implications for multi-agent system design and the limits of personality manipulation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that personality composition in multi-agent LLM teams affects objective task performance in a task-structure-dependent manner. Across frontier LLMs, low-agreeableness prompting produces adversarial communication that has negligible impact on milestone completion in structured coding tasks but substantially degrades outcomes in open-ended research collaboration and competitive bargaining.
Significance. If the reported task-dependent effects hold after proper controls, the result would be useful for multi-agent system design by clarifying when personality prompting is likely to be consequential versus inert. The work is an empirical comparison with no parameter-free derivations or machine-checked proofs.
major comments (2)
- [Abstract / Methods (not detailed)] The central causal claim—that observed performance differences are driven by personality-induced behavioral changes rather than prompt length, token distribution, or other uncontrolled factors—requires independent validation of the manipulation (e.g., blinded message coding, lexical metrics, or ablation that removes personality language while holding other prompt elements fixed). No such validation is described in the abstract or indicated in the provided manuscript text.
- [Abstract] The abstract reports large communication shifts in coding with little performance impact versus degradation elsewhere, yet provides no statistical details, controls for model-specific quirks in multi-agent loops, or task-framing ablations. This leaves open whether the task-structure dependence is robust or confounded.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for stronger validation of the personality manipulation and for greater statistical transparency in the abstract. We address each comment below and will revise the manuscript to incorporate the suggested improvements where feasible.
read point-by-point responses
-
Referee: [Abstract / Methods (not detailed)] The central causal claim—that observed performance differences are driven by personality-induced behavioral changes rather than prompt length, token distribution, or other uncontrolled factors—requires independent validation of the manipulation (e.g., blinded message coding, lexical metrics, or ablation that removes personality language while holding other prompt elements fixed). No such validation is described in the abstract or indicated in the provided manuscript text.
Authors: We agree that explicit validation of the manipulation is important for causal claims. The manuscript follows standard personality-prompting protocols from prior LLM studies but does not report independent checks such as blinded coding or targeted ablations. In revision we will add a dedicated manipulation-check subsection that includes (1) lexical metrics comparing adversarial language across conditions and (2) an ablation that removes personality descriptors while preserving prompt length and structure. These additions will be placed in the Methods section and referenced from the abstract. revision: yes
-
Referee: [Abstract] The abstract reports large communication shifts in coding with little performance impact versus degradation elsewhere, yet provides no statistical details, controls for model-specific quirks in multi-agent loops, or task-framing ablations. This leaves open whether the task-structure dependence is robust or confounded.
Authors: The full manuscript already contains statistical tests (significance levels, effect sizes) and uses multiple frontier models with fixed random seeds to mitigate model-specific quirks. The abstract, however, is intentionally concise and omits these details. We will revise the abstract to include a brief statement of the key statistical results and will add a short paragraph on multi-model controls. Task-framing ablations are partially addressed by the three deliberately contrasting task domains; a full factorial ablation of framing is beyond the current scope but will be noted as a limitation and direction for future work. revision: partial
Circularity Check
No circularity: empirical comparison with no derivation chain
full rationale
The paper is an empirical study comparing multi-agent LLM performance under personality prompt manipulations across coding, collaboration, and bargaining tasks. No equations, first-principles derivations, fitted parameters, or predictions are claimed that could reduce to inputs by construction. The abstract and provided text describe experimental manipulations and observed outcomes without any self-referential fitting or renaming of results. This matches the default expectation for non-circular empirical work; the central claims rest on task outcomes rather than any load-bearing self-citation or definitional loop.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Accessed: 2026-03-
URL https: //www.anthropic.com/engineering/building-effective-agents/. Accessed: 2026-03-
2026
-
[2]
Constitutional AI: Harmlessness from AI Feedback
URL https://www.anthropic. com/news/claude-sonnet-4-5. Accessed: 2026-03-29. Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, et al. Constitu- tional ai: Harmlessness from ai feedback.arXiv preprint arXiv:2212.08073,
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evalu- ating large language models trained on code.arXiv preprint arXiv:2107.03374,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Yifan Duan, Yihong Tang, Xuefeng Bai, Kehai Chen, Juntao Li, and Min Zhang. The power of personality: A human simulation perspective to investigate large language model agents.arXiv preprint arXiv:2502.20859,
-
[5]
How personality traits influence negotiation outcomes? a simulation based on large language models
Yin Jou Huang and Rafik Hadfi. How personality traits influence negotiation outcomes? a simulation based on large language models. InFindings of the Association for Computational Linguistics: EMNLP 2024, pp. 10336–10351,
2024
-
[6]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. Swe-bench: Can language models resolve real-world github issues? arXiv preprint arXiv:2310.06770,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Accessed: 2026-03-26
URL https://newsletter.pragmaticengineer.com/p/ ai-tooling-2026. Accessed: 2026-03-26. Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in neural information processing systems, 3...
2026
-
[10]
Keyu Pan and Yawen Zeng. Do llms possess a personality? making the mbti test an amazing evaluation for large language models.arXiv preprint arXiv:2307.16180,
-
[11]
Collab-overcooked: Benchmarking and evaluating large lan- guage models as collaborative agents
Haochen Sun, Shuwen Zhang, Lujie Niu, Lei Ren, Hao Xu, Hao Fu, Fangkun Zhao, Caixia Yuan, and Xiaojie Wang. Collab-overcooked: Benchmarking and evaluating large lan- guage models as collaborative agents. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp. 4922–4951,
2025
-
[12]
Sixiong Xie, Zhuofan Shi, Haiyang Shen, Gang Huang, Yun Ma, and Xiang Jing
Accessed: 2025-03-29. Sixiong Xie, Zhuofan Shi, Haiyang Shen, Gang Huang, Yun Ma, and Xiang Jing. M3-bench: Process-aware evaluation of llm agents social behaviors in mixed-motive games.arXiv preprint arXiv:2601.08462,
-
[13]
https://arxiv.org/abs/2409.20296
Thomas P Zollo, Andrew Wei Tung Siah, Naimeng Ye, Ang Li, and Hongseok Namkoong. Personalllm: Tailoring llms to individual preferences.arXiv preprint arXiv:2409.20296,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.