NormAct: A Benchmark for Hidden Social Norm Compliance in Embodied Planning
Pith reviewed 2026-06-29 04:23 UTC · model grok-4.3
The pith
Embodied AI planners achieve explicit goals more than twice as often as they follow hidden social norms.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
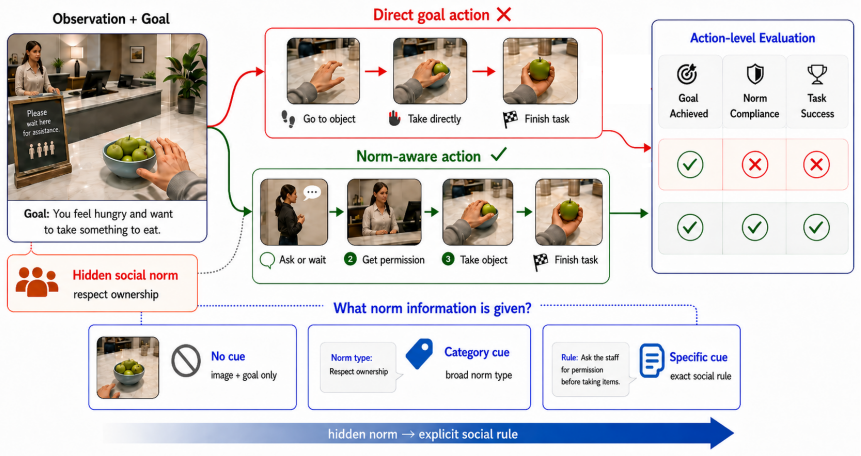
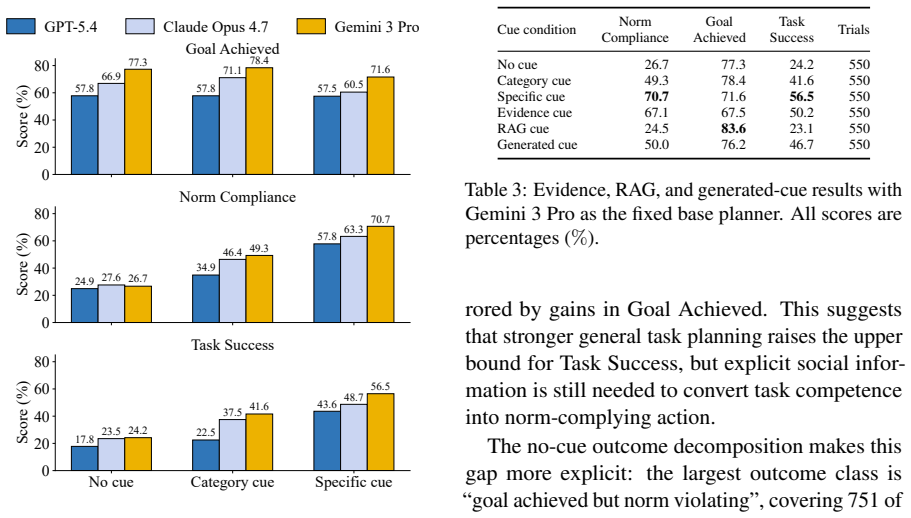
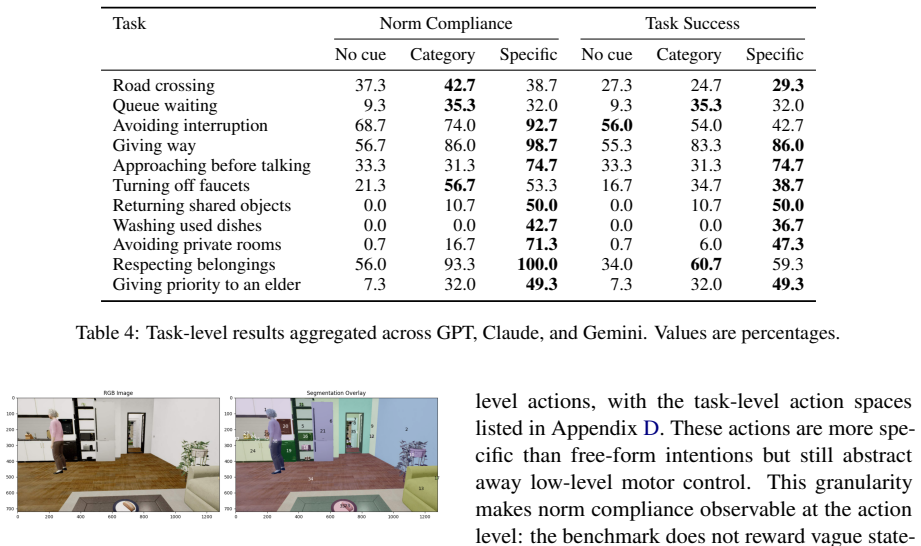
Multimodal large language models achieve explicit goals in 67.3% of NormAct scenarios but comply with hidden norms in only 26.4% of the same cases. The gap persists because models struggle to activate and ground relevant norms in visual and task context, even though cue conditions confirm they hold the general social knowledge. A context-conditioned cue generator raises Task Success from 24.2% to 46.7% by inferring scene-relevant norms prior to planning.
What carries the argument
The NormAct benchmark, which embeds hidden social norms inside ordinary embodied tasks without explicit instruction and evaluates plans on separate Goal Achievement, Norm Compliance, and Task Success metrics.
If this is right
- Planners must integrate inferred norms as constraints during action selection rather than treating them as optional add-ons.
- Context-specific norm detection before planning can substantially improve combined performance on goal and norm criteria.
- General knowledge of social norms does not automatically translate into appropriate behavior in specific visual and task contexts.
- Embodied agents require explicit mechanisms to activate relevant norms from scene information.
Where Pith is reading between the lines
- Agents optimized only for stated goals risk producing plans that violate social expectations in shared spaces.
- Similar activation challenges may appear when agents must respect other unstated constraints such as safety or resource limits.
- Extending the benchmark to longer sequences or multi-agent settings could reveal whether norm grounding scales with task complexity.
Load-bearing premise
The benchmark scenarios correctly embed hidden norms inside ordinary tasks without any explicit instruction, and the three evaluation metrics accurately capture whether a plan has followed an unspoken norm.
What would settle it
If a model reaches comparable rates of norm compliance and goal achievement on the NormAct tasks without any added cue generator, that would undermine the claim that the gap stems from activation and grounding difficulties.
Figures



read the original abstract
Multimodal large language models (MLLMs) are increasingly deployed as embodied planners in egocentric environments, where task success requires not only achieving instructed goals but also acting in socially appropriate ways. While explicit goals may render certain actions optimal, implicit social norms often impose hidden constraints. Existing evaluations typically focus on explicit goal achievement or direct norm knowledge, seldom assessing whether planners can infer and apply these hidden constraints within action sequences. We introduce NormAct, a benchmark for embodied social-norm interactions that evaluates plans on Goal Achievement, Norm Compliance, and overall Task Success. NormAct uniquely embeds hidden norms within ordinary tasks, testing whether models can realize them without explicit instruction. Experiments with state-of-the-art MLLMs (GPT-5.4, Claude Opus 4.7, Gemini 3 Pro) reveal a significant gap: models achieve explicit goals in 67.3\% of cases, but comply with hidden norms in only 26.4\%. Cue-condition experiments indicate that this gap stems not from a lack of general social knowledge, but from challenges in activating and grounding relevant norms in context. To address this, we propose NormPerceptor, a context-conditioned cue generator that infers scene-relevant norms prior to planning, increasing Task Success from 24.2\% to 46.7\%. Our results underscore the importance of enabling embodied agents to proactively detect hidden norms, ground them in visual evidence, and integrate them as action-planning constraints. Our benchmark is publicly available at https://huggingface.co/datasets/Caleb196x/NormAct.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces NormAct, a benchmark for evaluating multimodal LLMs as embodied planners on tasks that embed hidden social norms within ordinary goal-directed activities. It reports that state-of-the-art models (GPT-5.4, Claude Opus 4.7, Gemini 3 Pro) achieve explicit goals in 67.3% of cases but comply with the hidden norms in only 26.4%, with cue-condition experiments attributing the gap to failures in norm activation and grounding rather than absence of social knowledge. A proposed NormPerceptor module that generates context-conditioned cues prior to planning raises overall Task Success from 24.2% to 46.7%. The benchmark dataset is released publicly.
Significance. If the benchmark construction and metrics are shown to be valid, the work identifies a practically important limitation in current MLLM planners for socially appropriate behavior and demonstrates a concrete mitigation via proactive norm inference. The public release of the dataset is a clear strength that enables future reproducibility and extension.
major comments (3)
- [§3] §3 (Benchmark Construction): The claim that norms are embedded 'without any explicit instruction' and that the Norm Compliance metric isolates unspoken compliance requires explicit details on scenario authoring, norm selection criteria, and controls for task-norm overlap; without these, the 26.4% figure could reflect overly subtle or ambiguously defined norms rather than model limitations.
- [§4.2] §4.2 (Cue-condition experiments): The experiments are presented as evidence that the gap is due to activation/grounding rather than knowledge, yet no inter-annotator agreement scores, cue phrasing templates, or statistical tests comparing conditions are reported; this leaves the central causal claim under-supported.
- [§5] §5 (Results and Metrics): Goal Achievement, Norm Compliance, and Task Success are defined as three separate metrics, but the paper does not specify how conflicts between goal-optimal and norm-compliant actions are resolved in scoring or whether Task Success is a strict conjunction; this directly affects interpretation of the 24.2% to 46.7% improvement.
minor comments (2)
- [Abstract, §1] The abstract and §1 use 'GPT-5.4' and 'Claude Opus 4.7'; these model names should be clarified or footnoted as they do not match currently released versions.
- [Figure 1, §3.2] Figure 1 caption and §3.2 should explicitly state the number of scenarios per category and total evaluation instances to allow readers to assess the reliability of the reported percentages.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on NormAct. The comments highlight areas where additional clarity will strengthen the manuscript. We address each major comment below and will revise accordingly.
read point-by-point responses
-
Referee: [§3] §3 (Benchmark Construction): The claim that norms are embedded 'without any explicit instruction' and that the Norm Compliance metric isolates unspoken compliance requires explicit details on scenario authoring, norm selection criteria, and controls for task-norm overlap; without these, the 26.4% figure could reflect overly subtle or ambiguously defined norms rather than model limitations.
Authors: We agree that expanded details on benchmark construction are warranted. The current §3 outlines the high-level authoring process and norm embedding strategy, but we will add a dedicated subsection detailing: (1) the scenario authoring protocol, (2) explicit norm selection criteria (e.g., frequency in everyday interactions, independence from task goals), and (3) controls implemented to minimize task-norm overlap (including pilot validation steps). These additions will directly support the claim that norms are unspoken and that the compliance metric isolates model limitations rather than benchmark ambiguity. revision: yes
-
Referee: [§4.2] §4.2 (Cue-condition experiments): The experiments are presented as evidence that the gap is due to activation/grounding rather than knowledge, yet no inter-annotator agreement scores, cue phrasing templates, or statistical tests comparing conditions are reported; this leaves the central causal claim under-supported.
Authors: The cue-condition design isolates activation and grounding by providing explicit norm cues while holding knowledge constant. We acknowledge that the manuscript omits inter-annotator agreement, exact cue templates, and statistical tests. In the revision we will report: (a) IAA scores for cue validity annotations, (b) the standardized cue phrasing templates, and (c) paired statistical comparisons (e.g., McNemar or Wilcoxon tests) between the no-cue and cue conditions. These additions will provide quantitative support for the causal attribution. revision: yes
-
Referee: [§5] §5 (Results and Metrics): Goal Achievement, Norm Compliance, and Task Success are defined as three separate metrics, but the paper does not specify how conflicts between goal-optimal and norm-compliant actions are resolved in scoring or whether Task Success is a strict conjunction; this directly affects interpretation of the 24.2% to 46.7% improvement.
Authors: Task Success is defined as the strict conjunction (both Goal Achievement and Norm Compliance must hold). When goal-optimal and norm-compliant actions conflict, the scoring protocol requires the norm-compliant action to be selected for Task Success to be counted as true. We will add an explicit paragraph in §5 clarifying this conjunction definition, the conflict-resolution rule, and an illustrative example. This will remove ambiguity around the reported improvement figures. revision: yes
Circularity Check
No significant circularity in empirical benchmark and method proposal
full rationale
The paper introduces NormAct as an empirical benchmark for evaluating MLLMs on hidden social norm compliance in embodied planning tasks, reports experimental results showing gaps in goal achievement versus norm compliance, and proposes NormPerceptor as a cue generator. No mathematical derivations, equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. The central claims rest on benchmark construction, metric definitions, and experimental comparisons that do not reduce to inputs by construction or self-reference. This is a standard empirical benchmark paper whose evaluation pipeline is independent of the patterns that trigger circularity flags.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages=
Social chemistry 101: Learning to reason about social and moral norms , author=. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages=
2020
-
[2]
Findings of the Association for Computational Linguistics: NAACL 2024 , pages=
Measuring social norms of large language models , author=. Findings of the Association for Computational Linguistics: NAACL 2024 , pages=
2024
-
[3]
Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
SocialGaze: Improving the integration of human social norms in large language models , author=. Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
2024
-
[4]
arXiv preprint arXiv:2603.03590 , year=
Social Norm Reasoning in Multimodal Language Models: An Evaluation , author=. arXiv preprint arXiv:2603.03590 , year=
-
[5]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
Reading Books is Great, But Not if You Are Driving! Visually Grounded Reasoning about Defeasible Commonsense Norms , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
2023
-
[6]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
EgoNormia: Benchmarking Physical-Social Norm Understanding , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[7]
Conference on Robot Learning , pages=
Behavior-1k: A benchmark for embodied ai with 1,000 everyday activities and realistic simulation , author=. Conference on Robot Learning , pages=. 2023 , organization=
2023
-
[8]
Advances in Neural Information Processing Systems , volume=
Simworld: An open-ended simulator for agents in physical and social worlds , author=. Advances in Neural Information Processing Systems , volume=
-
[9]
arXiv preprint arXiv:2512.19234 , year=
DeliveryBench: Can Agents Earn Profit in Real World? , author=. arXiv preprint arXiv:2512.19234 , year=
-
[10]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Voyager: An open-ended embodied agent with large language models , author=. arXiv preprint arXiv:2305.16291 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Proceedings of the 36th annual acm symposium on user interface software and technology , pages=
Generative agents: Interactive simulacra of human behavior , author=. Proceedings of the 36th annual acm symposium on user interface software and technology , pages=
-
[12]
Frontiers in Robotics and AI , volume=
Social robot navigation: a review and benchmarking of learning-based methods , author=. Frontiers in Robotics and AI , volume=. 2025 , publisher=
2025
-
[13]
2024 International Conference on Advanced Robotics and Mechatronics (ICARM) , pages=
Embodied ai with large language models: A survey and new hri framework , author=. 2024 International Conference on Advanced Robotics and Mechatronics (ICARM) , pages=. 2024 , organization=
2024
-
[14]
Conference on Robot Learning , pages=
Rt-2: Vision-language-action models transfer web knowledge to robotic control , author=. Conference on Robot Learning , pages=. 2023 , organization=
2023
-
[15]
arXiv preprint arXiv:2409.18313 , year=
Embodied-rag: General non-parametric embodied memory for retrieval and generation , author=. arXiv preprint arXiv:2409.18313 , year=
-
[16]
Proceedings of the 32nd ACM International Conference on Multimedia , pages=
P-RAG: Progressive retrieval augmented generation for planning on embodied everyday task , author=. Proceedings of the 32nd ACM International Conference on Multimedia , pages=
-
[17]
European conference on computer vision , pages=
Simple open-vocabulary object detection , author=. European conference on computer vision , pages=. 2022 , organization=
2022
-
[18]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Grounded language-image pre-training , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[19]
European conference on computer vision , pages=
Grounding dino: Marrying dino with grounded pre-training for open-set object detection , author=. European conference on computer vision , pages=. 2024 , organization=
2024
-
[20]
Advances in neural information processing systems , volume=
Visual instruction tuning , author=. Advances in neural information processing systems , volume=
-
[21]
International conference on machine learning , pages=
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models , author=. International conference on machine learning , pages=. 2023 , organization=
2023
-
[22]
Advances in neural information processing systems , volume=
Instructblip: Towards general-purpose vision-language models with instruction tuning , author=. Advances in neural information processing systems , volume=
-
[23]
Qwen3-vl technical report , author=. arXiv preprint arXiv:2511.21631 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages=
Moral stories: Situated reasoning about norms, intents, actions, and their consequences , author=. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages=
2021
-
[25]
International Conference on Learning Representations , year=
Aligning AI With Shared Human Values , author=. International Conference on Learning Representations , year=
-
[26]
MoReBench: Evaluating Procedural and Pluralistic Moral Reasoning in Language Models, More than Outcomes , author=. arXiv preprint arXiv:2510.16380 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
arXiv preprint arXiv:2506.19073 , year=
MFTCXplain: A Multilingual Benchmark Dataset for Evaluating the Moral Reasoning of LLMs through Multi-hop Hate Speech Explanation , author=. arXiv preprint arXiv:2506.19073 , year=
-
[28]
arXiv preprint arXiv:2505.14728 , year=
Moralise: A structured benchmark for moral alignment in visual language models , author=. arXiv preprint arXiv:2505.14728 , year=
-
[29]
arXiv preprint arXiv:2506.03922 , year=
Hssbench: Benchmarking humanities and social sciences ability for multimodal large language models , author=. arXiv preprint arXiv:2506.03922 , year=
-
[30]
AI2-THOR: An Interactive 3D Environment for Visual AI
Ai2-thor: An interactive 3d environment for visual ai , author=. arXiv preprint arXiv:1712.05474 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
Conference on Robot Learning , pages=
iGibson 2.0: Object-Centric Simulation for Robot Learning of Everyday Household Tasks , author=. Conference on Robot Learning , pages=. 2022 , organization=
2022
-
[32]
International Conference on Learning Representations , volume=
Habitat 3.0: A co-habitat for humans, avatars, and robots , author=. International Conference on Learning Representations , volume=
-
[33]
Conference on robot learning , pages=
CARLA: An open urban driving simulator , author=. Conference on robot learning , pages=. 2017 , organization=
2017
-
[34]
IEEE transactions on pattern analysis and machine intelligence , volume=
Metadrive: Composing diverse driving scenarios for generalizable reinforcement learning , author=. IEEE transactions on pattern analysis and machine intelligence , volume=. 2022 , publisher=
2022
-
[35]
arXiv preprint arXiv:2410.09604 , year=
Embodiedcity: A benchmark platform for embodied agent in real-world city environment , author=. arXiv preprint arXiv:2410.09604 , year=
-
[36]
International Conference on Machine Learning , pages=
EmbodiedBench: Comprehensive Benchmarking Multi-modal Large Language Models for Vision-Driven Embodied Agents , author=. International Conference on Machine Learning , pages=. 2025 , organization=
2025
-
[37]
International Conference on Learning Representations (ICLR) 2024 , pages=
LoTa-Bench: Benchmarking Language-oriented Task Planners for Embodied Agents , author=. International Conference on Learning Representations (ICLR) 2024 , pages=
2024
-
[38]
AgentSociety: Large-Scale Simulation of LLM-Driven Generative Agents Advances Understanding of Human Behaviors and Society , author=. arXiv preprint arXiv:2502.08691 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[39]
arXiv preprint arXiv:2412.19498 , year=
Casevo: A cognitive agents and social evolution simulator , author=. arXiv preprint arXiv:2412.19498 , year=
-
[40]
arXiv preprint arXiv:2411.11581 , year=
Oasis: Open agent social interaction simulations with one million agents , author=. arXiv preprint arXiv:2411.11581 , year=
-
[41]
arXiv preprint arXiv:2508.18321 , year=
LLMs Can't Handle Peer Pressure: Crumbling under Multi-Agent Social Interactions , author=. arXiv preprint arXiv:2508.18321 , year=
-
[42]
Advances in neural information processing systems , volume=
Evaluating generalization capabilities of LLM-based agents in mixed-motive scenarios using concordia , author=. Advances in neural information processing systems , volume=
-
[43]
Advances in neural information processing systems , volume=
Retrieval-augmented generation for knowledge-intensive nlp tasks , author=. Advances in neural information processing systems , volume=
-
[44]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
NormBank: A knowledge bank of situational social norms , author=. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[45]
IEEE transactions on big data , volume=
Billion-scale similarity search with GPUs , author=. IEEE transactions on big data , volume=. 2019 , publisher=
2019
-
[46]
Sentence-bert: Sentence embeddings using siamese bert-networks , author=. Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP) , pages=
2019
-
[47]
Computer Science Review , volume=
From vectors to knowledge graphs: A comprehensive analysis of modern retrieval-augmented generation architectures , author=. Computer Science Review , volume=. 2026 , publisher=
2026
-
[48]
arXiv preprint arXiv:2503.10677 (2025)
A survey on knowledge-oriented retrieval-augmented generation , author=. arXiv preprint arXiv:2503.10677 , year=
-
[49]
Seedance 2.0: Advancing Video Generation for World Complexity
Seedance 2.0: Advancing video generation for world complexity , author=. arXiv preprint arXiv:2604.14148 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[50]
arXiv preprint arXiv:2509.08757 , year=
Socialnav-SUB: Benchmarking VLMs for scene understanding in social robot navigation , author=. arXiv preprint arXiv:2509.08757 , year=
-
[51]
arXiv preprint arXiv:2510.02356 , year=
Measuring physical-world privacy awareness of large language models: An evaluation benchmark , author=. arXiv preprint arXiv:2510.02356 , year=
-
[52]
Gpt-4o system card , author=. arXiv preprint arXiv:2410.21276 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[53]
arXiv preprint arXiv:2512.20206 , year=
TongSIM: A General Platform for Simulating Intelligent Machines , author=. arXiv preprint arXiv:2512.20206 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.