Embodiment Meets Environment: Toward Context-Aware, Safe Physical Caregiving Robots
Pith reviewed 2026-06-30 00:53 UTC · model grok-4.3
The pith
Caregiving robots can reuse the same skill templates safely across different homes and robot bodies by enforcing runtime constraints derived from a shared 3D scene model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
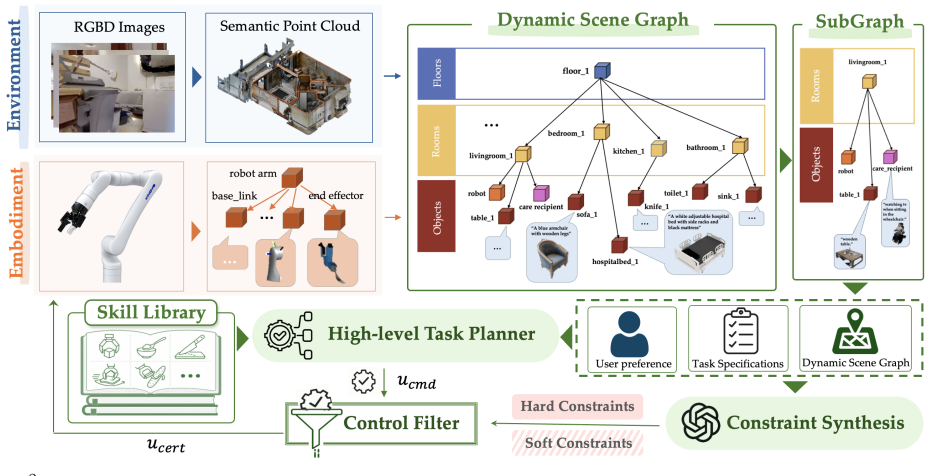
E²-CARE represents primitive caregiving skills as interaction templates whose execution is reshaped online. It places the environment, the robot, and the human inside one unified 3D dynamic scene graph that makes interaction contexts explicit, then synthesizes task-specific constraints that govern how each template runs. Enforcing those constraints at runtime lets the same templates transfer zero-shot and safely to new environments and new robot embodiments.
What carries the argument
The unified 3D dynamic scene graph that models explicit interaction contexts between environment, robot embodiment, and human, together with the online synthesis of task-specific execution constraints from that graph.
If this is right
- The same skill templates transfer zero-shot to new household layouts and new robot shapes while remaining safe.
- Hundreds of simulated homes plus real-robot user studies show consistent task success across activities of daily living.
- Caregiving systems no longer need separate programming for each environment-embodiment pair.
- Explicit modeling of human-robot-environment interactions replaces implicit assumptions about context.
Where Pith is reading between the lines
- The method could cut the engineering cost of deploying assistive robots in varied homes by removing per-site retraining.
- Templates might later be learned or refined from demonstration data while the constraint layer stays fixed for safety.
- Similar scene-graph-plus-constraint machinery could apply to collaborative factory tasks or elder-care mobility aids.
Load-bearing premise
Sensors can build a 3D scene graph that captures every safety-critical interaction among the robot, the person, and the room so the generated constraints actually stop harm.
What would settle it
A real-world trial in which the scene graph misses a close approach between robot and person, the synthesized constraints fail to block the motion, and contact occurs.
Figures


read the original abstract
Physical caregiving robots need to assist different users with different tasks in diverse environments, and they come in many embodiments. While substantial progress has been made on individual caregiving tasks, most existing systems remain tightly coupled to specific environments and robot embodiments, and often do not explicitly model or constrain interactions around people, despite humans being special agents in the environment. This motivates a focus on adapting to context that emerges from the joint interaction between the environment and the robot's embodiment. We propose $E^2$-CARE, a framework that enables context-aware adaptation by representing primitive caregiving skills as interaction templates whose execution is reshaped online. $E^2$-CARE represents the environment, the robot, and the human within a unified 3D dynamic scene graph that models these interaction contexts explicitly, and synthesizes task-specific constraints to govern how each skill is executed. By enforcing these constraints at runtime, the same skill templates can be reused zero-shot and safely across diverse environments and robot embodiments. We evaluate $E^2$-CARE across four activities of daily living in hundreds of simulated household environments, including assistive home settings, and across diverse robot embodiments, and validate it through user studies on two caregiving tasks with two robots in various real-world environments. Results demonstrate consistent and successful adaptation across these environments and embodiments. Website: https://emprise.cs.cornell.edu/e2care
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces E²-CARE, a framework for context-aware physical caregiving robots. Primitive skills are encoded as reusable interaction templates whose online execution is reshaped by task-specific constraints. These constraints are synthesized from a unified 3D dynamic scene graph that jointly represents the environment, robot embodiment, and human. The central claim is that enforcing the constraints at runtime permits the same templates to be deployed zero-shot and safely across hundreds of simulated household environments, multiple robot embodiments, and real-world user studies on two tasks.
Significance. If the safety and zero-shot reuse claims hold under realistic sensor conditions, the work would provide a concrete mechanism for decoupling skill libraries from embodiment and environment specifics while explicitly accounting for human interaction contexts. The scene-graph-plus-constraint approach is a natural fit for caregiving domains where both embodiment variation and human safety are first-order concerns. The evaluation scope (hundreds of simulated environments plus real-user validation) is larger than typical single-task caregiving papers and supplies a useful benchmark for future context-aware systems.
major comments (3)
- [§4, §5] §4 (Scene Graph Construction) and §5 (Constraint Synthesis): the central zero-shot safety argument requires that the 3D dynamic scene graph supplies every safety-relevant fact (human velocity, contact geometry, embodiment-specific reachability). No analysis is given of how the graph handles common sensor limitations (occlusion, limited FOV, latency, or missing soft-tissue deformation). If any critical interaction context is absent, the synthesized constraints cannot forbid the corresponding unsafe motion, yet the template is still executed. This assumption is load-bearing for the reuse claim across embodiments.
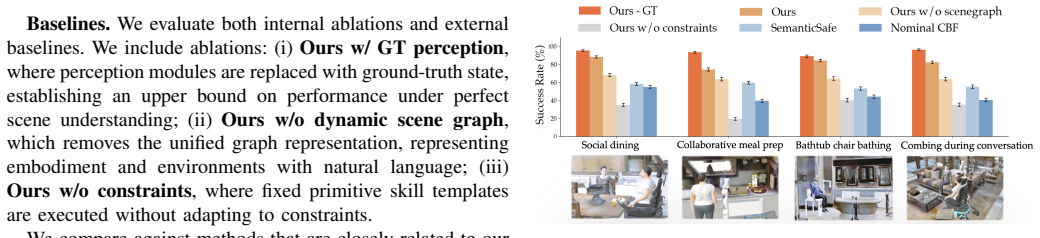
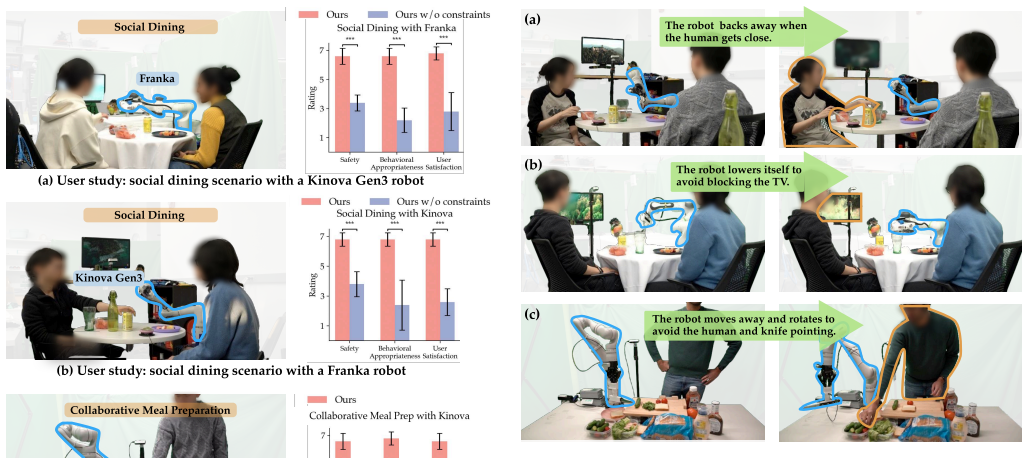
- [§6] §6 (Evaluation): the abstract and results claim “consistent and successful adaptation” across four ADLs, hundreds of environments, and real user studies, but no quantitative metrics (success rate, constraint violation rate, failure cases, or embodiment-specific safety incidents) are reported. Without these numbers it is impossible to assess whether the scene-graph constraints actually prevent harm or merely correlate with task completion in the tested regimes.
- [§5.2] §5.2 (Constraint Generation): the paper states that constraints are synthesized to “govern how each skill is executed,” yet provides no formal specification of the constraint language, how embodiment kinematics are folded into the constraints, or any verification procedure (static or runtime) that the constraints are sufficient to guarantee safety. This gap directly affects the reproducibility and safety claims.
minor comments (3)
- [§3] Notation for the scene-graph nodes and edges is introduced without a compact summary table; readers must hunt through the text to recall the meaning of each symbol.
- [Figure 3] Figure 3 (example scene graph) would benefit from an explicit legend distinguishing environment, robot, and human nodes.
- [§6.2] The real-world user-study protocol (number of participants, tasks, environments, and success criteria) is described only at high level; a supplementary table would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which identify key areas for strengthening the safety and reproducibility claims of E²-CARE. We address each major comment below and will incorporate revisions to clarify assumptions, add quantitative metrics, and formalize the constraint synthesis.
read point-by-point responses
-
Referee: [§4, §5] §4 (Scene Graph Construction) and §5 (Constraint Synthesis): the central zero-shot safety argument requires that the 3D dynamic scene graph supplies every safety-relevant fact (human velocity, contact geometry, embodiment-specific reachability). No analysis is given of how the graph handles common sensor limitations (occlusion, limited FOV, latency, or missing soft-tissue deformation). If any critical interaction context is absent, the synthesized constraints cannot forbid the corresponding unsafe motion, yet the template is still executed. This assumption is load-bearing for the reuse claim across embodiments.
Authors: We agree this assumption is central. The manuscript's evaluations rely on complete scene graphs (oracle in simulation; motion-capture in real-user studies). In the revision we will add a dedicated paragraph in §4 discussing these sensor assumptions and outlining extensions such as uncertainty propagation in the scene graph and conservative constraint tightening under partial observability. This will explicitly bound the zero-shot safety claims to settings where the graph is sufficiently complete. revision: yes
-
Referee: [§6] §6 (Evaluation): the abstract and results claim “consistent and successful adaptation” across four ADLs, hundreds of environments, and real user studies, but no quantitative metrics (success rate, constraint violation rate, failure cases, or embodiment-specific safety incidents) are reported. Without these numbers it is impossible to assess whether the scene-graph constraints actually prevent harm or merely correlate with task completion in the tested regimes.
Authors: The current manuscript emphasizes qualitative demonstration of zero-shot reuse. We accept that quantitative reporting is necessary. The revision will add a results table in §6 reporting per-task success rates, constraint violation counts, and categorized failure modes across the simulated environments and the two real-world user studies, broken down by embodiment where applicable. revision: yes
-
Referee: [§5.2] §5.2 (Constraint Generation): the paper states that constraints are synthesized to “govern how each skill is executed,” yet provides no formal specification of the constraint language, how embodiment kinematics are folded into the constraints, or any verification procedure (static or runtime) that the constraints are sufficient to guarantee safety. This gap directly affects the reproducibility and safety claims.
Authors: We will expand §5.2 with a formal definition of the constraint language (linear inequalities over joint velocities and end-effector poses) and explicitly show how embodiment-specific kinematic parameters from the scene graph are substituted into the constraint coefficients. We will also describe the runtime projection solver used for enforcement. While the paper does not provide formal safety proofs (which would require stronger assumptions on perception), the revision will clarify that safety is enforced empirically via the synthesized constraints and report the observed violation rates from the new quantitative evaluation. revision: yes
Circularity Check
No circularity: framework proposal contains no equations or self-referential derivations
full rationale
The paper introduces the E²-CARE framework conceptually, representing skills as interaction templates executed under constraints synthesized from a unified 3D dynamic scene graph. No mathematical derivations, fitted parameters, or equations appear in the provided text. Claims of zero-shot reuse are supported by external evaluations (simulations across environments and real-world user studies), not by any reduction of outputs to inputs by construction. Self-citations are absent from the abstract and description, and the central premise does not rely on uniqueness theorems or ansatzes imported from prior author work. This is a standard non-finding for a systems/framework paper whose load-bearing elements are empirical validation rather than algebraic self-reference.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A unified 3D dynamic scene graph can explicitly represent interaction contexts among environment, robot, and human.
invented entities (1)
-
interaction templates
no independent evidence
Reference graph
Works this paper leans on
-
[1]
https://meetobi.com/
Meet Obi. https://meetobi.com/. [Online; accessed 1-Jan- 2026]
2026
-
[2]
URL https://www.neater.co.uk/ neater-eater-robotic
Neater eater robot, 2024. URL https://www.neater.co.uk/ neater-eater-robotic. (Accessed: 1st January, 2026)
2024
-
[3]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black et al.π 0: A vision-language-action flow model for general robot control, 2025. URL https://arxiv. org/abs/2410.24164
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Rt-1: Robotics transformer for real- world control at scale.Robotics: Science and Systems XIX, 2023
Anthony Brohan, Noah Brown, Justice Carbajal, Yev- gen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alexander Herzog, Jas- mine Hsu, et al. Rt-1: Robotics transformer for real- world control at scale.Robotics: Science and Systems XIX, 2023
2023
-
[5]
Schoellig
Lukas Brunke, Yanni Zhang, Ralf R ¨omer, Jack Naimer, Nikola Staykov, Siqi Zhou, and Angela P. Schoellig. Se- mantically safe robot manipulation: From semantic scene understanding to motion safeguards.IEEE Robotics and Automation Letters, 10(5):4810–4817, 2025
2025
-
[6]
Matterport3d: Learning from rgb-d data in indoor environments.International Conference on 3D Vision (3DV), 2017
Angel Chang, Angela Dai, Thomas Funkhouser, Maciej Halber, Matthias Niessner, Manolis Savva, Shuran Song, Andy Zeng, and Yinda Zhang. Matterport3d: Learning from rgb-d data in indoor environments.International Conference on 3D Vision (3DV), 2017
2017
-
[7]
Mirage: Cross-embodiment zero-shot policy transfer with cross-painting.Robotics: Science and Systems XIX, 2024
Lawrence Yunliang Chen, Kush Hari, Karthik Dharmara- jan, Chenfeng Xu, Quan Vuong, and Ken Goldberg. Mirage: Cross-embodiment zero-shot policy transfer with cross-painting.Robotics: Science and Systems XIX, 2024
2024
-
[8]
Kemp, and C
Alexander Clegg, Zackory Erickson, Patrick Grady, Greg Turk, Charles C. Kemp, and C. Karen Liu. Learning to collaborate from simulation for robot-assisted dressing. IEEE Robotics and Automation Letters, 5(2):2746–2753,
-
[9]
doi: 10.1109/LRA.2020.2972852
-
[10]
Design and evaluation of a hair combing system using a general-purpose robotic arm
Nathaniel Dennler, Eura Shin, Maja Mataric, and Ste- fanos Nikolaidis. Design and evaluation of a hair combing system using a general-purpose robotic arm. pages 3739–3746, 09 2021. doi: 10.1109/IROS51168. 2021.9636768
-
[11]
Food peeling method for dual-arm cooking robot
Chenyu Dong, Liangliang Yu, Masaru Takizawa, Shun- suke Kudoh, and Takashi Suehiro. Food peeling method for dual-arm cooking robot. In2021 IEEE/SICE Inter- national Symposium on System Integration (SII), pages 801–806, 2021. doi: 10.1109/IEEECONF49454.2021. 9382700
-
[12]
Interleave- vla: Enhancing robot manipulation with image-text in- terleaved instructions
Cunxin Fan, Xiaosong Jia, Yihang Sun, Yixiao Wang, Jianglan Wei, Ziyang Gong, Xiangyu Zhao, Masayoshi Tomizuka, Xue Yang, Junchi Yan, et al. Interleave- vla: Enhancing robot manipulation with image-text in- terleaved instructions. InThe Fourteenth International Conference on Learning Representations, 2025
2025
-
[13]
Rh20t: A comprehensive robotic dataset for learning diverse skills in one-shot
Hao-Shu Fang, Hongjie Fang, Zhenyu Tang, Jirong Liu, Chenxi Wang, Junbo Wang, Haoyi Zhu, and Cewu Lu. Rh20t: A comprehensive robotic dataset for learning diverse skills in one-shot. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 653–660. IEEE, 2024
2024
-
[14]
Transfer depends on acquisition: Analyzing manipulation strategies for robotic feeding
Daniel Gallenberger, Tapomayukh Bhattacharjee, Young- sun Kim, and Siddhartha S Srinivasa. Transfer depends on acquisition: Analyzing manipulation strategies for robotic feeding. In2019 14th ACM/IEEE International Conference on Human-Robot Interaction (HRI), pages 267–276. IEEE, 2019
2019
-
[15]
Learning bimanual scooping policies for food acquisition
Jennifer Grannen, Yilin Wu, Suneel Belkhale, and Dorsa Sadigh. Learning bimanual scooping policies for food acquisition. In6th Annual Conference on Robot Learning, 2022. URL https://openreview.net/forum?id= qDtbMK67PJG
2022
-
[16]
Conceptgraphs: Open-vocabulary 3d scene graphs for perception and planning
Qiao Gu, Ali Kuwajerwala, Sacha Morin, Krishna Murthy Jatavallabhula, Bipasha Sen, Aditya Agarwal, Corban Rivera, William Paul, Kirsty Ellis, Rama Chellappa, et al. Conceptgraphs: Open-vocabulary 3d scene graphs for perception and planning. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 5021–5028. IEEE, 2024
2024
-
[17]
Vttb: A visuo-tactile learning approach for robot-assisted bed bathing.IEEE Robotics and Automation Letters, 9(6):5751–5758, 2024
Yijun Gu and Yiannis Demiris. Vttb: A visuo-tactile learning approach for robot-assisted bed bathing.IEEE Robotics and Automation Letters, 9(6):5751–5758, 2024
2024
-
[18]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
Physical Intelligence.π 0.5: a vision-language-action model with open-world generalization, 2025. URL https://arxiv.org/abs/2504.16054
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Flair: Feeding via long-horizon acquisition of realistic dishes
Rajat Kumar Jenamani, Priya Sundaresan, Maram Sakr, Tapomayukh Bhattacharjee, and Dorsa Sadigh. Flair: Feeding via long-horizon acquisition of realistic dishes. arXiv preprint arXiv:2407.07561, 2024
-
[20]
Feast: A flexible mealtime-assistance system towards in-the-wild personalization
Rajat Kumar Jenamani, Tom Silver, Ben Dodson, Shiqin Tong, Anthony Song, Yuting Yang, Ziang Liu, Benjamin Howe, Aimee Whitneck, and Tapomayukh Bhattacharjee. Feast: A flexible mealtime-assistance system towards in-the-wild personalization. InRobotics: Science and Systems (RSS), 2025
2025
-
[21]
The design of stretch: A compact, lightweight mobile manipulator for indoor human envi- ronments
Charles C Kemp, Aaron Edsinger, Henry M Clever, and Blaine Matulevich. The design of stretch: A compact, lightweight mobile manipulator for indoor human envi- ronments. In2022 International Conference on Robotics and Automation (ICRA), pages 3150–3157. IEEE, 2022
2022
-
[22]
Droid: A large-scale in- the-wild robot manipulation dataset
Alexander Khazatsky et al. Droid: A large-scale in- the-wild robot manipulation dataset. InProceedings of Robotics: Science and Systems (RSS), 2024
2024
-
[23]
Openvla: An open-source vision-language-action model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan P Foster, Pannag R Sanketi, Quan Vuong, et al. Openvla: An open-source vision-language-action model. In8th Annual Conference on Robot Learning
-
[24]
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C. Berg, Wan-Yen Lo, Piotr Doll ´ar, and Ross Girshick. Segment anything. arXiv:2304.02643, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[25]
Skill discovery in continuous reinforcement learning domains using skill chaining
George Konidaris and Andrew Barto. Skill discovery in continuous reinforcement learning domains using skill chaining. InProceedings of the 23rd International Conference on Neural Information Processing Systems, NIPS’09, page 1015–1023, Red Hook, NY , USA, 2009. Curran Associates Inc. ISBN 9781615679119
2009
-
[26]
Practice makes perfect: Planning to learn skill parameter policies.Robotics: Science and Systems, 2024
Nishanth Kumar, Tom Silver, Willie McClinton, Linfeng Zhao, Stephen Proulx, Tom´as Lozano-P´erez, Leslie Pack Kaelbling, and Jennifer Barry. Practice makes perfect: Planning to learn skill parameter policies.Robotics: Science and Systems, 2024
2024
-
[27]
Open-world task and motion plan- ning via vision-language model generated constraints
Nishanth Kumar, William Shen, Fabio Ramos, Dieter Fox, Tom ´as Lozano-P ´erez, Leslie Pack Kaelbling, and Caelan Reed Garrett. Open-world task and motion plan- ning via vision-language model generated constraints. IEEE Robotics and Automation Letters, 2026
2026
-
[28]
Learning hand-eye coor- dination for robotic grasping with deep learning and large-scale data collection.The International Journal of Robotics Research, 37(4-5):421–436, 2018
Sergey Levine, Peter Pastor, Alex Krizhevsky, Julian Ibarz, and Deirdre Quillen. Learning hand-eye coor- dination for robotic grasping with deep learning and large-scale data collection.The International Journal of Robotics Research, 37(4-5):421–436, 2018. doi: 10. 1177/0278364917710318. URL https://doi.org/10.1177/ 0278364917710318
2018
-
[29]
Qixiu Li, Yaobo Liang, Zeyu Wang, Lin Luo, Xi Chen, Mozheng Liao, Fangyun Wei, Yu Deng, Sicheng Xu, Yizhong Zhang, et al. Cogact: A foundational vision-language-action model for synergizing cognition and action in robotic manipulation.arXiv preprint arXiv:2411.19650, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
Open- RoboCare: A Multi-Modal Multi-Task Expert Demon- stration Dataset for Robot Caregiving
Xiaoyu Liang, Ziang Liu, Kelvin Lin, Edward Gu, Ruolin Ye, Tam Nguyen, Cynthia Hsu, Zhanxin Wu, Xiaoman Yang, Christy Sum Yu Cheung, Harold Soh, Katherine Dimitropoulou, and Tapomayukh Bhattacharjee. Open- RoboCare: A Multi-Modal Multi-Task Expert Demon- stration Dataset for Robot Caregiving. InProceedings of the IEEE/RSJ International Conference on Intel...
2025
-
[31]
Fukang Liu, Kavya Puthuveetil, Akhil Padmanabha, Karan Khokar, Zeynep Temel, and Zackory Erickson. Skingrip: An adaptive soft robotic manipulator with capacitive sensing for whole-limb bed bathing assistance. arXiv preprint arXiv:2405.02772, 2024
-
[32]
Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection. arXiv preprint arXiv:2303.05499, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[33]
Open scene graphs for open-world object-goal navigation
Joel Loo, Zhanxin Wu, and David Hsu. Open scene graphs for open-world object-goal navigation. The International Journal of Robotics Research, page 02783649251369549
-
[34]
Sparcs: Structuring physically assistive robotics for caregiving with stakeholders-in-the-loop.IROS, 2022
Rishabh Madan, Rajat Kumar Jenamani, Vy Thuy Nguyen, Ahmed Moustafa, Xuefeng Hu, Katherine Dim- itropoulou, and Tapomayukh Bhattacharjee. Sparcs: Structuring physically assistive robotics for caregiving with stakeholders-in-the-loop.IROS, 2022
2022
-
[35]
Rabbit: A robot-assisted bed bathing system with multimodal perception and integrated compliance
Rishabh Madan, Skyler Valdez, Kim David, Fang Sujie, Zhong Luoyan, Virtue Diego, and Tapomayukh Bhat- tacharjee. Rabbit: A robot-assisted bed bathing system with multimodal perception and integrated compliance. HRI, 2024
2024
-
[36]
Safe, task-consistent manipulation with operational space control barrier func- tions
Daniel Morton and Marco Pavone. Safe, task-consistent manipulation with operational space control barrier func- tions. In2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 187–194,
-
[37]
doi: 10.1109/IROS60139.2025.11246389
-
[38]
Gordon, Taylor A
Amal Nanavati, Ethan K. Gordon, Taylor A. Kessler Faulkner, Yuxin (Ray) Song, Jonathan Ko, Tyler Schrenk, Vy Nguyen, Bernie Hao Zhu, Haya Bolotski, Atharva Kashyap, Sriram Kutty, Raida Karim, Liander Rainbolt, Rosario Scalise, Hanjun Song, Ramon Qu, Maya Cakmak, and Siddhartha S. Srinivasa. Lessons learned from designing and evaluating a robot-assisted fe...
2025
-
[39]
Open X-Embodiment: Robotic learning datasets and RT-X models, 2023
Abby O’Neill et al. Open X-Embodiment: Robotic learning datasets and RT-X models, 2023
2023
-
[40]
Extending the application of an assistant personal robot as a walk-helper tool
Jordi Palac ´ın, Eduard Clotet, Dani Mart ´ınez, David Mart´ınez, and Javier Moreno. Extending the application of an assistant personal robot as a walk-helper tool. Robotics, 8(2):27, 2019
2019
-
[41]
Mahajan, Ho Keun Kim, Zackory Erickson, Wendy A
Daehyung Park, Yuuna Hoshi, Harshal P. Mahajan, Ho Keun Kim, Zackory Erickson, Wendy A. Rogers, and Charles C. Kemp. Active robot-assisted feed- ing with a general-purpose mobile manipulator: De- sign, evaluation, and lessons learned.Robotics and Autonomous Systems, 124:103344, 2020. ISSN 0921-8890. doi: https://doi.org/10.1016/j.robot.2019. 103344. URL h...
-
[42]
Active robot-assisted feeding with a general-purpose mobile manipulator: Design, evaluation, and lessons learned.Robotics and Autonomous Systems, 124:103344, 2020
Daehyung Park, Yuuna Hoshi, Harshal P Mahajan, Ho Keun Kim, Zackory Erickson, Wendy A Rogers, and Charles C Kemp. Active robot-assisted feeding with a general-purpose mobile manipulator: Design, evaluation, and lessons learned.Robotics and Autonomous Systems, 124:103344, 2020
2020
-
[43]
Habitat-matterport 3d dataset (HM3d): 1000 large-scale 3d environments for embodied AI
Santhosh Kumar Ramakrishnan, Aaron Gokaslan, Erik Wijmans, Oleksandr Maksymets, Alexander Clegg, John M Turner, Eric Undersander, Wojciech Galuba, Andrew Westbury, Angel X Chang, Manolis Savva, Yili Zhao, and Dhruv Batra. Habitat-matterport 3d dataset (HM3d): 1000 large-scale 3d environments for embodied AI. InThirty-fifth Conference on Neural Information...
-
[44]
URL https://arxiv.org/abs/2109.08238
work page internal anchor Pith review Pith/arXiv arXiv
-
[45]
Safety guardrails for llm-enabled robots.IEEE Robotics and Automation Letters, 2026
Zachary Ravichandran, Alexander Robey, Vijay Kumar, George J Pappas, and Hamed Hassani. Safety guardrails for llm-enabled robots.IEEE Robotics and Automation Letters, 2026
2026
-
[46]
Rosinol, A
A. Rosinol, A. Gupta, M. Abate, J. Shi, and L. Carlone. 3D dynamic scene graphs: Actionable spatial perception with places, objects, and humans. InRobotics: Science and Systems (RSS), 2020
2020
-
[47]
Learning manipula- tion graphs from demonstrations using multimodal sen- sory signals
Zhe Su, Oliver Kroemer, Gerald E Loeb, Gaurav S Sukhatme, and Stefan Schaal. Learning manipula- tion graphs from demonstrations using multimodal sen- sory signals. In2018 IEEE international conference on robotics and automation (ICRA), pages 2758–2765. IEEE, 2018
2018
-
[48]
Zhanyi Sun, Yufei Wang, David Held, and Zackory Erickson. Force-constrained visual policy: Safe robot- assisted dressing via multi-modal sensing.IEEE Robotics and Automation Letters, PP:1–8, 05 2024. doi: 10.1109/ LRA.2024.3375712
-
[49]
Perspective chapter: Uncovering older adult needs–applying user-centered research methodologies to inform robotics development and a call to action
Katherine M Tsui, Sarah Cohen, Selma Sabanovic, Alex Alspach, Rune Baggett, David Crandall, and Steffi Paepcke. Perspective chapter: Uncovering older adult needs–applying user-centered research methodologies to inform robotics development and a call to action. 2024
2024
-
[50]
Tsui, Rune Baggett, and Carol Chiang
Katherine M. Tsui, Rune Baggett, and Carol Chiang. Ex- ploring embodiment form factors of a home-helper robot: Perspectives from care receivers and caregivers.Applied Sciences, 15(2), 2025. ISSN 2076-3417. doi: 10.3390/ app15020891. URL https://www.mdpi.com/2076-3417/ 15/2/891
2025
-
[51]
Lotus: Continual imitation learning for robot manipula- tion through unsupervised skill discovery
Weikang Wan, Yifeng Zhu, Rutav Shah, and Yuke Zhu. Lotus: Continual imitation learning for robot manipula- tion through unsupervised skill discovery. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 537–544. IEEE, 2024
2024
-
[52]
Savor: Skill affordance learning from visuo- haptic perception for robot-assisted bite acquisition
Zhanxin Wu, Bo Ai, Tom Silver, and Tapomayukh Bhat- tacharjee. Savor: Skill affordance learning from visuo- haptic perception for robot-assisted bite acquisition. In Conference on Robot Learning (CoRL), 2025
2025
-
[53]
Pushing the limits of cross- embodiment learning for manipulation and navigation
Jonathan Yang, Catherine Glossop, Arjun Bhorkar, Dhruv Shah, Quan Vuong, Chelsea Finn, Dorsa Sadigh, and Sergey Levine. Pushing the limits of cross- embodiment learning for manipulation and navigation. Robotics: Science and Systems XIX, 2024
2024
-
[54]
Rcareworld: A human- centric simulation world for caregiving robots.IROS, 2022
Ruolin Ye, Wenqiang Xu, Haoyuan Fu, Rajat Kumar Je- namani, Vy Nguyen, Cewu Lu, Katherine Dimitropoulou, and Tapomayukh Bhattacharjee. Rcareworld: A human- centric simulation world for caregiving robots.IROS, 2022
2022
-
[55]
Morpheus: a multimodal one-armed robot-assisted peeling system with human users in-the-loop
Ruolin Ye, Yifei Hu, Yuhan Anjelica Bian, Luke Kulm, and Tapomayukh Bhattacharjee. Morpheus: a multimodal one-armed robot-assisted peeling system with human users in-the-loop. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 9540–9547,
-
[56]
doi: 10.1109/ICRA57147.2024.10610050
-
[57]
Soft and compliant contact-rich hair manipulation and care
Uksang Yoo, Nathaniel Dennler, Eliot Xing, Maja Mataric, Stefanos Nikolaidis, Jeffrey Ichnowski, and Jean Oh. Soft and compliant contact-rich hair manipulation and care. InProceedings of the 2025 ACM/IEEE Inter- national Conference on Human-Robot Interaction, 2025
2025
-
[58]
Learning garment manipulation policies toward robot-assisted dressing.Sci- ence robotics, 7(65):eabm6010, 2022
Fan Zhang and Yiannis Demiris. Learning garment manipulation policies toward robot-assisted dressing.Sci- ence robotics, 7(65):eabm6010, 2022
2022
-
[59]
Rec- ognize anything: A strong image tagging model.ArXiv, abs/2306.03514, 2023
Youcai Zhang, Xinyu Huang, Jinyu Ma, Zhaoyang Li, Zhaochuan Luo, Yanchun Xie, Yuzhuo Qin, Tong Luo, Yaqian Li, Shilong Liu, et al. Recognize any- thing: A strong image tagging model.arXiv preprint arXiv:2306.03514, 2023
-
[60]
Dymo-hair: Generalizable volu- metric dynamics modeling for robot hair manipulation
Chengyang Zhao, Uksang Yoo, Arkadeep Narayan Chaudhury, Giljoo Nam, Jonathan Francis, Jeffrey Ich- nowski, and Jean Oh. Dymo-hair: Generalizable volu- metric dynamics modeling for robot hair manipulation. International Conference on Robotics and Automation, 2026
2026
-
[61]
Bimanual robot-assisted dressing: A spherical coordinate-based strategy for tight-fitting garments
Jian Zhao, Yunlong Lian, Andy Tyrrell, Michael Gien- ger, and Jihong Zhu. Bimanual robot-assisted dressing: A spherical coordinate-based strategy for tight-fitting garments. pages 3328–3335, 10 2025. doi: 10.1109/ IROS60139.2025.11246012
-
[62]
Rt-2: Vision-language- action models transfer web knowledge to robotic control
Brianna Zitkovich, Tianhe Yu, Sichun Xu, Peng Xu, Ted Xiao, Fei Xia, Jialin Wu, Paul Wohlhart, Stefan Welker, Ayzaan Wahid, et al. Rt-2: Vision-language- action models transfer web knowledge to robotic control. InConference on Robot Learning, pages 2165–2183. PMLR, 2023
2023
-
[63]
Multimodal signal pro- cessing and learning aspects of human-robot interaction for an assistive bathing robot
Athanasia Zlatintsi, Isidoros Rodomagoulakis, Petros Koutras, AC Dometios, Vassilis Pitsikalis, Costas S Tzafestas, and Petros Maragos. Multimodal signal pro- cessing and learning aspects of human-robot interaction for an assistive bathing robot. In2018 IEEE international conference on acoustics, speech and signal processing (ICASSP), pages 3171–3175. IEEE, 2018
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.