MAVIN: Multi-Shot Audio-Visual Generation with Narrative Control
Pith reviewed 2026-06-30 07:15 UTC · model grok-4.3
The pith
MAVIN provides the first framework for multi-shot audio-visual generation with customized narrative control.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
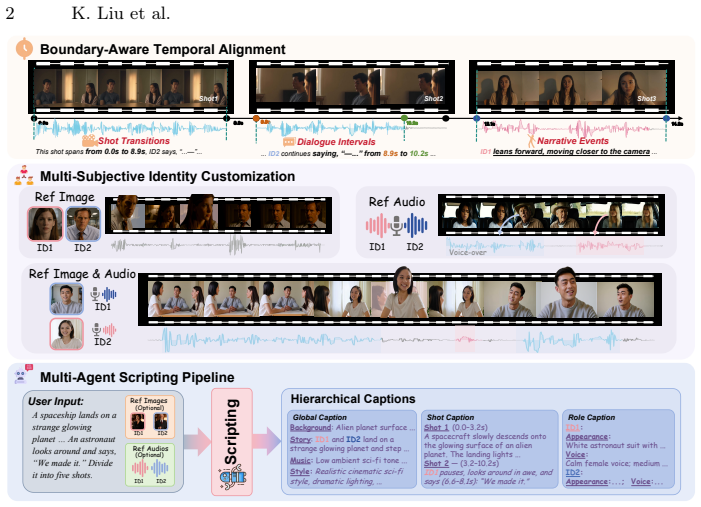
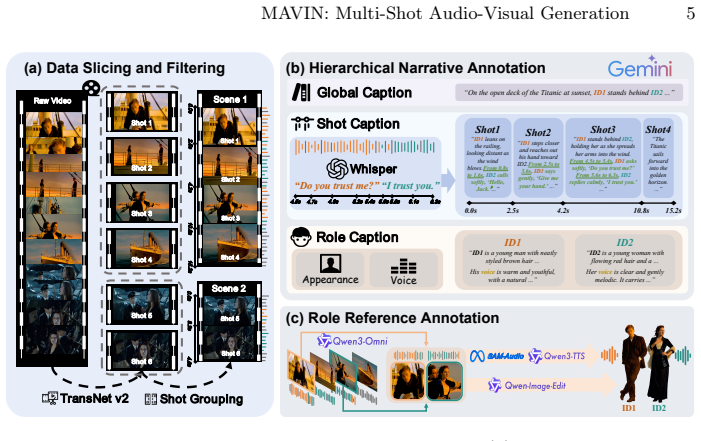
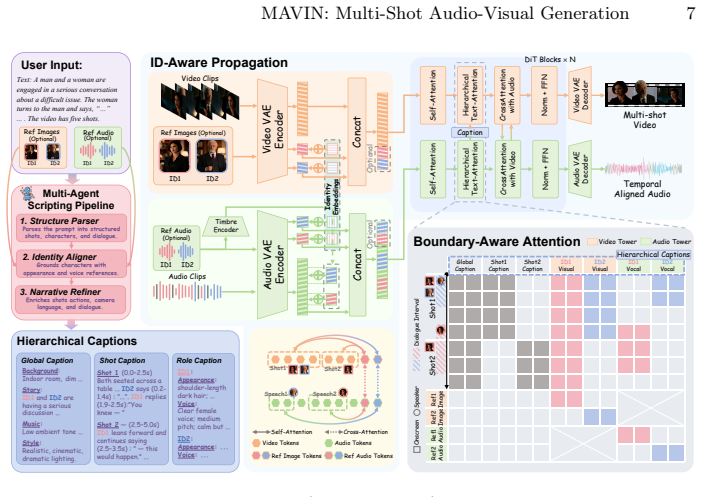
MAVIN is the first framework for multi-shot audio-visual generation with customized narrative control. To resolve temporal misalignment, we propose boundary-aware attention, which leverages hierarchical captions and boundary-aware token routing to render audio-visual elements within their respective temporal boundaries. To improve the controllability for multi-subject scenarios, we propose ID-aware propagation, utilizing identity embeddings and an identity-aware mask to bind specific identities to consistent visual appearances and vocal timbres. To provide comprehensive audio-visual narratives, we present a multi-agent scripting pipeline to transform free-form user inputs into hierarchical c
What carries the argument
Boundary-aware attention for temporal alignment combined with ID-aware propagation for identity consistency across shots.
If this is right
- Resolves temporal misalignment using boundary-aware attention with hierarchical captions.
- Improves controllability in multi-subject cases via ID-aware propagation with embeddings and masks.
- Generates comprehensive narratives from free-form inputs using multi-agent scripting.
- Achieves state-of-the-art performance on multi-shot audio-visual tasks.
- Opens integration of generative models into professional filmmaking workflows.
Where Pith is reading between the lines
- The techniques could be applied to single-shot or longer-form video generation to improve consistency.
- MAVINSet may become a standard benchmark for evaluating narrative coherence in generated media.
- Combining this with real-time user feedback could lead to interactive storytelling tools.
- Similar modular control strategies might address consistency issues in other generative domains like music or 3D animation.
Load-bearing premise
The boundary-aware attention, ID-aware propagation, and multi-agent scripting pipeline will successfully address temporal misalignment, limited controllability, and incomplete scripting.
What would settle it
A test on MAVINSet where generated sequences still exhibit audio-visual misalignment across shot boundaries or inconsistent character identities and timbres would show the proposed mechanisms fail to resolve the problems.
Figures

read the original abstract
While recent generative models produce high-fidelity videos, they struggle with the complex narrative control required for coherent multi-shot audio-visual generation. Existing methods suffer from temporal misalignment, limited controllability, and incomplete scripting. In this paper, we propose MAVIN, the first framework for multi-shot audio-visual generation with customized narrative control. To resolve temporal misalignment, we propose boundary-aware attention, which leverages hierarchical captions and boundary-aware token routing to render audio-visual elements within their respective temporal boundaries. To improve the controllability for multi-subject scenarios, we propose ID-aware propagation, utilizing identity embeddings and an identity-aware mask to bind specific identities to consistent visual appearances and vocal timbres. To provide comprehensive audio-visual narratives, we present a multi-agent scripting pipeline to transform free-form user inputs into hierarchical captions. Furthermore, we construct MAVINSet, a multi-shot audio-visual dataset for robust training and evaluation. Extensive experiments demonstrate that MAVIN achieves state-of-the-art performance, opening up a new avenue for integrating generative models into professional filmmaking workflows.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes MAVIN as the first framework for multi-shot audio-visual generation with customized narrative control. It introduces boundary-aware attention (leveraging hierarchical captions and boundary-aware token routing) to address temporal misalignment, ID-aware propagation (using identity embeddings and an identity-aware mask) to improve controllability for multi-subject scenarios, a multi-agent scripting pipeline to generate hierarchical captions from free-form inputs, and the MAVINSet dataset for training and evaluation. The paper asserts that extensive experiments demonstrate state-of-the-art performance.
Significance. If the proposed components are shown to deliver the claimed improvements in temporal consistency, identity binding, and narrative completeness, the work could open practical pathways for controllable generative models in professional audio-visual production workflows.
major comments (3)
- [Abstract] Abstract: The claim that boundary-aware attention resolves temporal misalignment rests on the unverified assertion that 'boundary-aware token routing' enforces per-boundary isolation; no mechanism (e.g., hard masking, explicit boundary tokens, or leakage-prevention analysis) is described that would guarantee no cross-boundary leakage, which is load-bearing for the central misalignment-resolution claim.
- [Abstract] Abstract: The ID-aware propagation is asserted to 'bind specific identities to consistent visual appearances and vocal timbres' via an 'identity-aware mask,' yet no details are given on how the mask prevents identity drift across shots (soft weighting vs. hard enforcement), undermining the controllability claim for multi-subject scenarios.
- [Abstract] Abstract: The assertion of 'state-of-the-art performance' and 'extensive experiments' is made without reference to any metrics, baselines, quantitative results, error bars, or dataset statistics, making it impossible to evaluate whether the proposed methods actually outperform prior work.
minor comments (1)
- [Abstract] The abstract uses several technical terms (boundary-aware token routing, identity-aware mask, hierarchical captions) without initial definitions or forward references to where they are formalized in the manuscript.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback focused on the abstract. We agree that the abstract would benefit from additional detail on the mechanisms and results to better support its claims. We will revise the abstract accordingly while ensuring the changes remain concise. Below we respond to each major comment.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that boundary-aware attention resolves temporal misalignment rests on the unverified assertion that 'boundary-aware token routing' enforces per-boundary isolation; no mechanism (e.g., hard masking, explicit boundary tokens, or leakage-prevention analysis) is described that would guarantee no cross-boundary leakage, which is load-bearing for the central misalignment-resolution claim.
Authors: We agree that the abstract, being concise, does not describe the implementation details of boundary-aware token routing or how it enforces isolation. The full manuscript provides these details in the methods section. To address the concern, we will revise the abstract to include a brief reference to the isolation mechanism as presented in the paper body. revision: yes
-
Referee: [Abstract] Abstract: The ID-aware propagation is asserted to 'bind specific identities to consistent visual appearances and vocal timbres' via an 'identity-aware mask,' yet no details are given on how the mask prevents identity drift across shots (soft weighting vs. hard enforcement), undermining the controllability claim for multi-subject scenarios.
Authors: We agree that the abstract does not specify how the identity-aware mask operates to prevent drift. The manuscript describes the identity embeddings and mask in the technical sections. We will revise the abstract to briefly clarify the mask's role in maintaining consistency across shots. revision: yes
-
Referee: [Abstract] Abstract: The assertion of 'state-of-the-art performance' and 'extensive experiments' is made without reference to any metrics, baselines, quantitative results, error bars, or dataset statistics, making it impossible to evaluate whether the proposed methods actually outperform prior work.
Authors: We agree that the abstract summarizes without citing specific metrics or results. The full manuscript presents the quantitative evaluation, baselines, metrics, error bars, and dataset statistics in the experiments section. We will revise the abstract to include a short reference to the key performance outcomes. revision: yes
Circularity Check
No circularity: framework components and dataset are independently specified
full rationale
The paper introduces boundary-aware attention, ID-aware propagation, a multi-agent scripting pipeline, and MAVINSet dataset as novel contributions without any equations, fitted parameters, or derivations that reduce to their own inputs. Claims of resolving misalignment and improving controllability are presented as design choices evaluated via experiments on the new dataset, with no self-citation load-bearing steps or renamings of prior results. The derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: Asian Conference on Computer Vision (2020)
Bain, M., Nagrani, A., Brown, A., Zisserman, A.: Condensed movies: Story based retrieval with contextual embeddings. In: Asian Conference on Computer Vision (2020)
2020
-
[2]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (2024)
Cai, S., Ceylan, D., Gadelha, M., Huang, C.H.P., Wang, T.Y., Wetzstein, G.: Generative rendering: Controllable 4D-guided video generation with 2D diffusion models. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (2024)
2024
-
[3]
In: European Conference on Computer Vision (2020)
Chatterjee, M., Cherian, A.: Sound2Sight: Generating visual dynamics from sound and context. In: European Conference on Computer Vision (2020)
2020
-
[4]
IEEE International Conference on Acoustics, Speech and Signal Processing (2020)
Chen, H., Xie, W., Vedaldi, A., Zisserman, A.: VGGSound: A large-scale audio- visual dataset. IEEE International Conference on Acoustics, Speech and Signal Processing (2020)
2020
-
[5]
Advances in Neural Information Processing Systems (2024)
Chen, K., Li, X., Li, Y., Tong, Y., Wu, J., Zeng, Y., Zhang, J., Zhou, Q.: Mo- tionBooth: Motion-aware customized text-to-video generation. Advances in Neural Information Processing Systems (2024)
2024
-
[6]
IEEE Journal of Selected Topics in Signal Processing (2022)
Chen,S.,Wang,C.,Chen,Z.,Wu,Y.,Liu,S.,Chen,Z.,Li,J.,Kanda,N.,Yoshioka, T., Xiao, X., et al.: WavLM: Large-scale self-supervised pre-training for full stack speech processing. IEEE Journal of Selected Topics in Signal Processing (2022)
2022
-
[7]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (2025)
Chen, T.S., Siarohin, A., Menapace, W., Fang, Y., Lee, K.S., Skorokhodov, I., Aberman, K., Zhu, J.Y., Yang, M.H., Tulyakov, S.: Multi-subject open-set person- alization in video generation. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (2025)
2025
-
[8]
In: Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (2025)
Chen, Y., Niu, Z., Ma, Z., Deng, K., Wang, C., JianZhao, J., Yu, K., Chen, X.: F5-TTS: A fairytaler that fakes fluent and faithful speech with flow matching. In: Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (2025)
2025
-
[9]
Cheng, H.K., Ishii, M., Hayakawa, A., Shibuya, T., Schwing, A., Mitsufuji, Y.: MMAudio: Taming multimodal joint training for high-quality video-to-audio syn- thesis.IEEE/CVFConferenceonComputerVisionandPatternRecognition(2025)
2025
-
[10]
In: Asian Conference on Computer Vision (2016)
Chung, J.S., Zisserman, A.: Out of time: automated lip sync in the wild. In: Asian Conference on Computer Vision (2016)
2016
-
[11]
Comanici, G., Bieber, E., Schaekermann, M., Pasupat, I., Sachdeva, N., Dhillon, I., Blistein, M., Ram, O., Zhang, D., Rosen, E., et al.: Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. arXiv preprint arXiv:2507.06261 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (2019)
Deng, J., Guo, J., Xue, N., Zafeiriou, S.: ArcFace: Additive angular margin loss for deep face recognition. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (2019)
2019
-
[13]
Du, Z., Chen, Q., Zhang, S., Hu, K., Lu, H., Yang, Y., Hu, H., Zheng, S., Gu, Y., Ma, Z., et al.: CosyVoice: A scalable multilingual zero-shot text-to-speech synthe- sizer based on supervised semantic tokens. arXiv preprint arXiv:2407.05407 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
ElevenLabs: Introducing Scribe v2.https://elevenlabs.io/blog/introducing- scribe-v2(2026), accessed: 2026-03-05
2026
-
[15]
In: IEEE International Conference on Acoustics, Speech and Signal Processing (2023)
Elizalde, B., Deshmukh, S., Al Ismail, M., Wang, H.: CLAP: learning audio con- cepts from natural language supervision. In: IEEE International Conference on Acoustics, Speech and Signal Processing (2023)
2023
-
[16]
Seedance 1.0: Exploring the Boundaries of Video Generation Models
Gao, Y., Guo, H., Hoang, T., Huang, W., Jiang, L., Kong, F., Li, H., Li, J., Li, L., Li, X., et al.: Seedance 1.0: Exploring the boundaries of video generation models. arXiv preprint arXiv:2506.09113 (2025) 26 K. Liu et al
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Gemmeke, J.F., Ellis, D.P., Freedman, D., Jansen, A., Lawrence, W., Moore, R.C., Plakal, M., Ritter, M.: Audio set: An ontology and human-labeled dataset for audio events.In:IEEEinternationalconferenceonacoustics,speechandsignalprocessing (2017)
2017
-
[18]
IEEE/CVF Conference on Computer Vision and Pattern Recognition (2025)
Geng, D., Herrmann, C., Hur, J., Cole, F., Zhang, S., Pfaff, T., Lopez-Guevara, T., Aytar, Y., Rubinstein, M., Sun, C., Wang, O., Owens, A., Sun, D.: Motion Prompt- ing: Controlling video generation with motion trajectories. IEEE/CVF Conference on Computer Vision and Pattern Recognition (2025)
2025
-
[19]
arXiv preprint arXiv:2406.10221 (2025)
Ghermi, R., Wang, X., Kalogeiton, V., Laptev, I.: Long Story Short: Story-level video understanding from 20k short films. arXiv preprint arXiv:2406.10221 (2025)
-
[20]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (2023)
Girdhar, R., El-Nouby, A., Liu, Z., Singh, M., Alwala, K.V., Joulin, A., Misra, I.: Imagebind: One embedding space to bind them all. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (2023)
2023
-
[21]
LTX-2: Efficient Joint Audio-Visual Foundation Model
HaCohen, Y., Brazowski, B., Chiprut, N., Bitterman, Y., Kvochko, A., Berkowitz, A., Shalem, D., Lifschitz, D., Moshe, D., Porat, E., et al.: LTX-2: Efficient joint audio-visual foundation model. arXiv preprint arXiv:2601.03233 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[22]
In: International Conference on Computer Vision (2025)
Haji-Ali, M., Menapace, W., Siarohin, A., Skorokhodov, I., Canberk, A., Lee, K.S., Ordonez, V., Tulyakov, S.: AV-Link: Temporally-aligned diffusion features for cross-modal audio-video generation. In: International Conference on Computer Vision (2025)
2025
-
[23]
In: ACM SIGGRAPH Asia Conference Papers (2025)
He,J.,Liu,H.,Li,J.,Huang,Z.,Yu,Q.,Ouyang,W.,Liu,Z.:Cut2next:Generating next shot via in-context tuning. In: ACM SIGGRAPH Asia Conference Papers (2025)
2025
-
[24]
IEEE/CVF Conference on Computer Vision and Pattern Recognition (2025)
Henschel, R., Khachatryan, L., Poghosyan, H., Hayrapetyan, D., Tadevosyan, V., Wang, Z., Navasardyan, S., Shi, H.: Streamingt2v: Consistent, dynamic, and ex- tendable long video generation from text. IEEE/CVF Conference on Computer Vision and Pattern Recognition (2025)
2025
-
[25]
In: International Conference on Learning Representations (2023)
Hong, W., Ding, M., Zheng, W., Liu, X., Tang, J.: CogVideo: Large-scale pretrain- ing for text-to-video generation via transformers. In: International Conference on Learning Representations (2023)
2023
-
[26]
Hu, H., Zhu, X., He, T., Guo, D., Zhang, B., Wang, X., Guo, Z., Jiang, Z., Hao, H., Guo, Z., et al.: Qwen3-TTS technical report. arXiv preprint arXiv:2601.15621 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[27]
arXiv preprint arXiv:2410.23775 (2024)
Huang,L.,Wang,W.,Wu,Z.F.,Shi,Y.,Dou,H.,Liang,C.,Feng,Y.,Liu,Y.,Zhou, J.: In-context lora for diffusion transformers. arXiv preprint arXiv:2410.23775 (2024)
-
[28]
In: IEEE/CVF Conference on Computer Vision and Pattern Recog- nition (2024)
Huang, Z., He, Y., Yu, J., Zhang, F., Si, C., Jiang, Y., Zhang, Y., Wu, T., Jin, Q., Chanpaisit, N., et al.: VBench: Comprehensive benchmark suite for video genera- tive models. In: IEEE/CVF Conference on Computer Vision and Pattern Recog- nition (2024)
2024
-
[29]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (2025)
Jiang, Z., Han, Z., Mao, C., Zhang, J., Pan, Y., Liu, Y.: VACE: All-in-one video creation and editing. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (2025)
2025
-
[30]
arXiv preprint arXiv:2403.03100 (2024)
Ju, Z., Wang, Y., Shen, K., Tan, X., Xin, D., Yang, D., Liu, Y., Leng, Y., Song, K., Tang, S., et al.: NaturalSpeech 3: Zero-shot speech synthesis with factorized codec and diffusion models. arXiv preprint arXiv:2403.03100 (2024)
-
[31]
IEEE/CVF Conference on Computer Vision and Pattern Recognition (2025) MAVIN: Multi-Shot Audio-Visual Generation 27
Kara, O., Singh, K.K., Liu, F., Ceylan, D., Rehg, J.M., Hinz, T.: Shotadapter: Text-to-multi-shot video generation with diffusion models. IEEE/CVF Conference on Computer Vision and Pattern Recognition (2025) MAVIN: Multi-Shot Audio-Visual Generation 27
2025
-
[32]
Fr\'echet Audio Distance: A Metric for Evaluating Music Enhancement Algorithms
Kilgour, K., Zuluaga, M., Roblek, D., Sharifi, M.: Fr\’echet audio distance: A met- ric for evaluating music enhancement algorithms. arXiv preprint arXiv:1812.08466 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[33]
IEEE/CVF Conference on Computer Vision and Pattern Recog- nition (2025)
Kushwaha, S.S., Tian, Y.: VinTAGe: Joint video and text conditioning for holistic audio generation. IEEE/CVF Conference on Computer Vision and Pattern Recog- nition (2025)
2025
-
[34]
IEEE/CVF Conference on Computer Vision and Pattern Recognition (2025)
Lei, G., Wang, C., Zhang, R., Wang, Y., Li, H., Xu, W.: AnimateAnything: Con- sistent and controllable animation for video generation. IEEE/CVF Conference on Computer Vision and Pattern Recognition (2025)
2025
-
[35]
IEEE/CVF Conference on Computer Vision and Pattern Recognition (2025)
Li, H., Xu, M., Zhan, Y., Mu, S., Li, J., Cheng, K., Chen, Y., Chen, T., Ye, M., Wang, J., Zhu, S.: Openhumanvid: A large-scale high-quality dataset for enhancing human-centric video generation. IEEE/CVF Conference on Computer Vision and Pattern Recognition (2025)
2025
-
[36]
In: International Conference on Computer Vision (2025)
Li, Q., Xing, Z., Wang, R., Zhang, H., Dai, Q., Wu, Z.: MagicMotion: Control- lable video generation with dense-to-sparse trajectory guidance. In: International Conference on Computer Vision (2025)
2025
-
[37]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (2025)
Li, Z., Rahmani, H., Ke, Q., Liu, J.: LongDiff: Training-free long video generation in one go. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (2025)
2025
-
[38]
In: Conference on Language Modeling (2024)
Lin, H., Zala, A., Cho, J., Bansal, M.: VideoDirectorGPT: Consistent multi-scene video generation via llm-guided planning. In: Conference on Language Modeling (2024)
2024
-
[39]
Flow Matching for Generative Modeling
Lipman, Y., Chen, R.T., Ben-Hamu, H., Nickel, M., Le, M.: Flow matching for generative modeling. arXiv preprint arXiv:2210.02747 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[40]
arXiv preprint arXiv:2301.12503 (2023)
Liu, H., Chen, Z., Yuan, Y., Mei, X., Liu, X., Mandic, D., Wang, W., Plumbley, M.D.: AudioLDM: Text-to-audio generation with latent diffusion models. arXiv preprint arXiv:2301.12503 (2023)
-
[41]
arXiv preprint arXiv:2503.23377 (2025)
Liu, K., Li, W., Chen, L., Wu, S., Zheng, Y., Ji, J., Zhou, F., Luo, J., Liu, Z., Fei, H., Chua, T.S.: JavisDiT: Joint audio-video diffusion transformer with hierarchical spatio-temporal prior synchronization. arXiv preprint arXiv:2503.23377 (2025)
-
[42]
arXiv preprint arXiv:2602.19163 (2026)
Liu, K., Zheng, Y., Wang, K., Wu, S., Zhang, R., Luo, J., Hatzinakos, D., Liu, Z., Fei, H., Chua, T.S.: JavisDiT++: Unified modeling and optimization for joint audio-video generation. arXiv preprint arXiv:2602.19163 (2026)
-
[43]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (2025)
Liu, L., Ma, T., Li, B., Chen, Z., Liu, J., Li, G., Zhou, S., He, Q., Wu, X.: Phantom: Subject-consistent video generation via cross-modal alignment. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (2025)
2025
-
[44]
European Conference on Computer Vision (2024)
Long, F., Qiu, Z., Yao, T., Mei, T.: VideoStudio: Generating consistent-content and multi-scene videos. European Conference on Computer Vision (2024)
2024
-
[45]
Decoupled Weight Decay Regularization
Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[46]
arXiv (2025)
Low, C., Wang, W., Katyal, C.: Ovi: Twin backbone cross-modal fusion for audio- video generation. arXiv (2025)
2025
-
[47]
Advances in Neural Information Processing Systems (2023)
Luo, S., Yan, C., Hu, C., Zhao, H.: Diff-Foley: Synchronized video-to-audio syn- thesis with latent diffusion models. Advances in Neural Information Processing Systems (2023)
2023
-
[48]
Advances in Neural Information Pro- cessing Systems (2024)
Montanaro, A., Savant Aira, L., Aiello, E., Valsesia, D., Magli, E.: Motioncraft: Physics-based zero-shot video generation. Advances in Neural Information Pro- cessing Systems (2024)
2024
-
[49]
arXiv preprint arXiv:2601.01568 (2026) 28 K
Qiang, C., Wang, J., Wang, X., Yin, K., Guo, Y.: MM-Sonate: Multimodal controllable audio-video generation with zero-shot voice cloning. arXiv preprint arXiv:2601.01568 (2026) 28 K. Liu et al
-
[50]
In: International Conference on Machine Learning (2023)
Radford,A.,Kim,J.W.,Xu,T.,Brockman,G.,McLeavey,C.,Sutskever,I.:Robust speech recognition via large-scale weak supervision. In: International Conference on Machine Learning (2023)
2023
-
[51]
SAM 2: Segment Anything in Images and Videos
Ravi, N., Gabeur, V., Hu, Y.T., Hu, R., Ryali, C., Ma, T., Khedr, H., Rädle, R., Rolland, C., Gustafson, L., et al.: SAM 2: Segment anything in images and videos. arXiv preprint arXiv:2408.00714 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[52]
IEEE/CVF Conference on Computer Vision and Pattern Recognition (2023)
Ruan, L., Ma, Y., Yang, H., He, H., Liu, B., Fu, J., Yuan, N.J., Jin, Q., Guo, B.: MM-Diffusion: Learning multi-modal diffusion models for joint audio and video generation. IEEE/CVF Conference on Computer Vision and Pattern Recognition (2023)
2023
-
[53]
com / christophschuhmann/improved-aesthetic-predictor(2022)
Schuhmann, C.: Improved aesthetic predictor.https : / / github . com / christophschuhmann/improved-aesthetic-predictor(2022)
2022
-
[54]
Shan, S., Li, Q., Cui, Y., Yang, M., Wang, Y., Yang, Q., Zhou, J., Zhong, Z.: HunyuanVideo-foley: Multimodal diffusion with representation alignment for high- fidelity foley audio generation. arXiv preprint arXiv:2508.16930 (2025)
-
[55]
arXiv preprint arXiv:2512.18099 (2025)
Shi, B., Tjandra, A., Hoffman, J., Wang, H., Wu, Y.C., Gao, L., Richter, J., Le, M., Vyas, A., Chen, S., et al.: SAM Audio: Segment anything in audio. arXiv preprint arXiv:2512.18099 (2025)
-
[56]
In: Cai, J., Kankanhalli, M.S., Prabhakaran, B., Boll, S., Subramanian, R., Zheng, L., Singh, V.K., César, P., Xie, L., Xu, D
Soucek, T., Lokoc, J.: Transnet V2: an effective deep network architecture for fast shot transition detection. In: Cai, J., Kankanhalli, M.S., Prabhakaran, B., Boll, S., Subramanian, R., Zheng, L., Singh, V.K., César, P., Xie, L., Xu, D. (eds.) ACM International Conference on Multimedia (2024)
2024
-
[57]
ACM Interna- tional Conference on Multimedia (2024)
Sun, M., Wang, W., Qiao, Y., Sun, J., Qin, Z., Guo, L., Zhu, X., Liu, J.: Mm-ldm: Multi-modal latent diffusion model for sounding video generation. ACM Interna- tional Conference on Multimedia (2024)
2024
-
[58]
arXiv preprint arXiv:2406.16260 (2024)
Tan, Z., Yang, X., Liu, S., Wang, X.: Video-infinity: Distributed long video gener- ation. arXiv preprint arXiv:2406.16260 (2024)
-
[59]
arXiv preprint arXiv:2602.08794 (2026)
Team, O., Yu, D., Chen, M., Chen, Q., Luo, Q., Wu, Q., Cheng, Q., Li, R., Liang, T., Zhang, W., et al.: MOVA: Towards scalable and synchronized video-audio gen- eration. arXiv preprint arXiv:2602.08794 (2026)
-
[60]
In: European Conference on Computer Vision (2020)
Teed, Z., Deng, J.: RAFT: Recurrent all-pairs field transforms for optical flow. In: European Conference on Computer Vision (2020)
2020
-
[61]
Meta Audiobox Aesthetics: Unified Automatic Quality Assessment for Speech, Music, and Sound
Tjandra, A., Wu, Y.C., Guo, B., Hoffman, J., Ellis, B., Vyas, A., Shi, B., Chen, S., Le, M., Zacharov, N., Wood, C., Lee, A., Hsu, W.N.: Meta Audiobox Aesthetics: Unified automatic quality assessment for speech, music, and sound. arXiv preprint arXiv:2502.05139 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[62]
Towards Accurate Generative Models of Video: A New Metric & Challenges
Unterthiner, T., Van Steenkiste, S., Kurach, K., Marinier, R., Michalski, M., Gelly, S.: Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:1812.01717 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[63]
Wan: Open and Advanced Large-Scale Video Generative Models
Wan, T., Wang, A., Ai, B., Wen, B., Mao, C., Xie, C.W., Chen, D., Yu, F., Zhao, H., Yang, J., et al.: Wan: Open and advanced large-scale video generative models. arXiv preprint arXiv:2503.20314 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[64]
arXiv preprint arXiv:2509.06155 (2025)
Wang, D., Zuo, W., Li, A., Chen, L.H., Liao, X., Zhou, D., Yin, Z., Dai, X., Jiang, D., Yu, G.: Universe-1: Unified audio-video generation via stitching of experts. arXiv preprint arXiv:2509.06155 (2025)
-
[65]
In: Advances in Neural Informa- tion Processing Systems (2025)
Wang, J., Sheng, H., Cai, S., Zhang, W., Yan, C., Feng, Y., Deng, B., Ye, J.: EchoShot: Multi-shot portrait video generation. In: Advances in Neural Informa- tion Processing Systems (2025)
2025
-
[66]
arXiv e-prints pp
Wang, J., Qiang, C., Guo, Y., Wang, Y., Zeng, X., Deng, F.: Apollo: Unified multi- task audio-video joint generation. arXiv e-prints pp. arXiv–2601 (2026) MAVIN: Multi-Shot Audio-Visual Generation 29
2026
-
[67]
ACM International Conference on Multimedia (2025)
Wang, K., Deng, S., Shi, J., Hatzinakos, D., Tian, Y.: Av-dit: Taming image diffu- sion transformers for efficient joint audio and video generation. ACM International Conference on Multimedia (2025)
2025
-
[68]
InternVid: A Large-scale Video-Text Dataset for Multimodal Understanding and Generation
Wang, Y., He, Y., Li, Y., Li, K., Yu, J., Ma, X., Li, X., Chen, G., Chen, X., Wang, Y., et al.: InternVid: A large-scale video-text dataset for multimodal understanding and generation. arXiv preprint arXiv:2307.06942 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[69]
ACM SIG- GRAPH Conference Papers (2024)
Wang, Z., Yuan, Z., Wang, X., Li, Y., Chen, T., Xia, M., Luo, P., Shan, Y.: Mo- tionCtrl: A unified and flexible motion controller for video generation. ACM SIG- GRAPH Conference Papers (2024)
2024
-
[70]
In: Advances in Neural Information Processing Systems (2025)
Weng, S., Zheng, H., Chang, Z., Li, S., Shi, B., Wang, X.: Audio-sync video gen- eration with multi-stream temporal control. In: Advances in Neural Information Processing Systems (2025)
2025
-
[71]
wiseman: py-webrtcvad.https://github.com/wiseman/py-webrtcvad(2016)
2016
-
[72]
HunyuanVideo 1.5 Technical Report
Wu, B., Zou, C., Li, C., Huang, D., Yang, F., Tan, H., Peng, J., Wu, J., Xiong, J., Jiang, J., et al.: HunyuanVideo 1.5 technical report. arXiv preprint arXiv:2511.18870 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[73]
Wu, C., Li, J., Zhou, J., Lin, J., Gao, K., Yan, K., ming Yin, S., Bai, S., Xu, X., Chen, Y., Chen, Y., Tang, Z., Zhang, Z., Wang, Z., Yang, A., Yu, B., Cheng, C., Liu, D., Li, D., Zhang, H., Meng, H., Wei, H., Ni, J., Chen, K., Cao, K., Peng, L., Qu, L., Wu, M., Wang, P., Yu, S., Wen, T., Feng, W., Xu, X., Wang, Y., Zhang, Y., Zhu, Y., Wu, Y., Cai, Y., L...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[74]
IEEE/CVF Con- ference on Computer Vision and Pattern Recognition (2022)
Wu, H., Chen, K., Luo, Y., Qiao, R., Ren, B., Liu, H., Xie, W., Shen, L.: Scene consistency representation learning for video scene segmentation. IEEE/CVF Con- ference on Computer Vision and Pattern Recognition (2022)
2022
-
[75]
IEEE/CVF Conference on Computer Vision and Pattern Recognition (2025)
Wu, W., Liu, M., Zhu, Z., Xia, X., Feng, H., Wang, W., Lin, K.Q., Shen, C., Shou, M.Z.: Moviebench: A hierarchical movie level dataset for long video generation. IEEE/CVF Conference on Computer Vision and Pattern Recognition (2025)
2025
-
[76]
arXiv preprint arXiv:2503.07314 (2025)
Wu, W., Zhu, Z., Shou, M.Z.: Automated movie generation via multi-agent CoT planning. arXiv preprint arXiv:2503.07314 (2025)
-
[77]
arXiv preprint arXiv:2508.11484 (2025)
Wu, X., Gao, B., Qiao, Y., Wang, Y., Chen, X.: CineTrans: Learning to gener- ate videos with cinematic transitions via masked diffusion models. arXiv preprint arXiv:2508.11484 (2025)
-
[78]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (2025)
Wu, Z., Siarohin, A., Menapace, W., Skorokhodov, I., Fang, Y., Chordia, V., Gilitschenski, I., Tulyakov, S.: Mind the time: Temporally-controlled multi-event video generation. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (2025)
2025
-
[79]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2024)
Xing, Y., He, Y., Tian, Z., Wang, X., Chen, Q.: Seeing and hearing: Open- domain visual-audio generation with diffusion latent aligners. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2024)
2024
-
[80]
Xu, J., Guo, Z., Hu, H., Chu, Y., Wang, X., He, J., Wang, Y., Shi, X., He, T., Zhu, X., et al.: Qwen3-Omni technical report. arXiv preprint arXiv:2509.17765 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.