PruneGround: Plug-and-play Spatial Pruning for 3D Visual Grounding
Pith reviewed 2026-07-01 06:39 UTC · model grok-4.3
The pith
Language-guided pruning of 3D point clouds to local regions enables more accurate visual grounding
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
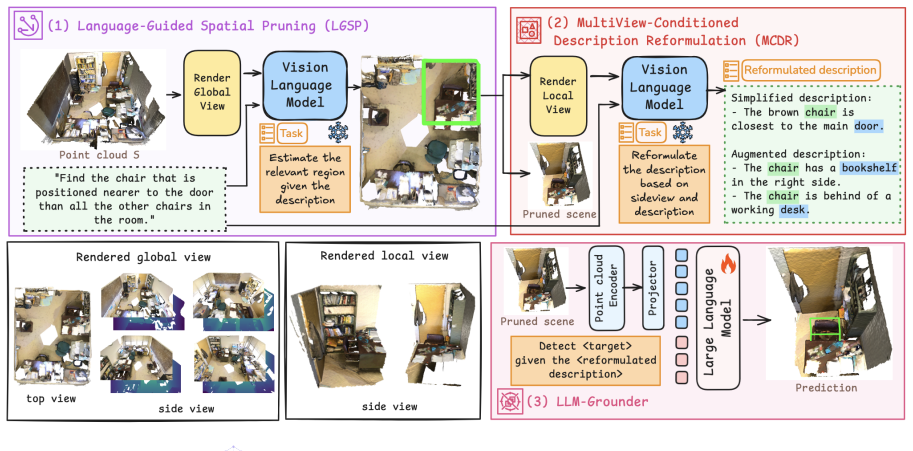
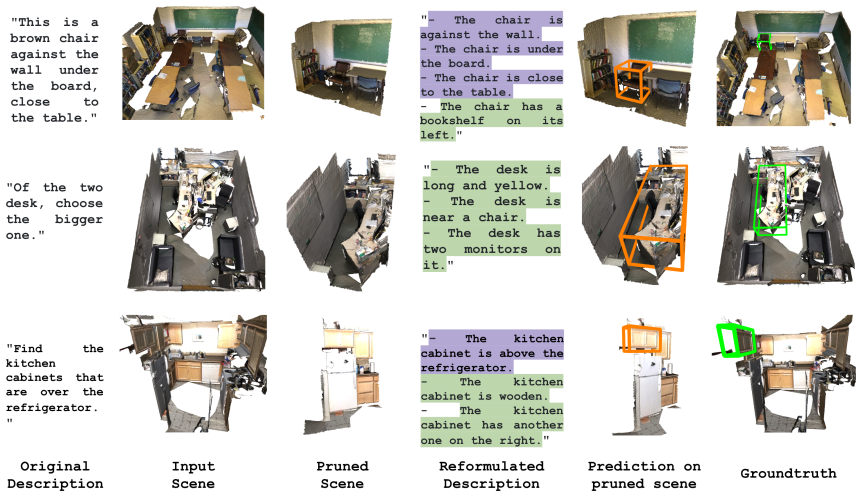
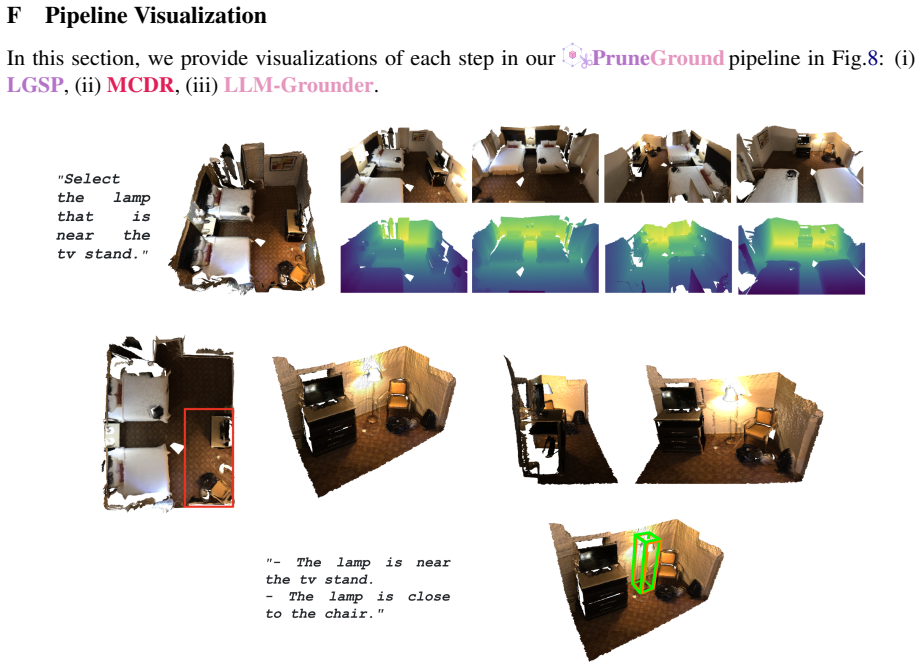
PruneGround achieves state-of-the-art results on all three ScanRefer settings and on nine out of ten Nr3D/Sr3D settings by first applying Language-Guided Spatial Pruning with a frozen VLM to restrict the point cloud to language-relevant regions, then using MultiView-Conditioned Description Reformulation to break expressions into target-anchor relations, and finally deploying LLM-Grounder to align representations inside the pruned space.
What carries the argument
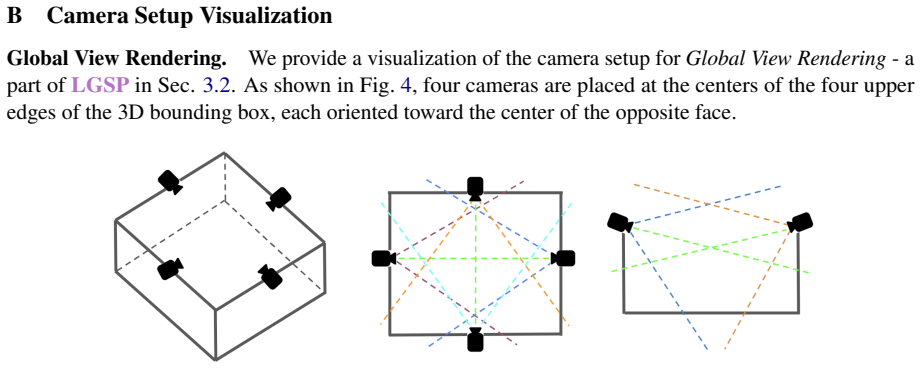
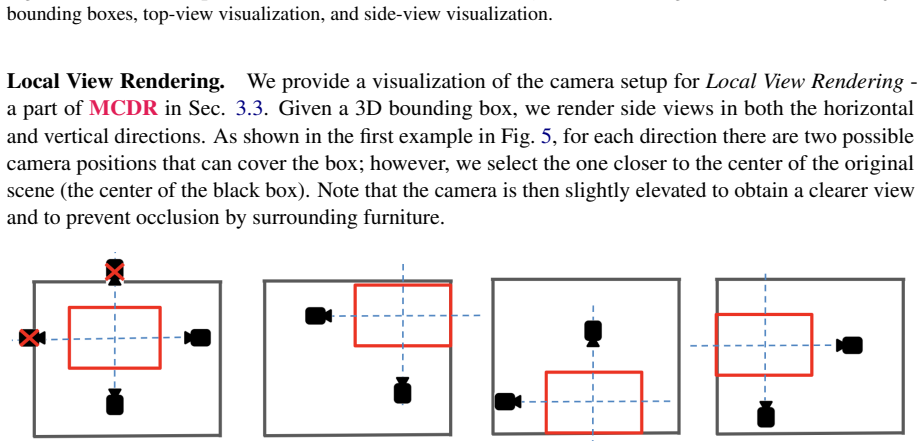
Language-Guided Spatial Pruning (LGSP), which routes the referential expression through a frozen VLM to select and retain only the relevant local region of the input point cloud
If this is right
- Computation drops because reasoning occurs only inside smaller selected regions instead of the entire point cloud
- Ambiguous predictions decrease in cluttered scenes by excluding irrelevant geometry
- The framework attaches to existing 3DVG pipelines without retraining the core model
- Performance improves on standard benchmarks without requiring full-scene processing
Where Pith is reading between the lines
- The same local-region selection step could be inserted into other 3D tasks such as dense captioning or navigation
- On-device or real-time systems may become feasible once scene size is reduced before heavy LLM calls
- Dynamic environments could be tested by checking whether language-relevant regions remain stable across short time windows
Load-bearing premise
Many referential expressions depend on restricted local spatial regions rather than the full scene
What would settle it
Running the identical downstream grounding model on the same ScanRefer test scenes once with LGSP pruning applied and once without, and finding equal or lower accuracy when pruning is used
Figures




read the original abstract
3D Visual Grounding (3DVG) aims to localize target objects in 3D scenes given natural language descriptions. Existing approaches typically perform reasoning over the entire scene, leading to ambiguous predictions and high computational cost, especially in cluttered environments. We observe that many referential expressions rely on local spatial context and often correspond to restricted spatial regions rather than the full scene. Motivated by this insight, we propose PruneGround, an effective plug-and-play framework for 3DVG built upon three key components. First, we introduce Language-Guided Spatial Pruning (LGSP), which leverages a frozen Vision Language Model (VLM) to identify language-relevant regions, thereby reducing spatial computation and grounding candidates in the narrower search space. Second, we propose MultiView-Conditioned Description Reformulation (MCDR), which decomposes complex expressions into simplified target-anchor relations and augments missing spatial cues through multi-view reasoning. Finally, we propose LLM-Grounder, which repurposes a detection-pretrained spatial LLM into a language-conditioned grounding model by aligning point cloud and linguistic representations within the pruned region. Extensive experiments on the three most popular point cloud benchmarks demonstrate that our method achieves state-of-the-art results on all three ScanRefer settings and on 9 out of 10 Nr3D/Sr3D settings. Code and models are publicly available: https://github.com/leduckhai/PruneGround
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PruneGround, a plug-and-play framework for 3D visual grounding consisting of Language-Guided Spatial Pruning (LGSP) that uses a frozen VLM to restrict the search space to language-relevant regions, MultiView-Conditioned Description Reformulation (MCDR) to decompose expressions into target-anchor relations, and LLM-Grounder to align point-cloud and language features inside the pruned region. It reports state-of-the-art results on all three ScanRefer settings and 9/10 Nr3D/Sr3D settings across three point-cloud benchmarks, with public code release.
Significance. If the empirical claims hold after verification of the missing controls, the work would be significant for demonstrating that spatial pruning via off-the-shelf VLMs can simultaneously improve accuracy and efficiency in 3DVG without task-specific training of the pruner. The public code release is a clear strength that enables direct reproduction and extension.
major comments (2)
- [Abstract / §3] Abstract and §3 (LGSP description): no pruning-recall, region-accuracy, or failure-rate statistic is reported for LGSP. Because the subsequent MCDR and LLM-Grounder stages operate exclusively inside the pruned region, the absence of this metric leaves open the possibility that the reported SOTA numbers rely on an unstated recovery mechanism or on cases where LGSP already contains the referent; an ablation isolating LGSP accuracy from the rest of the pipeline is required to support the central performance claim.
- [§4] §4 (Experiments): the SOTA claims rest on benchmark numbers whose experimental details, error bars, ablation controls, and per-setting breakdowns cannot be inspected from the provided text. Without these, the claim that PruneGround outperforms prior methods on 12 of 13 settings cannot be verified as load-bearing evidence for the framework.
minor comments (1)
- [§3] Notation for the pruned region (e.g., how the VLM output is converted into a 3D bounding volume) is introduced without an explicit equation or diagram; a single equation or figure panel would clarify the interface between LGSP and LLM-Grounder.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments below and commit to revisions that strengthen the empirical support for our claims.
read point-by-point responses
-
Referee: [Abstract / §3] Abstract and §3 (LGSP description): no pruning-recall, region-accuracy, or failure-rate statistic is reported for LGSP. Because the subsequent MCDR and LLM-Grounder stages operate exclusively inside the pruned region, the absence of this metric leaves open the possibility that the reported SOTA numbers rely on an unstated recovery mechanism or on cases where LGSP already contains the referent; an ablation isolating LGSP accuracy from the rest of the pipeline is required to support the central performance claim.
Authors: We agree that these metrics are absent and that an isolating ablation is needed. In the revised manuscript we will add a dedicated table reporting LGSP pruning recall (fraction of targets retained in the pruned region), region accuracy, and failure rates on ScanRefer, Nr3D, and Sr3D. We will also insert an ablation that compares full PruneGround against (i) no pruning, (ii) LGSP alone, and (iii) oracle pruning, thereby separating LGSP’s contribution from the downstream stages. revision: yes
-
Referee: [§4] §4 (Experiments): the SOTA claims rest on benchmark numbers whose experimental details, error bars, ablation controls, and per-setting breakdowns cannot be inspected from the provided text. Without these, the claim that PruneGround outperforms prior methods on 12 of 13 settings cannot be verified as load-bearing evidence for the framework.
Authors: We acknowledge the current text lacks sufficient detail for independent verification. The revision will expand §4 with: full hyper-parameter tables and training protocols, error bars from at least three random seeds, complete per-setting results for all Nr3D/Sr3D splits, and additional component-wise ablations. The already-released code will be updated with the exact evaluation scripts used for the reported numbers. revision: yes
Circularity Check
No circularity; empirical SOTA claims on public benchmarks with no derivations or self-referential reductions
full rationale
The paper introduces a plug-and-play 3DVG framework (LGSP + MCDR + LLM-Grounder) motivated by an observation about local spatial context in referential expressions. All central claims consist of reported performance numbers on the external public benchmarks ScanRefer, Nr3D, and Sr3D. No equations, parameter-fitting steps, uniqueness theorems, or self-citations appear in the provided text that would reduce any result to an input by construction. The evaluation is performed on standard, independently maintained datasets, rendering the claims directly falsifiable without circular dependence on the method's own definitions or prior author work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Many referential expressions rely on local spatial context and often correspond to restricted spatial regions rather than the full scene.
Reference graph
Works this paper leans on
-
[1]
Computer Vision--ECCV 2020: 16th European Conference, Glasgow, UK, August 23--28, 2020, Proceedings, Part XX 16 , pages=
Scanrefer: 3d object localization in rgb-d scans using natural language , author=. Computer Vision--ECCV 2020: 16th European Conference, Glasgow, UK, August 23--28, 2020, Proceedings, Part XX 16 , pages=. 2020 , organization=
2020
-
[2]
European Conference on Computer Vision , year=
ReferIt3D: Neural Listeners for Fine-Grained 3D Object Identification in Real-World Scenes , author=. European Conference on Computer Vision , year=
-
[3]
2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , year=
ScanNet: Richly-Annotated 3D Reconstructions of Indoor Scenes , author=. 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , year=
2017
-
[4]
North American Chapter of the Association for Computational Linguistics , year=
An Examination of the Compositionality of Large Generative Vision-Language Models , author=. North American Chapter of the Association for Computational Linguistics , year=
-
[5]
AAAI Conference on Artificial Intelligence , year=
NavGPT: Explicit Reasoning in Vision-and-Language Navigation with Large Language Models , author=. AAAI Conference on Artificial Intelligence , year=
-
[6]
2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
Think Global, Act Local: Dual-scale Graph Transformer for Vision-and-Language Navigation , author=. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
2022
-
[7]
European Conference on Computer Vision , year=
ASSISTER: Assistive Navigation via Conditional Instruction Generation , author=. European Conference on Computer Vision , year=
-
[8]
Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems , year=
Assertiveness-based Agent Communication for a Personalized Medicine on Medical Imaging Diagnosis , author=. Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems , year=
2023
-
[9]
Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems , year=
AppAgent: Multimodal Agents as Smartphone Users , author=. Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems , year=
2025
-
[10]
2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
CLIP2Scene: Towards Label-efficient 3D Scene Understanding by CLIP , author=. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
2023
-
[11]
2023 IEEE/CVF International Conference on Computer Vision (ICCV) , year=
Rethinking Range View Representation for LiDAR Segmentation , author=. 2023 IEEE/CVF International Conference on Computer Vision (ICCV) , year=
2023
-
[12]
2023 IEEE/CVF International Conference on Computer Vision (ICCV) , year=
Robo3D: Towards Robust and Reliable 3D Perception against Corruptions , author=. 2023 IEEE/CVF International Conference on Computer Vision (ICCV) , year=
2023
-
[13]
2023 IEEE/CVF International Conference on Computer Vision (ICCV) , year=
XVO: Generalized Visual Odometry via Cross-Modal Self-Training , author=. 2023 IEEE/CVF International Conference on Computer Vision (ICCV) , year=
2023
-
[14]
2024 IEEE/CVF Winter Conference on Applications of Computer Vision Workshops (WACVW) , year=
Drive as You Speak: Enabling Human-Like Interaction with Large Language Models in Autonomous Vehicles , author=. 2024 IEEE/CVF Winter Conference on Applications of Computer Vision Workshops (WACVW) , year=
2024
-
[15]
Nature , year=
Dense reinforcement learning for safety validation of autonomous vehicles , author=. Nature , year=
-
[16]
2021 IEEE/CVF International Conference on Computer Vision (ICCV) , year=
InstanceRefer: Cooperative Holistic Understanding for Visual Grounding on Point Clouds through Instance Multi-level Contextual Referring , author=. 2021 IEEE/CVF International Conference on Computer Vision (ICCV) , year=
2021
-
[17]
2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
Ges3ViG: Incorporating Pointing Gestures into Language-Based 3D Visual Grounding for Embodied Reference Understanding , author=. 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
2025
-
[18]
Advances in Neural Information Processing Systems , volume=
Multi-object 3d grounding with dynamic modules and language-informed spatial attention , author=. Advances in Neural Information Processing Systems , volume=
-
[19]
Multi-Object 3D Grounding with Dynamic Modules and Language-Informed Spatial Attention , author=. Proc. NeurIPS , year=
-
[20]
2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
Multi-Attribute Interactions Matter for 3D Visual Grounding , author=. 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
2024
-
[21]
2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
MiKASA: Multi-Key-Anchor & Scene-Aware Transformer for 3D Visual Grounding , author=. 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
2024
-
[22]
2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
SeeGround: See and Ground for Zero-Shot Open-Vocabulary 3D Visual Grounding , author=. 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
2025
-
[23]
Conference on Robot Learning , year=
VLM-Grounder: A VLM Agent for Zero-Shot 3D Visual Grounding , author=. Conference on Robot Learning , year=
-
[24]
AAAI Conference on Artificial Intelligence , year=
LIBA: Language Instructed Multi-granularity Bridge Assistant for 3D Visual Grounding , author=. AAAI Conference on Artificial Intelligence , year=
-
[25]
European Conference on Computer Vision , year=
ScanReason: Empowering 3D Visual Grounding with Reasoning Capabilities , author=. European Conference on Computer Vision , year=
-
[26]
Advances in neural information processing systems , volume=
Look around and refer: 2d synthetic semantics knowledge distillation for 3d visual grounding , author=. Advances in neural information processing systems , volume=
-
[27]
2021 IEEE/CVF International Conference on Computer Vision (ICCV) , year=
SAT: 2D Semantics Assisted Training for 3D Visual Grounding , author=. 2021 IEEE/CVF International Conference on Computer Vision (ICCV) , year=
2021
-
[28]
2023 IEEE/CVF International Conference on Computer Vision (ICCV) , year=
3D-VisTA: Pre-trained Transformer for 3D Vision and Text Alignment , author=. 2023 IEEE/CVF International Conference on Computer Vision (ICCV) , year=
2023
-
[29]
AAAI Conference on Artificial Intelligence , year=
AugRefer: Advancing 3D Visual Grounding via Cross-Modal Augmentation and Spatial Relation-based Referring , author=. AAAI Conference on Artificial Intelligence , year=
-
[30]
2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
Towards CLIP-Driven Language-Free 3D Visual Grounding via 2D-3D Relational Enhancement and Consistency , author=. 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
2024
-
[31]
Neural Information Processing Systems , year=
Exploiting Contextual Objects and Relations for 3D Visual Grounding , author=. Neural Information Processing Systems , year=
-
[32]
2021 IEEE/CVF International Conference on Computer Vision (ICCV) , year=
3DVG-Transformer: Relation Modeling for Visual Grounding on Point Clouds , author=. 2021 IEEE/CVF International Conference on Computer Vision (ICCV) , year=
2021
-
[33]
International Conference on Learning Representations , volume=
Cot3dref: Chain-of-thoughts data-efficient 3d visual grounding , author=. International Conference on Learning Representations , volume=
-
[34]
European Conference on Computer Vision , pages=
Bottom up top down detection transformers for language grounding in images and point clouds , author=. European Conference on Computer Vision , pages=. 2022 , organization=
2022
-
[35]
International Conference on Machine Learning , pages=
Unifying 2D and 3D Vision-Language Understanding , author=. International Conference on Machine Learning , pages=. 2025 , organization=
2025
-
[36]
2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
3D-SPS: Single-Stage 3D Visual Grounding via Referred Point Progressive Selection , author=. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
2022
-
[37]
2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
G3-LQ: Marrying Hyperbolic Alignment with Explicit Semantic-Geometric Modeling for 3D Visual Grounding , author=. 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
2024
-
[38]
2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
EDA: Explicit Text-Decoupling and Dense Alignment for 3D Visual Grounding , author=. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
2023
-
[39]
2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
Text-guided Sparse Voxel Pruning for Efficient 3D Visual Grounding , author=. 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
2025
-
[40]
2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
Visual Programming for Zero-Shot Open-Vocabulary 3D Visual Grounding , author=. 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
2024
-
[41]
AAAI Conference on Artificial Intelligence , year=
3D-STMN: Dependency-Driven Superpoint-Text Matching Network for End-to-End 3D Referring Expression Segmentation , author=. AAAI Conference on Artificial Intelligence , year=
-
[42]
2023 IEEE/CVF International Conference on Computer Vision (ICCV) , year=
ViewRefer: Grasp the Multi-view Knowledge for 3D Visual Grounding , author=. 2023 IEEE/CVF International Conference on Computer Vision (ICCV) , year=
2023
-
[43]
Advances in Neural Information Processing Systems , volume=
Lamm: Language-assisted multi-modal instruction-tuning dataset, framework, and benchmark , author=. Advances in Neural Information Processing Systems , volume=
-
[44]
AAAI Conference on Artificial Intelligence , year=
Mono3DVG: 3D Visual Grounding in Monocular Images , author=. AAAI Conference on Artificial Intelligence , year=
-
[45]
2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
Naturally Supervised 3D Visual Grounding with Language-Regularized Concept Learners , author=. 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
2024
-
[46]
Conference on Empirical Methods in Natural Language Processing , year=
Language-to-Space Programming for Training-Free 3D Visual Grounding , author=. Conference on Empirical Methods in Natural Language Processing , year=
-
[47]
2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
ReasonGrounder: LVLM-Guided Hierarchical Feature Splatting for Open-Vocabulary 3D Visual Grounding and Reasoning , author=. 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
2025
-
[48]
International Conference on Machine Learning , year=
From Thousands to Billions: 3D Visual Language Grounding via Render-Supervised Distillation from 2D VLMs , author=. International Conference on Machine Learning , year=
-
[49]
ArXiv , year=
Zero-Shot 3D Visual Grounding from Vision-Language Models , author=. ArXiv , year=
-
[50]
ArXiv , year=
PanoGrounder: Bridging 2D and 3D with Panoramic Scene Representations for VLM-based 3D Visual Grounding , author=. ArXiv , year=
-
[51]
2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
Grounding 3D Object Affordance with Language Instructions, Visual Observations and Interactions , author=. 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
2025
-
[52]
Advances in Neural Information Processing Systems , volume=
Spazer: Spatial-semantic progressive reasoning agent for zero-shot 3d visual grounding , author=. Advances in Neural Information Processing Systems , volume=
-
[53]
European Conference on Computer Vision , year=
SceneVerse: Scaling 3D Vision-Language Learning for Grounded Scene Understanding , author=. European Conference on Computer Vision , year=
-
[54]
Proceedings of the IEEE/CVF International Conference on Computer Vision , year =
Huang, Ronggang and Yang, Haoxin and Cai, Yan and Xu, Xuemiao and Zhang, Huaidong and He, Shengfeng , title =. Proceedings of the IEEE/CVF International Conference on Computer Vision , year =
-
[55]
Advances in Neural Information Processing Systems , volume=
Spatiallm: Training large language models for structured indoor modeling , author=. Advances in Neural Information Processing Systems , volume=
-
[56]
2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
Multi-View Transformer for 3D Visual Grounding , author=. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
2022
-
[57]
2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
Viewpoint-Aware Visual Grounding in 3D Scenes , author=. 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
2024
-
[58]
European Conference on Computer Vision , year=
Four Ways to Improve Verbo-visual Fusion for Dense 3D Visual Grounding , author=. European Conference on Computer Vision , year=
-
[59]
Advances in Neural Information Processing Systems 37 , year=
Chat-Scene: Bridging 3D Scene and Large Language Models with Object Identifiers , author=. Advances in Neural Information Processing Systems 37 , year=
-
[60]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
VGMamba: Attribute-to-Location Clue Reasoning for Quantity-Agnostic 3D Visual Grounding , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[61]
ArXiv , year=
Qwen2.5-VL Technical Report , author=. ArXiv , year=
-
[62]
European Conference on Computer Vision , pages=
Multi-branch collaborative learning network for 3d visual grounding , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[63]
European Conference on Computer Vision , pages=
Unifying 3d vision-language understanding via promptable queries , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[64]
Advances in neural information processing systems , volume=
Language conditioned spatial relation reasoning for 3d object grounding , author=. Advances in neural information processing systems , volume=
-
[65]
Cognitive psychology , volume=
A feature-integration theory of attention , author=. Cognitive psychology , volume=. 1980 , publisher=
1980
-
[66]
Psychonomic bulletin & review , volume=
Guided search 2.0 a revised model of visual search , author=. Psychonomic bulletin & review , volume=. 1994 , publisher=
1994
-
[67]
Science , volume=
Integration of visual and linguistic information in spoken language comprehension , author=. Science , volume=. 1995 , publisher=
1995
-
[68]
Acta psychologica , volume=
Using the visual world paradigm to study language processing: A review and critical evaluation , author=. Acta psychologica , volume=. 2011 , publisher=
2011
-
[69]
, author=
Spatial attention and the apprehension of spatial relations. , author=. Journal of Experimental Psychology: Human Perception and Performance , volume=. 1994 , publisher=
1994
-
[70]
Memory & Cognition , volume=
Using spatial terms to select an object , author=. Memory & Cognition , volume=. 2001 , publisher=
2001
-
[71]
Advances in neural information processing systems , volume=
Attention is all you need , author=. Advances in neural information processing systems , volume=
-
[72]
Neural networks , volume=
Sigmoid-weighted linear units for neural network function approximation in reinforcement learning , author=. Neural networks , volume=. 2018 , publisher=
2018
-
[73]
Advances in neural information processing systems , volume=
Root mean square layer normalization , author=. Advances in neural information processing systems , volume=
-
[74]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale , author=
-
[76]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Sonata: Self-supervised learning of reliable point representations , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[77]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Point transformer v3: Simpler faster stronger , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[78]
Advances in neural information processing systems , volume=
Flashattention: Fast and memory-efficient exact attention with io-awareness , author=. Advances in neural information processing systems , volume=
-
[79]
Eslam Abdelrahman, Mohamed Ayman Mohamed, Mahmoud Ahmed, and Mohamed Elhoseiny. 2024. Cot3dref: Chain-of-thoughts data-efficient 3d visual grounding. In International Conference on Learning Representations, volume 2024, pages 11871--11896
2024
-
[80]
Xia, Mohamed Elhoseiny, and Leonidas J
Panos Achlioptas, Ahmed Abdelreheem, F. Xia, Mohamed Elhoseiny, and Leonidas J. Guibas. 2020. Referit3d: Neural listeners for fine-grained 3d object identification in real-world scenes. In European Conference on Computer Vision
2020
-
[81]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. 2025. Qwen2.5-vl technical rep...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.