ReGRPO: Reflection-Augmented Policy Optimization for Tool-Using Agents
Pith reviewed 2026-07-01 05:21 UTC · model grok-4.3
The pith
ReGRPO trains tool-using agents to reflect on near-miss failures via structured triplets and group-relative optimization to improve recovery.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
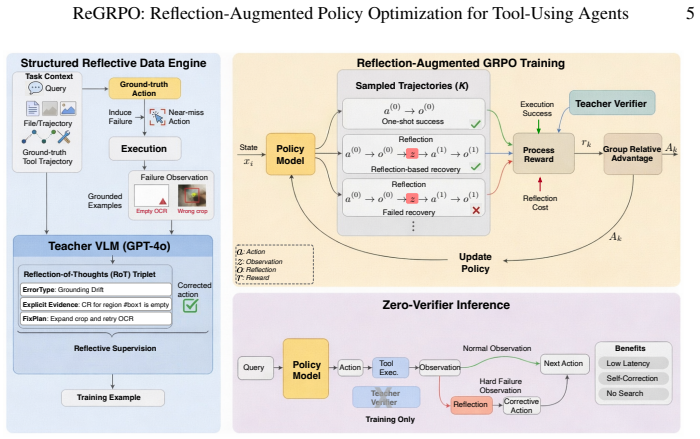
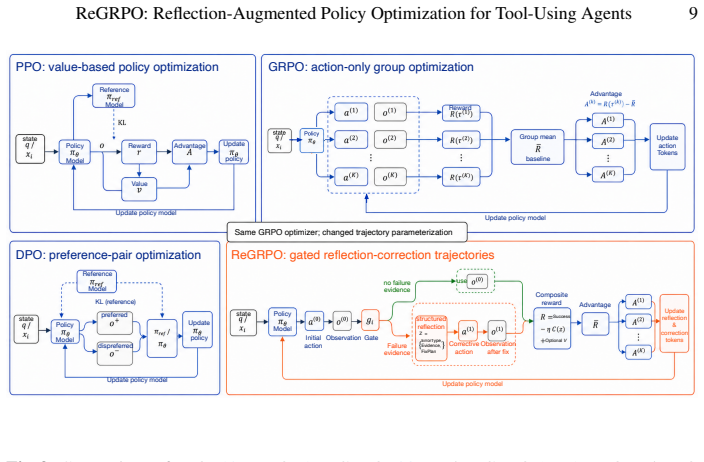
ReGRPO learns reflection-guided correction in tool-using agents. It starts with a structured reflective data engine that executes near-miss actions to collect grounded failure observations, then builds Reflection-of-Thought triplets (ErrorType, Evidence, FixPlan) paired with corrected actions for warm-start SFT. It optimizes reflection tokens and corrective actions jointly within local trajectories using group-relative advantages and includes a reflection-cost term to reduce unnecessary reflection.
What carries the argument
Reflection-of-Thought triplets (ErrorType, Evidence, FixPlan) paired with corrected actions, optimized via group-relative policy optimization plus a reflection-cost term.
Load-bearing premise
Collecting grounded failure observations via near-miss actions and structuring them as Reflection-of-Thought triplets supplies a sufficiently rich training signal to enable reliable recovery, and adding a reflection-cost term will not degrade performance on successful trajectories.
What would settle it
Training ReGRPO on GTA or GAIA and measuring no gain or a drop versus baselines that omit the reflection components would falsify the central claim.
Figures





read the original abstract
Tool-augmented vision-language models (VLMs) can solve multimodal, multi-step tasks by calling external tools, yet they remain fragile in practice. Existing works have two common gaps. Supervised fine-tuning (SFT) is built mostly on successful trajectories and offers little signal for recovery after tool failures, while sparse trajectory-level RL rewards provide limited guidance on which step failed and how to repair it. We introduce ReGRPO (Reflection-augmented Group Relative Policy Optimization), a framework that learns reflection-guided correction in tool-using agents. ReGRPO starts with a structured reflective data engine: we execute near-miss actions to collect grounded failure observations, then build Reflection-of-Thought triplets (ErrorType, Evidence, FixPlan) paired with corrected actions for warm-start SFT. We then optimize reflection tokens and corrective actions jointly within local trajectories using group-relative advantages, and include a reflection-cost term to reduce unnecessary reflection. Experiments on GTA and GAIA show that, under the same backbone and tool suite, ReGRPO consistently outperforms strong open-source baselines and achieves the best results among the compared open-source controllers. Code and RoT data are available at https://github.com/showlab/ReGRPO.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ReGRPO, a framework for tool-augmented VLMs that addresses limited recovery signals in SFT and sparse RL by collecting near-miss failure data into Reflection-of-Thought triplets (ErrorType, Evidence, FixPlan) for warm-start SFT, followed by joint GRPO optimization of reflection tokens and corrective actions with an added reflection-cost term. Experiments claim consistent outperformance over open-source baselines on GTA and GAIA under matched backbones and tool suites, with code and data released.
Significance. If the empirical gains hold, the work supplies a concrete mechanism for generating grounded recovery signals from near-miss trajectories and integrating them into group-relative optimization, which could improve robustness of multi-step tool use. Explicit release of code and RoT data is a positive contribution to reproducibility.
minor comments (3)
- [Abstract] The abstract states that ReGRPO 'consistently outperforms' baselines but provides no numerical deltas, success rates, or statistical significance; adding these values (or directing readers to the relevant table) would strengthen the claim.
- The description of the reflection-cost term is introduced without an explicit equation or hyperparameter schedule; including the precise formulation and how its weight was chosen would improve clarity.
- Figure or table captions should explicitly state the backbone model and tool suite used for each compared method to make the 'under the same backbone' claim immediately verifiable.
Simulated Author's Rebuttal
We thank the referee for the positive summary of ReGRPO, the recognition of its contribution to generating grounded recovery signals, and the recommendation for minor revision. No specific major comments were raised in the report.
Circularity Check
No significant circularity
full rationale
The paper presents ReGRPO as a pipeline of near-miss data collection into Reflection-of-Thought triplets, warm-start SFT, and joint GRPO optimization with an added reflection-cost term. No equations, fitted parameters, or predictions are shown that reduce by construction to the method's own inputs or self-citations. The performance claims rest on external experimental benchmarks (GTA, GAIA) rather than any self-referential derivation or renaming of known results. The derivation chain is therefore self-contained against external evaluation.
Axiom & Free-Parameter Ledger
free parameters (1)
- reflection-cost term weight
axioms (1)
- domain assumption Group-relative advantages within local trajectories supply finer-grained learning signal than sparse trajectory-level rewards
invented entities (1)
-
Reflection-of-Thought triplets (ErrorType, Evidence, FixPlan)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Chen, X., Lin, M., Schärli, N., Zhou, D.: Teaching large language models to self-debug (2023), https://arxiv.org/abs/2304.05128
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
In: ICML
Choi, W., Kim, W.K., Yoo, M., Woo, H.: Embodied cot distillation from llm to off-the-shelf agents. In: ICML. pp. 8702–8721 (2024)
2024
-
[3]
In: ECCV (2024)
Fan, Y ., Ma, X., Wu, R., Du, Y ., Li, J., Gao, Z., Li, Q.: Videoagent: A memory-augmented multimodal agent for video understanding. In: ECCV (2024)
2024
-
[4]
In: CVPR
Gao, Z., Du, Y ., Zhang, X., Ma, X., Han, W., Zhu, S.C., Li, Q.: Clova: A closed-loop visual assistant with tool usage and update. In: CVPR. pp. 13258–13268 (2024)
2024
-
[5]
arXiv preprint arXiv:2412.15606 (2024)
Gao, Z., Zhang, B., Li, P., Ma, X., Yuan, T., Fan, Y ., Wu, Y ., Jia, Y ., Zhu, S.C., Li, Q.: Multi-modal agent tuning: Building a vlm-driven agent for efficient tool usage. arXiv preprint arXiv:2412.15606 (2024)
-
[6]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., Wang, P., Bi, X., et al.: Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
In: ICLR (2022)
Hu, E.J., Shen, Y ., Wallis, P., Allen-Zhu, Z., Li, Y ., Wang, S., Wang, L., Chen, W.: Lora: Low-rank adaptation of large language models. In: ICLR (2022)
2022
-
[8]
LLaVA-NeXT-Interleave: Tackling Multi-image, Video, and 3D in Large Multimodal Models
Li, F., Zhang, R., Zhang, H., Zhang, Y ., Li, B., Li, W., Ma, Z., Li, C.: Llava-next- interleave: Tackling multi-image, video, and 3d in large multimodal models. arXiv preprint arXiv:2407.07895 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Iterative Tool Usage Exploration for Multimodal Agents via Step-wise Preference Tuning
Li, P., Gao, Z., Zhang, B., Mi, Y ., Ma, X., Shi, C., Yuan, T., Wu, Y ., Jia, Y ., Zhu, S.C., et al.: Iterative tool usage exploration for multimodal agents via step-wise preference tuning. arXiv preprint arXiv:2504.21561 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
arXiv preprint arXiv:2404.065103(2024)
Liao, Y .H., Mahmood, R., Fidler, S., Acuna, D.: Can feedback enhance semantic grounding in large vision-language models. arXiv preprint arXiv:2404.065103(2024)
-
[11]
Liu, H., Li, C., Li, Y ., Li, B., Zhang, Y ., Shen, S., Lee, Y .J.: Llava-next: Improved reasoning, ocr, and world knowledge (January 2024), https://llava-vl.github.io/blog/ 2024-01-30-llava-next/
2024
-
[12]
arXiv preprint arXiv:2311.05437 (2023)
Liu, S., Cheng, H., Liu, H., Zhang, H., Li, F., Ren, T., Zou, X., Yang, J., Su, H., Zhu, J., et al.: Llava-plus: Learning to use tools for creating multimodal agents. arXiv preprint arXiv:2311.05437 (2023)
-
[13]
arXiv preprint arXiv:2408.06327 (2024)
Liu, X., Zhang, T., Gu, Y ., Iong, I.L., Xu, Y ., Song, X., Zhang, S., Lai, H., Liu, X., Zhao, H., et al.: Visualagentbench: Towards large multimodal models as visual foundation agents. arXiv preprint arXiv:2408.06327 (2024)
-
[14]
DeepSeek-VL: Towards Real-World Vision-Language Understanding
Lu, H., Liu, W., Zhang, B., Wang, B., Dong, K., Liu, B., Sun, J., Ren, T., Li, Z., Yang, H., et al.: Deepseek-vl: towards real-world vision-language understanding. arXiv preprint arXiv:2403.05525 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Madaan, A., Tandon, N., Gupta, P., Hallinan, S., Gao, L., Wiegreffe, S., Alon, U., Dziri, N., Prabhumoye, S., Yang, Y ., Gupta, S., Majumder, B.P., Hermann, K., Welleck, S., Yazdanbakhsh, A., Clark, P.: Self-refine: Iterative refinement with self-feedback (2023), https://arxiv.org/abs/2303.17651
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
GAIA: a benchmark for General AI Assistants
Mialon, G., Fourrier, C., Swift, C., Wolf, T., LeCun, Y ., Scialom, T.: Gaia: a benchmark for general ai assistants. arXiv preprint arXiv:2311.12983 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[17]
Advances in neural information processing systems36, 53728–53741 (2023)
Rafailov, R., Sharma, A., Mitchell, E., Manning, C.D., Ermon, S., Finn, C.: Direct preference optimization: Your language model is secretly a reward model. Advances in neural information processing systems36, 53728–53741 (2023)
2023
-
[18]
Sasazawa, Y ., Sogawa, Y .: Layout generation agents with large language models. arXiv preprint arXiv:2405.08037 (2024) ReGRPO: Reflection-Augmented Policy Optimization for Tool-Using Agents 17
-
[19]
Proximal Policy Optimization Algorithms
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., Klimov, O.: Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[20]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y ., Wu, Y ., et al.: Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
arXiv preprint arXiv:2311.18760 (2023)
Shen, Y ., Song, K., Tan, X., Zhang, W., Ren, K., Yuan, S., Lu, W., Li, D., Zhuang, Y .: Taskbench: Benchmarking large language models for task automation. arXiv preprint arXiv:2311.18760 (2023)
-
[22]
Shinn, N., Cassano, F., Berman, E., Gopinath, A., Narasimhan, K., Yao, S.: Reflexion: Lan- guage agents with verbal reinforcement learning (2023), https://arxiv.org/abs/ 2303.11366
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
In: ICCV
Surís, D., Menon, S., V ondrick, C.: Vipergpt: Visual inference via python execution for reasoning. In: ICCV . pp. 11888–11898 (2023)
2023
-
[24]
arXiv preprint arXiv:2401.107274(2024)
Wang, C., Luo, W., Chen, Q., Mai, H., Guo, J., Dong, S., Xuan, X., Li, Z., Ma, L., Gao, S.: Mllm-tool: A multimodal large language model for tool agent learning. arXiv preprint arXiv:2401.107274(2024)
-
[25]
In: NeurIPS (2024)
Wang, J., Ma, Z., Li, Y ., Zhang, S., Chen, C., Chen, K., Le, X.: Gta: A benchmark for general tool agents. In: NeurIPS (2024)
2024
-
[26]
arXiv preprint arXiv:2407.05600 (2024)
Wang, Z., Li, A., Li, Z., Liu, X.: Genartist: Multimodal llm as an agent for unified image generation and editing. arXiv preprint arXiv:2407.05600 (2024)
-
[27]
Wang, Z., Xie, E., Li, A., Wang, Z., Liu, X., Li, Z.: Divide and conquer: Language mod- els can plan and self-correct for compositional text-to-image generation. arXiv preprint arXiv:2401.15688 (2024)
-
[28]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Xiong, T., Wang, X., Guo, D., Ye, Q., Fan, H., Gu, Q., Huang, H., Li, C.: Llava-critic: Learning to evaluate multimodal models. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 13618–13628 (2025)
2025
-
[29]
In: ICML
Yin, D., Brahman, F., Ravichander, A., Chandu, K., Chang, K.W., Choi, Y ., Lin, B.Y .: Agent lumos: Unified and modular training for open-source language agents. In: ICML. pp. 12380– 12403 (2024)
2024
-
[30]
arXiv preprint arXiv:2402.15506 (2024)
Zhang, J., Lan, T., Murthy, R., Liu, Z., Yao, W., Tan, J., Hoang, T., Yang, L., Feng, Y ., Liu, Z., et al.: Agentohana: Design unified data and training pipeline for effective agent learning. arXiv preprint arXiv:2402.15506 (2024)
-
[31]
task": ...,
Zheng, B., Gou, B., Kil, J., Sun, H., Su, Y .: Gpt-4v (ision) is a generalist web agent, if grounded. In: ICML. pp. 61349–61385 (2024) ReGRPO: Reflection-Augmented Policy Optimization for Tool-Using Agents 1 Appendix A1 Algorithmic Details In this section we provide pseudo code and implementation details for Reflection- Augmented Group Relative Policy Opt...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.