ART for Diffusion Sampling: Continuous-Time Control and Actor-Critic Learning
Pith reviewed 2026-07-03 17:12 UTC · model grok-4.3
The pith
A continuous-time control problem learns adaptive timestep grids for diffusion sampling that improve quality over fixed schedules.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ART formulates timestep allocation as a deterministic continuous-time control problem that chooses the speed of the sampling clock to minimize an integrated leading-order Euler error surrogate; the equivalent ART-RL randomized formulation with Gaussian policies admits policy evaluation and improvement characterizations whose optimal policy mean recovers the same optimal time-warping rate, and trajectory moment identities yield actor-critic updates that learn the schedule.
What carries the argument
The ART time change, in which the control input is the instantaneous speed of the sampling clock so that a uniform grid on the warped clock produces adaptive steps in original diffusion time, optimized via the Euler error surrogate and recovered from the mean of the optimal Gaussian policy.
If this is right
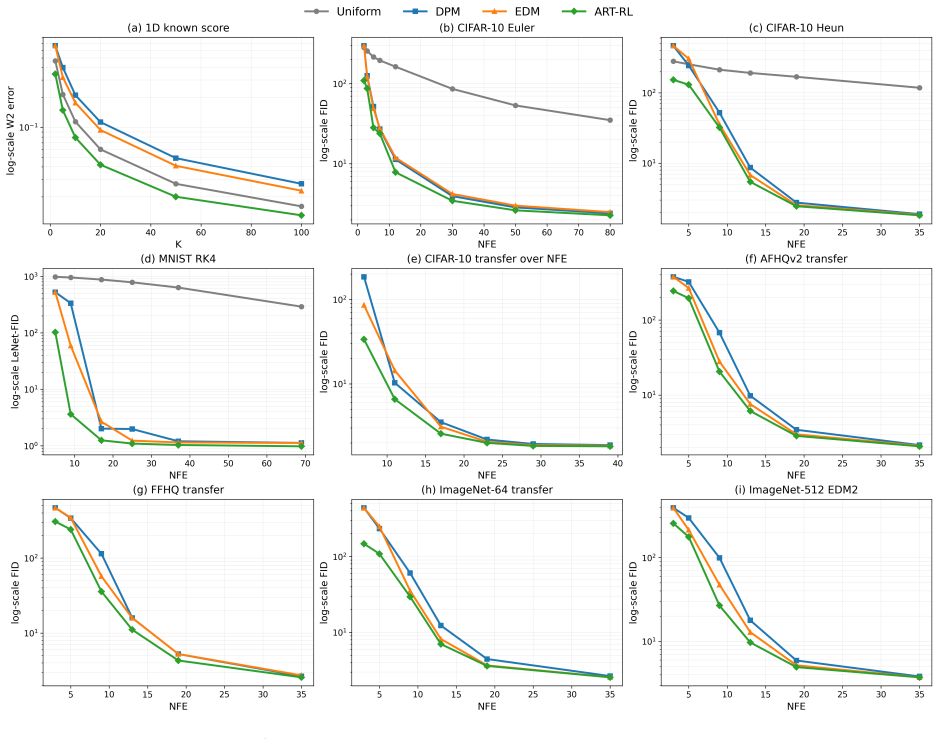
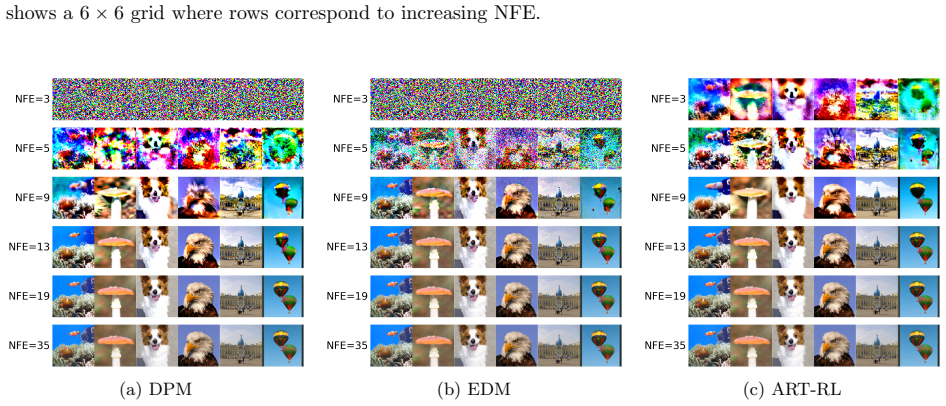
- Sample quality improves over strong baseline schedules at matched budgets when only the timestep grid is changed.
- Learned schedules generalize without retraining across sampling budgets, data sets, solvers, pipelines, and representation spaces.
- The randomized Gaussian-policy formulation is equivalent to the deterministic control problem at the optimizer level.
- Actor-critic updates derived from trajectory moment identities are sufficient to learn the schedule in practice.
Where Pith is reading between the lines
- The same continuous-time control framing could be applied to other numerical discretizations of SDEs or ODEs whenever a leading-order local error surrogate is available.
- Broad generalization of the learned schedules suggests that the optimal warping depends primarily on the diffusion dynamics rather than on particular data or model details.
- The actor-critic formulation could incorporate secondary objectives such as variance reduction or memory constraints by modifying the reward or adding control penalties.
Load-bearing premise
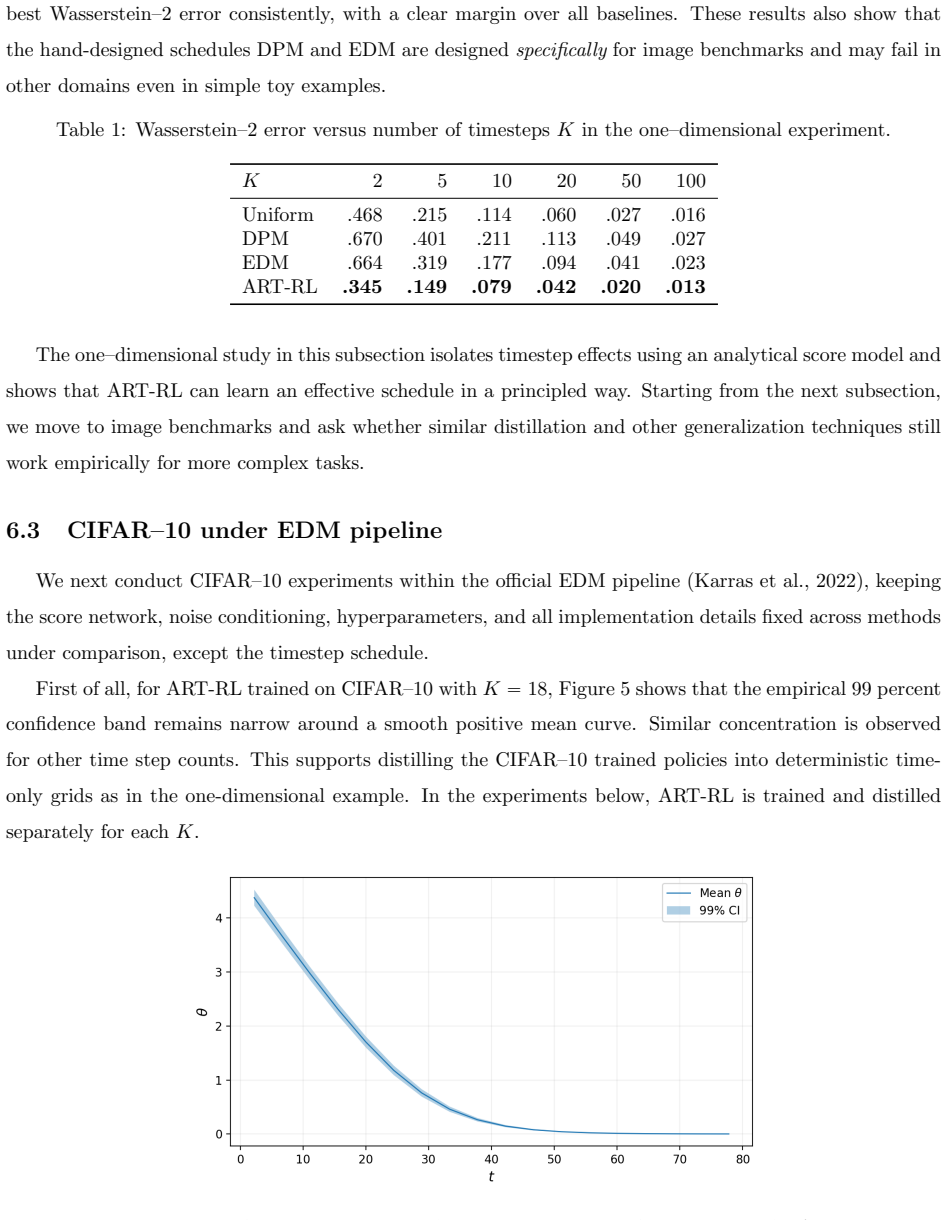
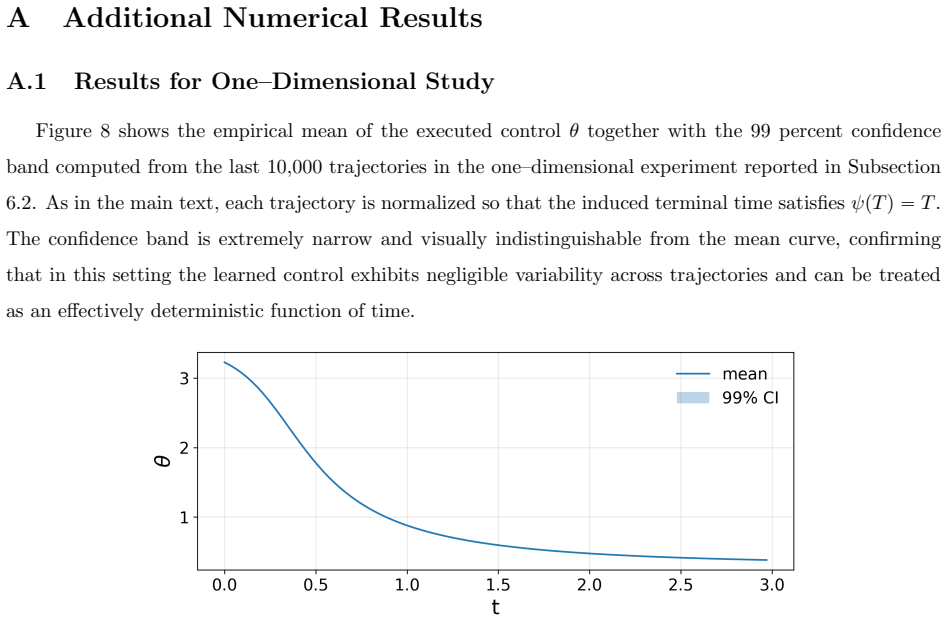
Optimizing the leading-order Euler error surrogate through the continuous-time control problem produces sampling trajectories that are measurably better than those from standard grids.
What would settle it
Applying an ART-learned timestep schedule to a diffusion sampler on image data and finding no improvement in sample quality metrics such as FID relative to uniform or hand-crafted grids at identical step counts would falsify the central practical claim.
Figures









read the original abstract
We study timestep allocation for score-based diffusion sampling, where a learned reverse-time dynamics is discretized on a finite grid. Uniform and hand-crafted schedules are standard choices, but they rely on fixed prescriptions and can therefore be suboptimal. To address this limitation, we propose Adaptive Reparameterized Time (ART), a continuous-time control formulation that learns a time change by treating the speed of the sampling clock as the control, so that a uniform grid on the learned clock induces adaptive timesteps in the original diffusion time. Based on a leading-order Euler error surrogate, ART provides a principled objective for allocating timesteps along the sampling trajectory. To solve this deterministic control problem, we introduce ART-RL, an auxiliary randomized formulation with Gaussian policies that turns schedule learning into a continuous-time reinforcement learning problem. We prove that the randomized ART-RL formulation is equivalent to ART at the optimizer level, in the sense that its optimal Gaussian policy recovers the optimal ART time-warping rate through its mean. We further establish policy evaluation and policy improvement characterizations and derive trajectory-based moment identities that yield implementable actor--critic updates for learning the schedule. Across experiments ranging from controlled low-dimensional settings to image generation, ART-RL can be plugged into existing diffusion samplers by changing only the timestep grid, consistently improving sample quality over strong baseline schedules at matched budgets while leaving the rest of the sampling pipeline unchanged. The learned schedules also exhibit broad generalization, transferring without retraining across sampling budgets, datasets, solvers, pipelines, and representation spaces.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Adaptive Reparameterized Time (ART), a continuous-time control formulation that learns a time change for adaptive timestep allocation in score-based diffusion sampling by treating clock speed as the control and using a leading-order Euler error surrogate as the objective. It further proposes ART-RL, a randomized auxiliary formulation with Gaussian policies that is claimed to be equivalent to ART at the optimizer level (optimal policy mean recovers the ART warping rate), with derived policy evaluation/improvement characterizations and trajectory-based moment identities enabling actor-critic updates. Empirically, ART-RL is shown to improve sample quality over strong baseline schedules at matched budgets by changing only the timestep grid, with learned schedules generalizing across budgets, datasets, solvers, pipelines, and representation spaces.
Significance. If the surrogate objective aligns with actual sampling trajectories and quality, the approach could provide a principled, plug-in method for optimizing diffusion sampling efficiency without modifying score models or solvers. The claimed equivalence proof between deterministic control and randomized RL formulations, together with the derivation of implementable actor-critic updates from moment identities, would constitute a notable theoretical contribution if the derivations are complete and rigorous.
major comments (3)
- [Abstract] Abstract: the central empirical claim that ART-RL yields measurably superior sampling trajectories rests on the leading-order Euler error surrogate constituting a sufficient objective for the continuous-time control problem, yet no validation, correlation analysis, or ablation is provided showing alignment between this surrogate and true accumulated discretization error (or downstream quality metrics) under the learned score; this is load-bearing for both the theoretical motivation and the generalization claims.
- [Abstract] Abstract: the assertions of equivalence at the optimizer level (randomized ART-RL recovering the deterministic optimum through its mean), policy evaluation and policy improvement characterizations, and derivation of trajectory-based moment identities for actor-critic updates are presented without derivation details, equation references, or proof sketches, preventing verification of these load-bearing theoretical results.
- [Abstract] Abstract: the claims of consistent improvements and broad generalization across sampling budgets, datasets, solvers, pipelines, and representation spaces are stated without reference to error bars, statistical significance, dataset specifics, or exact experimental protocols, which are required to assess whether the reported gains are robust and attributable to the timestep schedule alone.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment below and will revise the abstract accordingly to better reference supporting material from the main text while adding new validation where needed.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claim that ART-RL yields measurably superior sampling trajectories rests on the leading-order Euler error surrogate constituting a sufficient objective for the continuous-time control problem, yet no validation, correlation analysis, or ablation is provided showing alignment between this surrogate and true accumulated discretization error (or downstream quality metrics) under the learned score; this is load-bearing for both the theoretical motivation and the generalization claims.
Authors: We agree that explicit validation of the surrogate would strengthen the presentation. The manuscript derives the surrogate from leading-order Euler analysis (Section 3.1) and shows downstream quality gains, but does not include direct correlation studies or ablations against accumulated error. In the revision we will add a new low-dimensional correlation analysis and ablation linking the surrogate to true discretization error and FID, and will reference these results in the abstract. revision: yes
-
Referee: [Abstract] Abstract: the assertions of equivalence at the optimizer level (randomized ART-RL recovering the deterministic optimum through its mean), policy evaluation and policy improvement characterizations, and derivation of trajectory-based moment identities for actor-critic updates are presented without derivation details, equation references, or proof sketches, preventing verification of these load-bearing theoretical results.
Authors: The equivalence at the optimizer level, policy evaluation/improvement characterizations, and trajectory-based moment identities are derived with proof sketches in Sections 3.2–3.4 and full proofs in Appendix A. The abstract summarizes these results at a high level. We will revise the abstract to include parenthetical references to the relevant sections and key equations. revision: yes
-
Referee: [Abstract] Abstract: the claims of consistent improvements and broad generalization across sampling budgets, datasets, solvers, pipelines, and representation spaces are stated without reference to error bars, statistical significance, dataset specifics, or exact experimental protocols, which are required to assess whether the reported gains are robust and attributable to the timestep schedule alone.
Authors: Section 5 reports all experiments with error bars over multiple seeds, statistical significance tests, dataset details, and protocols confirming that only the timestep grid is changed. We will revise the abstract to reference these experimental details and the robustness findings. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper defines ART as a continuous-time control problem whose objective is the leading-order Euler error surrogate (explicitly introduced as such), then constructs ART-RL as an auxiliary randomized formulation with Gaussian policies, and states a mathematical proof that the optimal policy mean recovers the ART optimum. This equivalence is a derived structural property rather than a reduction of outputs to inputs by construction. No steps match the enumerated circularity patterns: there are no self-citations invoked as load-bearing uniqueness theorems, no fitted parameters renamed as predictions, no ansatzes smuggled via prior work, and no renaming of known results. The central claims rest on the chosen surrogate and the control/RL formulation, which are presented as modeling choices with independent content outside the paper's fitted values.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Leading-order Euler error surrogate is a valid proxy for sampling quality
Reference graph
Works this paper leans on
- [1]
-
[2]
Jonathan Ho, Ajay Jain, and Pieter Abbeel
Accessed: 2025- 09-17. Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. InNeurips, volume 33, pages 6840–6851,
2025
-
[3]
Convergence analysis of probability flow ode for score-based generative models
Daniel Zhengyu Huang, Jiaoyang Huang, and Zhengjiang Lin. Convergence analysis of probability flow ode for score-based generative models. 2025a. arXiv:2404.09730. To appear in IEEE Trans. Inf. Theory. Yilie Huang. Continuous-time reinforcement learning for asset–liability management. InProceedings of the 6th ACM International Conference on AI in Finance, ...
-
[4]
Yilie Huang, Yanwei Jia, and Xunyu Zhou
arXiv:2507.00358. Yilie Huang, Yanwei Jia, and Xunyu Zhou. Achieving mean–variance efficiency by continuous-time rein- forcement learning. InProceedings of the Third ACM International Conference on AI in Finance, pages 377–385,
-
[5]
Yilie Huang, Yanwei Jia, and Xun Yu Zhou
arXiv:2412.16175. Yilie Huang, Yanwei Jia, and Xun Yu Zhou. Sublinear regret for a class of continuous-time linear-quadratic reinforcement learning problems.SIAM Journal on Control and Optimization, 63(5):3452–3474, 2025b. 30 Yanwei Jia and Xun Yu Zhou. Policy evaluation and temporal-difference learning in continuous time and space: A martingale approach....
-
[6]
Mercury: Ultra-Fast Language Models Based on Diffusion
arXiv:2506.17298. Vijay Konda and John Tsitsiklis. Actor-critic algorithms.Advances in Neural Information Processing Systems, 12,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
arXiv:2502.09992. OpenAI. Sora: Creating video from text.https://openai.com/sora,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen
Accessed: 2025-09-17. Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image generation with clip latents
2025
-
[9]
Hierarchical Text-Conditional Image Generation with CLIP Latents
arXiv:2204.06125. Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj¨ orn Ommer. High-resolution image synthesis with latent diffusion models. InCVPR, pages 10684–10695,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Haoran Wang, Thaleia Zariphopoulou, and Xun Yu Zhou
arXiv:2411.01302. Haoran Wang, Thaleia Zariphopoulou, and Xun Yu Zhou. Reinforcement learning in continuous time and space: A stochastic control approach.Journal of Machine Learning Research, 21(198):1–34,
-
[11]
Qinsheng Zhang and Yongxin Chen
arXiv:2410.04760. Qinsheng Zhang and Yongxin Chen. Fast sampling of diffusion models with exponential integrator. InICLR,
-
[12]
Hanyang Zhao, Wenpin Tang, and David D Yao
arXiv:2308.02157. Hanyang Zhao, Wenpin Tang, and David D Yao. Policy optimization for continuous reinforcement learning. InNeurips, volume 36,
-
[13]
Hanyang Zhao, Haoxian Chen, Ji Zhang, David Yao, and Wenpin Tang
arXiv:2409.08400. Hanyang Zhao, Haoxian Chen, Ji Zhang, David Yao, and Wenpin Tang. Score as Action: Fine tuning diffusion generative models by continuous-time reinforcement learning. InICML,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.