Beyond Adam: SOAP and Muon for Faster, Label-Efficient Training of Machine Learning Interatomic Potentials
Pith reviewed 2026-07-03 16:21 UTC · model grok-4.3
The pith
Matrix-structured optimizers like SOAP and SOAP-Muon train ML interatomic potentials faster and more accurately than Adam.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
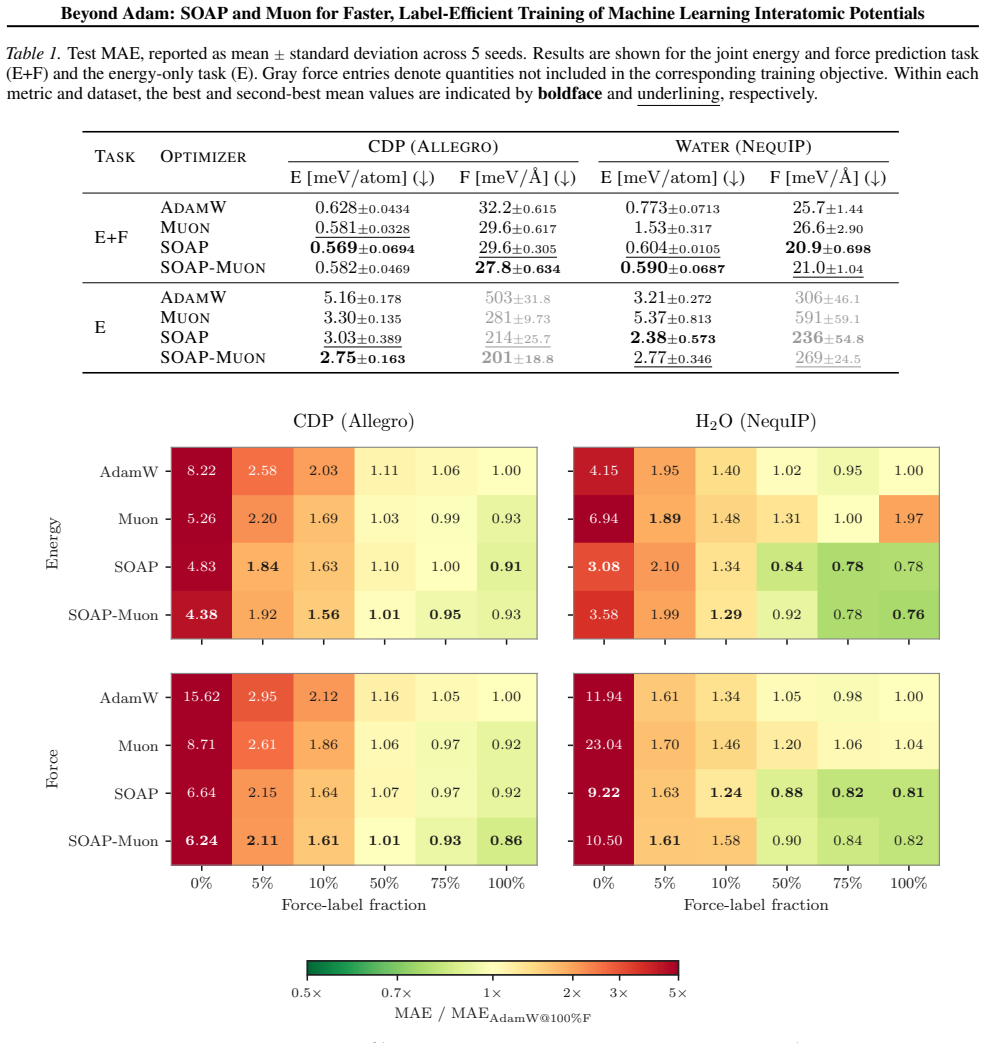
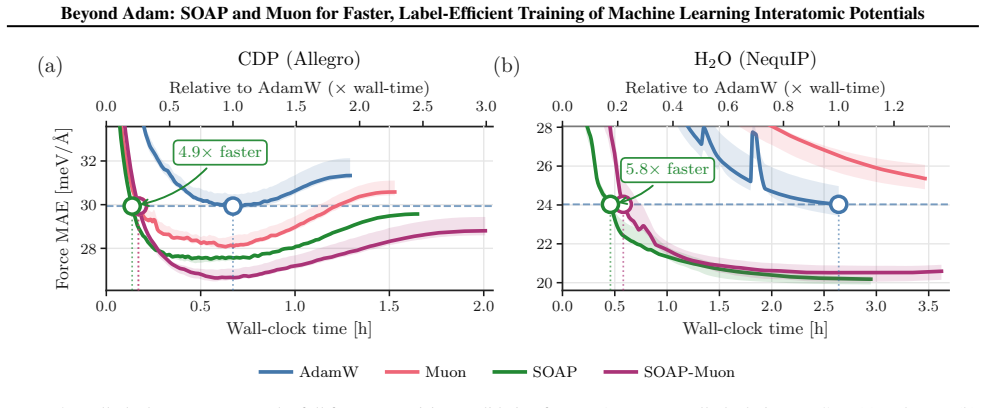
SOAP and SOAP-Muon substantially outperform Adam in both convergence speed and final accuracy on NequIP and Allegro models, while Muon alone yields only partial gains; the advantage of the stronger methods is especially clear under partial force supervision.
What carries the argument
Matrix-structured optimizers (Muon, SOAP, SOAP-Muon) that maintain and update structured matrices of parameters rather than independent per-element adaptive rates.
If this is right
- SOAP and SOAP-Muon deliver consistent gains across the tested architectures and datasets.
- Partial force supervision amplifies the benefit of these optimizers relative to Adam.
- Muon by itself improves training only modestly compared with the SOAP variants.
- Optimizer selection becomes a practical lever for reducing training cost in MLIP development.
Where Pith is reading between the lines
- If the gains hold for other architectures, routine adoption of SOAP could lower the data volume required to reach target accuracy.
- The interaction between optimizer structure and partial supervision may point to broader principles for label-efficient scientific machine learning.
- Replicating the comparison on larger or more diverse datasets would test whether the ranking of methods remains stable.
Load-bearing premise
Observed performance gaps are caused mainly by the choice of optimizer rather than by interactions with the specific model architectures, data distributions, or hyper-parameter tuning effort.
What would settle it
An experiment in which Adam is given exhaustive per-model hyper-parameter search and still fails to match the final accuracy or step count of SOAP on the same NequIP and Allegro training runs.
Figures
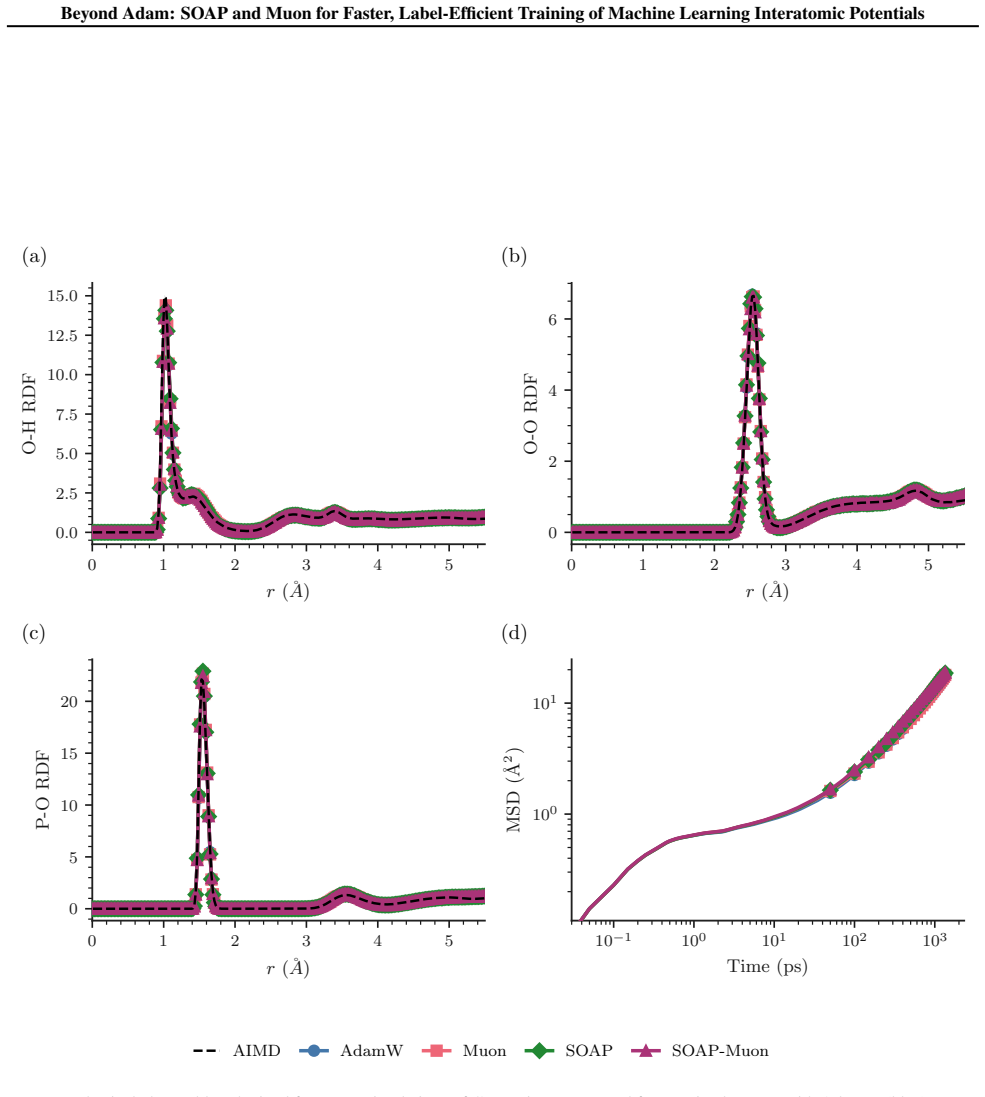
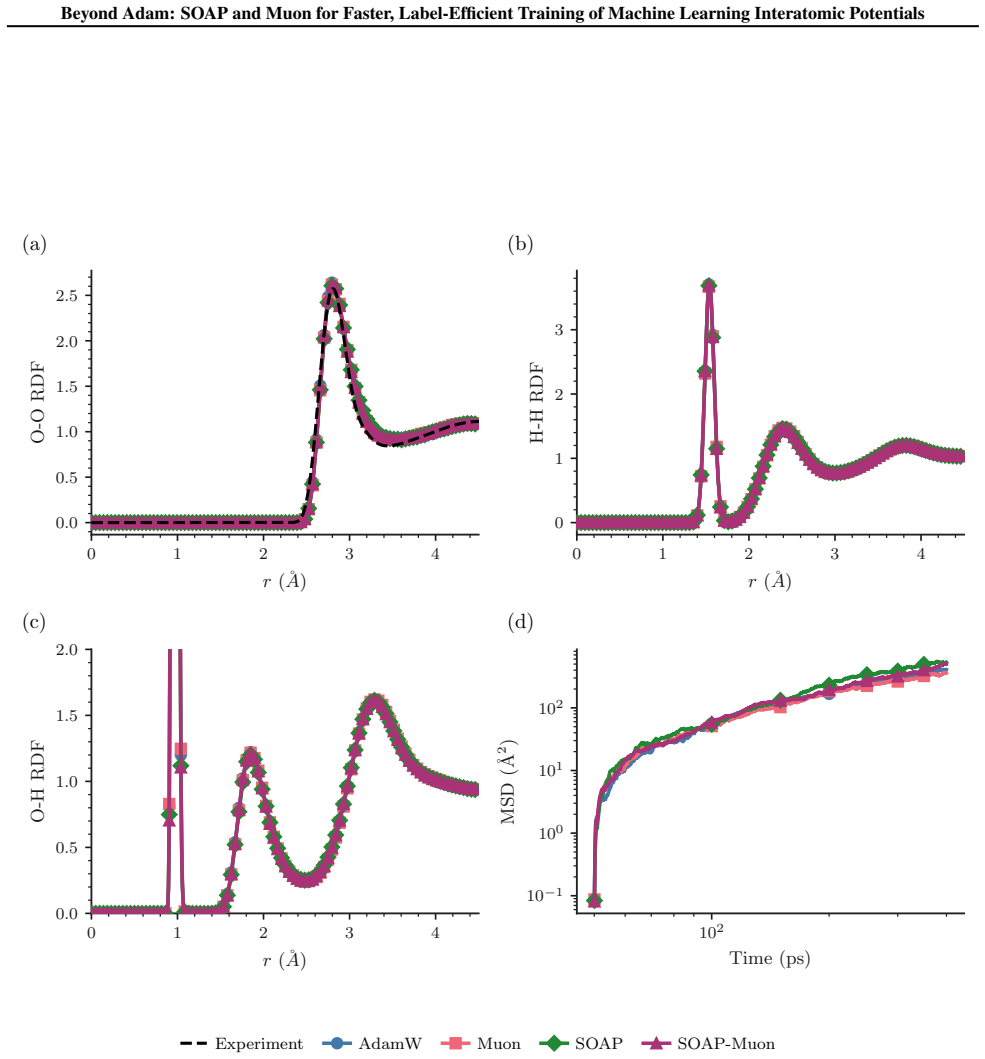
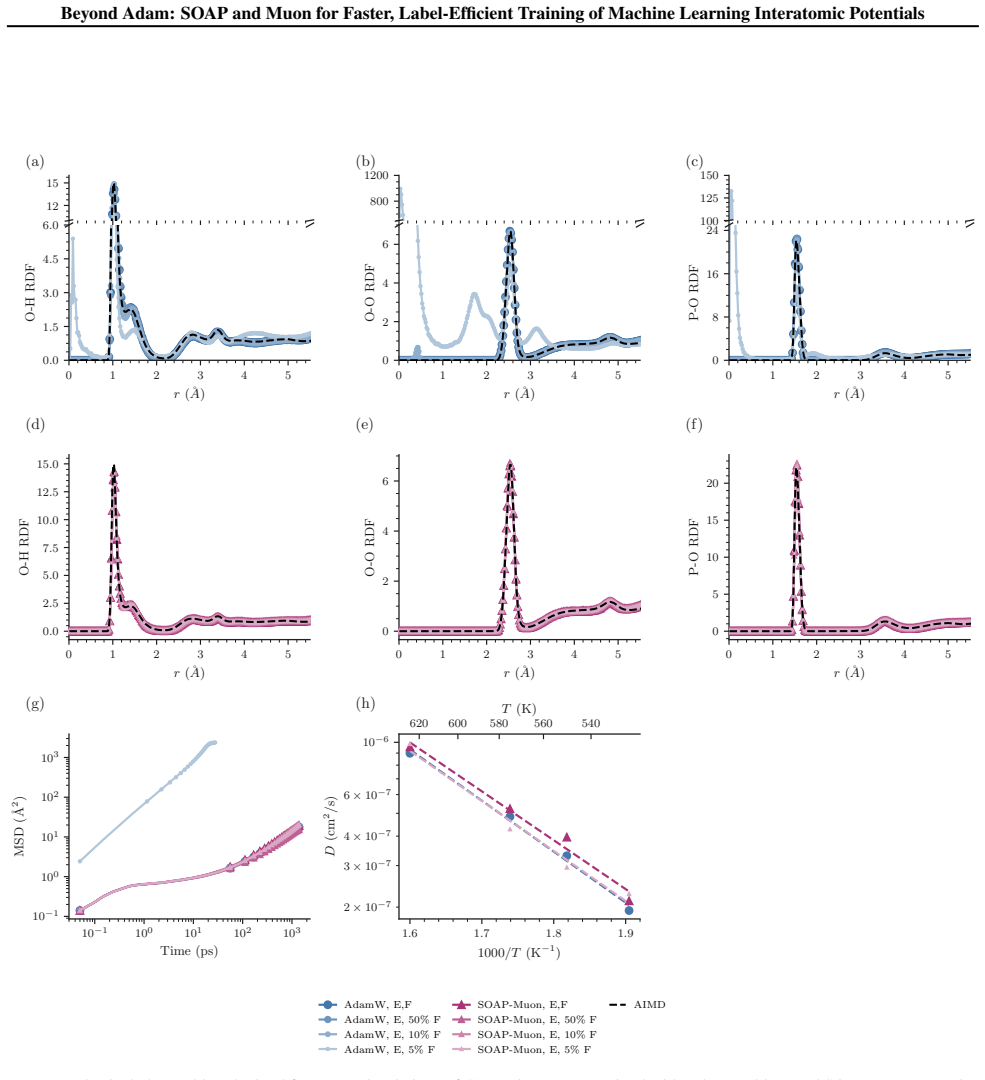
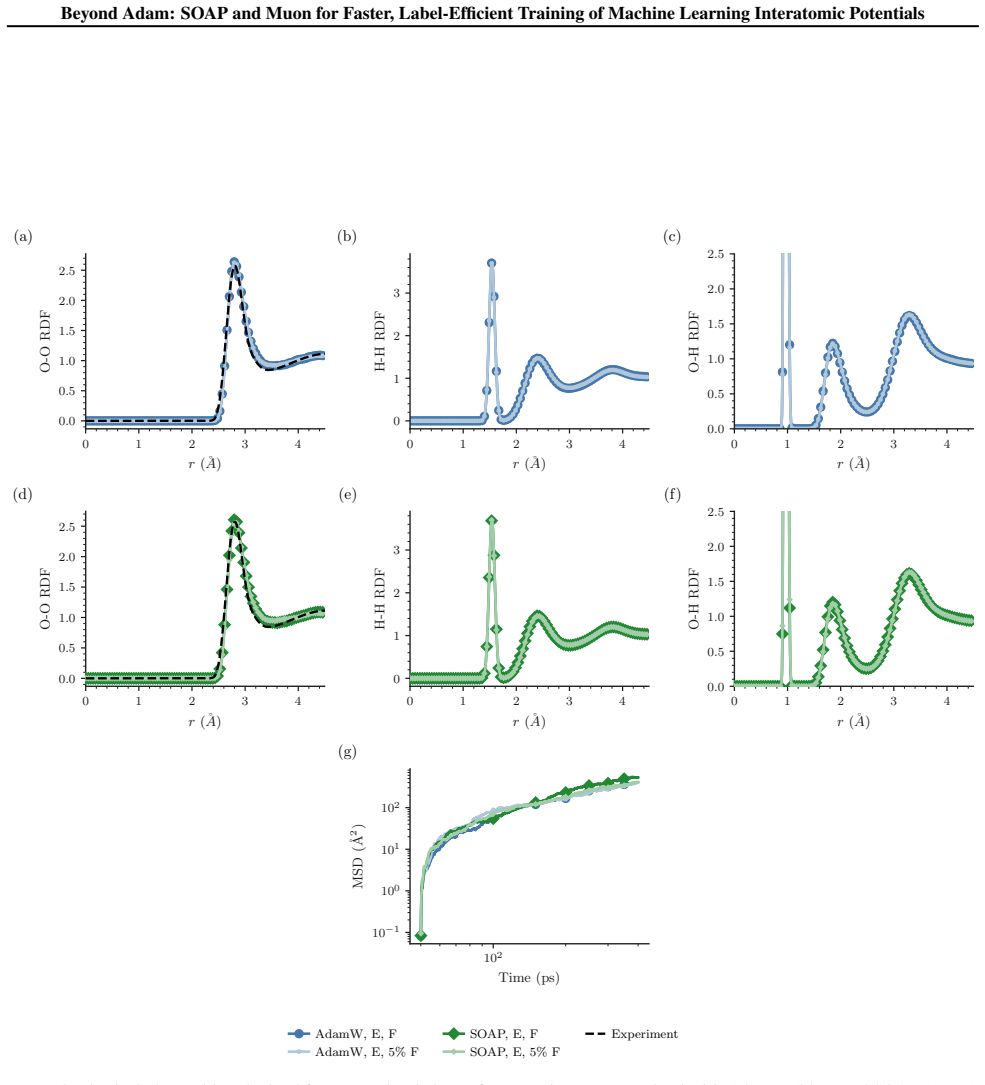
read the original abstract
Machine learning interatomic potentials (MLIPs) have become a hallmark of AI for scientific simulation. While efforts on new architectures and datasets have led to increasingly accurate and general models, the choice of optimizer for training has largely remained unexplored, defaulting to Adam and its variants in the community. Here, we implement and systematically compare a class of recently proposed matrix-structured optimizers, including Muon, SOAP, and the hybrid SOAP-Muon, for training NequIP and Allegro MLIP models. We find that these optimizers can substantially outperform Adam in both convergence speed and final accuracy. SOAP and SOAP-Muon emerge as robust and consistently strong methods, while Muon only provides partial gains relative to Adam. The improvements are particularly pronounced under partial force supervision. Our results indicate that optimizer choice is an overlooked yet impactful design axis for MLIPs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper implements matrix-structured optimizers (Muon, SOAP, SOAP-Muon) and benchmarks them against Adam for training NequIP and Allegro MLIP models on standard datasets. It claims that SOAP and SOAP-Muon deliver substantially faster convergence and higher final accuracy than Adam, with the largest gains under partial force supervision; Muon yields only partial improvements. The work positions optimizer choice as an overlooked but high-impact axis for MLIP training efficiency.
Significance. If the empirical gaps survive equivalent hyperparameter tuning and statistical controls, the result would establish optimizer architecture as a practical lever for label-efficient MLIP training, complementing architecture and dataset advances. The absence of any parameter-free derivations or machine-checked claims means significance rests entirely on the reproducibility and fairness of the reported benchmarks.
major comments (2)
- [Methods/Experiments] The experimental protocol (Methods/Experiments section) supplies no quantitative details on run counts, error bars, statistical tests, hyper-parameter search budget, learning-rate schedules, or data splits. Without these, it is impossible to determine whether the reported superiority of SOAP/SOAP-Muon is statistically reliable or an artifact of unequal tuning effort between Adam and the new optimizers.
- [Results and Abstract] The central claim that performance differences are driven by optimizer structure (rather than tuning disparity) is load-bearing for the abstract and results. The manuscript describes systematic comparison for the new methods but provides no corresponding protocol or search budget for Adam baselines, leaving open the possibility that observed gaps reflect optimization disparity rather than matrix-structured advantages.
minor comments (2)
- [Methods] Clarify the precise implementation details of SOAP and Muon within the NequIP and Allegro codebases (e.g., how matrix operations interface with the force/energy loss terms).
- [Appendix or Experiments] Add a table or figure summarizing the exact hyperparameter ranges searched for each optimizer to allow direct comparison of tuning effort.
Simulated Author's Rebuttal
We thank the referee for the constructive comments emphasizing reproducibility and fair comparisons. We will revise the manuscript to supply the requested experimental details and to make the hyperparameter protocol explicit and uniform across all optimizers.
read point-by-point responses
-
Referee: [Methods/Experiments] The experimental protocol (Methods/Experiments section) supplies no quantitative details on run counts, error bars, statistical tests, hyper-parameter search budget, learning-rate schedules, or data splits. Without these, it is impossible to determine whether the reported superiority of SOAP/SOAP-Muon is statistically reliable or an artifact of unequal tuning effort between Adam and the new optimizers.
Authors: We agree these quantitative details are necessary. The revised Methods section will report: 5 independent random seeds per configuration with mean and standard deviation; the hyperparameter search budget (identical grid over learning rate, weight decay, and schedule parameters for every optimizer); the learning-rate schedules employed; and the precise train/validation/test splits. These additions will allow direct assessment of statistical reliability and confirm equal tuning effort. revision: yes
-
Referee: [Results and Abstract] The central claim that performance differences are driven by optimizer structure (rather than tuning disparity) is load-bearing for the abstract and results. The manuscript describes systematic comparison for the new methods but provides no corresponding protocol or search budget for Adam baselines, leaving open the possibility that observed gaps reflect optimization disparity rather than matrix-structured advantages.
Authors: The experiments applied an identical systematic hyperparameter search procedure and budget to Adam as to Muon, SOAP, and SOAP-Muon. The revision will state this explicitly in both Methods and Results, including the search ranges and number of trials per optimizer. This documentation will substantiate that the reported gains arise from optimizer structure rather than unequal tuning. revision: yes
Circularity Check
Empirical benchmark with no derivation chain or self-referential reductions
full rationale
The paper is a direct empirical comparison of optimizers (SOAP, Muon, SOAP-Muon vs. Adam) on NequIP and Allegro models under varying supervision regimes. No equations, predictions, or first-principles derivations are presented that could reduce by construction to fitted inputs, self-citations, or ansatzes. All claims rest on reported training runs and metrics; the study is therefore self-contained against external benchmarks with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2025 , eprint=
Training a Foundation Model for Materials on a Budget , author=. 2025 , eprint=
2025
-
[2]
2017 , eprint=
Adam: A Method for Stochastic Optimization , author=. 2017 , eprint=
2017
-
[3]
2024 , url =
Keller Jordan and Yuchen Jin and Vlado Boza and Jiacheng You and Franz Cesista and Laker Newhouse and Jeremy Bernstein , title =. 2024 , url =
2024
-
[4]
Proceedings of the 35th International Conference on Machine Learning , pages =
Shampoo: Preconditioned Stochastic Tensor Optimization , author =. Proceedings of the 35th International Conference on Machine Learning , pages =. 2018 , editor =
2018
-
[5]
2025 , eprint=
SOAP: Improving and Stabilizing Shampoo using Adam , author=. 2025 , eprint=
2025
-
[6]
2025 , url=
Improving SOAP using iterative whitening and Muon , author=. 2025 , url=
2025
-
[7]
2024 , eprint=
Old Optimizer, New Norm: An Anthology , author=. 2024 , eprint=
2024
-
[8]
2019 , eprint=
Decoupled Weight Decay Regularization , author=. 2019 , eprint=
2019
-
[9]
2025 , eprint=
Revealing the proton slingshot mechanism in solid acid electrolytes through machine learning molecular dynamics , author=. 2025 , eprint=
2025
-
[10]
2025 , eprint=
Gradient Alignment in Physics-informed Neural Networks: A Second-Order Optimization Perspective , author=. 2025 , eprint=
2025
-
[11]
Liu, Xiaoqing and Wang, Yangshuai and Zhao, Teng , journal =. Beyond. 2026 , month =. doi:10.1088/3050-287x/ae5078 , issn =
-
[12]
2013 , publisher=
Molecular electronic-structure theory , author=. 2013 , publisher=
2013
-
[13]
and Kornbluth, Mordechai and Molinari, Nicola and Smidt, Tess E
Batzner, Simon and Musaelian, Albert and Sun, Lixin and Geiger, Mario and Mailoa, Jonathan P. and Kornbluth, Mordechai and Molinari, Nicola and Smidt, Tess E. and Kozinsky, Boris , journal =. E(3)-equivariant graph neural networks for data-efficient and accurate interatomic potentials , url =. 2022 , month =. doi:10.1038/s41467-022-29939-5 , issn =
-
[14]
and Kornbluth, Mordechai and Kozinsky, Boris , journal =
Musaelian, Albert and Batzner, Simon and Johansson, Anders and Sun, Lixin and Owen, Cameron J. and Kornbluth, Mordechai and Kozinsky, Boris , journal =. Learning local equivariant representations for large-scale atomistic dynamics , url =. 2023 , month =. doi:10.1038/s41467-023-36329-y , issn =
-
[15]
Physical Review X , volume=
Graph atomic cluster expansion for semilocal interactions beyond equivariant message passing , author=. Physical Review X , volume=. 2024 , publisher=
2024
-
[16]
and Galvelis, Raimondas and Herr, John E
Eastman, Peter and Behara, Pavan Kumar and Dotson, David L. and Galvelis, Raimondas and Herr, John E. and Horton, Josh T. and Mao, Yuezhi and Chodera, John D. and Pritchard, Benjamin P. and Wang, Yuanqing and De Fabritiis, Gianni and Markland, Thomas E. , journal =. SPICE,. 2023 , month =. doi:10.1038/s41597-022-01882-6 , issn =
-
[17]
Eastman, Peter and Pritchard, Benjamin P. and Chodera, John D. and Markland, Thomas E. , journal =. Nutmeg and. 2024 , month =. doi:10.1021/acs.jctc.4c00794 , issn =
-
[18]
Messerly, Mitchell and Matin, Sakib and Allen, Alice E A and Nebgen, Benjamin and Barros, Kipton and Smith, Justin S and Lubbers, Nicholas and Messerly, Richard , journal =. Multi-fidelity learning for interatomic potentials: low-level forces and high-level energies are all you need. 2025 , month =. doi:10.1088/2632-2153/ae040b , issn =
-
[19]
2026 , eprint=
A New Paradigm for Computational Chemistry , author=. 2026 , eprint=
2026
-
[20]
Blank, Thomas B. and Brown, Steven D. and Calhoun, August W. and Doren, Douglas J. , journal =. Neural network models of potential energy surfaces , url =. 1995 , month =. doi:10.1063/1.469597 , issn =
-
[21]
Generalized
Behler, J. Generalized. Physical Review Letters , doi =. 2007 , month =
2007
-
[22]
Gaussian
Bart. Gaussian. Physical Review Letters , doi =. 2010 , month =
2010
-
[23]
Physical Review B—Condensed Matter and Materials Physics , volume=
On representing chemical environments , author=. Physical Review B—Condensed Matter and Materials Physics , volume=. 2013 , publisher=
2013
-
[24]
Atomic cluster expansion for accurate and transferable interatomic potentials , author =. Phys. Rev. B , volume =. 2019 , month =. doi:10.1103/PhysRevB.99.014104 , url =
-
[25]
Shapeev, Alexander V. , year=. Moment Tensor Potentials: A Class of Systematically Improvable Interatomic Potentials , volume=. Multiscale Modeling & Simulation , publisher=. doi:10.1137/15m1054183 , number=
-
[26]
Deep Potential: A General Representation of a Many-Body Potential Energy Surface , volume=
Han, Jiequn and Zhang, Linfeng and Car, Roberto and E, Weinan , year=. Deep Potential: A General Representation of a Many-Body Potential Energy Surface , volume=. Communications in Computational Physics , publisher=. doi:10.4208/cicp.oa-2017-0213 , number=
-
[27]
SchNet: a continuous-filter convolutional neural network for modeling quantum interactions , year =
Sch\". SchNet: a continuous-filter convolutional neural network for modeling quantum interactions , year =. Proceedings of the 31st International Conference on Neural Information Processing Systems , pages =
-
[28]
MACE: Higher Order Equivariant Message Passing Neural Networks for Fast and Accurate Force Fields , url =
Batatia, Ilyes and Kovacs, David P and Simm, Gregor and Ortner, Christoph and Csanyi, Gabor , booktitle =. MACE: Higher Order Equivariant Message Passing Neural Networks for Fast and Accurate Force Fields , url =
-
[29]
The Eleventh International Conference on Learning Representations , year=
Equiformer: Equivariant Graph Attention Transformer for 3D Atomistic Graphs , author=. The Eleventh International Conference on Learning Representations , year=
-
[30]
and Isayev, Olexandr and Roitberg, Adrian E
Smith, Justin S. and Isayev, Olexandr and Roitberg, Adrian E. , journal =. ANI-1,. 2017 , month =. doi:10.1038/sdata.2017.193 , issn =
-
[31]
Lawrence and Ulissi, Zachary , journal =
Chanussot, Lowik and Das, Abhishek and Goyal, Siddharth and Lavril, Thibaut and Shuaibi, Muhammed and Riviere, Morgane and Tran, Kevin and Heras-Domingo, Javier and Ho, Caleb and Hu, Weihua and Palizhati, Aini and Sriram, Anuroop and Wood, Brandon and Yoon, Junwoong and Parikh, Devi and Zitnick, C. Lawrence and Ulissi, Zachary , journal =. Open. 2021 , mo...
-
[32]
Nature Machine Intelligence , author=
CHGNet as a pretrained universal neural network potential for charge-informed atomistic modelling , DOI=. Nature Machine Intelligence , author=. 2023 , pages=
2023
-
[33]
and Dzamba, Misko and Gao, Meng and Rizvi, Ammar and Zitnick, C
Barroso-Luque, Luis and Shuaibi, Muhammed and Fu, Xiang and Wood, Brandon M. and Dzamba, Misko and Gao, Meng and Rizvi, Ammar and Zitnick, C. Lawrence and Ulissi, Zachary W. , doi =. Open. 2024 , publisher =
2024
-
[34]
and Shuaibi, Muhammed and Spotte-Smith, Evan Walter Clark and Taylor, Michael G
Levine, Daniel S. and Shuaibi, Muhammed and Spotte-Smith, Evan Walter Clark and Taylor, Michael G. and Hasyim, Muhammad R. and Michel, Kyle and Batatia, Ilyes and Cs. The. doi:10.48550/ARXIV.2505.08762 , year =
-
[35]
Huang, Cancan and Rubenstein, Brenda M. , journal =. Machine. 2022 , month =. doi:10.1021/acs.jpca.2c05904 , issn =
-
[36]
The Journal of Chemical Physics , doi =
L. The Journal of Chemical Physics , doi =. 2023 , month =
2023
-
[37]
Engel and Jörg Behler and Christoph Dellago and Michele Ceriotti , title =
Bingqing Cheng and Edgar A. Engel and Jörg Behler and Christoph Dellago and Michele Ceriotti , title =. Proceedings of the National Academy of Sciences , volume =. 2019 , doi =. https://www.pnas.org/doi/pdf/10.1073/pnas.1815117116 , abstract =
-
[38]
and Behler, J
Cheng, Bingqing and Engel, Edgar A. and Behler, J. Ab initio thermodynamics of liquid and solid water , url =. Proceedings of the National Academy of Sciences , doi =. 2019 , month =
2019
-
[39]
and Bernstein, Noam and Cs
Deringer, Volker L. and Bernstein, Noam and Cs. Origins of structural and electronic transitions in disordered silicon , url =. Nature , doi =. 2021 , month =
2021
-
[40]
and Aykol, Muratahan and Cheon, Gowoon and Cubuk, Ekin Dogus , journal =
Merchant, Amil and Batzner, Simon and Schoenholz, Samuel S. and Aykol, Muratahan and Cheon, Gowoon and Cubuk, Ekin Dogus , journal =. Scaling deep learning for materials discovery , url =. 2023 , month =. doi:10.1038/s41586-023-06735-9 , issn =
-
[41]
Kozinsky, Boris and Musaelian, Albert and Johansson, Anders and Batzner, Simon , booktitle =. Scaling the. doi:10.1145/3581784.3627041 , year =
-
[42]
An efficient sparse kernel generator for O(3)-equivariant deep networks
Bharadwaj, Vivek and Glover, Austin and Bulu c , Ayd n and Demmel, James. An efficient sparse kernel generator for O(3)-equivariant deep networks. 2025 Proceedings of the Conference on Applied and Computational Discrete Algorithms ( ACDA )
2025
-
[43]
High-performance training and inference for deep equivariant interatomic potentials
Tan, Chuin Wei and Descoteaux, Marc L and Kotak, Mit and de Miranda Nascimento, Gabriel and Kavanagh, Se \'a n R and Zichi, Laura and Wang, Menghang and Saluja, Aadit and Hu, Yizhong R and Smidt, Tess and Johansson, Anders and Witt, William C and Kozinsky, Boris and Musaelian, Albert. High-performance training and inference for deep equivariant interatomi...
-
[44]
2024 , eprint=
OpenQDC: Open Quantum Data Commons , author=. 2024 , eprint=
2024
-
[45]
Amari, Shun-ichi , journal =. Natural. 1998 , month =. doi:10.1162/089976698300017746 , issn =
-
[46]
Haile, Sossina M. and Chisholm, Calum R. I. and Sasaki, Kenji and Boysen, Dane A. and Uda, Tetsuya. Solid acid proton conductors: from laboratory curiosities to fuel cell electrolytes. Faraday Discuss. 2007. doi:10.1039/B604311A
-
[47]
and Tyagi, Madhusudan and Segalman, Rachel A
Hoarfrost, Megan L. and Tyagi, Madhusudan and Segalman, Rachel A. and Reimer, Jeffrey A. , title =. The Journal of Physical Chemistry B , volume =. 2012 , doi =
2012
-
[48]
Proton dynamics of CsH2PO4 studied by quasi-elastic neutron scattering and PFG-NMR , journal =. 2008 , issn =. doi:https://doi.org/10.1016/j.ssi.2008.10.002 , url =
-
[49]
Skinner, L. B. and Benmore, C. J. and Neuefeind, J. C. and Parise, J. B. , title =. The Journal of Chemical Physics , volume =. 2014 , month =. doi:10.1063/1.4902412 , url =
-
[50]
Adafactor: Adaptive Learning Rates with Sublinear Memory Cost
Noam Shazeer and Mitchell Stern , title =. CoRR , volume =. 2018 , url =. 1804.04235 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[51]
Muon with
Lu, Binghang and Zhang, Jiahao and Lin, Guang , doi =. Muon with. 2026 , publisher =
2026
-
[52]
Advances in Neural Information Processing Systems , volume=
Smooth, exact rotational symmetrization for deep learning on point clouds , author=. Advances in Neural Information Processing Systems , volume=
-
[53]
Advances in Neural Information Processing Systems , volume=
The importance of being scalable: Improving the speed and accuracy of neural network interatomic potentials across chemical domains , author=. Advances in Neural Information Processing Systems , volume=
-
[54]
arXiv preprint arXiv:2603.06567 , year=
A recipe for scalable attention-based MLIPs: unlocking long-range accuracy with all-to-all node attention , author=. arXiv preprint arXiv:2603.06567 , year=
-
[55]
arXiv preprint arXiv:2506.23971 , year=
Uma: A family of universal models for atoms , author=. arXiv preprint arXiv:2506.23971 , year=
-
[56]
Nature Communications , year=
Optimizing cross-domain transfer for universal machine learning interatomic potentials , author=. Nature Communications , year=
-
[57]
arXiv preprint arXiv:2210.07237 , year=
Forces are not enough: Benchmark and critical evaluation for machine learning force fields with molecular simulations , author=. arXiv preprint arXiv:2210.07237 , year=
-
[58]
Nature communications , volume=
Approaching coupled cluster accuracy with a general-purpose neural network potential through transfer learning , author=. Nature communications , volume=. 2019 , publisher=
2019
-
[59]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Stable Gradients for Stable Learning at Scale in Deep Reinforcement Learning , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[60]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
A Stable Whitening Optimizer for Efficient Neural Network Training , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[61]
2025 , eprint=
DyKAF: Dynamical Kronecker Approximation of the Fisher Information Matrix for Gradient Preconditioning , author=. 2025 , eprint=
2025
-
[62]
Training Deep Learning Models with Norm-Constrained
Thomas Pethick and Wanyun Xie and Kimon Antonakopoulos and Zhenyu Zhu and Antonio Silveti-Falls and Volkan Cevher , booktitle=. Training Deep Learning Models with Norm-Constrained. 2025 , url=
2025
-
[63]
From Muon to Gluon: Bridging Theory and Practice of
Artem Riabinin and Egor Shulgin and Kaja Gruntkowska and Peter Richt. From Muon to Gluon: Bridging Theory and Practice of. 2026 , url=
2026
-
[64]
Lau, Tim Tsz-Kit and Qi Long and Weijie Su , year=
-
[65]
2026 , url=
Liming Liu and Zhenghao Xu and Zixuan Zhang and Hao Kang and Zichong Li and Chen Liang and Weizhu Chen and Tuo Zhao , booktitle=. 2026 , url=
2026
-
[66]
CoRR , volume=
Chongjie Si and Debing Zhang and Wei Shen , title=. CoRR , volume=. 2025 , month=
2025
-
[67]
2026 , eprint=
Mousse: Rectifying the Geometry of Muon with Curvature-Aware Preconditioning , author=. 2026 , eprint=
2026
-
[68]
2026 , eprint=
The Newton-Muon Optimizer , author=. 2026 , eprint=
2026
-
[69]
Liu, Jingyuan and Su, Jianlin and Yao, Xingcheng and Jiang, Zhejun and Lai, Guokun and Du, Yulun and Qin, Yidao and Xu, Weixin and Lu, Enzhe and Yan, Junjie and Chen, Yanru and Zheng, Huabin and Liu, Yibo and Liu, Shaowei and Yin, Bohong and He, Weiran and Zhu, Han and Wang, Yuzhi and Wang, Jianzhou and Dong, Mengnan and Zhang, Zheng and Kang, Yongsheng a...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.