Interpretable Question Answering on Knowledge Bases and Text
Pith reviewed 2026-05-25 16:00 UTC · model grok-4.3
The pith
Input perturbation provides better explanations for QA models on knowledge bases and text than LIME or attention.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
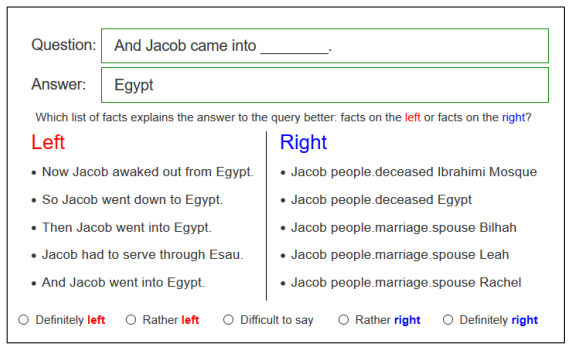
Input perturbation yields higher-quality explanations than either LIME or the model's attention mechanism when applied to question answering over combined knowledge bases and text; this superiority appears in both an automatic evaluation that measures how well explanations help identify the stronger model and in direct human judgments, and the agreement between the two evaluation routes supports treating the automatic measure as a valid proxy.
What carries the argument
Input perturbation (IP) as a post-hoc method that measures how model outputs change under controlled input changes, applied to hybrid KB-text QA and ranked against LIME and attention via automatic and human selection accuracy.
If this is right
- Input perturbation can replace or supplement attention when users need to understand why a KB-text QA system gave a particular answer.
- The automatic evaluation lets developers rank new explanation methods without running a full human study for each comparison.
- Attention weights alone are not the most reliable signal for interpretability in this class of models.
- Post-hoc perturbation methods remain effective even when the underlying model fuses structured KB facts with unstructured text.
Where Pith is reading between the lines
- The same automatic paradigm could be applied to other NLP tasks where explanation quality needs cheap, repeatable measurement.
- If input perturbation scales to larger models, production QA services might expose perturbation-derived highlights to end users by default.
- The human study design could be extended to measure whether explanations also improve users' ability to correct model errors rather than just rank models.
Load-bearing premise
The automatic evaluation measures the same thing as human judgments of which explanations are useful for spotting the better QA model.
What would settle it
A follow-up human study in which annotators given LIME or attention explanations select the stronger model more often than those given input-perturbation explanations would falsify the superiority claim.
Figures

read the original abstract
Interpretability of machine learning (ML) models becomes more relevant with their increasing adoption. In this work, we address the interpretability of ML based question answering (QA) models on a combination of knowledge bases (KB) and text documents. We adapt post hoc explanation methods such as LIME and input perturbation (IP) and compare them with the self-explanatory attention mechanism of the model. For this purpose, we propose an automatic evaluation paradigm for explanation methods in the context of QA. We also conduct a study with human annotators to evaluate whether explanations help them identify better QA models. Our results suggest that IP provides better explanations than LIME or attention, according to both automatic and human evaluation. We obtain the same ranking of methods in both experiments, which supports the validity of our automatic evaluation paradigm.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript adapts LIME and input perturbation (IP) as post-hoc explanation methods for ML-based QA models over combined knowledge bases and text. It introduces an automatic evaluation paradigm for explanation quality in this QA setting, compares the methods against the model's built-in attention, and reports a human study in which annotators use explanations to identify stronger QA models. The central claim is that IP yields better explanations than LIME or attention according to both the automatic metric and human judgments, with identical method rankings taken as evidence that the automatic paradigm is valid.
Significance. If the reported alignment between automatic and human rankings is robust, the work supplies a concrete, reproducible way to rank explanation methods for KB+text QA without requiring new human studies for every model variant. The dual-evaluation design (automatic plus human) is a positive feature that directly addresses the usual difficulty of validating interpretability claims.
major comments (2)
- [Abstract] Abstract: the statement that 'we obtain the same ranking of methods in both experiments' is presented without any statistical details (sample sizes, error bars, p-values, or inter-annotator agreement). Because the validity of the automatic paradigm rests entirely on this observed agreement, the absence of these quantities makes it impossible to judge whether the match is reliable or could arise by chance.
- [Human study section] Human evaluation (the sole external anchor for the automatic metric): the paper uses annotator decisions about which QA model is better when given explanations as the ground truth for explanation quality. No information is supplied on the number of annotators, how ties or disagreements were handled, or any measure of annotation reliability. This directly affects both the superiority claim for IP and the claim that the automatic paradigm has been validated.
minor comments (1)
- [Automatic evaluation paradigm] The precise formulation of the automatic fidelity/perturbation score for the QA setting (how answers are perturbed, how KB facts are masked, etc.) should be stated explicitly with a worked example so that the metric can be reproduced.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The points raised about statistical reporting are valid and we will revise the manuscript to include the requested details on sample sizes, error bars, p-values, annotator numbers, tie handling, and reliability measures.
read point-by-point responses
-
Referee: [Abstract] Abstract: the statement that 'we obtain the same ranking of methods in both experiments' is presented without any statistical details (sample sizes, error bars, p-values, or inter-annotator agreement). Because the validity of the automatic paradigm rests entirely on this observed agreement, the absence of these quantities makes it impossible to judge whether the match is reliable or could arise by chance.
Authors: We agree that the abstract would benefit from statistical details to support the ranking agreement claim. In the revised manuscript we will add the human study sample size, any variance or error measures from the evaluations, p-values testing the significance of the method ranking agreement (if the underlying data permit), and inter-annotator agreement statistics. These additions will allow readers to assess whether the observed alignment is robust. revision: yes
-
Referee: [Human study section] Human evaluation (the sole external anchor for the automatic metric): the paper uses annotator decisions about which QA model is better when given explanations as the ground truth for explanation quality. No information is supplied on the number of annotators, how ties or disagreements were handled, or any measure of annotation reliability. This directly affects both the superiority claim for IP and the claim that the automatic paradigm has been validated.
Authors: We concur that explicit reporting of the human evaluation protocol is necessary. The revision will specify the number of annotators, the method used to resolve ties or disagreements (e.g., majority vote), and a reliability metric such as percentage agreement or Fleiss' kappa. These details will strengthen both the claim that input perturbation yields superior explanations and the validation of the automatic evaluation paradigm. revision: yes
Circularity Check
No circularity; empirical comparisons rest on independent automatic and human evaluations
full rationale
The paper adapts existing post-hoc methods (LIME, IP) and compares them to attention via a proposed automatic evaluation paradigm plus a separate human study. Rankings are derived from these external evaluations rather than from any model-internal fitted parameters, self-definitions, or self-citation chains. No equations or derivations reduce one quantity to another by construction; the automatic paradigm is presented as a new proposal whose validity is checked against human annotators, not presupposed. This is a standard empirical setup with no load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Core assumptions of LIME (local linearity and feature independence in perturbations) transfer to the KB+text QA setting without modification.
Reference graph
Works this paper leans on
-
[1]
ENTRY address author booktitle chapter edition editor howpublished institution journal key month note number organization pages publisher school series title type volume year eprint doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRINGS urlintro eprinturl eprintpr...
-
[2]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[3]
Abdalghani Abujabal, Rishiraj Saha Roy, Mohamed Yahya, and Gerhard Weikum. 2017. https://doi.org/10.18653/v1/D17-2011 Quint: Interpretable question answering over knowledge bases . In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 61--66. Association for Computational Linguistics
-
[4]
Yonatan Bisk, Siva Reddy, John Blitzer, Julia Hockenmaier, and Mark Steedman. 2016. https://doi.org/https://doi.org/10.18653/v1/d16-1214 Evaluating induced ccg parsers on grounded semantic parsing . In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX
-
[5]
Bollacker, Colin Evans, Praveen Paritosh, Tim Sturge, and Jamie Taylor
Kurt D. Bollacker, Colin Evans, Praveen Paritosh, Tim Sturge, and Jamie Taylor. 2008. https://doi.org/https://doi.org/10.1145/1376616.1376746 Freebase: a collaboratively created graph database for structuring human knowledge . In SIGMOD Conference
-
[6]
Rajarshi Das, Manzil Zaheer, Siva Reddy, and Andrew McCallum. 2017. https://doi.org/10.18653/v1/P17-2057 Question answering on knowledge bases and text using universal schema and memory networks . In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 358--365. Association for Computation...
-
[7]
Finale Doshi-Velez and Been Kim. 2017. https://arxiv.org/abs/1702.08608 Towards a rigorous science of interpretable machine learning . arXiv preprint. ArXiv:1702.08608v2
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[8]
Evgeniy Gabrilovich, Michael Ringgaard, and Amarnag Subramanya. 2013. https://lemurproject.org/clueweb09/ Facc1: Freebase annotation of clueweb corpora, version 1 (release date 2013-06-26, format version 1, correction level 0)
work page 2013
-
[9]
Sarthak Jain and Byron C. Wallace. 2019. http://arxiv.org/abs/1902.10186 Attention is not explanation . arXiv preprint. ArXiv:1902.10186
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[10]
Jiwei Li, Will Monroe, and Dan Jurafsky. 2016. http://arxiv.org/abs/1612.08220 Understanding neural networks through representation erasure . arXiv preprint. ArXiv:1612.08220
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[11]
Zachary Chase Lipton. 2018. https://doi.org/10.1145/3236386.3241340 The mythos of model interpretability . Queue, 16(3):30:31--30:57
-
[12]
Miller, Adam Fisch, Jesse Dodge, Amir - Hossein Karimi, Antoine Bordes, and Jason Weston
Alexander H. Miller, Adam Fisch, Jesse Dodge, Amir - Hossein Karimi, Antoine Bordes, and Jason Weston. 2016. https://doi.org/10.18653/v1/D16-1147 Key-value memory networks for directly reading documents . In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pages 1400--1409. Association for Computational Linguistics
-
[13]
Selvakumar Murugan, Suriyadeepan Ramamoorthy, Vaidheeswaran Archana, and Malaikannan Sankarasubbu. 2018. https://arxiv.org/abs/1810.12698 Compositional attention networks for interpretability in natural language question answering . arXiv preprint. ArXiv:1810.12698
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[14]
Nina Poerner, Benjamin Roth, and Hinrich Sch \" u tze. 2018. https://www.aclweb.org/anthology/papers/P/P18/P18-1032/ Evaluating neural network explanation methods using hybrid documents and morphological agreement . In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Volume 1: Long Papers, pages 340--350, Melbourne,...
work page 2018
-
[15]
arXiv preprint arXiv:1802.07810, 2018
Forough Poursabzi - Sangdeh, Daniel G. Goldstein, Jake M. Hofman, Jennifer Wortman Vaughan, and Hanna M. Wallach. 2018. http://arxiv.org/abs/1802.07810 Manipulating and measuring model interpretability . arXiv preprint. ArXiv:1802.07810
-
[16]
Marco Tulio Ribeiro, Sameer Singh, and Carlos Guestrin. 2016. https://doi.org/10.1145/2939672.2939778 "why should i trust you?": Explaining the predictions of any classifier . In Proceedings of the 22Nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD '16, pages 1135--1144, New York, NY, USA. ACM
-
[17]
Sebastian Riedel, Limin Yao, Andrew Mccallum, and Benjamin M Marlin. 2013. https://www.aclweb.org/anthology/N13-1008 Relation extraction with matrix factorization and universal schemas . Proceedings of NAACL-HLT 2013, pages 74--84
work page 2013
-
[18]
Barbara Rychalska, Dominika Basaj, and Przemyslaw Biecek. 2018. http://arxiv.org/abs/1812.02205 Are you tough enough? framework for robustness validation of machine comprehension systems . In Interpretability and Robustness for Audio, Speech and Language Workshop, Montreal, Canada
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[19]
Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Batra
Ramprasaath R. Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Batra. 2017. https://doi.org/10.1109/ICCV.2017.74 Grad-cam: Visual explanations from deep networks via gradient-based localization . In 2017 IEEE International Conference on Computer Vision (ICCV), pages 618--626, Venice, Italy
-
[20]
Mantong Zhou, Minlie Huang, and Xiaoyan Zhu. 2018. https://www.aclweb.org/anthology/C18-1171 An interpretable reasoning network for multi-relation question answering . In COLING, pages 2010--2022, Sante Fe, USA
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.