Arena: a toolkit for Multi-Agent Reinforcement Learning
Pith reviewed 2026-05-24 18:33 UTC · model grok-4.3
The pith
Arena introduces modular interfaces that extend Gym wrappers to handle customizations in multi-agent reinforcement learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
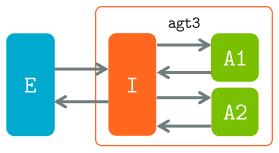
Arena claims that its Interface design manipulates observation, reward, and action routines in MARL through two mechanisms: interfaces can be concatenated and combined, and they can be placed inside either wrapped OpenAI Gym compatible environments or raw environment compatible agents, thereby extending the Gym wrapper concept to multi-agent settings and enabling off-the-shelf support for multiple platforms.
What carries the argument
Interface, a modular component that can be concatenated with others and embedded in environments or agents to customize multi-agent reinforcement learning routines.
If this is right
- Interfaces support concatenation to build complex custom observation and reward schemes.
- The same interfaces can be embedded in Gym-wrapped environments or used directly with raw agents.
- Off-the-shelf interfaces are supplied for StarCraft II, Pommerman, ViZDoom, and Soccer.
- The design enables both self-play reinforcement learning and cooperative-competitive hybrid training.
- Users can extend Arena to additional MARL platforms by writing new interfaces.
Where Pith is reading between the lines
- The modular structure could shorten the time needed to test new agent interaction rules by reusing stacked interfaces across experiments.
- Standard interfaces might make it easier to compare algorithms on the same customization layer across different base environments.
- The embedding choice between environment and agent sides could influence how easily third-party agents are integrated into training loops.
- Similar interface patterns might reduce engineering overhead when adapting single-agent environments to multi-agent versions.
Load-bearing premise
The Interface design is sufficiently general and flexible to cover the customization needs of diverse MARL platforms and scenarios without requiring substantial extra code beyond the provided interfaces.
What would settle it
A developer trying to set up a complex new MARL scenario, such as dynamic team switching in an unsupported game, still needs to write large amounts of custom code even after combining all available interfaces.
Figures













read the original abstract
We introduce Arena, a toolkit for multi-agent reinforcement learning (MARL) research. In MARL, it usually requires customizing observations, rewards and actions for each agent, changing cooperative-competitive agent-interaction, and playing with/against a third-party agent, etc. We provide a novel modular design, called Interface, for manipulating such routines in essentially two ways: 1) Different interfaces can be concatenated and combined, which extends the OpenAI Gym Wrappers concept to MARL scenarios. 2) During MARL training or testing, interfaces can be embedded in either wrapped OpenAI Gym compatible Environments or raw environment compatible Agents. We offer off-the-shelf interfaces for several popular MARL platforms, including StarCraft II, Pommerman, ViZDoom, Soccer, etc. The interfaces effectively support self-play RL and cooperative-competitive hybrid MARL. Also, Arena can be conveniently extended to your own favorite MARL platform.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Arena, a toolkit for multi-agent reinforcement learning (MARL) research. It presents a novel modular design called Interface that allows different interfaces to be concatenated and combined to customize observations, rewards, and actions for agents in MARL scenarios, extending the concept of OpenAI Gym Wrappers. These interfaces can be embedded either in wrapped Gym-compatible environments or in raw environment-compatible agents. The toolkit provides off-the-shelf interfaces for platforms such as StarCraft II, Pommerman, ViZDoom, and Soccer, supporting self-play RL and cooperative-competitive hybrid MARL, and is designed to be extensible to other platforms.
Significance. If the Interface design functions as described, it could provide a valuable tool for MARL researchers by offering a flexible, composable way to handle agent-specific customizations and interactions, building upon the popular Gym framework. This has the potential to reduce development effort for complex MARL setups involving self-play and mixed cooperative-competitive dynamics.
major comments (1)
- [Abstract] Abstract: The central claim that the Interface design 'effectively support[s] self-play RL and cooperative-competitive hybrid MARL' and extends Gym Wrappers via concatenation/embedding is presented without any code snippets, usage examples, or verification steps in the manuscript. This leaves the generality and practicality of the design (the weakest assumption noted in the review) unsubstantiated, which is load-bearing for the paper's contribution as a toolkit.
minor comments (1)
- The abstract uses vague phrasing such as 'etc.' when listing customization routines; replacing this with a short enumerated list of additional examples would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the positive assessment and the specific suggestion for improvement. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the Interface design 'effectively support[s] self-play RL and cooperative-competitive hybrid MARL' and extends Gym Wrappers via concatenation/embedding is presented without any code snippets, usage examples, or verification steps in the manuscript. This leaves the generality and practicality of the design (the weakest assumption noted in the review) unsubstantiated, which is load-bearing for the paper's contribution as a toolkit.
Authors: We agree that the abstract (and, upon re-examination, the main text) would benefit from explicit usage examples to demonstrate concatenation/embedding and the resulting support for self-play and hybrid settings. The manuscript describes the two embedding modes and lists the provided interfaces for StarCraft II, Pommerman, etc., but does not include concrete code or verification steps. We will add a short usage example (including a code snippet) in the revised manuscript, most naturally in Section 3 or a new short “Usage” subsection, to make the practicality of the design explicit. revision: yes
Circularity Check
No significant circularity
full rationale
The paper presents a software toolkit and modular Interface design for MARL environments. It contains no equations, derivations, predictions, fitted parameters, or uniqueness theorems. The central claims concern concatenation of interfaces and dual embedding (environment or agent), which are described as design features without any reduction to self-referential inputs or self-citations that bear the load of a result. This is a pure architecture description whose correctness is evaluated by implementation and usage rather than internal logical closure.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Interface
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Human-level control through deep reinforce- ment learning
Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A Rusu, Joel Veness, Marc G Bellemare, Alex Graves, Martin Riedmiller, Andreas K Fid- jeland, Georg Ostrovski, Stig Petersen, Charles Beattie, Amir Sadik, Ioan- nis Antonoglou, Helen King, Dharshan Kumaran, Daan Wierstra, Shane Legg, and Demis Hassabis. Human-level control through deep reinforce- men...
work page 2015
-
[2]
Mas- tering the game of go with deep neural networks and tree search
David Silver, Aja Huang, Chris J Maddison, Arthur Guez, Laurent Sifre, George Van Den Driessche, Julian Schrittwieser, Ioannis Antonoglou, Veda Panneershelvam, Marc Lanctot, Sander Dieleman, Dominik Grewe, John Nham, Nal Kalchbrenner, Ilya Sutskever, Timothy Lillicrap, Madeleine Leach, Koray Kavukcuoglu, Thore Graepel, and Demis Hassabis. Mas- tering the ...
work page 2016
- [3]
-
[4]
Max Jaderberg, Wojciech M. Czarnecki, Iain Dunning, Luke Marris, Guy Lever, Antonio Garc´ ıa Casta˜ neda, Charles Beattie, Neil C. Rabinowitz, Ari S. Morcos, Avraham Ruderman, Nicolas Sonnerat, Tim Green, Louise Deason, Joel Z. Leibo, David Silver, Demis Hassabis, Koray Kavukcuoglu, and Thore Graepel. Human-level performance in first-person multi- player g...
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[5]
Alphastar: Mastering the real-time strategy game starcraft ii
The AlphaStar team. Alphastar: Mastering the real-time strategy game starcraft ii. https://deepmind.com/blog/ alphastar-mastering-real-time-strategy-game-starcraft-ii/ , 2019
work page 2019
-
[6]
Greg Brockman, Vicki Cheung, Ludwig Pettersson, Jonas Schneider, John Schulman, Jie Tang, and Wojciech Zaremba. Openai gym, 2016
work page 2016
-
[7]
Charles Beattie, Joel Z Leibo, Denis Teplyashin, Tom Ward, Marcus Wain- wright, Heinrich K¨ uttler, Andrew Lefrancq, Simon Green, V´ ıctor Vald´ es, Amir Sadik, et al. Deepmind lab. arXiv preprint arXiv:1612.03801 , 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[8]
Gotta Learn Fast: A New Benchmark for Generalization in RL
Alex Nichol, Vicki Pfau, Christopher Hesse, Oleg Klimov, and John Schul- man. Gotta learn fast: A new benchmark for generalization in rl. arXiv preprint arXiv:1804.03720, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[9]
Yuval Tassa, Yotam Doron, Alistair Muldal, Tom Erez, Yazhe Li, Diego de Las Casas, David Budden, Abbas Abdolmaleki, Josh Merel, Andrew Lefrancq, et al. Deepmind control suite. arXiv preprint arXiv:1801.00690 , 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[10]
Richard Bellman. A markovian decision process. Journal of Mathematics and Mechanics, pages 679–684, 1957
work page 1957
-
[11]
Optimal control of markov processes with incom- plete state information
Karl Johan ˚Astr¨ om. Optimal control of markov processes with incom- plete state information. Journal of Mathematical Analysis and Applica- tions, 10(1):174–205, 1965
work page 1965
-
[12]
Lloyd S Shapley. Stochastic games. Proceedings of the national academy of sciences, 39(10):1095–1100, 1953
work page 1953
-
[13]
Counterfactual multi-agent policy gra- dients
Jakob N Foerster, Gregory Farquhar, Triantafyllos Afouras, Nantas Nardelli, and Shimon Whiteson. Counterfactual multi-agent policy gra- dients. In Thirty-Second AAAI Conference on Artificial Intelligence , 2018
work page 2018
-
[14]
Grid-wise control for multi-agent reinforce- ment learning in video game AI
Lei Han, Peng Sun, Yali Du, Jiechao Xiong, Qing Wang, Xinghai Sun, Han Liu, and Tong Zhang. Grid-wise control for multi-agent reinforce- ment learning in video game AI. In Proceedings of the 36th International Conference on Machine Learning (ICML) , pages 2576–2585, 2019
work page 2019
-
[15]
Emergence of Grounded Compositional Language in Multi-Agent Populations
Igor Mordatch and Pieter Abbeel. Emergence of grounded compositional language in multi-agent populations. arXiv preprint arXiv:1703.04908 , 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[16]
Emergent Complexity via Multi-Agent Competition
Trapit Bansal, Jakub Pachocki, Szymon Sidor, Ilya Sutskever, and Igor Mordatch. Emergent complexity via multi-agent competition. arXiv preprint arXiv:1710.03748, 2017. 10
work page internal anchor Pith review Pith/arXiv arXiv 2017
- [17]
-
[18]
StarCraft II: A New Challenge for Reinforcement Learning
Oriol Vinyals, Timo Ewalds, Sergey Bartunov, Petko Georgiev, Alexan- der Sasha Vezhnevets, Michelle Yeo, Alireza Makhzani, Heinrich K¨ uttler, John Agapiou, Julian Schrittwieser, John Quan, Stephen Gaffney, Stig Pe- tersen, Karen Simonyan, Tom Schaul, Hado van Hasselt, David Silver, Tim- othy P. Lillicrap, Kevin Calderone, Paul Keet, Anthony Brunasso, Davi...
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[19]
Pommerman: A multi- agent playground
Cinjon Resnick, Wes Eldridge, David Ha, Denny Britz, Jakob Foerster, Julian Togelius, Kyunghyun Cho, and Joan Bruna. Pommerman: A multi- agent playground. arXiv preprint arXiv:1809.07124 , 2018
-
[20]
Vizdoom com- petitions: Playing doom from pixels
Marek Wydmuch, Micha l Kempka, and Wojciech Ja´ skowski. Vizdoom com- petitions: Playing doom from pixels. IEEE Transactions on Games , 2018
work page 2018
-
[21]
Emergent coordination through competition
Siqi Liu, Guy Lever, Josh Merel, Saran Tunyasuvunakool, Nicolas Heess, and Thore Graepel. Emergent coordination through competition. arXiv preprint arXiv:1902.07151, 2019
-
[22]
Xinghai Sun. Xinghai sun pong. https://github.com/xinghai-sun/ deep-rl/blob/master/docs/selfplay_pong.md
-
[23]
Steven Hewitt. Steven hewitt pong. https://github.com/ Steven-Hewitt/Multi-Agent-Pong-Rally
-
[24]
TStarBots: Defeating the Cheating Level Builtin AI in StarCraft II in the Full Game
Peng Sun, Xinghai Sun, Lei Han, Jiechao Xiong, Qing Wang, Bo Li, Yang Zheng, Ji Liu, Yongsheng Liu, Han Liu, and Tong Zhang. Tstarbots: De- feating the cheating level builtin ai in starcraft ii in the full game. arXiv preprint arXiv:1809.07193, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[25]
ViZDoom: A Doom-based AI research platform for visual reinforcement learning
Micha l Kempka, Marek Wydmuch, Grzegorz Runc, Jakub Toczek, and Wo- jciech Ja´ skowski. ViZDoom: A Doom-based AI research platform for visual reinforcement learning. In IEEE Conference on Computational Intelligence and Games, pages 341–348, Santorini, Greece, Sep 2016. IEEE. The best paper award
work page 2016
-
[26]
Training agent for first-person shooter game with actor-critic curriculum learning
Yuxin Wu and Yuandong Tian. Training agent for first-person shooter game with actor-critic curriculum learning. In ICLR, 2016
work page 2016
-
[27]
Learning to act by predicting the future
Alexey Dosovitskiy and Vladlen Koltun. Learning to act by predicting the future. In ICLR, 2017
work page 2017
-
[28]
Combo-action: Training agent for fps game with auxiliary tasks
Shiyu Huang, Hang Su, Jun Zhu, and Ting Chen. Combo-action: Training agent for fps game with auxiliary tasks. In AAAI, 2019. 11
work page 2019
-
[29]
Emanuel Todorov, Tom Erez, and Yuval Tassa. Mujoco: A physics engine for model-based control. In Intelligent Robots and Systems (IROS), 2012 IEEE/RSJ International Conference on , pages 5026–5033. IEEE, 2012. 12 A List of supported environments A.1 Pong-2p Pong-2p (Pong of 2 players) is much like the Atari Pong [6], except that the two players on both sid...
work page 2012
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.