Enhancing Trust in Large Language Models via Uncertainty-Calibrated Fine-Tuning
Pith reviewed 2026-05-23 07:43 UTC · model grok-4.3
The pith
An uncertainty-aware loss during fine-tuning produces better-calibrated probability estimates from large language models without hurting task accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Replacing the standard causal language modeling loss with an uncertainty-aware variant derived from decision theory during fine-tuning produces probability estimates whose calibration error is lower on natural language generation tasks, while task accuracy remains comparable; the same models also become better at detecting hallucinations and out-of-domain prompts.
What carries the argument
The uncertainty-aware causal language modeling loss, obtained by applying decision-theoretic principles to the usual next-token objective.
If this is right
- The same loss can be plugged into any autoregressive fine-tuning pipeline without changing the model architecture.
- Better-calibrated uncertainty scores become available for downstream filtering or abstention decisions on generated text.
- Hallucination detectors that rely on token probabilities gain reliability when the underlying model was fine-tuned with this loss.
Where Pith is reading between the lines
- The approach might generalize to tasks outside free-form QA if the decision-theoretic loss is applied to other autoregressive objectives.
- If the loss improves calibration on the training distribution, it could also reduce over on shifted distributions that share similar token statistics.
Load-bearing premise
Optimizing the new decision-theoretic loss on the fine-tuning data improves calibration on future data drawn from the same distribution and does not trade off against accuracy.
What would settle it
On a held-out free-form QA dataset, a model fine-tuned with the new loss shows higher expected calibration error or lower hallucination-detection AUC than the same model fine-tuned with the ordinary causal language modeling loss.
Figures

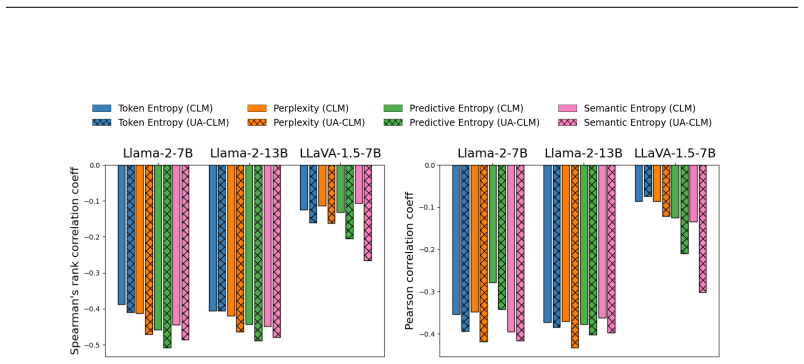
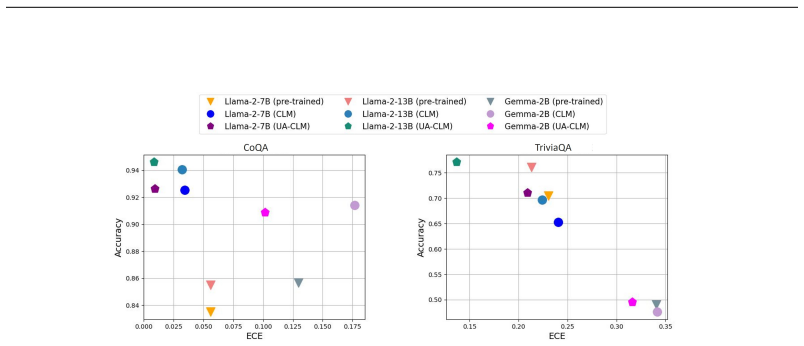



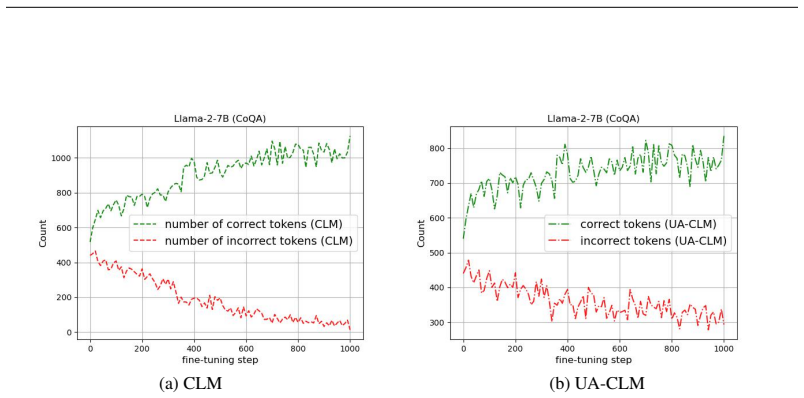







read the original abstract
Large language models (LLMs) have revolutionized the field of natural language processing with their impressive reasoning and question-answering capabilities. However, these models are sometimes prone to generating credible-sounding but incorrect information, a phenomenon known as LLM hallucinations. Reliable uncertainty estimation in LLMs is essential for fostering trust in their generated responses and serves as a critical tool for the detection and prevention of erroneous or hallucinated outputs. To achieve reliable and well-calibrated uncertainty quantification in open-ended and free-form natural language generation, we propose an uncertainty-aware fine-tuning approach for LLMs. This approach enhances the model's ability to provide reliable uncertainty estimates without compromising accuracy, thereby guiding them to produce more trustworthy responses. We introduce a novel uncertainty-aware causal language modeling loss function, grounded in the principles of decision theory. Through rigorous evaluation on multiple free-form question-answering datasets and models, we demonstrate that our uncertainty-aware fine-tuning approach yields better calibrated uncertainty estimates in natural language generation tasks than fine-tuning with the standard causal language modeling loss. Furthermore, the experimental results show that the proposed method significantly improves the model's ability to detect hallucinations and identify out-of-domain prompts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an uncertainty-aware fine-tuning approach for LLMs that replaces the standard causal language modeling loss with a novel loss derived from decision theory. The central claim is that this yields better-calibrated uncertainty estimates on free-form QA tasks than standard fine-tuning, while preserving accuracy and improving hallucination detection and OOD identification, with supporting results reported across multiple datasets and models.
Significance. If the empirical claims hold with proper quantitative support, the work would be significant for LLM reliability: a decision-theoretic loss that improves calibration without accuracy trade-offs could directly aid hallucination mitigation and user trust. The grounding in decision theory and the focus on open-ended generation are positive differentiators from heuristic calibration methods.
major comments (2)
- [Abstract] Abstract: the claim that the method 'yields better calibrated uncertainty estimates' and 'significantly improves' hallucination detection is presented without any numerical results, baselines, metrics (e.g., ECE, AUROC), statistical tests, or implementation details. This absence makes the data-to-claim link unevaluable and is load-bearing for the central empirical contribution.
- [Evaluation / Experiments] The weakest assumption (that the new loss improves calibration while preserving accuracy and generalizing) is stated but not yet supported by evidence in the provided description; the evaluation section must supply the missing quantitative comparisons and controls to substantiate it.
minor comments (2)
- [Method] Clarify whether the decision-theoretic loss introduces any new hyperparameters and how they are chosen or shown to be robust.
- [Experiments] Add explicit comparison to existing calibration techniques (e.g., temperature scaling, post-hoc methods) in addition to the standard LM loss baseline.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address the two major comments below. We agree that the abstract requires quantitative support and will revise it; the evaluation section already contains the requested comparisons but will be expanded for clarity.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the method 'yields better calibrated uncertainty estimates' and 'significantly improves' hallucination detection is presented without any numerical results, baselines, metrics (e.g., ECE, AUROC), statistical tests, or implementation details. This absence makes the data-to-claim link unevaluable and is load-bearing for the central empirical contribution.
Authors: We agree that the abstract would be strengthened by including key numerical results. In the revised version we will add specific metrics (e.g., ECE reductions, AUROC gains for hallucination detection), mention the main baselines, models, and datasets, and note that statistical significance was assessed. This change directly addresses the data-to-claim concern while preserving the abstract's brevity. revision: yes
-
Referee: [Evaluation / Experiments] The weakest assumption (that the new loss improves calibration while preserving accuracy and generalizing) is stated but not yet supported by evidence in the provided description; the evaluation section must supply the missing quantitative comparisons and controls to substantiate it.
Authors: The full manuscript already reports results across multiple free-form QA datasets and models, showing improved calibration (via ECE and related metrics), maintained accuracy, and gains in hallucination detection and OOD identification. To make this support more explicit, we will add further quantitative tables, additional baseline comparisons, statistical tests, and implementation details in the evaluation section. revision: partial
Circularity Check
No significant circularity identified
full rationale
The paper presents a novel uncertainty-aware causal language modeling loss derived from decision theory principles, with empirical evaluations on multiple datasets showing improved calibration over standard fine-tuning. No load-bearing step reduces by construction to fitted inputs, self-citations, or renamings; the derivation chain and performance claims remain independent of the reported results themselves. The abstract and described approach contain no self-definitional or fitted-prediction patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A review of uncertainty quantification in deep learning: Techniques, applications and challenges
Moloud Abdar, Farhad Pourpanah, Sadiq Hussain, Dana Rezazadegan, Li Liu, Mohammad Ghavamzadeh, Paul Fieguth, Xiaochun Cao, Abbas Khosravi, U Rajendra Acharya, et al. A review of uncertainty quantification in deep learning: Techniques, applications and challenges. Information fusion, 76: 0 243--297, 2021
work page 2021
-
[2]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Creating trustworthy llms: Dealing with hallucinations in healthcare ai
Muhammad Aurangzeb Ahmad, Ilker Yaramis, and Taposh Dutta Roy. Creating trustworthy llms: Dealing with hallucinations in healthcare ai. arXiv preprint arXiv:2311.01463, 2023
-
[4]
Concrete Problems in AI Safety
Dario Amodei, Chris Olah, Jacob Steinhardt, Paul Christiano, John Schulman, and Dan Man \'e . Concrete problems in ai safety. arXiv preprint arXiv:1606.06565, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[5]
Linguistic calibration of long-form generations
Neil Band, Xuechen Li, Tengyu Ma, and Tatsunori Hashimoto. Linguistic calibration of long-form generations. In Forty-first International Conference on Machine Learning, 2024. URL https://openreview.net/forum?id=rJVjQSQ8ye
work page 2024
-
[6]
Pearson correlation coefficient
Jacob Benesty, Jingdong Chen, Yiteng Huang, and Israel Cohen. Pearson correlation coefficient. In Noise reduction in speech processing, pp.\ 37--40. Springer, 2009
work page 2009
-
[7]
Confabulations: a conceptual history
German E Berrios. Confabulations: a conceptual history. Journal of the History of the Neurosciences, 7 0 (3): 0 225--241, 1998
work page 1998
-
[8]
Weight uncertainty in neural network
Charles Blundell, Julien Cornebise, Koray Kavukcuoglu, and Daan Wierstra. Weight uncertainty in neural network. In International conference on machine learning, pp.\ 1613--1622. PMLR, 2015
work page 2015
-
[9]
The relationship between precision-recall and roc curves
Jesse Davis and Mark Goadrich. The relationship between precision-recall and roc curves. In Proceedings of the 23rd international conference on Machine learning, pp.\ 233--240, 2006
work page 2006
-
[10]
Calibration of pre-trained transformers
Shrey Desai and Greg Durrett. Calibration of pre-trained transformers. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp.\ 295--302, 2020
work page 2020
-
[11]
Determinants of llm-assisted decision-making
Eva Eigner and Thorsten H \"a ndler. Determinants of llm-assisted decision-making. arXiv preprint arXiv:2402.17385, 2024
-
[12]
Lm-polygraph: Uncertainty estimation for language models
Ekaterina Fadeeva, Roman Vashurin, Akim Tsvigun, Artem Vazhentsev, Sergey Petrakov, Kirill Fedyanin, Daniil Vasilev, Elizaveta Goncharova, Alexander Panchenko, Maxim Panov, et al. Lm-polygraph: Uncertainty estimation for language models. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pp.\ ...
work page 2023
-
[13]
Detecting hallucinations in large language models using semantic entropy
Sebastian Farquhar, Jannik Kossen, Lorenz Kuhn, and Yarin Gal. Detecting hallucinations in large language models using semantic entropy. Nature, 630 0 (8017): 0 625--630, 2024
work page 2024
-
[14]
Unsupervised quality estimation for neural machine translation
Marina Fomicheva, Shuo Sun, Lisa Yankovskaya, Fr \'e d \'e ric Blain, Francisco Guzm \'a n, Mark Fishel, Nikolaos Aletras, Vishrav Chaudhary, and Lucia Specia. Unsupervised quality estimation for neural machine translation. Transactions of the Association for Computational Linguistics, 8: 0 539--555, 2020
work page 2020
-
[15]
A survey of uncertainty in deep neural networks
Jakob Gawlikowski, Cedrique Rovile Njieutcheu Tassi, Mohsin Ali, Jongseok Lee, Matthias Humt, Jianxiang Feng, Anna Kruspe, Rudolph Triebel, Peter Jung, Ribana Roscher, et al. A survey of uncertainty in deep neural networks. Artificial Intelligence Review, 56 0 (Suppl 1): 0 1513--1589, 2023
work page 2023
-
[16]
Gemma: Open Models Based on Gemini Research and Technology
Gemma, Thomas Mesnard, Cassidy Hardin, Robert Dadashi, Surya Bhupatiraju, Shreya Pathak, Laurent Sifre, Morgane Rivi \`e re, Mihir Sanjay Kale, Juliette Love, et al. Gemma: Open models based on gemini research and technology. arXiv preprint arXiv:2403.08295, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
A survey of confidence estimation and calibration in large language models
Jiahui Geng, Fengyu Cai, Yuxia Wang, Heinz Koeppl, Preslav Nakov, and Iryna Gurevych. A survey of confidence estimation and calibration in large language models. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pp.\ 6577--6595, 2024
work page 2024
-
[18]
On calibration of modern neural networks
Chuan Guo, Geoff Pleiss, Yu Sun, and Kilian Q Weinberger. On calibration of modern neural networks. In International conference on machine learning, pp.\ 1321--1330. PMLR, 2017
work page 2017
-
[19]
Augmix: A simple data processing method to improve robustness and uncertainty
Dan Hendrycks, Norman Mu, Ekin Dogus Cubuk, Barret Zoph, Justin Gilmer, and Balaji Lakshminarayanan. Augmix: A simple data processing method to improve robustness and uncertainty. In International Conference on Learning Representations, 2020
work page 2020
-
[20]
Parameter-efficient transfer learning for nlp
Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin De Laroussilhe, Andrea Gesmundo, Mona Attariyan, and Sylvain Gelly. Parameter-efficient transfer learning for nlp. In International conference on machine learning, pp.\ 2790--2799. PMLR, 2019
work page 2019
-
[21]
Lora: Low-rank adaptation of large language models
Edward J Hu, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models. In International Conference on Learning Representations, 2022
work page 2022
-
[22]
Survey of hallucination in natural language generation
Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Ye Jin Bang, Andrea Madotto, and Pascale Fung. Survey of hallucination in natural language generation. ACM Computing Surveys, 55 0 (12): 0 1--38, 2023
work page 2023
-
[23]
Zhengbao Jiang, Jun Araki, Haibo Ding, and Graham Neubig. How can we know when language models know? on the calibration of language models for question answering. Transactions of the Association for Computational Linguistics, 9: 0 962--977, 2021
work page 2021
-
[24]
Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension
Mandar Joshi, Eunsol Choi, Daniel S Weld, and Luke Zettlemoyer. Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp.\ 1601--1611, 2017
work page 2017
-
[25]
Language Models (Mostly) Know What They Know
Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran-Johnson, et al. Language models (mostly) know what they know. arXiv preprint arXiv:2207.05221, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[26]
Calibration-tuning: Teaching large language models to know what they don’t know
Sanyam Kapoor, Nate Gruver, Manley Roberts, Arka Pal, Samuel Dooley, Micah Goldblum, and Andrew Wilson. Calibration-tuning: Teaching large language models to know what they don’t know. In Proceedings of the 1st Workshop on Uncertainty-Aware NLP (UncertaiNLP 2024), pp.\ 1--14, 2024
work page 2024
-
[27]
Soft calibration objectives for neural networks
Archit Karandikar, Nicholas Cain, Dustin Tran, Balaji Lakshminarayanan, Jonathon Shlens, Michael C Mozer, and Becca Roelofs. Soft calibration objectives for neural networks. Advances in Neural Information Processing Systems, 34: 0 29768--29779, 2021
work page 2021
-
[28]
Calibrated language model fine-tuning for in-and out-of-distribution data
Lingkai Kong, Haoming Jiang, Yuchen Zhuang, Jie Lyu, Tuo Zhao, and Chao Zhang. Calibrated language model fine-tuning for in-and out-of-distribution data. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp.\ 1326--1340, 2020
work page 2020
-
[29]
Improving model calibration with accuracy versus uncertainty optimization
Ranganath Krishnan and Omesh Tickoo. Improving model calibration with accuracy versus uncertainty optimization. Advances in Neural Information Processing Systems, 33: 0 18237--18248, 2020
work page 2020
-
[30]
Bioasq-qa: A manually curated corpus for biomedical question answering
Anastasia Krithara, Anastasios Nentidis, Konstantinos Bougiatiotis, and Georgios Paliouras. Bioasq-qa: A manually curated corpus for biomedical question answering. Scientific Data, 10 0 (1): 0 170, 2023
work page 2023
-
[31]
Lorenz Kuhn, Yarin Gal, and Sebastian Farquhar. Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation. In The Eleventh International Conference on Learning Representations, 2023
work page 2023
-
[32]
Meelis Kull, Telmo Silva Filho, and Peter Flach. Beta calibration: a well-founded and easily implemented improvement on logistic calibration for binary classifiers. In Artificial intelligence and statistics, pp.\ 623--631. PMLR, 2017
work page 2017
-
[33]
Trainable calibration measures for neural networks from kernel mean embeddings
Aviral Kumar, Sunita Sarawagi, and Ujjwal Jain. Trainable calibration measures for neural networks from kernel mean embeddings. In International Conference on Machine Learning, pp.\ 2805--2814. PMLR, 2018
work page 2018
-
[34]
arXiv preprint arXiv:2305.18404 , year=
Bhawesh Kumar, Charlie Lu, Gauri Gupta, Anil Palepu, David Bellamy, Ramesh Raskar, and Andrew Beam. Conformal prediction with large language models for multi-choice question answering. arXiv preprint arXiv:2305.18404, 2023
-
[35]
Simple and scalable predictive uncertainty estimation using deep ensembles
Balaji Lakshminarayanan, Alexander Pritzel, and Charles Blundell. Simple and scalable predictive uncertainty estimation using deep ensembles. Advances in neural information processing systems, 30, 2017
work page 2017
-
[36]
Chin-Yew Lin and Franz Josef Och. Automatic evaluation of machine translation quality using longest common subsequence and skip-bigram statistics. In Proceedings of the 42nd annual meeting of the association for computational linguistics (ACL-04), pp.\ 605--612, 2004
work page 2004
-
[37]
Generating with confidence: Uncertainty quantification for black-box large language models
Zhen Lin, Shubhendu Trivedi, and Jimeng Sun. Generating with confidence: Uncertainty quantification for black-box large language models. Transactions on Machine Learning Research, 2024
work page 2024
-
[38]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. Advances in neural information processing systems, 36, 2024 a
work page 2024
-
[39]
Pengfei Liu, Weizhe Yuan, Jinlan Fu, Zhengbao Jiang, Hiroaki Hayashi, and Graham Neubig. Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing. ACM Computing Surveys, 55 0 (9): 0 1--35, 2023
work page 2023
-
[40]
Litcab: Lightweight language model calibration over short-and long-form responses
Xin Liu, Muhammad Khalifa, and Lu Wang. Litcab: Lightweight language model calibration over short-and long-form responses. In The Twelfth International Conference on Learning Representations, 2024 b
work page 2024
-
[41]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. In International Conference on Learning Representations, 2019
work page 2019
-
[42]
Hallucination-free? assessing the reliability of leading ai legal research tools
Varun Magesh, Faiz Surani, Matthew Dahl, Mirac Suzgun, Christopher D Manning, and Daniel E Ho. Hallucination-free? assessing the reliability of leading ai legal research tools. arXiv preprint arXiv:2405.20362, 2024
-
[43]
Uncertainty estimation in autoregressive structured prediction
Andrey Malinin and Mark Gales. Uncertainty estimation in autoregressive structured prediction. In International Conference on Learning Representations, 2021
work page 2021
-
[44]
Peft: State-of-the-art parameter-efficient fine-tuning methods
Sourab Mangrulkar, Sylvain Gugger, Lysandre Debut, Younes Belkada, Sayak Paul, and Benjamin Bossan. Peft: State-of-the-art parameter-efficient fine-tuning methods. https://github.com/huggingface/peft, 2022
work page 2022
-
[45]
Ok-vqa: A visual question answering benchmark requiring external knowledge
Kenneth Marino, Mohammad Rastegari, Ali Farhadi, and Roozbeh Mottaghi. Ok-vqa: A visual question answering benchmark requiring external knowledge. In Proceedings of the IEEE/cvf conference on computer vision and pattern recognition, pp.\ 3195--3204, 2019
work page 2019
-
[46]
Factscore: Fine-grained atomic evaluation of factual precision in long form text generation
Sewon Min, Kalpesh Krishna, Xinxi Lyu, Mike Lewis, Wen-tau Yih, Pang Wei Koh, Mohit Iyyer, Luke Zettlemoyer, and Hannaneh Hajishirzi. Factscore: Fine-grained atomic evaluation of factual precision in long form text generation. In The 2023 Conference on Empirical Methods in Natural Language Processing, 2023
work page 2023
-
[47]
Revisiting the calibration of modern neural networks
Matthias Minderer, Josip Djolonga, Rob Romijnders, Frances Hubis, Xiaohua Zhai, Neil Houlsby, Dustin Tran, and Mario Lucic. Revisiting the calibration of modern neural networks. Advances in Neural Information Processing Systems, 34: 0 15682--15694, 2021
work page 2021
-
[48]
Calibrating deep neural networks using focal loss
Jishnu Mukhoti, Viveka Kulharia, Amartya Sanyal, Stuart Golodetz, Philip Torr, and Puneet Dokania. Calibrating deep neural networks using focal loss. Advances in Neural Information Processing Systems, 33: 0 15288--15299, 2020
work page 2020
-
[49]
Machine learning: a probabilistic perspective
Kevin P Murphy. Machine learning: a probabilistic perspective. MIT press, 2012
work page 2012
-
[50]
Accuracy-rejection curves (arcs) for comparing classification methods with a reject option
Malik Sajjad Ahmed Nadeem, Jean-Daniel Zucker, and Blaise Hanczar. Accuracy-rejection curves (arcs) for comparing classification methods with a reject option. In Machine Learning in Systems Biology, pp.\ 65--81. PMLR, 2009
work page 2009
-
[51]
Obtaining well calibrated probabilities using bayesian binning
Mahdi Pakdaman Naeini, Gregory Cooper, and Milos Hauskrecht. Obtaining well calibrated probabilities using bayesian binning. In Proceedings of the AAAI conference on artificial intelligence, volume 29, 2015
work page 2015
-
[52]
Measuring calibration in deep learning
Jeremy Nixon, Michael W Dusenberry, Linchuan Zhang, Ghassen Jerfel, and Dustin Tran. Measuring calibration in deep learning. In CVPR workshops, 2019
work page 2019
-
[53]
Softmax probabilities (mostly) predict large language model correctness on multiple-choice q&a
Benjamin Plaut, Khanh Nguyen, and Tu Trinh. Softmax probabilities (mostly) predict large language model correctness on multiple-choice q&a. arXiv preprint arXiv:2402.13213, 2024
-
[54]
Coqa: A conversational question answering challenge
Siva Reddy, Danqi Chen, and Christopher D Manning. Coqa: A conversational question answering challenge. Transactions of the Association for Computational Linguistics, 7: 0 249--266, 2019
work page 2019
-
[55]
Out-of-distribution detection and selective generation for conditional language models
Jie Ren, Jiaming Luo, Yao Zhao, Kundan Krishna, Mohammad Saleh, Balaji Lakshminarayanan, and Peter J Liu. Out-of-distribution detection and selective generation for conditional language models. In The Eleventh International Conference on Learning Representations, 2022
work page 2022
-
[56]
Takaya Saito and Marc Rehmsmeier. The precision-recall plot is more informative than the roc plot when evaluating binary classifiers on imbalanced datasets. PloS one, 10 0 (3): 0 e0118432, 2015
work page 2015
-
[57]
On mixup training: Improved calibration and predictive uncertainty for deep neural networks
Sunil Thulasidasan, Gopinath Chennupati, Jeff A Bilmes, Tanmoy Bhattacharya, and Sarah Michalak. On mixup training: Improved calibration and predictive uncertainty for deep neural networks. Advances in neural information processing systems, 32, 2019
work page 2019
-
[58]
Katherine Tian, Eric Mitchell, Allan Zhou, Archit Sharma, Rafael Rafailov, Huaxiu Yao, Chelsea Finn, and Christopher D Manning. Just ask for calibration: Strategies for eliciting calibrated confidence scores from language models fine-tuned with human feedback. In The 2023 Conference on Empirical Methods in Natural Language Processing, 2023
work page 2023
-
[59]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[60]
Adamix: Mixture-of-adaptations for parameter-efficient model tuning
Yaqing Wang, Sahaj Agarwal, Subhabrata Mukherjee, Xiaodong Liu, Jing Gao, Ahmed Hassan, and Jianfeng Gao. Adamix: Mixture-of-adaptations for parameter-efficient model tuning. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pp.\ 5744--5760, 2022
work page 2022
-
[61]
Neural text generation with unlikelihood training
Sean Welleck, Ilia Kulikov, Stephen Roller, Emily Dinan, Kyunghyun Cho, and Jason Weston. Neural text generation with unlikelihood training. In International Conference on Learning Representations, 2020
work page 2020
-
[62]
Quantifying uncertainties in natural language processing tasks
Yijun Xiao and William Yang Wang. Quantifying uncertainties in natural language processing tasks. In Proceedings of the AAAI conference on artificial intelligence, pp.\ 7322--7329, 2019
work page 2019
-
[63]
Can llms express their uncertainty? an empirical evaluation of confidence elicitation in llms
Miao Xiong, Zhiyuan Hu, Xinyang Lu, YIFEI LI, Jie Fu, Junxian He, and Bryan Hooi. Can llms express their uncertainty? an empirical evaluation of confidence elicitation in llms. In The Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[64]
Can we trust llms? mitigate overconfidence bias in llms through knowledge transfer
Haoyan Yang, Yixuan Wang, Xingyin Xu, Hanyuan Zhang, and Yirong Bian. Can we trust llms? mitigate overconfidence bias in llms through knowledge transfer. arXiv preprint arXiv:2405.16856, 2024
-
[65]
Bertscore: Evaluating text generation with bert
Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q Weinberger, and Yoav Artzi. Bertscore: Evaluating text generation with bert. In International Conference on Learning Representations, 2020
work page 2020
-
[66]
CRC standard probability and statistics tables and formulae
Daniel Zwillinger and Stephen Kokoska. CRC standard probability and statistics tables and formulae. Crc Press, 1999
work page 1999
-
[67]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[68]
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[69]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[70]
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.