MusicInfuser: Making Video Diffusion Listen and Dance
Pith reviewed 2026-05-22 23:24 UTC · model grok-4.3
The pith
Pre-trained text-to-video diffusion models can be adapted to generate dance videos synchronized with music by selectively fine-tuning layers identified via a constructive influence function.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MusicInfuser adapts pre-trained text-to-video diffusion models to generate high-quality dance videos synchronized with specified music tracks. It uses a novel layer-wise adaptability criterion based on a guidance-inspired constructive influence function to select adaptable layers, reducing training costs while preserving rich prior knowledge even with limited datasets. This is done without requiring motion data.
What carries the argument
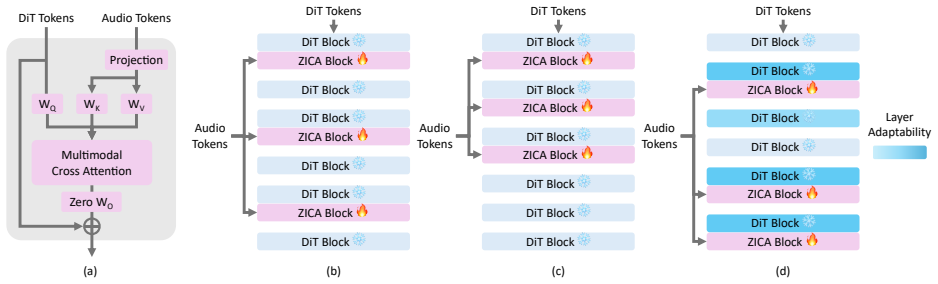
Layer-wise adaptability criterion based on a guidance-inspired constructive influence function that selects which layers to adapt.
If this is right
- Generates novel and diverse dance movements that respond dynamically to music.
- Generalizes well to unseen music tracks, longer video sequences, and unconventional subjects.
- Outperforms baseline models in consistency and synchronization.
- Trains on a single GPU within a day without motion data.
Where Pith is reading between the lines
- This selective layer adaptation could be applied to align video models with other inputs like speech or sound effects.
- Similar influence-based selection might help adapt diffusion models in other domains with limited data.
- The method suggests that pre-trained models have modular knowledge that can be targeted for specific tasks like music response.
Load-bearing premise
The guidance-inspired constructive influence function can accurately identify layers adaptable to music inputs while keeping the model's video generation abilities intact.
What would settle it
If adapted models produce dance videos that do not match the timing or style of the input music on new tracks, or if all layers must be retrained to achieve synchronization, the approach would not hold.
Figures
















read the original abstract
We introduce MusicInfuser, an approach that aligns pre-trained text-to-video diffusion models to generate high-quality dance videos synchronized with specified music tracks. Rather than training a multimodal audio-video or audio-motion model from scratch, our method demonstrates how existing video diffusion models can be efficiently adapted to align with musical inputs. We propose a novel layer-wise adaptability criterion based on a guidance-inspired constructive influence function to select adaptable layers, significantly reducing training costs while preserving rich prior knowledge, even with limited, specialized datasets. Experiments show that MusicInfuser effectively bridges the gap between music and video, generating novel and diverse dance movements that respond dynamically to music. Furthermore, our framework generalizes well to unseen music tracks, longer video sequences, and unconventional subjects, outperforming baseline models in consistency and synchronization. All of this is achieved without requiring motion data, with training completed on a single GPU within a day.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MusicInfuser, a technique for adapting pre-trained text-to-video diffusion models to generate dance videos synchronized with input music tracks. It proposes a novel layer-wise adaptability criterion based on a guidance-inspired constructive influence function to select which layers to adapt, with the goal of reducing training costs while preserving prior knowledge even on limited specialized datasets. The paper claims this enables generation of novel and diverse dance movements that respond dynamically to music, strong generalization to unseen music tracks, longer sequences, and unconventional subjects, and outperformance of baselines in consistency and synchronization—all without motion data and with single-GPU training completed in one day.
Significance. If the central claims are substantiated with quantitative evidence and the adaptability criterion is shown to be principled rather than heuristic, the work would be significant for efficient multimodal adaptation of large diffusion models. Demonstrating that targeted layer selection can achieve music-video alignment and generalization on limited data without full retraining or motion supervision would be relevant to resource-efficient generative modeling in computer vision.
major comments (2)
- [Abstract] Abstract: The central experimental claims—that the method outperforms baselines in consistency and synchronization, generalizes to unseen music tracks/longer sequences/unconventional subjects, and produces novel diverse movements—are stated without any metrics, baseline names, dataset descriptions, quantitative results, or error analysis. These assertions are load-bearing for the paper's contribution but cannot be evaluated from the given information.
- [Method (layer-wise adaptability criterion)] Method (layer-wise adaptability criterion): The novel layer-wise adaptability criterion relies on an unspecified 'guidance-inspired constructive influence function' whose ability to select adaptable layers while preserving priors on limited data is asserted without definition, mathematical formulation, derivation, computation details, or ablation against simpler selection strategies. This is load-bearing for the efficiency, low-cost training, and generalization claims.
minor comments (1)
- [Abstract] Abstract: The term 'guidance-inspired constructive influence function' is introduced without any reference or prior explanation of the underlying guidance mechanism.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address each major comment below and will revise the manuscript accordingly to improve clarity and substantiation of the claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central experimental claims—that the method outperforms baselines in consistency and synchronization, generalizes to unseen music tracks/longer sequences/unconventional subjects, and produces novel diverse movements—are stated without any metrics, baseline names, dataset descriptions, quantitative results, or error analysis. These assertions are load-bearing for the paper's contribution but cannot be evaluated from the given information.
Authors: We agree that the abstract presents claims at a high level without quantitative details. While full experimental results, metrics, baselines, datasets, and analysis appear in Sections 4 and 5, we will revise the abstract to incorporate key quantitative highlights (e.g., specific synchronization metrics and baseline names) to make the claims more evaluable from the abstract alone. revision: yes
-
Referee: [Method (layer-wise adaptability criterion)] Method (layer-wise adaptability criterion): The novel layer-wise adaptability criterion relies on an unspecified 'guidance-inspired constructive influence function' whose ability to select adaptable layers while preserving priors on limited data is asserted without definition, mathematical formulation, derivation, computation details, or ablation against simpler selection strategies. This is load-bearing for the efficiency, low-cost training, and generalization claims.
Authors: The guidance-inspired constructive influence function and layer-wise criterion are defined with mathematical formulation in Section 3.2. We will expand this section with additional derivation steps, explicit computation details, and an ablation study against simpler strategies (e.g., full-layer adaptation or random selection) to better demonstrate its role in efficiency and prior preservation. revision: yes
Circularity Check
No circularity; adaptation method is independent of reported outcomes
full rationale
The paper introduces MusicInfuser as an adaptation of pre-trained text-to-video diffusion models via a novel layer-wise adaptability criterion using a guidance-inspired constructive influence function. This criterion is presented as an input to the method rather than derived from the target synchronization or generalization results. No equations or steps in the provided abstract or description reduce predictions to fitted parameters by construction, nor do self-citations form a load-bearing chain for the central claims. The framework is framed as a general adaptation technique whose effectiveness is evaluated experimentally on unseen data, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Self-rectifying diffu- sion sampling with perturbed-attention guidance
Donghoon Ahn, Hyoungwon Cho, Jaewon Min, Wooseok Jang, Jungwoo Kim, SeonHwa Kim, Hyun Hee Park, Ky- ong Hwan Jin, and Seungryong Kim. Self-rectifying diffu- sion sampling with perturbed-attention guidance. InEuro- pean Conference on Computer Vision, pages 1–17. Springer,
-
[2]
Omid Alemi, Jules Franc ¸oise, and Philippe Pasquier. Groovenet: Real-time music-driven dance movement gen- eration using artificial neural networks.networks, 8(17):26,
-
[3]
Simon Alexanderson, Rajmund Nagy, Jonas Beskow, and Gustav Eje Henter. Listen, denoise, action! audio-driven motion synthesis with diffusion models.ACM Transactions on Graphics (TOG), 42(4):1–20, 2023. 2, 3
work page 2023
-
[4]
Andreas Aristidou, Anastasios Yiannakidis, Kfir Aberman, Daniel Cohen-Or, Ariel Shamir, and Yiorgos Chrysanthou. Rhythm is a dancer: Music-driven motion synthesis with global structure.IEEE transactions on visualization and computer graphics, 29(8):3519–3534, 2022. 3
work page 2022
-
[5]
Ho Yin Au, Jie Chen, Junkun Jiang, and Yike Guo. Chore- ograph: Music-conditioned automatic dance choreography over a style and tempo consistent dynamic graph. InPro- ceedings of the 30th ACM International Conference on Mul- timedia, pages 3917–3925, 2022. 3
work page 2022
-
[6]
Alexei Baevski, Yuhao Zhou, Abdelrahman Mohamed, and Michael Auli. wav2vec 2.0: A framework for self-supervised learning of speech representations.Advances in neural infor- mation processing systems, 33:12449–12460, 2020. 7
work page 2020
-
[7]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram V oleti, Adam Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
Align your latents: High-resolution video synthesis with la- tent diffusion models
Andreas Blattmann, Robin Rombach, Huan Ling, Tim Dock- horn, Seung Wook Kim, Sanja Fidler, and Karsten Kreis. Align your latents: High-resolution video synthesis with la- tent diffusion models. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 22563–22575, 2023. 3
work page 2023
-
[9]
Caroline Chan, Shiry Ginosar, Tinghui Zhou, and Alexei A Efros. Everybody dance now. InProceedings of the IEEE/CVF international conference on computer vision, pages 5933–5942, 2019. 3
work page 2019
-
[10]
Sound2sight: Gen- erating visual dynamics from sound and context
Moitreya Chatterjee and Anoop Cherian. Sound2sight: Gen- erating visual dynamics from sound and context. InCom- puter Vision–ECCV 2020: 16th European Conference, Glas- gow, UK, August 23–28, 2020, Proceedings, Part XXVII 16, pages 701–719. Springer, 2020. 3
work page 2020
-
[11]
arXiv preprint arXiv:2502.02492 , year=
Hila Chefer, Uriel Singer, Amit Zohar, Yuval Kirstain, Adam Polyak, Yaniv Taigman, Lior Wolf, and Shelly Sheynin. Videojam: Joint appearance-motion representations for en- hanced motion generation in video models.arXiv preprint arXiv:2502.02492, 2025. 16
-
[12]
Kang Chen, Zhipeng Tan, Jin Lei, Song-Hai Zhang, Yuan- Chen Guo, Weidong Zhang, and Shi-Min Hu. Choreomaster: choreography-oriented music-driven dance synthesis.ACM Transactions on Graphics (TOG), 40(4):1–13, 2021. 2
work page 2021
-
[13]
Training-free layout control with cross-attention guidance
Minghao Chen, Iro Laina, and Andrea Vedaldi. Training-free layout control with cross-attention guidance. InProceedings of the IEEE/CVF winter conference on applications of com- puter vision, pages 5343–5353, 2024. 4
work page 2024
-
[14]
VideoLLaMA 2: Advancing Spatial-Temporal Modeling and Audio Understanding in Video-LLMs
Zesen Cheng, Sicong Leng, Hang Zhang, Yifei Xin, Xin Li, Guanzheng Chen, Yongxin Zhu, Wenqi Zhang, Ziyang Luo, Deli Zhao, et al. Videollama 2: Advancing spatial- temporal modeling and audio understanding in video-llms. arXiv preprint arXiv:2406.07476, 2024. 2, 6, 7, 12, 15, 16
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Satoru Fukayama and Masataka Goto. Automated chore- ography synthesis using a gaussian process leveraging consumer-generated dance motions. InProceedings of the 11th Conference on Advances in Computer Entertainment Technology, pages 1–6, 2014. 2
work page 2014
-
[16]
Long video generation with time-agnostic vqgan and time- sensitive transformer
Songwei Ge, Thomas Hayes, Harry Yang, Xi Yin, Guan Pang, David Jacobs, Jia-Bin Huang, and Devi Parikh. Long video generation with time-agnostic vqgan and time- sensitive transformer. InEuropean Conference on Computer Vision, pages 102–118. Springer, 2022. 3
work page 2022
-
[17]
Tm2d: Bimodality driven 3d dance generation via music-text integration
Kehong Gong, Dongze Lian, Heng Chang, Chuan Guo, Zi- hang Jiang, Xinxin Zuo, Michael Bi Mi, and Xinchao Wang. Tm2d: Bimodality driven 3d dance generation via music-text integration. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 9942–9952, 2023. 3
work page 2023
-
[18]
Prompt-to-Prompt Image Editing with Cross Attention Control
Amir Hertz, Ron Mokady, Jay Tenenbaum, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Prompt-to-prompt im- age editing with cross attention control.arXiv preprint arXiv:2208.01626, 2022. 4
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[19]
Classifier-Free Diffusion Guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598, 2022. 3
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[20]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising dif- fusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020. 3
work page 2020
-
[21]
Video dif- fusion models.Advances in Neural Information Processing Systems, 35:8633–8646, 2022
Jonathan Ho, Tim Salimans, Alexey Gritsenko, William Chan, Mohammad Norouzi, and David J Fleet. Video dif- fusion models.Advances in Neural Information Processing Systems, 35:8633–8646, 2022. 3
work page 2022
-
[22]
Smoothed energy guidance: Guiding dif- fusion models with reduced energy curvature of attention
Susung Hong. Smoothed energy guidance: Guiding dif- fusion models with reduced energy curvature of attention. Advances in Neural Information Processing Systems, 37: 66743–66772, 2025. 4
work page 2025
-
[23]
Improving sample quality of diffusion models us- ing self-attention guidance
Susung Hong, Gyuseong Lee, Wooseok Jang, and Seungry- ong Kim. Improving sample quality of diffusion models us- ing self-attention guidance. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 7462– 7471, 2023. 4
work page 2023
-
[24]
Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022. 6
work page 2022
-
[25]
Vbench: Comprehensive bench- mark suite for video generative models
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, 9 Nattapol Chanpaisit, et al. Vbench: Comprehensive bench- mark suite for video generative models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21807–21818, 2024. 4, 15
work page 2024
-
[26]
Spatiotemporal skip guidance for enhanced video diffusion sampling.arXiv preprint arXiv:2411.18664,
Junha Hyung, Kinam Kim, Susung Hong, Min-Jung Kim, and Jaegul Choo. Spatiotemporal skip guidance for enhanced video diffusion sampling.arXiv preprint arXiv:2411.18664,
-
[27]
Tero Karras, Miika Aittala, Timo Aila, and Samuli Laine. Elucidating the design space of diffusion-based generative models.Advances in neural information processing systems, 35:26565–26577, 2022. 3
work page 2022
-
[28]
Tae-hoon Kim, Sang Il Park, and Sung Yong Shin. Rhythmic-motion synthesis based on motion-beat analy- sis.ACM Transactions on Graphics (TOG), 22(3):392–401,
-
[29]
Nhat Le, Tuong Do, Khoa Do, Hien Nguyen, Erman Tjipu- tra, Quang D Tran, and Anh Nguyen. Controllable group choreography using contrastive diffusion.ACM Transactions on Graphics (TOG), 42(6):1–14, 2023. 3
work page 2023
-
[30]
Dancing to music.Advances in neural information process- ing systems, 32, 2019
Hsin-Ying Lee, Xiaodong Yang, Ming-Yu Liu, Ting-Chun Wang, Yu-Ding Lu, Ming-Hsuan Yang, and Jan Kautz. Dancing to music.Advances in neural information process- ing systems, 32, 2019. 2
work page 2019
-
[31]
VideoChat: Chat-Centric Video Understanding
KunChang Li, Yinan He, Yi Wang, Yizhuo Li, Wenhai Wang, Ping Luo, Yali Wang, Limin Wang, and Yu Qiao. Videochat: Chat-centric video understanding.arXiv preprint arXiv:2305.06355, 2023. 6, 7, 15
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[32]
Ai choreographer: Music conditioned 3d dance generation with aist++
Ruilong Li, Shan Yang, David A Ross, and Angjoo Kanazawa. Ai choreographer: Music conditioned 3d dance generation with aist++. InProceedings of the IEEE/CVF international conference on computer vision, pages 13401– 13412, 2021. 2, 6, 7, 13, 15
work page 2021
-
[33]
Gaojie Lin, Jianwen Jiang, Jiaqi Yang, Zerong Zheng, and Chao Liang. Omnihuman-1: Rethinking the scaling-up of one-stage conditioned human animation models.arXiv preprint arXiv:2502.01061, 2025. 16
-
[34]
Dancegen: Supporting choreog- raphy ideation and prototyping with generative ai
Yimeng Liu and Misha Sra. Dancegen: Supporting choreog- raphy ideation and prototyping with generative ai. InPro- ceedings of the 2024 ACM Designing Interactive Systems Conference, pages 920–938, 2024. 3
work page 2024
-
[35]
Ferda Ofli, Engin Erzin, Y ¨ucel Yemez, and A Murat Tekalp. Learn2dance: Learning statistical music-to-dance mappings for choreography synthesis.IEEE Transactions on Multime- dia, 14(3):747–759, 2011. 2
work page 2011
-
[36]
Diffdance: Cascaded human mo- tion diffusion model for dance generation
Qiaosong Qi, Le Zhuo, Aixi Zhang, Yue Liao, Fei Fang, Si Liu, and Shuicheng Yan. Diffdance: Cascaded human mo- tion diffusion model for dance generation. InProceedings of the 31st ACM International Conference on Multimedia, pages 1374–1382, 2023. 3
work page 2023
-
[37]
Vimo: Generating motions from casual videos.arXiv preprint arXiv:2408.06614, 2024
Liangdong Qiu, Chengxing Yu, Yanran Li, Zhao Wang, Haibin Huang, Chongyang Ma, Di Zhang, Pengfei Wan, and Xiaoguang Han. Vimo: Generating motions from casual videos.arXiv preprint arXiv:2408.06614, 2024. 3
-
[38]
Mm-diffusion: Learning multi-modal diffusion mod- els for joint audio and video generation
Ludan Ruan, Yiyang Ma, Huan Yang, Huiguo He, Bei Liu, Jianlong Fu, Nicholas Jing Yuan, Qin Jin, and Baining Guo. Mm-diffusion: Learning multi-modal diffusion mod- els for joint audio and video generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10219–10228, 2023. 2, 3, 7, 8, 11, 14
work page 2023
-
[39]
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L Denton, Kamyar Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Salimans, et al. Photorealistic text-to-image diffusion models with deep language understanding.Advances in neural information processing systems, 35:36479–36494, 2022. 4
work page 2022
-
[40]
Bailando: 3d dance generation by actor-critic gpt with choreographic memory
Li Siyao, Weijiang Yu, Tianpei Gu, Chunze Lin, Quan Wang, Chen Qian, Chen Change Loy, and Ziwei Liu. Bailando: 3d dance generation by actor-critic gpt with choreographic memory. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11050– 11059, 2022. 3
work page 2022
-
[41]
Denois- ing diffusion implicit models.ICLR, 2021
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denois- ing diffusion implicit models.ICLR, 2021. 3
work page 2021
-
[42]
Score-based generative modeling through stochastic differential equa- tions.ICLR, 2021
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Ab- hishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equa- tions.ICLR, 2021. 3
work page 2021
-
[43]
Mochi 1.https :/ /github .com/ genmoai/models, 2024
Genmo Team. Mochi 1.https :/ /github .com/ genmoai/models, 2024. 2, 7, 8, 11, 15
work page 2024
-
[44]
Edge: Editable dance generation from music
Jonathan Tseng, Rodrigo Castellon, and Karen Liu. Edge: Editable dance generation from music. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 448–458, 2023. 2, 3, 15
work page 2023
-
[45]
Shuhei Tsuchida, Satoru Fukayama, Masahiro Hamasaki, and Masataka Goto. Aist dance video database: Multi-genre, multi-dancer, and multi-camera database for dance informa- tion processing. InISMIR, page 6, 2019. 5, 6, 7, 15
work page 2019
-
[46]
Jin Xu, Zhifang Guo, Hangrui Hu, Yunfei Chu, Xiong Wang, Jinzheng He, Yuxuan Wang, Xian Shi, Ting He, Xinfa Zhu, et al. Qwen3-omni technical report.arXiv preprint arXiv:2509.17765, 2025. 2, 6, 7, 15, 16
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[47]
Choreonet: Towards music to dance synthesis with choreographic action unit
Zijie Ye, Haozhe Wu, Jia Jia, Yaohua Bu, Wei Chen, Fanbo Meng, and Yanfeng Wang. Choreonet: Towards music to dance synthesis with choreographic action unit. InProceed- ings of the 28th ACM International Conference on Multime- dia, pages 744–752, 2020. 2
work page 2020
-
[48]
Video probabilistic diffusion models in projected latent space
Sihyun Yu, Kihyuk Sohn, Subin Kim, and Jinwoo Shin. Video probabilistic diffusion models in projected latent space. InProceedings of the IEEE/CVF conference on com- puter vision and pattern recognition, pages 18456–18466,
-
[49]
Adding conditional control to text-to-image diffusion models
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. In Proceedings of the IEEE/CVF international conference on computer vision, pages 3836–3847, 2023. 6, 8
work page 2023
-
[50]
Music-to-dance generation with mul- tiple conformer
Mingao Zhang, Changhong Liu, Yong Chen, Zhenchun Lei, and Mingwen Wang. Music-to-dance generation with mul- tiple conformer. InProceedings of the 2022 International Conference on Multimedia Retrieval, pages 34–38, 2022. 2
work page 2022
-
[51]
Wenlin Zhuang, Congyi Wang, Jinxiang Chai, Yangang Wang, Ming Shao, and Siyu Xia. Music2dance: Dancenet for music-driven dance generation.ACM Transactions on Multimedia Computing, Communications, and Applications (TOMM), 18(2):1–21, 2022. 2 10 MusicInfuser: Making Video Diffusion Listen and Dance Supplementary Material MusicTrack 1 MusicTrack 2 MusicTrack...
work page 2022
-
[52]
Which video has higher visual quality?
-
[53]
Which video’s dance aligns better with the music?
-
[54]
Which video’s motion is more realistic?
-
[55]
a male dancer wearing a suit dancing in the middle of a New York City, captured from a front view
Which video’s dance is more complex? 13 Feature Addi+on Full No ZICA Layer Selec+on No Beta-Uniform No LoRA No Higher Rank Figure 14. Ablation study. The prompt is set to “a male dancer wearing a suit dancing in the middle of a New York City, captured from a front view”. The seed and music are set the same across all methods. D. Limitations Although our m...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.