DEGround: An Effective Baseline for Ego-centric 3D Visual Grounding with a Homogeneous Framework
Pith reviewed 2026-05-19 11:00 UTC · model grok-4.3
The pith
A single set of queries shared between 3D detection and grounding raises accuracy on ego-centric visual grounding tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DEGround centers on object-level sharing by using a set of queries as the common representation for both detection and grounding, decoded by a shared transformer and bounding box head, and augments this base with a Regional Activation Grounding module that highlights instruction-relevant regions plus a Query-wise Modulation module that applies sentence-conditioned affine modulation to create instruction-aware queries at initialization.
What carries the argument
A set of shared queries that act as the common object representation for detection and grounding, decoded by one transformer and one box head.
If this is right
- Object-level priors learned during detection transfer directly into the grounding stage without re-optimization.
- Redundant training steps that arise from separate detector and grounding models are removed.
- Fine-grained spatial-textual alignment improves through the Regional Activation Grounding module.
- Instruction-aware query initialization becomes possible via the Query-wise Modulation module.
- Overall precision on benchmarks such as EmbodiedScan rises, with reported gains of 7.52 percent.
Where Pith is reading between the lines
- The same shared-query pattern could be tested on related tasks such as 3D referring expression comprehension or embodied question answering.
- Unified architectures of this type may lower the memory footprint needed for real-time robotic deployment.
- The design suggests that other multimodal 3D tasks would benefit from keeping object representations identical across subtasks instead of learning them separately.
Load-bearing premise
The performance gains come from the homogeneous shared-query design and the two plug-in modules rather than from differences in training schedules, data augmentation, or total model capacity.
What would settle it
A side-by-side test that applies the same training schedule, data augmentation, and comparable parameter count to a prior heterogeneous detector-plus-grounder pipeline and checks whether the accuracy gap on EmbodiedScan closes.
Figures





read the original abstract
A core task in embodied intelligence is ego-centric 3D visual grounding. Existing methods typically adopt two-stage, heterogeneous pipelines that pair a detector with a separate grounding model. Incompatible decoders and box heads hinder the transfer of object-level priors, and the split training causes redundant re-optimization. To overcome these limitations, we present DEGround, a straight, elegant, and effective framework that centers on object-level sharing over detection and grounding. It employs a set of queries that serves as the common object representation for both detection and grounding, which is decoded by a shared transformer and bounding box head. Building on this homogeneous framework, we further introduce two task-specific plug-in modules to enhance fine-grained instruction grounding. The Regional Activation Grounding module improves spatial-textual alignment by highlighting instruction-relevant regions, while the Query-wise Modulation module applies sentence-conditioned affine modulation to generate instruction-aware queries at initialization. Extensive experiments demonstrate that DEGround achieves the best performance on multiple benchmarks. Remarkably, it significantly outperforms previous methods by 7.52% at overall precision on the EmbodiedScan dataset.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DEGround, a homogeneous framework for ego-centric 3D visual grounding that replaces typical two-stage heterogeneous pipelines (detector + separate grounding model) with a shared set of queries serving as common object representations for both detection and grounding. These queries are decoded by a single transformer and bounding-box head. Two task-specific plug-in modules are added: Regional Activation Grounding (to highlight instruction-relevant regions for better spatial-textual alignment) and Query-wise Modulation (sentence-conditioned affine modulation for instruction-aware query initialization). Experiments on multiple benchmarks, including a claimed 7.52% overall-precision gain on EmbodiedScan, are presented to show state-of-the-art results.
Significance. If the performance margins can be isolated to the homogeneous shared-query design and the two plug-ins rather than uncontrolled differences in training or capacity, the work would supply a simple, transferable baseline that reduces redundant optimization and improves object-level prior transfer. The empirical focus on embodied 3D grounding benchmarks makes the result potentially useful for downstream embodied-AI pipelines, though its impact hinges on the robustness of the experimental controls.
major comments (1)
- [§4, Table 1] §4 (Experiments) and Table 1 (main results): the 7.52% overall-precision improvement on EmbodiedScan is reported against prior heterogeneous methods, yet the text does not describe whether those baselines were re-trained under identical schedules, data-augmentation pipelines, or parameter budgets as DEGround. Without such matched controls, the central claim that gains arise from architectural homogeneity and the two plug-in modules cannot be isolated from confounding factors.
minor comments (1)
- [§3.2] The abstract and §3.2 refer to 'Regional Activation Grounding' and 'Query-wise Modulation' without an early diagram or equation block that shows how their outputs are injected into the shared decoder; a single figure or pseudocode block would clarify the integration.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comment point by point below and indicate the planned revisions.
read point-by-point responses
-
Referee: [§4, Table 1] §4 (Experiments) and Table 1 (main results): the 7.52% overall-precision improvement on EmbodiedScan is reported against prior heterogeneous methods, yet the text does not describe whether those baselines were re-trained under identical schedules, data-augmentation pipelines, or parameter budgets as DEGround. Without such matched controls, the central claim that gains arise from architectural homogeneity and the two plug-in modules cannot be isolated from confounding factors.
Authors: We agree that the manuscript does not explicitly state the comparison protocol for the baselines. The reported numbers for prior heterogeneous methods are taken from the original publications, following standard practice in the 3D visual grounding literature. Re-training every baseline under identical schedules, augmentations, and capacity constraints would require substantial additional compute and is outside the scope of the current work. In the revised manuscript we will expand Section 4 to describe DEGround’s exact training schedule, data-augmentation pipeline, and parameter count, and we will add an explicit statement that baseline results are reproduced from the cited papers. This clarification will make the experimental controls transparent while preserving the central architectural claims. revision: yes
Circularity Check
No circularity: empirical benchmark claims rest on external validation rather than self-referential derivations.
full rationale
The paper introduces an architectural framework (homogeneous shared queries plus two plug-in modules) and supports its effectiveness solely through reported performance numbers on public benchmarks such as EmbodiedScan. No equations, fitted parameters renamed as predictions, uniqueness theorems, or self-citation chains appear in the provided text that would make any claimed result equivalent to its own inputs by construction. The 7.52% gain is presented as an experimental outcome, not a logical consequence of prior definitions or internal re-optimization.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Training data for embodied 3D scenes is representative of real-world deployment distributions.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
DEGround... shares DETR queries as object representation for both detection and grounding... Regional Activation Grounding module... Query-wise Modulation module applies sentence-conditioned affine modulation
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Achlioptas, P., Abdelreheem, A., Xia, F., Elhoseiny, M., Guibas, L.: Referit3d: Neural listeners for fine-grained 3d object identification in real-world scenes. In: ECCV (2020) 1, 3
work page 2020
-
[2]
Azuma, D., Miyanishi, T., Kurita, S., Kawanabe, M.: Scanqa: 3d question answering for spatial scene understanding. In: CVPR (2022) 1, 3
work page 2022
-
[3]
Baruch, G., Chen, Z., Dehghan, A., Dimry, T., Feigin, Y ., Fu, P., Gebauer, T., Joffe, B., Kurz, D., Schwartz, A., et al.: Arkitscenes: A diverse real-world dataset for 3d indoor scene understanding using mobile rgb-d data. arXiv (2021) 13
work page 2021
-
[4]
Caesar, H., Bankiti, V ., Lang, A.H., V ora, S., Liong, V .E., Xu, Q., Krishnan, A., Pan, Y ., Baldan, G., Beijbom, O.: nuscenes: A multimodal dataset for autonomous driving. In: CVPR (2020) 3
work page 2020
-
[5]
Carion, N., Massa, F., Synnaeve, G., Usunier, N., Kirillov, A., Zagoruyko, S.: End-to-end object detection with transformers. In: ECCV (2020) 2, 5
work page 2020
-
[6]
Matterport3D: Learning from RGB-D Data in Indoor Environments
Chang, A., Dai, A., Funkhouser, T., Halber, M., Niessner, M., Savva, M., Song, S., Zeng, A., Zhang, Y .: Matterport3d: Learning from rgb-d data in indoor environments. arXiv preprint arXiv:1709.06158 (2017) 6, 7
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[7]
Chang, C.P., Wang, S., Pagani, A., Stricker, D.: Mikasa: Multi-key-anchor & scene-aware transformer for 3d visual grounding. In: CVPR (2024) 3
work page 2024
-
[8]
Chen, C., Jain, U., Schissler, C., Gari, S.V .A., Al-Halah, Z., Ithapu, V .K., Robinson, P., Grauman, K.: Soundspaces: Audio-visual navigation in 3d environments. In: ECCV (2020) 3
work page 2020
-
[9]
Chen, D.Z., Chang, A.X., Nießner, M.: Scanrefer: 3d object localization in rgb-d scans using natural language. In: ECCV (2020) 1, 3
work page 2020
-
[10]
Chen, S., Guhur, P.L., Tapaswi, M., Schmid, C., Laptev, I.: Language conditioned spatial relation reasoning for 3d object grounding. NeurIPS (2022) 3
work page 2022
-
[11]
arXiv preprint arXiv:2405.10370 (2024) 3
Chen, Y ., Yang, S., Huang, H., Wang, T., Xu, R., Lyu, R., Lin, D., Pang, J.: Grounded 3d-llm with referent tokens. arXiv preprint arXiv:2405.10370 (2024) 3
-
[12]
Choy, C., Gwak, J., Savarese, S.: 4d spatio-temporal convnets: Minkowski convolutional neural networks. In: CVPR (2019) 7
work page 2019
-
[13]
Indoor Semantic Segmentation using depth information
Couprie, C., Farabet, C., Najman, L., LeCun, Y .: Indoor semantic segmentation using depth information. arXiv preprint arXiv:1301.3572 (2013) 7
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[14]
Dai, A., Chang, A.X., Savva, M., Halber, M., Funkhouser, T., Nießner, M.: Scannet: Richly- annotated 3d reconstructions of indoor scenes. In: CVPR (2017) 6
work page 2017
-
[15]
Deitke, M., VanderBilt, E., Herrasti, A., Weihs, L., Ehsani, K., Salvador, J., Han, W., Kolve, E., Kembhavi, A., Mottaghi, R.: Procthor: Large-scale embodied ai using procedural generation. NeurIPS (2022) 3
work page 2022
- [16]
-
[17]
Ding, Z., Han, X., Niethammer, M.: V otenet: A deep learning label fusion method for multi-atlas segmentation. In: MICCAI (2019) 6
work page 2019
-
[18]
Feng, M., Li, Z., Li, Q., Zhang, L., Zhang, X., Zhu, G., Zhang, H., Wang, Y ., Mian, A.: Free-form description guided 3d visual graph network for object grounding in point cloud. In: ICCV (2021) 3 10
work page 2021
-
[19]
Guo, Z., Tang, Y ., Zhang, R., Wang, D., Wang, Z., Zhao, B., Li, X.: Viewrefer: Grasp the multi-view knowledge for 3d visual grounding. In: ICCV (2023) 3
work page 2023
-
[20]
He, D., Zhao, Y ., Luo, J., Hui, T., Huang, S., Zhang, A., Liu, S.: Transrefer3d: Entity-and- relation aware transformer for fine-grained 3d visual grounding. In: ACM MM (2021) 3
work page 2021
-
[21]
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: CVPR (2016) 7
work page 2016
-
[22]
Hong, Y ., Zhen, H., Chen, P., Zheng, S., Du, Y ., Chen, Z., Gan, C.: 3d-llm: Injecting the 3d world into large language models. NeurIPS (2023) 3
work page 2023
-
[23]
Hsu, J., Mao, J., Wu, J.: Ns3d: Neuro-symbolic grounding of 3d objects and relations. In: CVPR (2023) 3
work page 2023
-
[24]
Huang, H., Chen, Y ., Wang, Z., Huang, R., Xu, R., Wang, T., Liu, L., Cheng, X., Zhao, Y ., Pang, J., et al.: Chat-scene: Bridging 3d scene and large language models with object identifiers. In: NeurIPS (2024) 3
work page 2024
-
[25]
An Embodied Generalist Agent in 3D World
Huang, J., Yong, S., Ma, X., Linghu, X., Li, P., Wang, Y ., Li, Q., Zhu, S.C., Jia, B., Huang, S.: An embodied generalist agent in 3d world. arXiv preprint arXiv:2311.12871 (2023) 3, 13
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
Huang, P.H., Lee, H.H., Chen, H.T., Liu, T.L.: Text-guided graph neural networks for referring 3d instance segmentation. In: AAAI (2021) 3
work page 2021
-
[27]
Huang, S., Chen, Y ., Jia, J., Wang, L.: Multi-view transformer for 3d visual grounding. In: CVPR (2022) 3
work page 2022
-
[28]
Jain, A., Gkanatsios, N., Mediratta, I., Fragkiadaki, K.: Bottom up top down detection trans- formers for language grounding in images and point clouds. In: ECCV (2022) 3
work page 2022
-
[29]
In: Autonomous Grand Challenge CVPR 2024 Workshop
Liang, C., Li, B., Zhou, Z., Wang, L., He, P., Hu, L., Wang, H.: Spatioawaregrouding3d: A spatio aware model for improving 3d vision grouding. In: Autonomous Grand Challenge CVPR 2024 Workshop. vol. 6 (2024) 2, 5, 13
work page 2024
-
[30]
In: Proceedings of the IEEE international conference on computer vision
Lin, T.Y ., Goyal, P., Girshick, R., He, K., Dollár, P.: Focal loss for dense object detection. In: Proceedings of the IEEE international conference on computer vision. pp. 2980–2988 (2017) 6
work page 2017
-
[31]
arXiv preprint arXiv:2411.14869 (2024) 3, 6, 7, 8, 13
Lin, X., Lin, T., Huang, L., Xie, H., Su, Z.: Bip3d: Bridging 2d images and 3d perception for embodied intelligence. arXiv preprint arXiv:2411.14869 (2024) 3, 6, 7, 8, 13
-
[32]
Liu, S., Zeng, Z., Ren, T., Li, F., Zhang, H., Yang, J., Jiang, Q., Li, C., Yang, J., Su, H., et al.: Grounding dino: Marrying dino with grounded pre-training for open-set object detection. In: ECCV (2024) 3
work page 2024
-
[33]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Liu, Y ., Ott, M., Goyal, N., Du, J., Joshi, M., Chen, D., Levy, O., Lewis, M., Zettlemoyer, L., Stoyanov, V .: Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692 (2019) 7
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[34]
Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. ICLR (2017) 7
work page 2017
-
[35]
Luo, J., Fu, J., Kong, X., Gao, C., Ren, H., Shen, H., Xia, H., Liu, S.: 3d-sps: Single-stage 3d visual grounding via referred point progressive selection. In: CVPR (2022) 3
work page 2022
-
[36]
Rukhovich, D., V orontsova, A., Konushin, A.: Fcaf3d: Fully convolutional anchor-free 3d object detection. In: ECCV (2022) 2, 6
work page 2022
-
[37]
Rukhovich, D., V orontsova, A., Konushin, A.: Imvoxelnet: Image to voxels projection for monocular and multi-view general-purpose 3d object detection. In: W ACV (2022) 6
work page 2022
-
[38]
Shi, X., Wu, Z., Lee, S.: Aware visual grounding in 3d scenes. In: CVPR (2024) 3
work page 2024
-
[39]
Song, S., Lichtenberg, S.P., Xiao, J.: Sun rgb-d: A rgb-d scene understanding benchmark suite. In: CVPR (2015) 7 11
work page 2015
-
[40]
Tian, X., Jiang, T., Yun, L., Mao, Y ., Yang, H., Wang, Y ., Wang, Y ., Zhao, H.: Occ3d: A large-scale 3d occupancy prediction benchmark for autonomous driving. NeurIPS (2023) 3
work page 2023
-
[41]
Unal, O., Sakaridis, C., Saha, S., Van Gool, L.: Four ways to improve verbo-visual fusion for dense 3d visual grounding. In: ECCV (2024) 3
work page 2024
-
[42]
Wald, J., Avetisyan, A., Navab, N., Tombari, F., Nießner, M.: Rio: 3d object instance re- localization in changing indoor environments. In: ICCV (2019) 6
work page 2019
-
[43]
In: CVPR (2024) 1, 2, 4, 5, 6, 7, 8, 9, 13
Wang, T., Mao, X., Zhu, C., Xu, R., Lyu, R., Li, P., Chen, X., Zhang, W., Chen, K., Xue, T., et al.: Embodiedscan: A holistic multi-modal 3d perception suite towards embodied ai. In: CVPR (2024) 1, 2, 4, 5, 6, 7, 8, 9, 13
work page 2024
-
[44]
Wang, Y ., Li, Y ., Wang, S.: Gˆ 3-lq: Marrying hyperbolic alignment with explicit semantic- geometric modeling for 3d visual grounding. In: CVPR (2024) 3
work page 2024
-
[45]
NeurIPS 37, 110972–110999 (2024) 3
Wu, C., Ji, J., Wang, H., Ma, Y ., Huang, Y ., Luo, G., Fei, H., Sun, X., Ji, R., et al.: Rg-san: Rule-guided spatial awareness network for end-to-end 3d referring expression segmentation. NeurIPS 37, 110972–110999 (2024) 3
work page 2024
-
[46]
Xu, C., Han, Y ., Xu, R., Hui, L., Xie, J., Yang, J.: Multi-attribute interactions matter for 3d visual grounding. In: CVPR (2024) 3
work page 2024
-
[47]
Yang, Z., Zhang, S., Wang, L., Luo, J.: Sat: 2d semantics assisted training for 3d visual grounding. In: ICCV (2021) 3
work page 2021
-
[48]
Yuan, Z., Yan, X., Liao, Y ., Zhang, R., Wang, S., Li, Z., Cui, S.: Instancerefer: Coopera- tive holistic understanding for visual grounding on point clouds through instance multi-level contextual referring. In: ICCV (2021) 3
work page 2021
-
[49]
Zhang, Y ., Gong, Z., Chang, A.X.: Multi3drefer: Grounding text description to multiple 3d objects. In: ICCV (2023) 1, 3
work page 2023
-
[50]
Zhang, Y ., Luo, H., Lei, Y .: Towards clip-driven language-free 3d visual grounding via 2d-3d relational enhancement and consistency. In: CVPR (2024) 3
work page 2024
-
[51]
Zhao, L., Cai, D., Sheng, L., Xu, D.: 3dvg-transformer: Relation modeling for visual grounding on point clouds. In: ICCV (2021) 3
work page 2021
-
[52]
Zheng, D., Huang, S., Zhao, L., Zhong, Y ., Wang, L.: Towards learning a generalist model for embodied navigation. In: CVPR (2024) 3
work page 2024
-
[53]
In: Autonomous Grand Challenge CVPR 2024 Workshop
Zheng, H., Shi, H., Chng, Y .X., Huang, R., Ni, Z., Tan, T., Peng, Q., Weng, Y ., Shi, Z., Huang, G.: Denseg: Alleviating vision-language feature sparsity in multi-view 3d visual grounding. In: Autonomous Grand Challenge CVPR 2024 Workshop. vol. 2, p. 6 (2024) 5
work page 2024
-
[54]
In: ICLR (2025) 2, 4, 5, 7, 8, 13
Zheng, H., Shi, H., Peng, Q., Chng, Y .X., Huang, R., Weng, Y ., Huang, G., et al.: Denseground- ing: Improving dense language-vision semantics for ego-centric 3d visual grounding. In: ICLR (2025) 2, 4, 5, 7, 8, 13
work page 2025
-
[55]
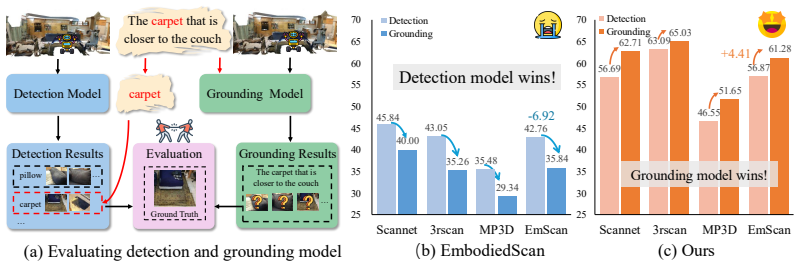
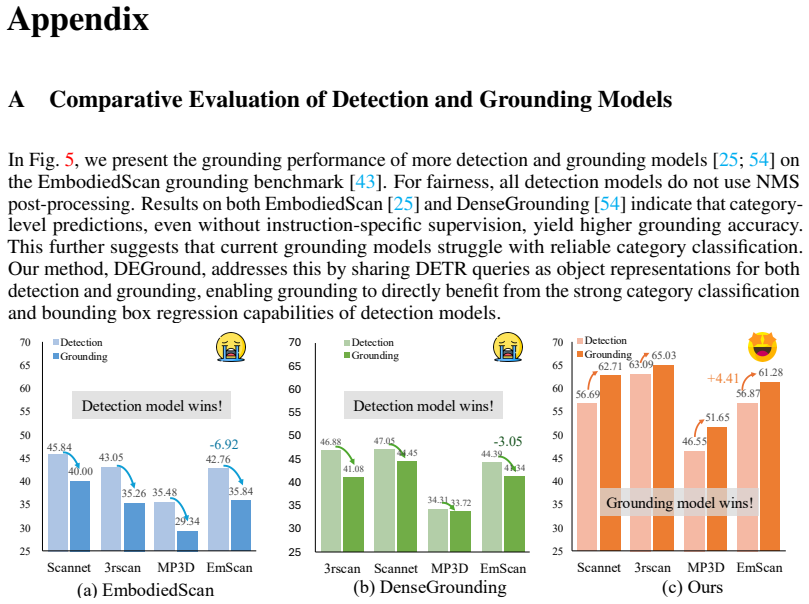
In: ECCV (2024) 3 12 Appendix A Comparative Evaluation of Detection and Grounding Models In Fig
Zhu, Z., Zhang, Z., Ma, X., Niu, X., Chen, Y ., Jia, B., Deng, Z., Huang, S., Li, Q.: Unifying 3d vision-language understanding via promptable queries. In: ECCV (2024) 3 12 Appendix A Comparative Evaluation of Detection and Grounding Models In Fig. 5, we present the grounding performance of more detection and grounding models [25; 54] on the EmbodiedScan ...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.