Not All Tokens Matter: Towards Efficient LLM Reasoning via Token Significance in Reinforcement Learning
Pith reviewed 2026-05-19 10:02 UTC · model grok-4.3
The pith
Penalizing only low-significance tokens in RL training lets LLMs shorten reasoning chains while preserving or raising accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Observing that many chain-of-thought tokens contribute little to the final answer, the work introduces a significance-aware length reward that selectively penalizes insignificant tokens and a dynamic length reward that encourages detail early then shifts toward conciseness. When these are added to standard policy optimization, both reasoning efficiency and accuracy improve.
What carries the argument
Significance-aware length reward that estimates each token's contribution to the final answer and applies penalties only to low-contribution tokens.
If this is right
- Response lengths drop substantially on standard reasoning benchmarks.
- Correctness is preserved or improved compared with uniform length rewards.
- Essential reasoning steps remain intact while redundant tokens are reduced.
- The dynamic reward produces a gradual shift from detailed to concise outputs over training.
Where Pith is reading between the lines
- The same token-level view could apply to other RLHF objectives beyond length, such as factual consistency.
- Pre-computing rough significance scores from a smaller model might approximate the method at lower cost.
- The findings suggest that sequence-level rewards in generative RL are often too coarse and that finer token analysis may be broadly useful.
Load-bearing premise
Token significance can be estimated reliably enough during training to guide penalties without removing steps needed for a correct answer.
What would settle it
Replace the significance estimate with random token selection in the reward and measure whether response accuracy falls more than under the proposed method on the same benchmarks.
Figures










read the original abstract
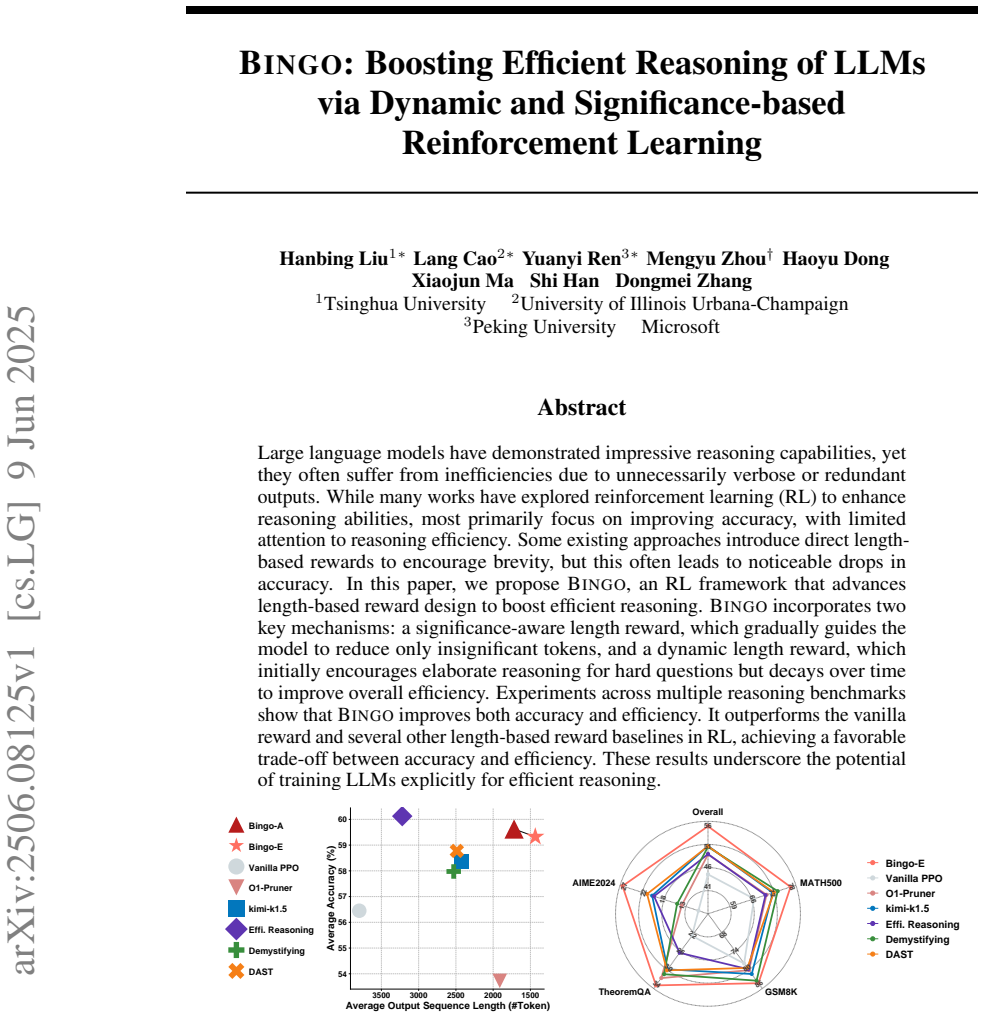
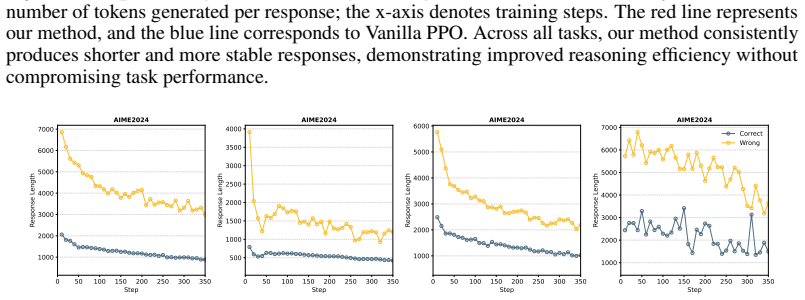
Large language models (LLMs) show strong reasoning abilities but often produce unnecessarily long explanations that reduce efficiency. Although reinforcement learning (RL) has been used to improve reasoning, most methods focus on accuracy and rely on uniform length-based rewards that overlook the differing contributions of individual tokens, often harming correctness. We revisit length optimization in RL through the perspective of token significance. Observing that many chain-of-thought (CoT) tokens contribute little to the final answer, we introduce a significance-aware length reward that selectively penalizes insignificance tokens, reducing redundancy while preserving essential reasoning. We also propose a dynamic length reward that encourages more detailed reasoning early in training and gradually shifts toward conciseness as learning progresses. Integrating these components into standard policy optimization yields a framework that improves both reasoning efficiency and accuracy. Experiments across multiple benchmarks demonstrate substantial reductions in response length while preserving or improving correctness, highlighting the importance of modeling token significance for efficient LLM reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes integrating token significance estimation into RL-based length optimization for LLM reasoning. It introduces a significance-aware length reward that selectively penalizes low-significance CoT tokens and a dynamic length reward that shifts from encouraging detail early in training to conciseness later. These are combined with standard policy optimization to reduce response length while preserving or improving accuracy on reasoning benchmarks.
Significance. If the significance estimator reliably identifies redundant tokens without circular dependence on the policy, the framework could improve both efficiency and correctness over uniform length penalties, offering a practical advance in RL for long-form reasoning. The dynamic reward component is a notable design choice that addresses training dynamics.
major comments (2)
- [§3.2] §3.2 (significance estimation): The method for computing token significance is not externally validated against counterfactual answer changes or human-annotated essential steps. Without such a check (e.g., ablation removing high-significance tokens and measuring answer degradation), it is unclear whether the estimator captures causal contribution or merely correlates with the current policy's down-weighted tokens, risking circularity in the reward signal.
- [§4.1] §4.1 (experimental setup): The reported length reductions and accuracy gains lack error bars across multiple random seeds and do not include an ablation isolating the significance-aware reward from the dynamic reward. This makes it difficult to attribute improvements specifically to token significance modeling.
minor comments (2)
- Notation for the significance score s_t and its integration into the reward r_t should be defined explicitly in the main text rather than deferred to the appendix.
- Figure 2 (length vs. accuracy curves): Axis labels and legend entries are too small for readability; consider increasing font size or splitting into separate panels.
Simulated Author's Rebuttal
We appreciate the referee's insightful comments on our manuscript. We address each major comment below and plan to incorporate revisions to strengthen the presentation and validation of our proposed methods.
read point-by-point responses
-
Referee: [§3.2] §3.2 (significance estimation): The method for computing token significance is not externally validated against counterfactual answer changes or human-annotated essential steps. Without such a check (e.g., ablation removing high-significance tokens and measuring answer degradation), it is unclear whether the estimator captures causal contribution or merely correlates with the current policy's down-weighted tokens, risking circularity in the reward signal.
Authors: We thank the referee for this valuable feedback. We acknowledge that additional validation would help confirm the reliability of the token significance estimator. In the revised manuscript, we will include a new ablation study that removes high-significance tokens from the chain-of-thought and measures the degradation in reasoning accuracy. This will provide evidence of their causal contribution. We will also clarify in §3.2 how the significance is estimated to mitigate concerns about circular dependence on the policy. revision: yes
-
Referee: [§4.1] §4.1 (experimental setup): The reported length reductions and accuracy gains lack error bars across multiple random seeds and do not include an ablation isolating the significance-aware reward from the dynamic reward. This makes it difficult to attribute improvements specifically to token significance modeling.
Authors: We agree that reporting variability and isolating components is important for rigorous evaluation. In the revised version, we will rerun the experiments with multiple random seeds and report mean results with standard deviations (error bars). Additionally, we will add an ablation study that compares the full method against variants using only the significance-aware reward and only the dynamic length reward to better attribute the contributions of each component. revision: yes
Circularity Check
No significant circularity; empirical claims rest on external benchmarks
full rationale
The abstract and available description frame the contribution as an empirical RL framework that introduces significance-aware and dynamic length rewards, with results validated across multiple benchmarks showing reduced response length while preserving or improving correctness. No equations, self-citations, or derivation steps are visible that reduce a claimed prediction or uniqueness result to a fitted input or prior author work by construction. The central premise relies on experimental outcomes rather than an internal loop, satisfying the condition for a self-contained paper against external validation.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 2 Pith papers
-
Post Reasoning: Improving the Performance of Non-Thinking Models at No Cost
Post-Reasoning boosts LLM accuracy by reversing the usual answer-after-reasoning order, delivering mean relative gains of 17.37% across 117 model-benchmark pairs with zero extra cost.
-
Stop Overthinking: A Survey on Efficient Reasoning for Large Language Models
A survey organizing techniques to achieve efficient reasoning in LLMs by shortening chain-of-thought outputs.
Reference graph
Works this paper leans on
- [1]
-
[2]
Textbooks are all you need, 2023
Suriya Gunasekar, Yi Zhang, Jyoti Aneja, Caio César Teodoro Mendes, Allie Del Giorno, Sivakanth Gopi, Mojan Javaheripi, Piero Kauffmann, Gustavo de Rosa, Olli Saarikivi, Adil Salim, Shital Shah, Harkirat Singh Behl, Xin Wang, Sébastien Bubeck, Ronen Eldan, Adam Tau- man Kalai, Yin Tat Lee, and Yuanzhi Li. Textbooks are all you need, 2023
work page 2023
-
[3]
Solving math word problems with process- and outcome-based feedback, 2022
Jonathan Uesato, Nate Kushman, Ramana Kumar, Francis Song, Noah Siegel, Lisa Wang, Antonia Creswell, Geoffrey Irving, and Irina Higgins. Solving math word problems with process- and outcome-based feedback, 2022
work page 2022
-
[4]
Measuring Mathematical Problem Solving With the MATH Dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
- [5]
-
[6]
Theoremqa: A theorem-driven question answering dataset
Wenhu Chen, Ming Yin, Max Ku, Pan Lu, Yixin Wan, Xueguang Ma, Jianyu Xu, Xinyi Wang, and Tony Xia. Theoremqa: A theorem-driven question answering dataset. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 7889–7901, Singapore, 2023. Association for Computational Linguistics
work page 2023
-
[7]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022
work page 2022
-
[8]
Chi, Tatsunori Hashimoto, Oriol Vinyals, Percy Liang, Jeff Dean, and William Fedus
Jason Wei, Yi Tay, Rishi Bommasani, Colin Raffel, Barret Zoph, Sebastian Borgeaud, Dani Yogatama, Maarten Bosma, Denny Zhou, Donald Metzler, Ed H. Chi, Tatsunori Hashimoto, Oriol Vinyals, Percy Liang, Jeff Dean, and William Fedus. Emergent abilities of large language models, 2022
work page 2022
- [9]
-
[10]
Xiaoye Qu, Yafu Li, Zhaochen Su, Weigao Sun, Jianhao Yan, Dongrui Liu, Ganqu Cui, Daizong Liu, Shuxian Liang, Junxian He, Peng Li, Wei Wei, Jing Shao, Chaochao Lu, Yue Zhang, Xian- Sheng Hua, Bowen Zhou, and Yu Cheng. A survey of efficient reasoning for large reasoning models: Language, multimodality, and beyond, 2025
work page 2025
-
[11]
Stop overthinking: A survey on efficient reasoning for large language models, 2025
Yang Sui, Yu-Neng Chuang, Guanchu Wang, Jiamu Zhang, Tianyi Zhang, Jiayi Yuan, Hongyi Liu, Andrew Wen, Shaochen Zhong, Hanjie Chen, and Xia Hu. Stop overthinking: A survey on efficient reasoning for large language models, 2025
work page 2025
-
[12]
From system 1 to system 2: A survey of reasoning large language models, 2025
Zhong-Zhi Li, Duzhen Zhang, Ming-Liang Zhang, Jiaxin Zhang, Zengyan Liu, Yuxuan Yao, Haotian Xu, Junhao Zheng, Pei-Jie Wang, Xiuyi Chen, Yingying Zhang, Fei Yin, Jiahua Dong, Zhijiang Guo, Le Song, and Cheng-Lin Liu. From system 1 to system 2: A survey of reasoning large language models, 2025
work page 2025
-
[13]
Harnessing the reasoning economy: A survey of efficient reasoning for large language models, 2025
Rui Wang, Hongru Wang, Boyang Xue, Jianhui Pang, Shudong Liu, Yi Chen, Jiahao Qiu, Derek Fai Wong, Heng Ji, and Kam-Fai Wong. Harnessing the reasoning economy: A survey of efficient reasoning for large language models, 2025. 10
work page 2025
-
[14]
Tokenskip: Controllable chain-of-thought compression in llms, 2025
Heming Xia, Yongqi Li, Chak Tou Leong, Wenjie Wang, and Wenjie Li. Tokenskip: Controllable chain-of-thought compression in llms, 2025
work page 2025
-
[15]
Twt: Thinking without tokens by habitual reasoning distillation with multi-teachers’ guidance, 2025
Jingxian Xu, Mengyu Zhou, Weichang Liu, Hanbing Liu, Shi Han, and Dongmei Zhang. Twt: Thinking without tokens by habitual reasoning distillation with multi-teachers’ guidance, 2025
work page 2025
-
[16]
Lightthinker: Thinking step-by-step compression, 2025
Jintian Zhang, Yuqi Zhu, Mengshu Sun, Yujie Luo, Shuofei Qiao, Lun Du, Da Zheng, Huajun Chen, and Ningyu Zhang. Lightthinker: Thinking step-by-step compression, 2025
work page 2025
-
[17]
C3ot: Generating shorter chain-of- thought without compromising effectiveness, 2024
Yu Kang, Xianghui Sun, Liangyu Chen, and Wei Zou. C3ot: Generating shorter chain-of- thought without compromising effectiveness, 2024
work page 2024
-
[18]
O1-pruner: Length-harmonizing fine-tuning for o1-like reasoning pruning, 2025
Haotian Luo, Li Shen, Haiying He, Yibo Wang, Shiwei Liu, Wei Li, Naiqiang Tan, Xiaochun Cao, and Dacheng Tao. O1-pruner: Length-harmonizing fine-tuning for o1-like reasoning pruning, 2025
work page 2025
-
[19]
Kimi Team, Angang Du, Bofei Gao, Bowei Xing, Changjiu Jiang, Cheng Chen, Cheng Li, Chenjun Xiao, Chenzhuang Du, Chonghua Liao, Chuning Tang, Congcong Wang, Dehao Zhang, Enming Yuan, Enzhe Lu, Fengxiang Tang, Flood Sung, Guangda Wei, Guokun Lai, Haiqing Guo, Han Zhu, Hao Ding, Hao Hu, Hao Yang, Hao Zhang, Haotian Yao, Haotian Zhao, Haoyu Lu, Haoze Li, Haoz...
work page 2025
-
[20]
Training language models to reason efficiently, 2025
Daman Arora and Andrea Zanette. Training language models to reason efficiently, 2025
work page 2025
-
[21]
L1: Controlling how long a reasoning model thinks with reinforcement learning, 2025
Pranjal Aggarwal and Sean Welleck. L1: Controlling how long a reasoning model thinks with reinforcement learning, 2025
work page 2025
-
[22]
Demystifying long chain-of-thought reasoning in llms, 2025
Edward Yeo, Yuxuan Tong, Morry Niu, Graham Neubig, and Xiang Yue. Demystifying long chain-of-thought reasoning in llms, 2025
work page 2025
-
[23]
Dast: Difficulty-adaptive slow-thinking for large reasoning models, 2025
Shuming Shi, Jian Zhang, Yi Shen, Kai Wang, Shiguo Lian, Ning Wang, Wenjing Zhang, Jieyun Huang, and Jiangze Yan. Dast: Difficulty-adaptive slow-thinking for large reasoning models, 2025
work page 2025
-
[24]
Token dropping for efficient BERT pretraining
Le Hou, Richard Yuanzhe Pang, Tianyi Zhou, Yuexin Wu, Xinying Song, Xiaodan Song, and Denny Zhou. Token dropping for efficient BERT pretraining. In Smaranda Muresan, Preslav Nakov, and Aline Villavicencio, editors,Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 3774–3784, Dublin, Irela...
work page 2022
-
[25]
Rho-1: Not all tokens are what you need, 2025
Zhenghao Lin, Zhibin Gou, Yeyun Gong, Xiao Liu, Yelong Shen, Ruochen Xu, Chen Lin, Yujiu Yang, Jian Jiao, Nan Duan, and Weizhu Chen. Rho-1: Not all tokens are what you need, 2025
work page 2025
-
[26]
s1: Simple test-time scaling, 2025
Niklas Muennighoff, Zitong Yang, Weijia Shi, Xiang Lisa Li, Li Fei-Fei, Hannaneh Hajishirzi, Luke Zettlemoyer, Percy Liang, Emmanuel Candès, and Tatsunori Hashimoto. s1: Simple test-time scaling, 2025
work page 2025
-
[27]
When more is less: Understanding chain-of-thought length in llms, 2025
Yuyang Wu, Yifei Wang, Tianqi Du, Stefanie Jegelka, and Yisen Wang. When more is less: Understanding chain-of-thought length in llms, 2025
work page 2025
-
[28]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms. ArXiv, abs/1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[29]
Leslie Pack Kaelbling, Michael L. Littman, and Andrew W. Moore. Reinforcement learning: A survey. J. Artif. Intell. Res., 4:237–285, 1996
work page 1996
-
[30]
Deep reinforcement learning from human preferences
Paul Francis Christiano, Jan Leike, Tom B. Brown, Miljan Martic, Shane Legg, and Dario Amodei. Deep reinforcement learning from human preferences. ArXiv, abs/1706.03741, 2017. 11
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[31]
Learning to summarize from human feedback
Nisan Stiennon, Long Ouyang, Jeff Wu, Daniel M. Ziegler, Ryan J. Lowe, Chelsea V oss, Alec Radford, Dario Amodei, and Paul Christiano. Learning to summarize from human feedback. ArXiv, abs/2009.01325, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[32]
Training language models to follow instructions with human feedback
Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke E. Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Francis Christiano, Jan Leike, and Ryan J. Lowe. Training language models to follow instructions with h...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[33]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models, 2024
work page 2024
-
[34]
REINFORCE++: Stabilizing Critic-Free Policy Optimization with Global Advantage Normalization
Jian Hu. Reinforce++: A simple and efficient approach for aligning large language models. ArXiv, abs/2501.03262, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Let’s verify step by step, 2023
Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step, 2023
work page 2023
-
[36]
DeepSeek-AI, Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, Aixin Liu, Bing Xue, Bingxuan Wang, Bochao Wu, Bei Feng, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, Damai D...
work page 2025
- [37]
-
[38]
Fortune: Formula-driven reinforcement learning for symbolic table reasoning in language models
Lang Cao, Jingxian Xu, Hanbing Liu, Jinyu Wang, Mengyu Zhou, Haoyu Dong, Shi Han, and Dongmei Zhang. Fortune: Formula-driven reinforcement learning for symbolic table reasoning in language models. arXiv preprint arXiv:2505.23667, 2025
-
[39]
Chain-of-thought prompting elicits reasoning in large language models, 2023
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models, 2023
work page 2023
-
[40]
Griffiths, Yuan Cao, and Karthik Narasimhan
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models, 2023. 12
work page 2023
-
[41]
Lang Cao. GraphReason: Enhancing reasoning capabilities of large language models through a graph-based verification approach. In Bhavana Dalvi Mishra, Greg Durrett, Peter Jansen, Ben Lipkin, Danilo Neves Ribeiro, Lionel Wong, Xi Ye, and Wenting Zhao, editors,Proceedings of the 2nd Workshop on Natural Language Reasoning and Structured Explanations (@ACL 20...
work page 2024
-
[42]
Self-consistency improves chain of thought reasoning in language models, 2023
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models, 2023
work page 2023
-
[43]
Token-budget-aware llm reasoning, 2025
Tingxu Han, Zhenting Wang, Chunrong Fang, Shiyu Zhao, Shiqing Ma, and Zhenyu Chen. Token-budget-aware llm reasoning, 2025
work page 2025
-
[44]
Reasoning models can be effective without thinking, 2025
Wenjie Ma, Jingxuan He, Charlie Snell, Tyler Griggs, Sewon Min, and Matei Zaharia. Reasoning models can be effective without thinking, 2025
work page 2025
-
[45]
Chain of draft: Thinking faster by writing less, 2025
Silei Xu, Wenhao Xie, Lingxiao Zhao, and Pengcheng He. Chain of draft: Thinking faster by writing less, 2025
work page 2025
-
[46]
Vicky Zhao, Lili Qiu, and Dongmei Zhang
Zhuoshi Pan, Qianhui Wu, Huiqiang Jiang, Menglin Xia, Xufang Luo, Jue Zhang, Qingwei Lin, Victor Rühle, Yuqing Yang, Chin-Yew Lin, H. Vicky Zhao, Lili Qiu, and Dongmei Zhang. Llmlingua-2: Data distillation for efficient and faithful task-agnostic prompt compression, 2024
work page 2024
-
[47]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Jacob Hilton, Reiichiro Nakano, Christo- pher Hesse, and John Schulman. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[48]
Compressing context to enhance inference efficiency of large language models
Yucheng Li, Bo Dong, Frank Guerin, and Chenghua Lin. Compressing context to enhance inference efficiency of large language models. In Houda Bouamor, Juan Pino, and Kalika Bali, editors, Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 6342–6353, Singapore, December 2023. Association for Computational Linguistics
work page 2023
-
[49]
Llmlingua: Compress- ing prompts for accelerated inference of large language models, 2023
Huiqiang Jiang, Qianhui Wu, Chin-Yew Lin, Yuqing Yang, and Lili Qiu. Llmlingua: Compress- ing prompts for accelerated inference of large language models, 2023
work page 2023
-
[50]
Yucheng Li, Bo Dong, Chenghua Lin, and Frank Guerin. Compressing context to enhance inference efficiency of large language models, 2023. 13 Contents of Appendix A Limitations and Future Work 15 B Broader Impacts and Safeguards 15 C Discussion of Token Significance Measurement 16 D Theoretical Analysis of Significance-Aware Length Reward 16 E Theoretical D...
work page 2023
-
[51]
Why does encouraging longer chains of thought (CoT) during early training help exploration?
-
[52]
Why does applying a fixed length penalty throughout training limit performance?
-
[53]
Why does dynamically flipping the reward from positive to negative upon convergence yield better accuracy–efficiency trade-offs?
-
[54]
Longer CoT Enables Richer Exploration. Let Pt(L) be the model’s distribution over output lengths at training stept, and define A(L) = Pr ˆz(y) = z | L(y) = L (27) as the expected accuracy (e.g., exact match) given output length L. Empirically, A(L) follows a saturating “S-curve”: A′(L) > 0 for L < L ⋆, A ′(L) ≈ 0 for L ≥ L⋆, (28) 18 where A′(L) denotes th...
-
[55]
Consider a fixed length penalty λ > 0, giving the reward Jstatic(L) = A(L) − λL
Static Length Penalty Causes Premature Compression. Consider a fixed length penalty λ > 0, giving the reward Jstatic(L) = A(L) − λL. (30) The optimal length Ls under this objective satisfies A′(Ls) = λ. (31) Since A′(L) vanishes for L ≥ L⋆, any λ > 0 forces Ls < L ⋆, implying A(Ls) < A(L⋆). (32) As A′(L) > 0 for L < L ⋆, the reward Jstatic(L) reaches its ...
-
[56]
Let’s think step by step and output the final answer within \boxed
Dynamic Penalty Supports a Two-Phase Curriculum. We introduce a time-dependent penalty λt: λt = ( 0, t < t 0 (exploration phase), α (t − t0), t ≥ t0 (compression phase), (33) where t0 is the step at which validation accuracy (training batch accuracy used in the experiments) stabilizes, i.e. when ˙At = Acct − Acct−∆ ∆ < β. (34) Phase I (Exploration). Durin...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.