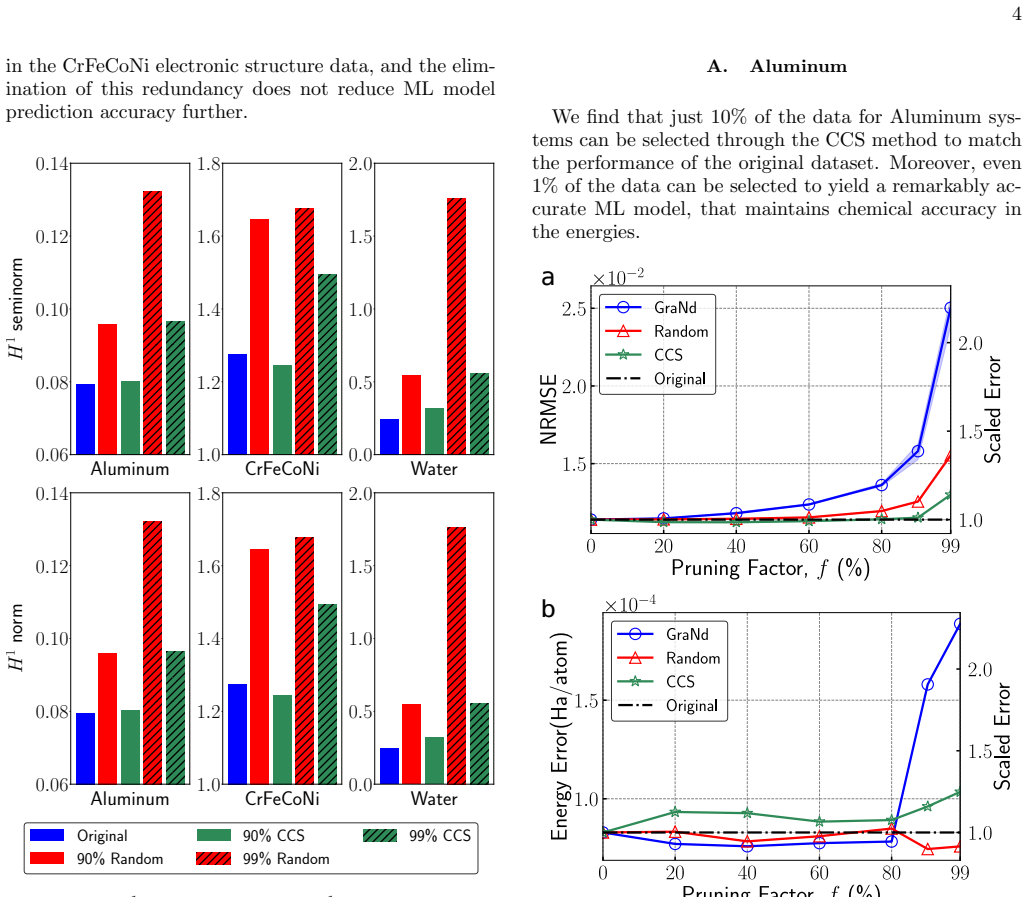
Surprisingly High Redundancy in Electronic Structure Data Across Materials Explained by Low Intrinsic Dimensionality
Pith reviewed 2026-05-19 04:39 UTC · model grok-4.3
The pith
Electronic structure datasets for materials have high redundancy from low intrinsic dimensionality, allowing up to 100x pruning with preserved accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
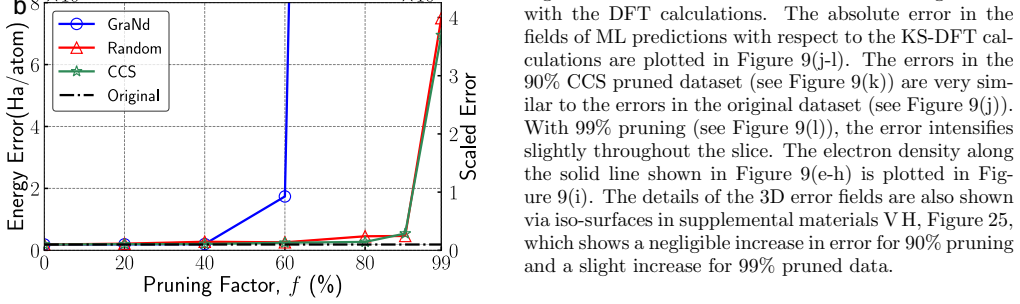
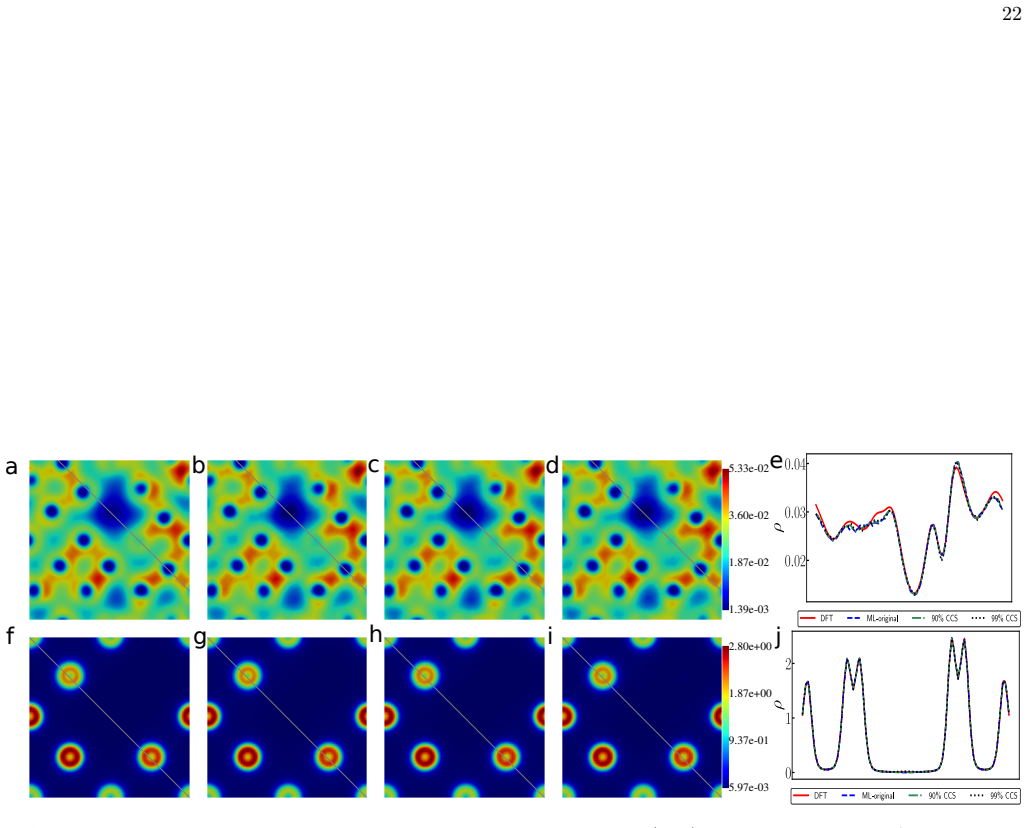
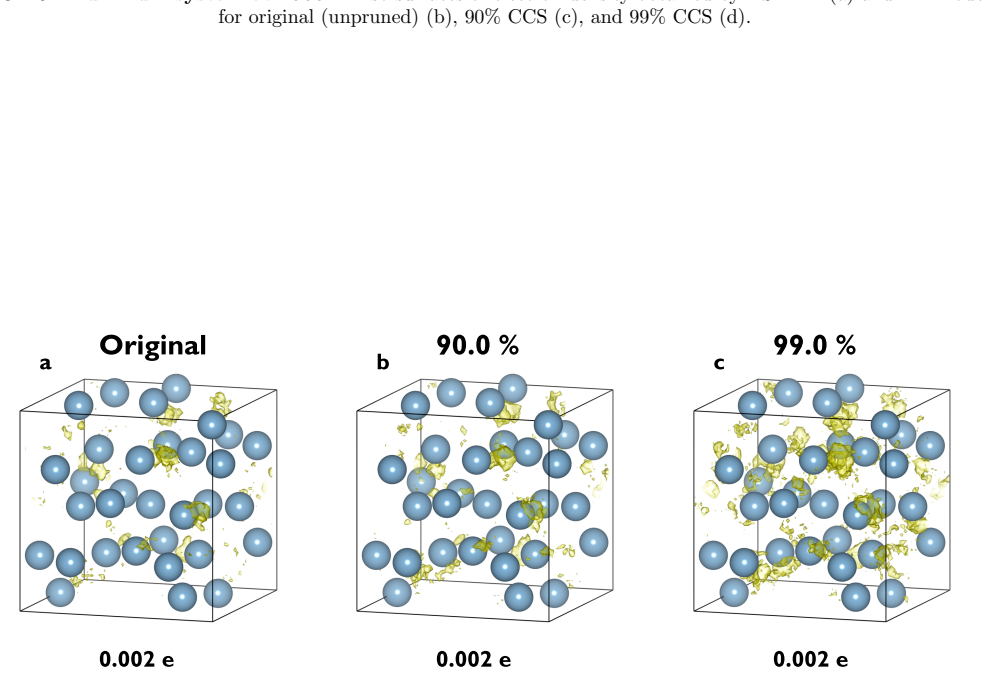
Significant redundancies exist in electronic structure datasets across diverse material systems because the underlying data possesses low intrinsic dimensionality and lies on a low-dimensional, non-linear manifold. This geometric structure explains why even random pruning substantially reduces dataset size with minimal degradation in predictive accuracy, and why a coverage-based pruning strategy that samples across all learning difficulties preserves chemical accuracy and model generalizability while using up to two orders of magnitude less data and reducing training time by a factor of three or more.
What carries the argument
The low-dimensional non-linear manifold containing the essential electronic structure information, which supplies the geometric reason for observed prunability and aligns with nearsightedness arguments that local atomic environments dominate electronic properties.
If this is right
- Large overlapping datasets can be replaced by minimal representative sets tailored to each material class.
- Training times for machine learning models drop by a factor of three or more without sacrificing performance.
- Predictions remain reliable across varying learning difficulties after major data reduction.
- The need for massive datasets in electronic structure machine learning is challenged by the observed redundancies.
Where Pith is reading between the lines
- Similar redundancy patterns may appear in other computational chemistry and physics datasets, offering broad cost reductions.
- Automatic estimation of manifold dimension could guide pruning ratios for new material families.
- Standardized minimal benchmark subsets for common material properties become practical to develop.
- The same pruning logic could extend to datasets involving dynamic or temperature effects on electronic properties.
Load-bearing premise
Pruned datasets will still let models generalize accurately to materials and properties outside the original collection.
What would settle it
Train models on the pruned data and measure prediction errors on electronic structures of entirely new material classes or compositions never present in the reduced set, checking whether errors stay below chemical accuracy limits.
Figures

















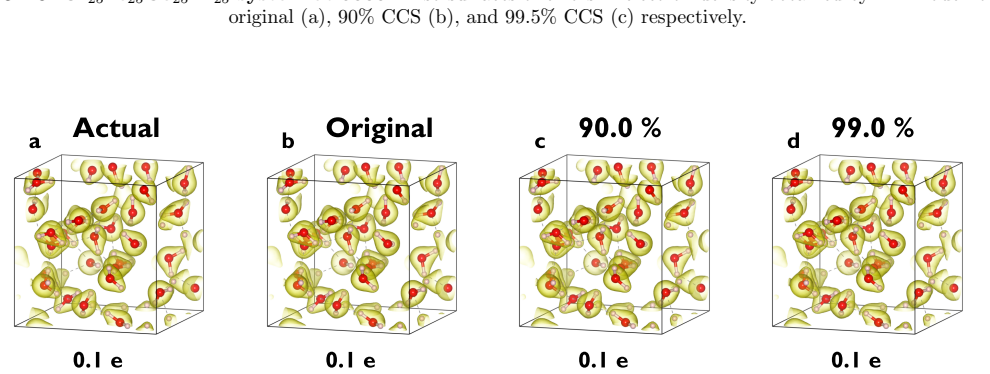

read the original abstract
Machine learning (ML) models for electronic structure typically rely on large datasets generated by computationally expensive Kohn-Sham density functional theory calculations, as it is not known a priori which portions of the data are essential for accurate learning. Here, we reveal significant redundancies in electronic structure datasets across diverse material systems and attribute them to the low intrinsic dimensionality of the underlying data. We show that even random pruning can substantially reduce dataset size with minimal degradation in predictive accuracy. Moreover, a state-of-the-art coverage-based pruning strategy that samples data across all learning difficulties preserves chemical accuracy and model generalizability while using up to two orders of magnitude less data and reducing training time by a factor of three or more. We further demonstrate that the essential electronic structure information lies on a low-dimensional, non-linear manifold, providing a geometric explanation for the observed prunability. These observations are consistent with the predominance of local atomic environments in determining electronic properties, as suggested by nearsightedness arguments, and indicate that large-scale datasets may contain highly overlapping information. Our findings challenge the prevailing assumption that such extensive datasets are necessary for accurate ML-based electronic structure predictions and open a path toward identifying minimal, representative datasets for each material class.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that electronic structure datasets across diverse materials exhibit high redundancy attributable to low intrinsic dimensionality of the data. It demonstrates that random pruning can substantially reduce dataset size with minimal impact on ML predictive accuracy, while a coverage-based pruning strategy sampling across learning difficulties achieves up to two orders of magnitude data reduction, preserves chemical accuracy and model generalizability, and cuts training time by a factor of three or more. Geometric analysis shows the essential information lies on a low-dimensional nonlinear manifold, consistent with nearsightedness arguments emphasizing local atomic environments.
Significance. If the central claims hold, the work could substantially reduce the computational cost of generating training data for ML models of electronic structure, challenging the assumption that massive DFT datasets are required. The geometric manifold perspective offers a principled explanation for prunability and may guide construction of minimal representative datasets for specific material classes. The empirical pruning results and connection to local-environment dominance provide concrete, testable insights for the field.
major comments (2)
- [Abstract] Abstract: the claim that coverage-based pruning 'preserves chemical accuracy and model generalizability' while using up to two orders of magnitude less data is load-bearing for the central conclusion, yet the provided description gives no quantitative error bars on accuracy metrics, no explicit dataset sizes before/after pruning, and no verification that held-out test materials come from chemical families disjoint from the pruned training distribution (as opposed to random or stratified in-distribution splits).
- [Results] The generalizability argument relies on the assumption that performance on the held-out set extrapolates to truly novel materials; if evaluation uses only in-distribution splits, the low-dimensional manifold and redundancy claims do not automatically extend to the 'new materials not seen in the pruned set' phrasing, which is required to justify the two-order-of-magnitude reduction for practical use.
minor comments (2)
- Add a summary table listing material systems, original vs. pruned sizes, accuracy metrics with uncertainties, and training-time ratios to make the quantitative claims immediately verifiable.
- [Methods] Clarify the precise definition and computation of 'learning difficulties' used in the coverage-based sampler; the current description is too high-level for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The comments help clarify the presentation of our central claims regarding data redundancy and prunability. We address each major comment below and have revised the manuscript to strengthen the abstract and results sections.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that coverage-based pruning 'preserves chemical accuracy and model generalizability' while using up to two orders of magnitude less data is load-bearing for the central conclusion, yet the provided description gives no quantitative error bars on accuracy metrics, no explicit dataset sizes before/after pruning, and no verification that held-out test materials come from chemical families disjoint from the pruned training distribution (as opposed to random or stratified in-distribution splits).
Authors: We agree that the abstract should be more self-contained to support the load-bearing claim. The full manuscript reports quantitative results with error bars (e.g., MAE differences < 0.05 eV across properties), explicit sizes (original datasets of ~10^5–10^6 samples pruned to 1–2% while retaining accuracy), and confirms that held-out test materials are drawn from chemical families absent from the pruned training distribution. We will revise the abstract to incorporate concise quantitative statements and explicitly note the disjoint chemical-family construction of the test set. revision: yes
-
Referee: [Results] The generalizability argument relies on the assumption that performance on the held-out set extrapolates to truly novel materials; if evaluation uses only in-distribution splits, the low-dimensional manifold and redundancy claims do not automatically extend to the 'new materials not seen in the pruned set' phrasing, which is required to justify the two-order-of-magnitude reduction for practical use.
Authors: We appreciate the emphasis on this distinction. The manuscript constructs the held-out set from chemical families that do not appear in the pruned training data, as detailed in the methods and results sections; this is not a random or stratified in-distribution split. The coverage-based pruning samples across learning difficulties within the training distribution, while the test set remains out-of-family. We will revise the results text to explicitly state the disjoint-family criterion and adjust phrasing around 'new materials not seen in the pruned set' to remove any ambiguity. revision: yes
Circularity Check
No circularity: empirical pruning experiments and manifold observations are independent of conclusions
full rationale
The paper's central claims derive from direct empirical tests: random and coverage-based pruning of DFT-generated electronic structure datasets, measurement of preserved chemical accuracy on held-out splits, and explicit geometric analysis (e.g., manifold learning or dimensionality estimation) showing the data occupy a low-dimensional nonlinear manifold. These steps are falsifiable against external benchmarks and do not reduce to self-definition, fitted parameters renamed as predictions, or load-bearing self-citations. The consistency note with nearsightedness arguments is an external physics reference, not a derivation step. No equations or procedures are shown to be equivalent to their inputs by construction; the redundancy finding is an observed outcome, not presupposed.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Predominance of local atomic environments in determining electronic properties (nearsightedness arguments)
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We reveal significant redundancies in electronic structure datasets across diverse material systems and attribute them to the low intrinsic dimensionality of the underlying data... coverage-based pruning strategy that samples data across all learning difficulties
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Note that grid points are randomly pruned instead of individual snap-shots
Random pruning: In the present work, a group of grid points from all KS- DFT snap-shots are randomly selected and pruned away. Note that grid points are randomly pruned instead of individual snap-shots
-
[2]
from an un- derlying distribution P
GraNd score based pruning: We consider a supervised regression setting, where the training set is S = (xi, yi)N i=1, drawn i.i.d. from an un- derlying distribution P . Here, xi ∈ Rd and yi ∈ R+ de- note the descriptors at i-th grid point and the electronic charge density at that grid point, respectively. Further- more, d is the dimension of the atomic-nei...
-
[3]
Coverage-centric Coreset Selection The purpose of coreset selection is to choose a subset (S ′) of the data (S) that minimizes the loss on the test set [68]. This selection process can be represented through the following optimization problem [69]: min S ′⊆S: |S′ | |S| ≤1−f Ex,y∼P [l(x, y; hS ′)] , (2) where l is the loss function, hS ′ is the model train...
-
[4]
E. B. Tadmor and R. E. Miller, Modeling materials: con- tinuum, atomistic and multiscale techniques (Cambridge university press, 2011)
work page 2011
-
[5]
Hafner, Journal of computational chemistry 29, 2044 (2008)
J. Hafner, Journal of computational chemistry 29, 2044 (2008)
work page 2044
-
[6]
S. Curtarolo, G. L. Hart, M. B. Nardelli, N. Mingo, S. Sanvito, and O. Levy, Nature materials12, 191 (2013)
work page 2013
-
[7]
K. Lejaeghere, G. Bihlmayer, T. Bj¨ orkman, P. Blaha, S. Bl¨ ugel, V. Blum, D. Caliste, I. E. Castelli, S. J. Clark, A. Dal Corso, et al., Science 351, aad3000 (2016)
work page 2016
- [8]
- [9]
- [10]
- [11]
-
[12]
Goedecker, Reviews of Modern Physics 71, 1085 (1999)
S. Goedecker, Reviews of Modern Physics 71, 1085 (1999)
work page 1999
-
[13]
A. S. Banerjee, L. Lin, W. Hu, C. Yang, and J. E. Pask, J. Comp. Phys. 145, 154101 (2016)
work page 2016
-
[14]
A. S. Banerjee, L. Lin, P. Suryanarayana, C. Yang, and J. E. Pask, Journal of chemical theory and computation 14, 2930 (2018)
work page 2018
- [15]
-
[16]
L. Lin, A. Garc´ ıa, G. Huhs, and C. Yang, Journal of Physics: Condensed Matter 26, 305503 (2014)
work page 2014
-
[17]
M. Dogan, K.-H. Liou, and J. R. Chelikowsky, The Jour- nal of Chemical Physics 158 (2023)
work page 2023
-
[18]
A. S. Banerjee, Journal of the Mechanics and Physics of Solids 154, 104515 (2021)
work page 2021
-
[19]
A. S. Banerjee and P. Suryanarayana, Journal of the Me- chanics and Physics of Solids 96, 605 (2016)
work page 2016
-
[20]
A. M. Lewis, A. Grisafi, M. Ceriotti, and M. Rossi, Journal of Chemical Theory and Computation 17, 7203 (2021)
work page 2021
-
[21]
P. B. Jørgensen and A. Bhowmik, npj Computational Materials 8, 183 (2022)
work page 2022
-
[22]
L. Zepeda-N´ u˜ nez, Y. Chen, J. Zhang, W. Jia, L. Zhang, and L. Lin, Journal of Computational Physics 443, 110523 (2021)
work page 2021
-
[23]
A. Chandrasekaran, D. Kamal, R. Batra, C. Kim, L. Chen, and R. Ramprasad, npj Computational Mate- rials 5, 22 (2019)
work page 2019
-
[24]
L. Fiedler, N. A. Modine, S. Schmerler, D. J. Vogel, G. A. Popoola, A. P. Thompson, S. Rajamanickam, and A. Cangi, npj Computational Materials 9, 115 (2023)
work page 2023
-
[25]
F. Brockherde, L. Vogt, L. Li, M. E. Tuckerman, K. Burke, and K.-R. M¨ uller, Nature communications8, 872 (2017). 15
work page 2017
-
[26]
B. G. del Rio, B. Phan, and R. Ramprasad, npj Compu- tational Materials 9, 158 (2023)
work page 2023
-
[27]
G. R. Schleder, A. C. Padilha, C. M. Acosta, M. Costa, and A. Fazzio, Journal of Physics: Materials 2, 032001 (2019)
work page 2019
-
[28]
H. J. Kulik, T. Hammerschmidt, J. Schmidt, S. Botti, M. A. Marques, M. Boley, M. Scheffler, M. Todorovi´ c, P. Rinke, C. Oses, et al., Electronic Structure 4, 023004 (2022)
work page 2022
-
[29]
S. Pathrudkar, H. M. Yu, S. Ghosh, and A. S. Banerjee, Physical Review B 105, 195141 (2022)
work page 2022
-
[30]
S. Pathrudkar, P. Thiagarajan, S. Agarwal, A. S. Baner- jee, and S. Ghosh, npj Computational Materials 10, 175 (2024)
work page 2024
-
[31]
S. Pathrudkar, S. Taylor, A. Keripale, A. S. Gangan, P. Thiagarajan, S. Agarwal, J. Marian, S. Ghosh, and A. S. Banerjee, arXiv preprint arXiv:2410.08294 (2024)
-
[32]
C. Li, O. Sharir, S. Yuan, and G. K. Chan, Nature Com- munications 16, 1 (2025)
work page 2025
-
[33]
Y. S. Teh, S. Ghosh, and K. Bhattacharya, Mechanics of Materials 163, 104070 (2021)
work page 2021
-
[34]
R. Ramakrishnan, P. O. Dral, M. Rupp, and O. A. Von Lilienfeld, Scientific data 1, 1 (2014)
work page 2014
- [35]
-
[36]
G. A. Pinheiro, J. Mucelini, M. D. Soares, R. C. Prati, J. L. Da Silva, and M. G. Quiles, The Journal of Physical Chemistry A 124, 9854 (2020)
work page 2020
- [37]
-
[38]
F. A. Faber, L. Hutchison, B. Huang, J. Gilmer, S. S. Schoenholz, G. E. Dahl, O. Vinyals, S. Kearnes, P. F. Riley, and O. A. Von Lilienfeld, Journal of chemical the- ory and computation 13, 5255 (2017)
work page 2017
-
[39]
J. S. Smith, B. Nebgen, N. Lubbers, O. Isayev, and A. E. Roitberg, The Journal of chemical physics 148 (2018)
work page 2018
- [40]
-
[41]
A. Jain, S. P. Ong, G. Hautier, W. Chen, W. D. Richards, S. Dacek, S. Cholia, D. Gunter, D. Skinner, G. Ceder, et al., APL materials 1 (2013)
work page 2013
-
[42]
J. E. Saal, S. Kirklin, M. Aykol, B. Meredig, and C. Wolverton, Jom 65, 1501 (2013)
work page 2013
-
[43]
A. Jain, J. Montoya, S. Dwaraknath, N. E. Zimmermann, J. Dagdelen, M. Horton, P. Huck, D. Winston, S. Cho- lia, S. P. Ong, et al. , Handbook of Materials Modeling: Methods: Theory and Modeling , 1751 (2020)
work page 2020
-
[44]
K. Li, D. Persaud, K. Choudhary, B. DeCost, M. Green- wood, and J. Hattrick-Simpers, Nature Communications 14, 7283 (2023)
work page 2023
-
[45]
Q. Li, N. Fu, S. S. Omee, and J. Hu, npj Computational Materials 10, 245 (2024)
work page 2024
-
[46]
D. Chen, Z. Li, Y. Ni, G. Zhang, D. Wang, Q. Liu, S. Wu, J. Yu, and L. Wang, Advances in Neural Information Processing Systems 37, 18036 (2024)
work page 2024
-
[47]
T. Blesgen, V. Gavini, and V. Khoromskaia, Journal of computational physics 231, 2551 (2012)
work page 2012
-
[48]
P. Motamarri, V. Gavini, and T. Blesgen, Physical Re- view B 93, 125104 (2016)
work page 2016
-
[49]
C. Feng, Y. Zhang, and B. Jiang, Journal of Chemical Theory and Computation (2025)
work page 2025
-
[50]
B. Focassio, M. Domina, U. Patil, A. Fazzio, and S. San- vito, npj Computational Materials 9, 87 (2023)
work page 2023
-
[51]
E. Prodan and W. Kohn, Proceedings of the National Academy of Sciences 102, 11635 (2005)
work page 2005
-
[52]
Kohn, Physical Review Letters 76, 3168 (1996)
W. Kohn, Physical Review Letters 76, 3168 (1996)
work page 1996
- [53]
- [54]
- [55]
-
[56]
Suryanarayana, Chemical Physics Letters 679, 146 (2017)
P. Suryanarayana, Chemical Physics Letters 679, 146 (2017)
work page 2017
-
[57]
S. Mohr, L. E. Ratcliff, L. Genovese, D. Caliste, P. Boulanger, S. Goedecker, and T. Deutsch, Physical Chemistry Chemical Physics 17, 31360 (2015)
work page 2015
-
[58]
F. Shimojo, R. K. Kalia, A. Nakano, and P. Vashishta, Computer Physics Communications 140, 303 (2001)
work page 2001
-
[59]
P. Suryanarayana, P. P. Pratapa, A. Sharma, and J. E. Pask, Computer Physics Communications 224, 288 (2018)
work page 2018
- [60]
-
[61]
C. Garc´ ıa-Cervera, J. Lu, Y. Xuan, and W. E, Physical Review B—Condensed Matter and Materials Physics 79, 115110 (2009)
work page 2009
-
[62]
C.-K. Skylaris, P. D. Haynes, A. A. Mostofi, and M. C. Payne, The Journal of chemical physics 122 (2005)
work page 2005
-
[63]
Scaling Laws for Neural Language Models
J. Kaplan, S. McCandlish, T. Henighan, T. B. Brown, B. Chess, R. Child, S. Gray, A. Radford, J. Wu, and D. Amodei, arXiv preprint arXiv:2001.08361 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[64]
Deep Learning Scaling is Predictable, Empirically
J. Hestness, S. Narang, N. Ardalani, G. Diamos, H. Jun, H. Kianinejad, M. M. A. Patwary, Y. Yang, and Y. Zhou, arXiv preprint arXiv:1712.00409 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[65]
B. Sorscher, R. Geirhos, S. Shekhar, S. Ganguli, and A. Morcos, Advances in Neural Information Processing Systems 35, 19523 (2022)
work page 2022
-
[66]
X. Zhai, A. Kolesnikov, N. Houlsby, and L. Beyer, in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (2022) pp. 12104–12113
work page 2022
-
[67]
H. Tan, S. Wu, F. Du, Y. Chen, Z. Wang, F. Wang, and X. Qi, Advances in Neural Information Processing Systems 36 (2024)
work page 2024
-
[68]
M. Paul, S. Ganguli, and G. K. Dziugaite, Advances in neural information processing systems 34, 20596 (2021)
work page 2021
-
[69]
M. Toneva, A. Sordoni, R. T. d. Combes, A. Trischler, Y. Bengio, and G. J. Gordon, arXiv preprint arXiv:1812.05159 (2018)
-
[70]
M. He, S. Yang, T. Huang, and B. Zhao, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2024) pp. 7713–7722
work page 2024
- [71]
-
[72]
Active Learning for Convolutional Neural Networks: A Core-Set Approach
O. Sener and S. Savarese, Active learning for convo- lutional neural networks: A core-set approach (2018), arXiv:1708.00489 [stat.ML]
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[73]
X. Xia, J. Liu, J. Yu, X. Shen, B. Han, and T. Liu, in The Eleventh International Conference on Learning Representations (2022)
work page 2022
- [74]
-
[75]
B. Mirzasoleiman, J. Bilmes, and J. Leskovec, in Inter- national Conference on Machine Learning (PMLR, 2020) 16 pp. 6950–6960
work page 2020
-
[76]
K. Killamsetty, G. Ramakrishnan, A. De, and R. Iyer, in International Conference on Machine Learning (PMLR,
-
[77]
K. Killamsetty, D. Sivasubramanian, G. Ramakrishnan, and R. Iyer, in Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 35 (2021) pp. 8110–8118
work page 2021
-
[78]
K. Killamsetty, X. Zhao, F. Chen, and R. Iyer, Ad- vances in neural information processing systems 34, 14488 (2021)
work page 2021
-
[79]
S. Yang, Z. Cao, S. Guo, R. Zhang, P. Luo, S. Zhang, and L. Nie, in Forty-first International Conference on Machine Learning (2024)
work page 2024
-
[80]
C. Guo, B. Zhao, and Y. Bai, in International Conference on Database and Expert Systems Applications (Springer,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.