Learning from Natural Language Feedback for Personalized Question Answering
Pith reviewed 2026-05-18 22:52 UTC · model grok-4.3
The pith
Natural language feedback replaces scalar rewards to better personalize question answering models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
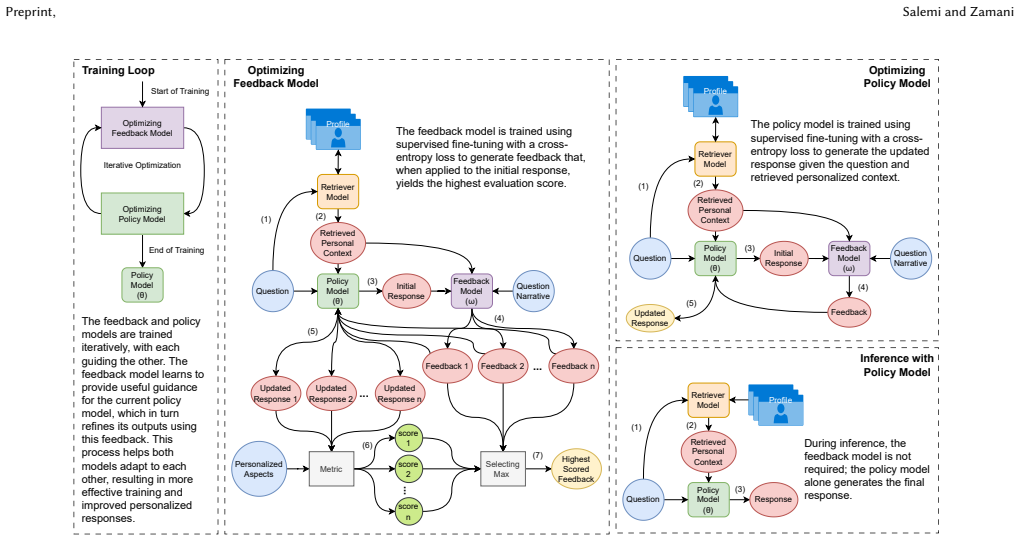
Natural language feedback serves as a rich and actionable supervision signal, allowing the policy model to iteratively refine its outputs and internalize effective personalization strategies. Training alternates between optimizing the feedback model and fine-tuning the policy model on the improved responses, resulting in a policy model that no longer requires feedback at inference and produces consistent improvements over the state-of-the-art on LaMP-QA.
What carries the argument
VAC framework: alternating optimization in which a feedback model generates natural language feedback conditioned on user profiles and question narratives to supervise iterative refinement of the policy model's personalized answers.
If this is right
- The policy model internalizes personalization strategies and generates high-quality responses without any feedback at inference time.
- Consistent and significant gains appear over prior state-of-the-art methods across the three domains in the LaMP-QA benchmark.
- Human evaluations rate the final responses as higher quality than those from scalar-reward approaches.
- Natural language feedback supplies more instructive optimization signals than scalar rewards alone.
Where Pith is reading between the lines
- The alternating training loop could be tested on other personalization settings such as recommendation or summarization where user context is available.
- If the feedback model generalizes across domains, the approach might enable faster adaptation to new users with limited history.
- Model-generated natural language critiques could reduce dependence on costly human-written feedback in similar alignment pipelines.
Load-bearing premise
The generated natural language feedback is consistently high-quality, unbiased, and more informative than scalar rewards without introducing new inconsistencies or hallucinations that could degrade the policy model during alternating optimization.
What would settle it
If a controlled experiment on LaMP-QA shows that the VAC policy model fails to outperform scalar-reward baselines on automatic metrics or human preference judgments, or if performance drops when feedback quality is degraded, the central claim would be falsified.
Figures









read the original abstract
Personalization is crucial for enhancing both the effectiveness and user satisfaction of language technologies, particularly in information-seeking tasks like question answering. Current approaches for personalizing large language models (LLMs) often rely on retrieval-augmented generation (RAG), followed by reinforcement learning with scalar reward signals to teach models how to use retrieved personal context. We believe that these scalar rewards sometimes provide weak, non-instructive feedback, limiting learning efficiency and personalization quality. We introduce VAC, a novel framework for personalized response generation that replaces scalar rewards with natural language feedback (NLF) that are generated conditioned on the user profiles and the question narratives. NLF serves as a rich and actionable supervision signal, allowing the policy model to iteratively refine its outputs and internalize effective personalization strategies. Training alternates between optimizing the feedback model and fine-tuning the policy model on the improved responses, resulting in a policy model that no longer requires feedback at inference. Evaluation on the LaMP-QA benchmark that consists of three diverse domains demonstrates consistent and significant improvements over the state-of-the-art results. Human evaluations further confirm the superior quality of the generated responses. These results demonstrate that NLF provides more effective signals for optimizing personalized question answering.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces VAC, a framework for personalized question answering that replaces scalar rewards with natural language feedback (NLF) generated conditioned on user profiles and question narratives. Training alternates between optimizing the feedback model and fine-tuning the policy model on the resulting responses, yielding a policy that requires no feedback at inference time. The approach is evaluated on the LaMP-QA benchmark across three domains and reports consistent improvements over prior state-of-the-art methods, corroborated by human evaluations.
Significance. If the alternating optimization maintains high-quality, unbiased NLF without introducing hallucinations or profile misinterpretations, the method could supply richer supervision than scalar rewards and improve personalization in information-seeking tasks. The LaMP-QA gains and human evaluations would then constitute a meaningful advance over RAG-plus-RL baselines. The result's impact depends on demonstrating that feedback quality does not degrade across iterations.
major comments (2)
- [Method] The alternating optimization procedure (described in the method) provides no explicit safeguard—such as regularization, divergence monitoring between successive feedback rounds, or periodic human filtering—against feedback-model drift or hallucination. This is load-bearing for the central claim that NLF supplies strictly richer, actionable supervision than scalar rewards.
- [Experiments] No quantitative assessment of NLF quality (e.g., human ratings of feedback accuracy, consistency with user profiles, or hallucination rate) is reported, nor are statistical significance tests or variance estimates supplied for the LaMP-QA improvements. These omissions prevent verification that the observed gains are robust rather than artifacts of unmonitored feedback degradation.
minor comments (1)
- [Abstract] The abstract states that LaMP-QA consists of 'three diverse domains' but does not name them; adding this detail would improve clarity for readers unfamiliar with the benchmark.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments on our manuscript. We address each major comment below with clarifications from the current work and indicate where revisions will be made to improve the presentation of safeguards and evaluation details.
read point-by-point responses
-
Referee: [Method] The alternating optimization procedure (described in the method) provides no explicit safeguard—such as regularization, divergence monitoring between successive feedback rounds, or periodic human filtering—against feedback-model drift or hallucination. This is load-bearing for the central claim that NLF supplies strictly richer, actionable supervision than scalar rewards.
Authors: We agree that safeguards against potential drift or hallucination in the alternating loop are important for the central claim. The VAC method initializes the feedback model from a strong pretrained LLM and generates NLF explicitly conditioned on user profiles and question narratives to promote grounded, profile-consistent feedback. The alternating process allows the policy to internalize effective strategies so that feedback is not needed at inference. While explicit regularization or divergence monitoring was not implemented or reported in the original submission, the human evaluations on final responses show consistent gains over baselines, suggesting the process did not suffer from severe degradation. In the revision we will add a dedicated paragraph in the method section discussing these risks and outlining simple monitoring approaches (e.g., periodic consistency checks) as future safeguards, without retroactively claiming they were applied. revision: partial
-
Referee: [Experiments] No quantitative assessment of NLF quality (e.g., human ratings of feedback accuracy, consistency with user profiles, or hallucination rate) is reported, nor are statistical significance tests or variance estimates supplied for the LaMP-QA improvements. These omissions prevent verification that the observed gains are robust rather than artifacts of unmonitored feedback degradation.
Authors: We acknowledge that direct quantitative assessment of NLF quality and statistical details for the automatic metrics were not included. The manuscript reports human evaluations only on the final personalized responses, which provide indirect support for the training signal quality. We will revise the experiments section to add human ratings on a sampled set of NLF instances for accuracy, profile consistency, and hallucination rate. We will also report standard deviations across multiple runs and include statistical significance tests (e.g., paired t-tests) for the LaMP-QA improvements to demonstrate robustness. revision: yes
Circularity Check
No circularity: new training procedure evaluated on external benchmark with no self-referential reductions
full rationale
The paper presents VAC as a novel alternating optimization framework that replaces scalar rewards with natural language feedback generated from user profiles and question narratives. It describes iterative refinement of a policy model on an external LaMP-QA benchmark across three domains, with reported gains over prior SOTA and human evaluations. No equations, derivations, or first-principles claims appear that reduce by construction to fitted inputs, self-citations, or renamed patterns. The method is self-contained against the independent benchmark, with no load-bearing self-citation chains or definitional loops in the provided description.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Natural language feedback generated from user profiles and question narratives constitutes richer and more actionable supervision than scalar rewards for personalizing LLM outputs.
Reference graph
Works this paper leans on
-
[1]
Payal Bajaj, Daniel Campos, Nick Craswell, Li Deng, Jianfeng Gao, Xiaodong Liu, Rangan Majumder, Andrew McNamara, Bhaskar Mitra, Tri Nguyen, Mir Rosenberg, Xia Song, Alina Stoica, Saurabh Tiwary, and Tong Wang. 2018. MS MARCO: A Human Generated MAchine Reading COmprehension Dataset. arXiv:1611.09268 [cs.CL] https://arxiv.org/abs/1611.09268
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[2]
Bowman, Kyunghyun Cho, and Ethan Perez
Angelica Chen, Jérémy Scheurer, Jon Ander Campos, Tomasz Korbak, Jun Shern Chan, Samuel R. Bowman, Kyunghyun Cho, and Ethan Perez. 2024. Learning from Natural Language Feedback. Transactions on Machine Learning Research (2024). https://openreview.net/forum?id=xo3hI5MwvU
work page 2024
-
[3]
Bowman, Kyunghyun Cho, and Ethan Perez
Angelica Chen, Jérémy Scheurer, Tomasz Korbak, Jon Ander Campos, Jun Sh- ern Chan, Samuel R. Bowman, Kyunghyun Cho, and Ethan Perez. 2024. Improving Code Generation by Training with Natural Language Feedback. arXiv:2303.16749 [cs.SE] https://arxiv.org/abs/2303.16749
-
[4]
Zhicheng Dou, Ruihua Song, and Ji-Rong Wen. 2007. A large-scale evaluation and analysis of personalized search strategies. In Proceedings of the 16th International Conference on World Wide Web (Banff, Alberta, Canada) (WWW ’07). Association for Computing Machinery, New York, NY, USA, 581–590. doi:10.1145/1242572. 1242651
-
[5]
Andrew Fowler, Kurt Partridge, Ciprian Chelba, Xiaojun Bi, Tom Ouyang, and Shumin Zhai. 2015. Effects of Language Modeling and Its Personalization on Touchscreen Typing Performance. In Proceedings of the 33rd Annual ACM Con- ference on Human Factors in Computing Systems (Seoul, Republic of Korea) (CHI ’15). Association for Computing Machinery, New York, N...
-
[6]
Qian Guo, Wei Chen, and Huaiyu Wan. 2021. AOL4PS: A Large-scale Data Set for Personalized Search. Data Intelligence 3, 4 (10 2021), 548–567. arXiv:https://direct.mit.edu/dint/article-pdf/3/4/548/1968580/dint_a_00104.pdf doi:10.1162/dint_a_00104
-
[7]
Ari Holtzman, Jan Buys, Li Du, Maxwell Forbes, and Yejin Choi. 2020. The Curious Case of Neural Text Degeneration. InInternational Conference on Learning Representations. https://openreview.net/forum?id=rygGQyrFvH
work page 2020
-
[8]
Edward J Hu, yelong shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2022. LoRA: Low-Rank Adaptation of Large Language Models. In International Conference on Learning Representations . https: //openreview.net/forum?id=nZeVKeeFYf9
work page 2022
-
[9]
Gautier Izacard, Mathilde Caron, Lucas Hosseini, Sebastian Riedel, Piotr Bo- janowski, Armand Joulin, and Edouard Grave. 2022. Unsupervised Dense Infor- mation Retrieval with Contrastive Learning. Transactions on Machine Learning Research (2022). https://openreview.net/forum?id=jKN1pXi7b0
work page 2022
-
[10]
Joel Jang, Seungone Kim, Bill Yuchen Lin, Yizhong Wang, Jack Hessel, Luke Zettlemoyer, Hannaneh Hajishirzi, Yejin Choi, and Prithviraj Ammanabrolu
-
[11]
Personalized Soups: Personalized Large Language Model Alignment via Post-hoc Parameter Merging. arXiv:2310.11564
-
[12]
Adam: A Method for Stochastic Optimization
Diederik P. Kingma and Jimmy Ba. 2014. Adam: A Method for Stochastic Opti- mization. CoRR abs/1412.6980 (2014). https://api.semanticscholar.org/CorpusID: 6628106
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[13]
Ishita Kumar, Snigdha Viswanathan, Sushrita Yerra, Alireza Salemi, Ryan A. Rossi, Franck Dernoncourt, Hanieh Deilamsalehy, Xiang Chen, Ruiyi Zhang, Shubham Agarwal, Nedim Lipka, Chien Van Nguyen, Thien Huu Nguyen, and Hamed Zamani. 2024. LongLaMP: A Benchmark for Personalized Long-form Text Generation. arXiv:2407.11016 [cs.CL] https://arxiv.org/abs/2407.11016
-
[14]
Cheng Li, Mingyang Zhang, Qiaozhu Mei, Weize Kong, and Michael Ben- dersky. 2024. Learning to Rewrite Prompts for Personalized Text Genera- tion. In Proceedings of the ACM on Web Conference 2024 (WWW ’24) . ACM. doi:10.1145/3589334.3645408
- [15]
-
[16]
Alphaone: Reasoning models thinking slow and fast at test time
Yanyang Li, Michael R. Lyu, and Liwei Wang. 2025. Learning to Reason from Feedback at Test-Time. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar (Eds.). Association for Computational Linguistics, Vienna, Austria, ...
-
[17]
Jiongnan Liu, Zhicheng Dou, Guoyu Tang, and Sulong Xu. 2023. JDsearch: A Personalized Product Search Dataset with Real Queries and Full Interactions. In Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval (Taipei, Taiwan) (SIGIR ’23). Association for Computing Machinery, New York, NY, USA, 2945–2...
- [18]
-
[19]
Hanjia Lyu, Song Jiang, Hanqing Zeng, Yinglong Xia, Qifan Wang, Si Zhang, Ren Chen, Chris Leung, Jiajie Tang, and Jiebo Luo. 2024. LLM-Rec: Personalized Recommendation via Prompting Large Language Models. In Findings of the Asso- ciation for Computational Linguistics: NAACL 2024 , Kevin Duh, Helena Gomez, and Steven Bethard (Eds.). Association for Computa...
-
[20]
Chunyan Mao, Shuaishuai Huang, Mingxiu Sui, Haowei Yang, and Xueshe Wang
-
[21]
arXiv:2410.09923 [cs.IR] https://arxiv.org/abs/ 2410.09923
Analysis and Design of a Personalized Recommendation System Based on a Dynamic User Interest Model. arXiv:2410.09923 [cs.IR] https://arxiv.org/abs/ 2410.09923
-
[22]
Sheshera Mysore, Zhuoran Lu, Mengting Wan, Longqi Yang, Steve Menezes, Tina Baghaee, Emmanuel Barajas Gonzalez, Jennifer Neville, and Tara Safavi
-
[23]
PEARL: Personalizing Large Language Model Writing Assistants with Generation-Calibrated Retrievers. arXiv:2311.09180
-
[24]
Maxim Naumov, Dheevatsa Mudigere, Hao-Jun Michael Shi, Jianyu Huang, Narayanan Sundaraman, Jongsoo Park, Xiaodong Wang, Udit Gupta, Carole-Jean Wu, Alisson G. Azzolini, Dmytro Dzhulgakov, Andrey Mallevich, Ilia Cherni- avskii, Yinghai Lu, Raghuraman Krishnamoorthi, Ansha Yu, Volodymyr Kon- dratenko, Stephanie Pereira, Xianjie Chen, Wenlin Chen, Vijay Rao,...
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[25]
Debjit Paul, Mete Ismayilzada, Maxime Peyrard, Beatriz Borges, Antoine Bosselut, Robert West, and Boi Faltings. 2024. REFINER: Reasoning Feedback on Intermedi- ate Representations. In Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers) , Yvette Graham and Matthew Purver (Eds.)...
-
[26]
Qwen, :, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li,...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. 2023. Direct Preference Optimization: Your Language Model is Secretly a Reward Model. In Thirty-seventh Conference on Neural Infor- mation Processing Systems. https://openreview.net/forum?id=HPuSIXJaa9
work page 2023
-
[28]
Alireza Salemi, Surya Kallumadi, and Hamed Zamani. 2024. Optimization Methods for Personalizing Large Language Models through Retrieval Augmen- tation. In Proceedings of the 47th International ACM SIGIR Conference on Re- search and Development in Information Retrieval (Washington DC, USA) (SI- GIR ’24). Association for Computing Machinery, New York, NY, U...
-
[29]
Alireza Salemi, Julian Killingback, and Hamed Zamani. 2025. ExPerT: Effec- tive and Explainable Evaluation of Personalized Long-Form Text Generation. In Findings of the Association for Computational Linguistics: ACL 2025 , Wanxi- ang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar (Eds.). Association for Computational Linguistics, Vienn...
work page 2025
- [30]
-
[31]
Alireza Salemi, Sheshera Mysore, Michael Bendersky, and Hamed Zamani. 2024. LaMP: When Large Language Models Meet Personalization. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Lun-Wei Ku, Andre Martins, and Vivek Srikumar (Eds.). Association for Computational Linguistics, Bangkok, Thai...
-
[32]
Alireza Salemi and Hamed Zamani. 2025. Comparing Retrieval-Augmentation and Parameter-Efficient Fine-Tuning for Privacy-Preserving Personalization of Large Language Models. In Proceedings of the 2025 International ACM SIGIR Conference on Innovative Concepts and Theories in Information Retrieval (ICTIR) (Padua, Italy) (ICTIR ’25). Association for Computing...
-
[33]
Alireza Salemi and Hamed Zamani. 2025. LaMP-QA: A Benchmark for Personal- ized Long-form Question Answering. In Proceedings of the The 2025 Conference Learning from Natural Language Feedback for Personalized Question Answering Preprint, on Empirical Methods in Natural Language Processing (to appear) . Association for Computational Linguistics, Suzhou, China
work page 2025
-
[34]
Avi Singh, John D Co-Reyes, Rishabh Agarwal, Ankesh Anand, Piyush Patil, Xavier Garcia, Peter J Liu, James Harrison, Jaehoon Lee, Kelvin Xu, Aaron T Parisi, Abhishek Kumar, Alexander A Alemi, Alex Rizkowsky, Azade Nova, Ben Adlam, Bernd Bohnet, Gamaleldin Fathy Elsayed, Hanie Sedghi, Igor Mordatch, Isabelle Simpson, Izzeddin Gur, Jasper Snoek, Jeffrey Pen...
work page 2024
-
[35]
Ilya Sutskever, Oriol Vinyals, and Quoc V. Le. 2014. Sequence to sequence learning with neural networks. InProceedings of the 28th International Conference on Neural Information Processing Systems - Volume 2 (Montreal, Canada) (NIPS’14). MIT Press, Cambridge, MA, USA, 3104–3112
work page 2014
- [36]
-
[37]
Zhiheng Xi, Dingwen Yang, Jixuan Huang, Jiafu Tang, Guanyu Li, Yiwen Ding, Wei He, Boyang Hong, Shihan Do, Wenyu Zhan, Xiao Wang, Rui Zheng, Tao Ji, Xiaowei Shi, Yitao Zhai, Rongxiang Weng, Jingang Wang, Xunliang Cai, Tao Gui, Zuxuan Wu, Qi Zhang, Xipeng Qiu, Xuanjing Huang, and Yu-Gang Jiang. 2024. Enhancing LLM Reasoning via Critique Models with Test-Ti...
-
[38]
Yiyan Xu, Jinghao Zhang, Alireza Salemi, Xinting Hu, Wenjie Wang, Fuli Feng, Hamed Zamani, Xiangnan He, and Tat-Seng Chua. 2025. Personalized Generation In Large Model Era: A Survey. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Moham...
work page 2025
-
[39]
Gui-Rong Xue, Jie Han, Yong Yu, and Qiang Yang. 2009. User Language Model for Collaborative Personalized Search. ACM Trans. Inf. Syst. 27, 2, Article 11 (mar 2009), 28 pages. doi:10.1145/1462198.1462203
-
[40]
Wang, Wen-tau Yih, and Ziyu Yao
Hao Yan, Saurabh Srivastava, Yintao Tai, Sida I. Wang, Wen-tau Yih, and Ziyu Yao. 2023. Learning to Simulate Natural Language Feedback for Interactive Semantic Parsing. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , Anna Rogers, Jordan Boyd- Graber, and Naoaki Okazaki (Eds.). Associatio...
-
[41]
Chengrun Yang, Xuezhi Wang, Yifeng Lu, Hanxiao Liu, Quoc V Le, Denny Zhou, and Xinyun Chen. 2024. Large Language Models as Optimizers. In The Twelfth International Conference on Learning Representations . https://openreview.net/ forum?id=Bb4VGOWELI
work page 2024
-
[42]
Mert Yuksekgonul, Federico Bianchi, Joseph Boen, Sheng Liu, Pan Lu, Zhi Huang, Carlos Guestrin, and James Zou. 2025. Optimizing generative AI by backpropa- gating language model feedback. Nature 639 (2025), 609–616
work page 2025
-
[43]
Kai Zhang, Yangyang Kang, Fubang Zhao, and Xiaozhong Liu. 2024. LLM- based Medical Assistant Personalization with Short- and Long-Term Memory Coordination. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), Kevin Duh, Helena Gomez, and S...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.