Online Learning with Multiple Fairness Regularizers via Graph-Structured Feedback
Pith reviewed 2026-05-25 08:24 UTC · model grok-4.3
The pith
Graph-structured feedback enables bandit algorithms to adaptively learn time-varying weights for multiple competing fairness objectives.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In the bandit setting with graph-structured feedback, the authors develop an algorithm that learns the appropriate weights for multiple fairness regularizers adaptively through sequential interactions, allowing the system to respond to changes in fairness priorities without prior specification of those weights.
What carries the argument
Graph-structured feedback that supplies information from decisions sufficient to track and adapt to time-varying fairness weights.
If this is right
- Competing fairness objectives can be enforced online without fixing their relative weights in advance.
- The system adapts automatically when fairness priorities shift over time.
- No separate data or strong functional assumptions are required beyond the graph feedback itself.
- The approach extends standard bandit regret analysis to include multiple regularizers whose weights are learned on the fly.
Where Pith is reading between the lines
- Similar graph feedback could be used to adapt weights in other multi-objective online problems such as resource allocation.
- Real-world deployments could test the method by monitoring whether fairness violations decrease after the algorithm has observed enough graph feedback.
- The technique suggests a route to dynamic fairness constraints in recommendation or pricing systems where user preferences evolve.
Load-bearing premise
The graph feedback supplies enough information for the algorithm to learn changing fairness weights without side information or strong assumptions on rewards and fairness functions.
What would settle it
A setting in which the graph feedback leaves multiple fairness weight vectors indistinguishable, so that the algorithm cannot correctly adapt when the true weights change.
Figures

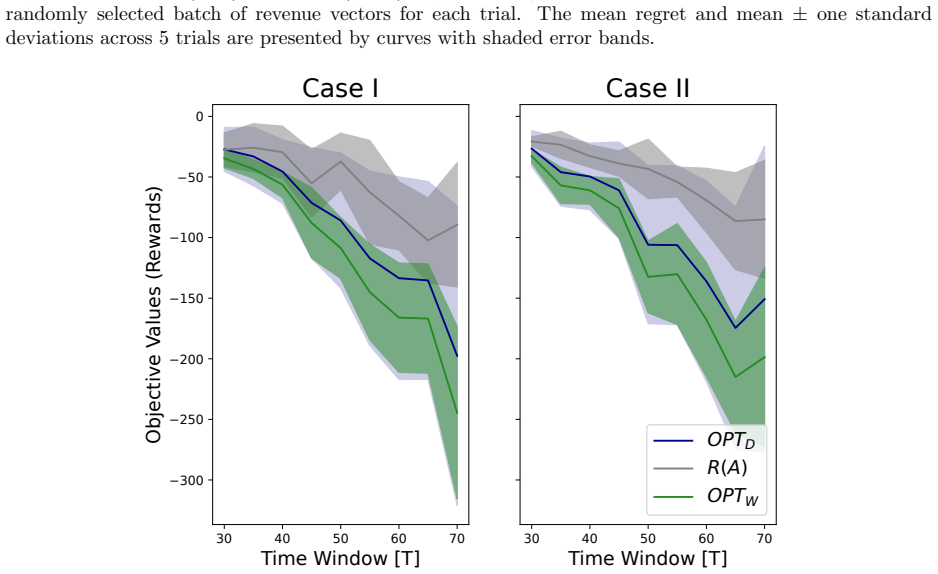
read the original abstract
There is an increasing need to enforce multiple, often competing, measures of fairness within automated decision systems. The appropriate weighting of these fairness objectives is typically unknown a priori, may change over time and, in our setting, must be learned adaptively through sequential interactions. In this work, we address this challenge in a bandit setting, where decisions are made with graph-structured feedback.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims to solve the problem of adaptively learning time-varying weights for multiple competing fairness regularizers in an online bandit setting, where decisions receive graph-structured feedback that is presumed sufficient to track the weights without additional side information or strong functional assumptions on rewards or fairness functions.
Significance. The topic of adaptive multi-fairness in sequential decision-making is relevant to fair ML. If the approach delivered parameter-free regret bounds, reproducible code, or falsifiable predictions under the stated minimal assumptions, it would be a meaningful contribution. As presented, however, no such results, derivations, or validation are visible, so significance cannot be evaluated.
major comments (2)
- [Abstract] Abstract: the central claim that graph-structured feedback alone enables adaptive learning of time-varying fairness weights is stated at a high level but supplies no derivations, regret bounds, algorithm description, or empirical validation, preventing assessment of internal consistency or support.
- [Abstract] Abstract (weakest assumption): the claim relies on the unstated premise that the graph encodes sufficient observable information about each fairness violation and that weight changes occur at a rate compatible with feedback delay; no observability model or variation-rate bound is provided to substantiate this.
Simulated Author's Rebuttal
We thank the referee for the comments. The abstract provides a high-level summary as is conventional; the full manuscript contains the algorithm, regret analysis, and formal assumptions. We address each point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that graph-structured feedback alone enables adaptive learning of time-varying fairness weights is stated at a high level but supplies no derivations, regret bounds, algorithm description, or empirical validation, preventing assessment of internal consistency or support.
Authors: Abstracts are concise overviews by design. The manuscript details the algorithm in Section 3, presents the regret bound (Theorem 4.1, O(sqrt(T log K)) under graph feedback) with full derivation in Appendix A, and includes empirical validation in Section 6. These elements support the claim; we can add a one-sentence pointer to the regret result in the abstract for clarity. revision: partial
-
Referee: [Abstract] Abstract (weakest assumption): the claim relies on the unstated premise that the graph encodes sufficient observable information about each fairness violation and that weight changes occur at a rate compatible with feedback delay; no observability model or variation-rate bound is provided to substantiate this.
Authors: Section 2.2 defines the graph feedback model, specifying that each fairness violation is observable via the graph edges without side information. Assumption 2.3 explicitly bounds the total variation of the weight vector to be o(T), ensuring compatibility with feedback delay. These are stated in the main text; if the presentation is unclear we can expand the abstract to reference the assumption. revision: no
Circularity Check
No significant circularity; no derivations or equations available for inspection
full rationale
The provided manuscript text contains only the abstract and high-level claims about a bandit algorithm with graph-structured feedback for adaptive fairness weights. No equations, algorithmic pseudocode, derivation steps, or self-citations are visible in the given content. The reader's note explicitly states that no equations or derivations are visible, preventing any evaluation of load-bearing reductions to inputs by construction. In the absence of mathematical structure, the central claim cannot be shown to reduce circularly, and the result is treated as self-contained pending full text inspection.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Optimal algorithms for online convex optimization with multi-point bandit feedback
Alekh Agarwal, Ofer Dekel, and Lin Xiao. Optimal algorithms for online convex optimization with multi-point bandit feedback. In COLT, pages 28–40. Citeseer, 2010
work page 2010
-
[2]
Online learning with feedback graphs: Beyond bandits
Noga Alon, Nicolo Cesa-Bianchi, Ofer Dekel, and Tomer Koren. Online learning with feedback graphs: Beyond bandits. In Conference on Learning Theory, pages 23–35. PMLR, 2015
work page 2015
-
[3]
Nonstochastic multi-armed bandits with graph-structured feedback
Noga Alon, Nicolo Cesa-Bianchi, Claudio Gentile, Shie Mannor, Yishay Mansour, and Ohad Shamir. Nonstochastic multi-armed bandits with graph-structured feedback. SIAM Journal on Computing , 46(6):1785–1826, 2017
work page 2017
-
[4]
From bandits to experts: A tale of domination and independence
Noga Alon, Nicol` o Cesa-Bianchi, Claudio Gentile, and Yishay Mansour. From bandits to experts: A tale of domination and independence. Advances in Neural Information Processing Systems , 26:1610–1618, 2013
work page 2013
-
[5]
Bandits with feedback graphs and switching costs
Raman Arora, Teodor Vanislavov Marinov, and Mehryar Mohri. Bandits with feedback graphs and switching costs. In H. Wallach, H. Larochelle, A. Beygelzimer, F. d 'Alch´ e-Buc, E. Fox, and R. Garnett, editors, Advances in Neural Information Processing Systems , volume 32. Curran Associates, Inc., 2019
work page 2019
-
[6]
Minimax policies for adversarial and stochastic bandits
Jean-Yves Audibert, S´ ebastien Bubeck, et al. Minimax policies for adversarial and stochastic bandits. In COLT, volume 7, pages 1–122, 2009
work page 2009
-
[7]
Beyond individual and group fairness
Pranjal Awasthi, Corinna Cortes, Yishay Mansour, and Mehryar Mohri. Beyond individual and group fairness. arXiv preprint arXiv:2008.09490 , 2020
-
[8]
Individually fair learning with one-sided feedback
Yahav Bechavod and Aaron Roth. Individually fair learning with one-sided feedback. In International Conference on Machine Learning, pages 1954–1977. PMLR, 2023
work page 1954
-
[9]
Bandit convex optimization:\sqrtt regret in one dimension
S´ ebastien Bubeck, Ofer Dekel, Tomer Koren, and Yuval Peres. Bandit convex optimization:\sqrtt regret in one dimension. In Conference on Learning Theory, pages 266–278. PMLR, 2015
work page 2015
-
[10]
Stochastic bandits with side observations on networks
Swapna Buccapatnam, Atilla Eryilmaz, and Ness B Shroff. Stochastic bandits with side observations on networks. In The 2014 ACM international conference on Measurement and modeling of computer systems, pages 289–300, 2014
work page 2014
-
[11]
An experimental study of the relationship between online engagement and advertising effectiveness
Bobby J Calder, Edward C Malthouse, and Ute Schaedel. An experimental study of the relationship between online engagement and advertising effectiveness. Journal of interactive marketing , 23(4):321– 331, 2009
work page 2009
-
[12]
Leveraging side observations in stochastic bandits
Stephane Caron, Branislav Kveton, Marc Lelarge, and S Bhagat. Leveraging side observations in stochastic bandits. In UAI, 2012
work page 2012
-
[13]
Revealing graph bandits for maximizing local influence
Alexandra Carpentier and Michal Valko. Revealing graph bandits for maximizing local influence. In Artificial Intelligence and Statistics , pages 10–18. PMLR, 2016
work page 2016
-
[14]
Prediction, learning, and games
Nicolo Cesa-Bianchi and G´ abor Lugosi. Prediction, learning, and games . Cambridge university press, 2006
work page 2006
-
[15]
Understanding bandits with graph feedback
Houshuang Chen, Zengfeng Huang, Shuai Li, and Chihao Zhang. Understanding bandits with graph feedback. arXiv preprint arXiv:2105.14260 , 2021
-
[16]
Online learning with feedback graphs without the graphs
Alon Cohen, Tamir Hazan, and Tomer Koren. Online learning with feedback graphs without the graphs. In International Conference on Machine Learning , pages 811–819. PMLR, 2016
work page 2016
-
[17]
Online learning with dependent stochastic feedback graphs
Corinna Cortes, Giulia DeSalvo, Claudio Gentile, Mehryar Mohri, and Ningshan Zhang. Online learning with dependent stochastic feedback graphs. In International Conference on Machine Learning , pages 2154–2163. PMLR, 2020. 10
work page 2020
-
[18]
Fairness is not static: deeper understanding of long term fairness via simulation studies
Alexander D’Amour, Hansa Srinivasan, James Atwood, Pallavi Baljekar, David Sculley, and Yoni Halpern. Fairness is not static: deeper understanding of long term fairness via simulation studies. In Proceedings of the 2020 Conference on Fairness, Accountability, and Transparency , pages 525–534, 2020
work page 2020
-
[19]
Umut Dur, Parag A Pathak, and Tayfun S¨ onmez. Explicit vs. statistical targeting in affirmative action: Theory and evidence from chicago’s exam schools. Journal of Economic Theory , 187:104996, 2020
work page 2020
-
[20]
Cynthia Dwork, Moritz Hardt, Toniann Pitassi, Omer Reingold, and Richard S Zemel. Fairness through awareness. corr abs/1104.3913 (2011). arXiv preprint arXiv:1104.3913 , 2011
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[21]
A decision-theoretic generalization of on-line learning and an application to boosting
Yoav Freund and Robert E Schapire. A decision-theoretic generalization of on-line learning and an application to boosting. Journal of computer and system sciences , 55(1):119–139, 1997
work page 1997
-
[22]
Equality of Opportunity in Supervised Learning
Moritz Hardt, Eric Price, and Nathan Srebro. Equality of opportunity in supervised learning. arXiv preprint arXiv:1610.02413, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[23]
Introduction to online convex optimization
Elad Hazan. Introduction to online convex optimization. Foundations and Trends in Optimization , 2(3-4):157–325, 2016
work page 2016
-
[24]
An optimal algorithm for bandit convex optimization
Elad Hazan and Yuanzhi Li. An optimal algorithm for bandit convex optimization. arXiv preprint arXiv:1603.04350, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[25]
Miikka Hiltunen. Online political advertising and disinformation during elections: Regulatory framework in the eu and member states. Helsinki Legal Studies Research Paper, (68), 2021
work page 2021
-
[26]
Problem-dependent regret bounds for online learning with feedback graphs
Bingshan Hu, Nishant A Mehta, and Jianping Pan. Problem-dependent regret bounds for online learning with feedback graphs. In Uncertainty in Artificial Intelligence , pages 852–861. PMLR, 2020
work page 2020
-
[27]
An optimal algorithm for bandit convex optimization with strongly-convex and smooth loss
Shinji Ito. An optimal algorithm for bandit convex optimization with strongly-convex and smooth loss. In International Conference on Artificial Intelligence and Statistics , pages 2229–2239. PMLR, 2020
work page 2020
-
[28]
Fairness in reinforcement learning
Shahin Jabbari, Matthew Joseph, Michael Kearns, Jamie Morgenstern, and Aaron Roth. Fairness in reinforcement learning. In International conference on machine learning, pages 1617–1626. PMLR, 2017
work page 2017
-
[29]
Rules for fair digital campaigning
Julian Jaursch. Rules for fair digital campaigning. Stiftung NV, 2020
work page 2020
-
[30]
Efficient algorithms for online decision problems
Adam Kalai and Santosh Vempala. Efficient algorithms for online decision problems. Journal of Com- puter and System Sciences , 71(3):291–307, 2005
work page 2005
-
[31]
Fact: A diagnostic for group fairness trade-offs
Joon Sik Kim, Jiahao Chen, and Ameet Talwalkar. Fact: A diagnostic for group fairness trade-offs. In International Conference on Machine Learning , pages 5264–5274. PMLR, 2020
work page 2020
-
[32]
Nearly tight bounds for the continuum-armed bandit problem
Robert Kleinberg. Nearly tight bounds for the continuum-armed bandit problem. Advances in Neural Information Processing Systems, 17:697–704, 2004
work page 2004
-
[33]
Online learning with noisy side observations
Tom´ aˇ s Koc´ ak, Gergely Neu, and Michal Valko. Online learning with noisy side observations. InArtificial Intelligence and Statistics , pages 1186–1194. PMLR, 2016
work page 2016
-
[34]
Efficient learning by implicit exploration in bandit problems with side observations
Tom´ aˇ s Koc´ ak, Gergely Neu, Michal Valko, and R´ emi Munos. Efficient learning by implicit exploration in bandit problems with side observations. In Proceedings of the 27th International Conference on Neural Information Processing Systems-Volume 1, pages 613–621, 2014
work page 2014
-
[35]
Robert S Koppel. The applicability of the equal time doctrine and the reasonable access rule to elections in the new media era. Harv. J. on Legis. , 20:499, 1983
work page 1983
-
[36]
Matt J Kusner, Joshua R Loftus, Chris Russell, and Ricardo Silva. Counterfactual fairness. arXiv preprint arXiv:1703.06856, 2017. 11
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[37]
Optimal dynamic portfolio selection: Multiperiod mean-variance formula- tion
Duan Li and Wan-Lung Ng. Optimal dynamic portfolio selection: Multiperiod mean-variance formula- tion. Mathematical Finance, 10(3):387–406, 2000
work page 2000
-
[38]
Stochastic online learning with probabilistic graph feedback
Shuai Li, Wei Chen, Zheng Wen, and Kwong-Sak Leung. Stochastic online learning with probabilistic graph feedback. Proceedings of the AAAI Conference on Artificial Intelligence , 34(04):4675–4682, Apr. 2020
work page 2020
-
[39]
Information directed sampling for stochastic bandits with graph feedback
Fang Liu, Swapna Buccapatnam, and Ness Shroff. Information directed sampling for stochastic bandits with graph feedback. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 32, 2018
work page 2018
-
[40]
Analysis of Thompson Sampling for Graphical Bandits Without the Graphs
Fang Liu, Zizhan Zheng, and Ness Shroff. Analysis of thompson sampling for graphical bandits without the graphs. arXiv preprint arXiv:1805.08930 , 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[41]
Delayed impact of fair machine learning
Lydia T Liu, Sarah Dean, Esther Rolf, Max Simchowitz, and Moritz Hardt. Delayed impact of fair machine learning. In International Conference on Machine Learning , pages 3150–3158. PMLR, 2018
work page 2018
-
[42]
Bias mitigation post-processing for individual and group fairness
Pranay K Lohia, Karthikeyan Natesan Ramamurthy, Manish Bhide, Diptikalyan Saha, Kush R Varsh- ney, and Ruchir Puri. Bias mitigation post-processing for individual and group fairness. In Icassp 2019-2019 ieee international conference on acoustics, speech and signal processing (icassp), pages 2847–
work page 2019
-
[43]
Dual mirror descent for online allocation problems
Haihao Lu, Santiago Balseiro, and Vahab Mirrokni. Dual mirror descent for online allocation problems. arXiv preprint arXiv:2002.10421 , 2020
-
[44]
Stochastic graphical bandits with adversarial corruptions
Shiyin Lu, Guanghui Wang, and Lijun Zhang. Stochastic graphical bandits with adversarial corruptions. In Proceedings of the AAAI Conference on Artificial Intelligence , volume 35, pages 8749–8757, 2021
work page 2021
-
[45]
Feedback graph regret bounds for thompson sampling and ucb
Thodoris Lykouris, ´Eva Tardos, and Drishti Wali. Feedback graph regret bounds for thompson sampling and ucb. In Algorithmic Learning Theory, pages 592–614. PMLR, 2020
work page 2020
-
[46]
An ‘equal time’ rule for social media
Mark MacCarthy. An ‘equal time’ rule for social media. Forbes, 2020. January 21st
work page 2020
-
[47]
From bandits to experts: On the value of side-observations
Shie Mannor and Ohad Shamir. From bandits to experts: On the value of side-observations. Advances in Neural Information Processing Systems , 24:684–692, 2011
work page 2011
-
[48]
How trump conquered facebook—without russian ads
Antonio Garcia Martinez. How trump conquered facebook—without russian ads. Wired, 2018. February 23rd
work page 2018
-
[49]
P. Miller. Media Law for Producers. Taylor & Francis, 2013
work page 2013
-
[50]
Time-varying optimization of networked systems with human preferences
Ana M Ospina, Andrea Simonetto, and Emiliano Dall’Anese. Time-varying optimization of networked systems with human preferences. arXiv preprint arXiv:2103.13470 , 2021
-
[51]
Perceived fairness and consequences of affirmative action policies
Hannah Schildberg-H¨ orisch, Chi Trieu, and Jana Willrodt. Perceived fairness and consequences of affirmative action policies. 2020
work page 2020
-
[52]
Online learning and online convex optimization
Shai Shalev-Shwartz et al. Online learning and online convex optimization. Foundations and trends in Machine Learning, 4(2):107–194, 2011
work page 2011
-
[53]
Xiao-Ling Sun, KIM McKinnon, and Duan Li. A convexification method for a class of global optimization problems with applications to reliability optimization. Journal of Global Optimization , 21(2):185–199, 2001
work page 2001
-
[54]
Thompson sampling for stochastic bandits with graph feedback
Aristide CY Tossou, Christos Dimitrakakis, and Devdatt Dubhashi. Thompson sampling for stochastic bandits with graph feedback. In Thirty-First AAAI Conference on Artificial Intelligence , 2017
work page 2017
-
[55]
Norman C Wang. Diversity, inclusion, and equity: evolution of race and ethnicity considerations for the cardiology workforce in the united states of america from 1969 to 2019. Journal of the American Heart Association, 9(7):e015959, 2020. 12
work page 1969
-
[56]
Algorithms for fairness in sequential decision making
Min Wen, Osbert Bastani, and Ufuk Topcu. Algorithms for fairness in sequential decision making. In International Conference on Artificial Intelligence and Statistics , pages 1144–1152. PMLR, 2021
work page 2021
-
[57]
Solving dynamic multi-objective problems with a new prediction-based optimization algorithm
Qingyang Zhang, Shouyong Jiang, Shengxiang Yang, and Hui Song. Solving dynamic multi-objective problems with a new prediction-based optimization algorithm. Plos one, 16(8):e0254839, 2021
work page 2021
-
[58]
Fairness in learning-based sequential decision algorithms: A survey
Xueru Zhang and Mingyan Liu. Fairness in learning-based sequential decision algorithms: A survey. In Handbook of Reinforcement Learning and Control, pages 525–555. Springer, 2021
work page 2021
-
[59]
Martin Zinkevich. Online convex programming and generalized infinitesimal gradient ascent. In Pro- ceedings of the 20th international conference on machine learning (icml-03) , pages 928–936, 2003. 8 Appendix 8.1 Related Work There are many measures of fairness for any single subgroup and many protected attributes (e.g., gender, race, ethnicity, income) d...
work page 2003
-
[60]
similar individuals should be treated similarly
require the predictor to be unrelated to protected attributes. In other words, they can be seen as the revised version of unawareness that gets rid of the effects of those unobserved features related to protected attributes. They focus more on accurate prediction of the unbalanced distribution without discrimination. It believes that a predictor is very u...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.