LEAF: Knowledge Distillation of Text Embedding Models with Teacher-Aligned Representations
Pith reviewed 2026-05-18 17:08 UTC · model grok-4.3
The pith
Distilling text embeddings while aligning them to the teacher enables small models to pair with large ones for better retrieval.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
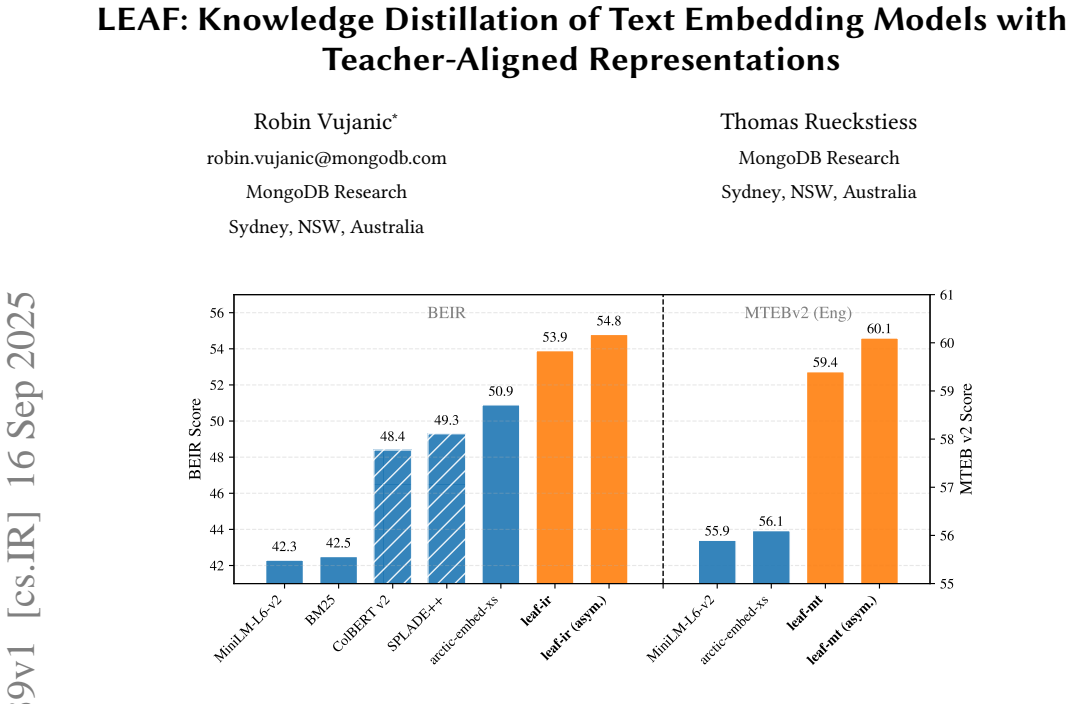
LEAF is a distillation framework for text embedding models that creates student models whose representations are aligned with those of the teacher model. This alignment permits asymmetric information retrieval architectures in which the teacher encodes documents and the student encodes queries. The resulting leaf-ir model, with 23 million parameters, establishes a new state of the art on the BEIR benchmark among models of similar size, with performance increasing when operated in the asymmetric mode. The same framework applied to multi-task learning yields leaf-mt, which leads the MTEB leaderboard in its size category.
What carries the argument
Teacher-aligned representations produced by the LEAF distillation process, which maintain compatibility between teacher and student embeddings to enable mixed-scale retrieval without performance loss.
Load-bearing premise
The premise that aligning a small model to a large teacher's outputs will let the small model work well for queries while the large one handles documents.
What would settle it
A direct comparison on the BEIR benchmark showing that the asymmetric setup with the teacher encoding documents and the leaf model encoding queries yields no improvement or lower scores than using the leaf model alone.
Figures












read the original abstract
We present LEAF ("Lightweight Embedding Alignment Framework"), a knowledge distillation framework for text embedding models. A key distinguishing feature is that our distilled leaf models are aligned to their teacher. In the context of information retrieval, this allows for flexible asymmetric architectures where documents are encoded with the larger teacher model, while queries can be served with the smaller leaf models. We also show that leaf models automatically inherit MRL and robustness to output quantization whenever these properties are present in the teacher model, without explicitly training for them. To demonstrate the capability of our framework we publish leaf-ir, a 23M parameters information retrieval oriented text embedding model trained using LEAF, which sets a new state-of-the-art (SOTA) on BEIR, ranking #1 on the public leaderboard for this benchmark and for models of its size. When run in asymmetric mode, its retrieval performance is further increased. Our scheme is however not restricted to the information retrieval setting, and we demonstrate its wider applicability by synthesizing the multi-task leaf-mt model. This also sets a new SOTA, ranking #1 on the public MTEB v2 (English) leaderboard for its size. LEAF is applicable to black-box models and in contrast to other embedding model training frameworks, it does not require judgments nor hard negatives, and training can be conducted using small batch sizes. Thus, dataset and training infrastructure requirements for our framework are modest. We make our models publicly available under a permissive Apache 2.0 license.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LEAF, a knowledge distillation framework for text embedding models in which student ('leaf') models are aligned to teacher representations. This alignment is presented as enabling flexible asymmetric retrieval architectures, with documents encoded by the larger teacher and queries served by the smaller leaf model. The authors release leaf-ir (23M parameters), claiming new state-of-the-art results on the BEIR benchmark (ranking #1 for its size class) with further gains when run asymmetrically; a multi-task variant leaf-mt is also claimed to set a new SOTA on MTEB v2 English for its size. The framework is described as requiring neither judgments nor hard negatives, operating with small batch sizes, and automatically inheriting properties such as Matryoshka Representation Learning and quantization robustness from the teacher when present.
Significance. If the empirical claims are substantiated with detailed experiments, LEAF could represent a practical advance for efficient deployment of embedding models in information retrieval by lowering data and compute requirements while supporting asymmetric teacher-student combinations. The automatic inheritance of advanced properties without explicit training would be a notable strength for real-world use cases.
major comments (2)
- [Abstract] Abstract: The claim that asymmetric mode (teacher-encoded documents scored against leaf-encoded queries) further increases retrieval performance without task-specific fine-tuning or additional negative mining is load-bearing for the central advantage of 'flexible asymmetric architectures'. This rests on the unverified assumption that a standard representation-matching distillation objective applied to the same inputs will preserve ranking quality under cosine or dot-product scoring, despite potential stylistic and length mismatches between queries and documents; no analysis or experiments addressing this transfer are provided.
- [Abstract] Abstract: The SOTA claims for leaf-ir on BEIR and leaf-mt on MTEB v2 rest on external public leaderboards rather than quantities defined by fitted parameters or internal controls inside the paper. No ablation studies, statistical significance tests, or experimental details (e.g., exact distillation loss weights, temperature, batch size schedule, or teacher model) are supplied, preventing assessment of whether the 23M-parameter results are robust or confounded by external factors.
minor comments (2)
- The abstract and method description would benefit from explicit notation for the distillation objective and how teacher alignment is enforced (e.g., loss form and any hyperparameters).
- Consider adding a table comparing leaf-ir against other models of similar parameter count on BEIR subsets to make the leaderboard claim more self-contained.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback on our manuscript. We address each major comment below and indicate where we will revise the paper to strengthen the presentation of our results and claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that asymmetric mode (teacher-encoded documents scored against leaf-encoded queries) further increases retrieval performance without task-specific fine-tuning or additional negative mining is load-bearing for the central advantage of 'flexible asymmetric architectures'. This rests on the unverified assumption that a standard representation-matching distillation objective applied to the same inputs will preserve ranking quality under cosine or dot-product scoring, despite potential stylistic and length mismatches between queries and documents; no analysis or experiments addressing this transfer are provided.
Authors: We thank the referee for this important point. The asymmetric mode is indeed central to the practical value of teacher-aligned representations. Our manuscript reports empirical improvements when using the leaf model for queries against teacher-encoded documents on BEIR. To directly address concerns about stylistic and length mismatches and the preservation of ranking quality, we will add a dedicated analysis subsection in the revised manuscript. This will include quantitative comparisons of query versus document representation properties and additional experiments breaking down performance by query length and domain. We believe these additions will substantiate the transfer under the distillation objective. revision: yes
-
Referee: [Abstract] Abstract: The SOTA claims for leaf-ir on BEIR and leaf-mt on MTEB v2 rest on external public leaderboards rather than quantities defined by fitted parameters or internal controls inside the paper. No ablation studies, statistical significance tests, or experimental details (e.g., exact distillation loss weights, temperature, batch size schedule, or teacher model) are supplied, preventing assessment of whether the 23M-parameter results are robust or confounded by external factors.
Authors: We appreciate the referee highlighting the need for greater experimental transparency. Public leaderboards are the established evaluation standard for BEIR and MTEB to enable reproducible comparisons across models. Our current manuscript includes core training details and the general framework; however, we agree that additional internal controls would strengthen the work. In the revision we will expand the experimental section and appendix with ablation studies on key hyperparameters (including loss weights, temperature, and batch size), statistical significance testing on the reported metrics, and explicit specification of the teacher model and full training schedule. These additions will allow readers to better assess robustness. revision: yes
Circularity Check
No circularity detected in LEAF framework or empirical claims
full rationale
The paper introduces the LEAF distillation framework that aligns student embeddings to a teacher model on the same inputs, enabling asymmetric query-document scoring as an empirical consequence rather than a definitional tautology. SOTA results on BEIR and MTEB are reported via external public leaderboards using standard retrieval metrics, with no evidence that any performance quantity is fitted internally and then renamed as a prediction. No equations, self-citations, or uniqueness theorems are invoked in a load-bearing way that reduces the central claims to the paper's own inputs by construction. The method is presented as self-contained with explicit statements on modest data and infrastructure needs, making the derivation chain independent and externally falsifiable.
Axiom & Free-Parameter Ledger
free parameters (2)
- distillation loss weights and temperature
- batch size and learning rate schedule
axioms (1)
- domain assumption The teacher model produces high-quality representations worth distilling
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose LEAF, a knowledge distillation framework that produces text embedding models that are aligned to their teacher... L_i = ||e_i||_2
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
leaf models automatically inherit MRL and robustness to output quantization
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
- [1]
-
[2]
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. 2020. A simple framework for contrastive learning of visual representations. InPro- ceedings of the 37th International Conference on Machine Learning (ICML’20). JMLR.org, Article 149, 11 pages
work page 2020
-
[3]
Xuanang Chen, Ben He, Kai Hui, Le Sun, and Yingfei Sun. 2021. Simplified TinyBERT: Knowledge Distillation for Document Retrieval. InAdvances in In- formation Retrieval: 43rd European Conference on IR Research, ECIR 2021, Virtual Event, March 28 – April 1, 2021, Proceedings, Part II. Springer-Verlag, Berlin, Heidelberg, 241–248. doi:10.1007/978-3-030-72240-1_21
-
[4]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers). 4171–4186
work page 2019
-
[5]
Kenneth Enevoldsen, Isaac Chung, Imene Kerboua, Márton Kardos, Ashwin Mathur, David Stap, Jay Gala, Wissam Siblini, Dominik Krzemiński, Genta Indra Winata, Saba Sturua, Saiteja Utpala, Mathieu Ciancone, Marion Schaeffer, Gabriel Sequeira, Diganta Misra, Shreeya Dhakal, Jonathan Rystrøm, Roman Solomatin, Ömer Çağatan, Akash Kundu, Martin Bernstorff, Shitao...
-
[6]
Hugging Face. 2023. DistilBERT. https://github.com/huggingface/transformers- research-projects/blob/362a490dc36e91359fe76a7a707dc29e663196b2/ distillation/distiller.py#L434 Accessed: 2025-05-22
work page 2023
-
[7]
2021.SPLADE: Sparse Lexical and Expansion Model for First Stage Ranking
Thibault Formal, Benjamin Piwowarski, and Stéphane Clinchant. 2021.SPLADE: Sparse Lexical and Expansion Model for First Stage Ranking. Association for Computing Machinery, New York, NY, USA, 2288–2292. https://doi.org/10.1145/ 3404835.3463098
- [8]
-
[9]
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. 2015. Distilling the knowledge in a neural network.arXiv preprint arXiv:1503.02531(2015)
work page internal anchor Pith review Pith/arXiv arXiv 2015
- [10]
-
[11]
Sebastian Hofstätter, Markus Zlabinger, and Allan Hanbury. 2020. Interpretable & time-budget-constrained contextualization for re-ranking. InECAI 2020. IOS Press, 513–520
work page 2020
-
[12]
Gautier Izacard and Edouard Grave. 2021. Distilling Knowledge from Reader to Retriever for Question Answering. InInternational Conference on Learning Representations. https://openreview.net/forum?id=NTEz-6wysdb
work page 2021
-
[13]
Xiaoqi Jiao, Yichun Yin, Lifeng Shang, Xin Jiang, Xiao Chen, Linlin Li, Fang Wang, and Qun Liu. 2020. TinyBERT: Distilling BERT for Natural Language Un- derstanding. InFindings of the Association for Computational Linguistics: EMNLP 2020, Trevor Cohn, Yulan He, and Yang Liu (Eds.). Association for Computational Linguistics, Online, 4163–4174. doi:10.18653...
-
[14]
Qiao Jin, Bhuwan Dhingra, Zhengping Liu, William Cohen, and Xinghua Lu
-
[15]
PubMedQA: A Dataset for Biomedical Research Question Answering. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Pro- cessing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2567–2577
work page 2019
-
[16]
Mandar Joshi, Eunsol Choi, Daniel Weld, and Luke Zettlemoyer. 2017. triviaqa: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehen- sion.arXiv e-prints, Article arXiv:1705.03551 (2017), arXiv:1705.03551 pages. arXiv:1705.03551
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[17]
Kaggle. 2023. Dataset containing 479k English words. doi:10.34740/KAGGLE/ DS/4075094
-
[18]
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. 2020. Scaling laws for neural language models.arXiv preprint arXiv:2001.08361(2020)
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[19]
Aditya Kusupati, Gantavya Bhatt, Aniket Rege, Matthew Wallingford, Aditya Sinha, Vivek Ramanujan, William Howard-Snyder, Kaifeng Chen, Sham Kakade, Prateek Jain, and Ali Farhadi. 2022. Matryoshka Representation Learning. In Advances in Neural Information Processing Systems, S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh (Eds.), Vol. 35....
work page 2022
- [20]
-
[21]
Wenhao Lu, Jian Jiao, and Ruofei Zhang. 2020. Twinbert: Distilling knowledge to twin-structured compressed bert models for large-scale retrieval. InProceedings of the 29th ACM International Conference on Information & Knowledge Management. 2645–2652
work page 2020
- [22]
-
[23]
Niklas Muennighoff, Hongjin SU, Liang Wang, Nan Yang, Furu Wei, Tao Yu, Amanpreet Singh, and Douwe Kiela. 2025. Generative Representational Instruc- tion Tuning. InThe Thirteenth International Conference on Learning Representa- tions. https://openreview.net/forum?id=BC4lIvfSzv
work page 2025
-
[24]
Arvind Neelakantan, Tao Xu, Raul Puri, Alec Radford, Jesse Michael Han, Jerry Tworek, Qiming Yuan, Nikolas Tezak, Jong Wook Kim, Chris Hallacy, Johannes Heidecke, Pranav Shyam, Boris Power, Tyna Eloundou Nekoul, Girish Sastry, Gretchen Krueger, David Schnurr, Felipe Petroski Such, Kenny Hsu, Madeleine Thompson, Tabarak Khan, Toki Sherbakov, Joanne Jang, P...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[25]
Tri Nguyen, Mir Rosenberg, Xia Song, Jianfeng Gao, Saurabh Tiwary, Rangan Majumder, and Li Deng. 2016. MS MARCO: A Human Generated MAchine Reading COmprehension Dataset.CoRRabs/1611.09268 (2016). arXiv:1611.09268 http://arxiv.org/abs/1611.09268
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[26]
Jakob Nielsen. 1994.Usability engineering. Morgan Kaufmann
work page 1994
-
[27]
Guilherme Penedo, Hynek Kydlíček, Loubna Ben allal, Anton Lozhkov, Margaret Mitchell, Colin Raffel, Leandro Von Werra, and Thomas Wolf. 2024. The FineWeb Datasets: Decanting the Web for the Finest Text Data at Scale. InThe Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track. https://openreview.net/forum?id=n6SCkn2QaG
work page 2024
-
[28]
Nils Reimers and Iryna Gurevych. 2019. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. InProceedings of the 2019 Conference on Em- pirical Methods in Natural Language Processing. Association for Computational Linguistics. https://arxiv.org/abs/1908.10084
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[29]
Nils Reimers and Iryna Gurevych. 2020. Making Monolingual Sentence Em- beddings Multilingual using Knowledge Distillation. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Bonnie Webber, Trevor Cohn, Yulan He, and Yang Liu (Eds.). Association for Computa- tional Linguistics, Online, 4512–4525. doi:10.18653/...
-
[30]
Ruiyang Ren, Yingqi Qu, Jing Liu, Wayne Xin Zhao, QiaoQiao She, Hua Wu, Haifeng Wang, and Ji-Rong Wen. 2021. RocketQAv2: A Joint Training Method for Dense Passage Retrieval and Passage Re-ranking. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Marie-Francine Moens, Xuanjing Huang, Lucia Specia, and Scott Wen-tau ...
-
[31]
Victor Sanh, Lysandre Debut, Julien Chaumond, and Thomas Wolf. 2020. DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter. arXiv:1910.01108 [cs.CL] https://arxiv.org/abs/1910.01108
work page internal anchor Pith review Pith/arXiv arXiv 2020
- [32]
-
[33]
Ferdinand Schlatt, Tim Hagen, Martin Potthast, and Matthias Hagen. 2025. TITE: Token-Independent Text Encoder for Information Retrieval. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Infor- mation Retrieval(Padua, Italy)(SIGIR ’25). Association for Computing Machinery, New York, NY, USA, 2493–2503. doi:10.1145...
-
[34]
Jacob Mitchell Springer, Suhas Kotha, Daniel Fried, Graham Neubig, and Aditi Raghunathan. 2025. Repetition Improves Language Model Embeddings. In The Thirteenth International Conference on Learning Representations. https: //openreview.net/forum?id=Ahlrf2HGJR
work page 2025
-
[35]
Smith, Luke Zettlemoyer, and Tao Yu
Hongjin Su, Weijia Shi, Jungo Kasai, Yizhong Wang, Yushi Hu, Mari Ostendorf, Wen-tau Yih, Noah A. Smith, Luke Zettlemoyer, and Tao Yu. 2023. One Embedder, Any Task: Instruction-Finetuned Text Embeddings. InFindings of the Association for Computational Linguistics: ACL 2023, Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki (Eds.). Association for Comput...
- [36]
-
[37]
Nandan Thakur, Nils Reimers, Andreas Rücklé, Abhishek Srivastava, and Iryna Gurevych. 2021. Beir: A heterogenous benchmark for zero-shot evaluation of information retrieval models.arXiv preprint arXiv:2104.08663(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[38]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need.Advances in neural information processing systems30 (2017)
work page 2017
-
[39]
Wenhui Wang, Furu Wei, Li Dong, Hangbo Bao, Nan Yang, and Ming Zhou
-
[40]
Minilm: Deep self-attention distillation for task-agnostic compression of pre-trained transformers.Advances in neural information processing systems33 (2020), 5776–5788
work page 2020
-
[41]
Xhluca. 2023. BM25 Benchmarks. https://github.com/xhluca/bm25- benchmarks/blob/22df0ccccc083d2985a5b7e55d3ecd1764d4f9ed/README.md? plain=1#L220. Accessed: 2025-05-07
work page 2023
-
[42]
Puxuan Yu, Luke Merrick, Gaurav Nuti, and Daniel Campos. 2024. Arctic-Embed 2.0: Multilingual Retrieval Without Compromise. arXiv:2412.04506 [cs.CL] https: //arxiv.org/abs/2412.04506 9 Vujanic et al. A Training Setup A.1 Pooling Layer In Figure 8 a comparison of different popular pooling layers is shown. These are obtained by running one training epoch of...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.