LifeAlign: Lifelong Alignment for Large Language Models with Memory-Augmented Focalized Preference Optimization
Pith reviewed 2026-05-18 14:42 UTC · model grok-4.3
The pith
LifeAlign maintains human preference alignment in LLMs across sequential tasks without catastrophic forgetting.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
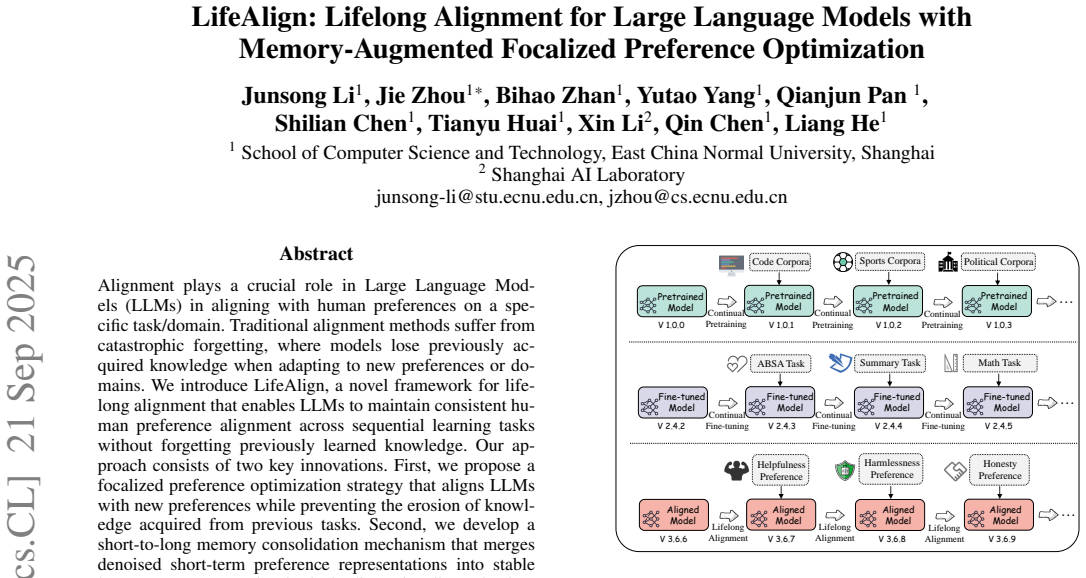
LifeAlign is a novel framework that enables LLMs to maintain consistent human preference alignment across sequential learning tasks without forgetting previously learned knowledge. It achieves this through a focalized preference optimization strategy that aligns models with new preferences while preventing erosion of prior knowledge, and a short-to-long memory consolidation mechanism that merges denoised short-term preference representations into stable long-term memory using intrinsic dimensionality reduction.
What carries the argument
short-to-long memory consolidation mechanism that merges denoised short-term preference representations into stable long-term memory using intrinsic dimensionality reduction
Load-bearing premise
The short-to-long memory consolidation using intrinsic dimensionality reduction will reliably merge denoised short-term representations into stable long-term memory without significant loss of alignment patterns across diverse domains.
What would settle it
After sequential training on tasks from several distinct domains, measuring whether performance on the earliest task stays comparable to a model trained only on that task would confirm the claim; a substantial decline would falsify it.
Figures







read the original abstract
Alignment plays a crucial role in Large Language Models (LLMs) in aligning with human preferences on a specific task/domain. Traditional alignment methods suffer from catastrophic forgetting, where models lose previously acquired knowledge when adapting to new preferences or domains. We introduce LifeAlign, a novel framework for lifelong alignment that enables LLMs to maintain consistent human preference alignment across sequential learning tasks without forgetting previously learned knowledge. Our approach consists of two key innovations. First, we propose a focalized preference optimization strategy that aligns LLMs with new preferences while preventing the erosion of knowledge acquired from previous tasks. Second, we develop a short-to-long memory consolidation mechanism that merges denoised short-term preference representations into stable long-term memory using intrinsic dimensionality reduction, enabling efficient storage and retrieval of alignment patterns across diverse domains. We evaluate LifeAlign across multiple sequential alignment tasks spanning different domains and preference types. Experimental results demonstrate that our method achieves superior performance in maintaining both preference alignment quality and knowledge retention compared to existing lifelong learning approaches. The codes and datasets have been released on https://github.com/real-ljs/LifeAlign.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LifeAlign, a framework for lifelong alignment of LLMs to human preferences across sequential tasks. It proposes two main components: a focalized preference optimization strategy that aligns to new preferences while preserving prior knowledge, and a short-to-long memory consolidation mechanism that uses intrinsic dimensionality reduction to merge denoised short-term preference representations into stable long-term memory. The approach is evaluated on multiple sequential alignment tasks spanning different domains, with claims of superior performance in alignment quality and knowledge retention over existing lifelong learning methods. Code and datasets are released.
Significance. If the empirical results hold under rigorous controls, the work would address a key limitation in LLM alignment by mitigating catastrophic forgetting in continual preference learning. The memory consolidation via dimensionality reduction and focalized optimization represent a plausible engineering approach to efficient storage and retrieval of alignment patterns. Releasing code supports reproducibility, which strengthens the contribution if the experiments are well-documented.
major comments (2)
- [Abstract] Abstract: the claim of 'superior performance in maintaining both preference alignment quality and knowledge retention' lacks any mention of specific baselines, metrics (e.g., win rates, forgetting measures), statistical significance tests, or task sequence details. This information is load-bearing for the central no-forgetting claim and must be supplied with concrete numbers and controls.
- [Method (memory consolidation)] Short-to-long memory consolidation section: the assumption that intrinsic dimensionality reduction (e.g., PCA or autoencoder) preserves key directions of human preference alignment across domains requires explicit validation. If the projection discards non-linear or task-specific preference features, the no-forgetting guarantee would be violated; the paper should report ablation results on reconstruction error for preference signals or alignment metrics before/after consolidation.
minor comments (2)
- [Experiments] Clarify the exact sequence of tasks, number of domains, and preference types used in the experiments to allow replication.
- [Method] Provide the precise definition and hyperparameters of the focalized preference optimization objective, including how it differs from standard DPO or RLHF variants.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and indicate the changes we will make in the revised version.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of 'superior performance in maintaining both preference alignment quality and knowledge retention' lacks any mention of specific baselines, metrics (e.g., win rates, forgetting measures), statistical significance tests, or task sequence details. This information is load-bearing for the central no-forgetting claim and must be supplied with concrete numbers and controls.
Authors: We agree that the abstract would be strengthened by including more concrete details. In the revision we will update the abstract to reference the specific baselines (EWC, GEM, and standard PPO), report key metrics such as win rates and forgetting rates drawn from the experimental results in Section 4, note statistical significance where computed, and briefly describe the task sequences used. These additions will make the central claims more precise without exceeding length constraints. revision: yes
-
Referee: [Method (memory consolidation)] Short-to-long memory consolidation section: the assumption that intrinsic dimensionality reduction (e.g., PCA or autoencoder) preserves key directions of human preference alignment across domains requires explicit validation. If the projection discards non-linear or task-specific preference features, the no-forgetting guarantee would be violated; the paper should report ablation results on reconstruction error for preference signals or alignment metrics before/after consolidation.
Authors: We appreciate this observation. While the current experiments show that end-to-end performance is preserved after consolidation, we acknowledge that dedicated validation of the dimensionality reduction step is warranted. In the revised manuscript we will add ablation results that quantify reconstruction error on the preference representations and compare alignment metrics immediately before and after the short-to-long consolidation step. These results will be presented in a new table or subsection to directly address the concern about potential loss of task-specific features. revision: yes
Circularity Check
No significant circularity; empirical framework with independent experimental validation
full rationale
The paper introduces LifeAlign as an empirical framework with two described innovations (focalized preference optimization and short-to-long memory consolidation via intrinsic dimensionality reduction). No equations, derivations, or fitted parameters are presented that reduce to inputs by construction. The central claims rest on experimental results across sequential tasks and released code, making them independently testable rather than self-referential. This is the common honest finding for applied ML papers without mathematical self-definition.
Axiom & Free-Parameter Ledger
invented entities (2)
-
focalized preference optimization strategy
no independent evidence
-
short-to-long memory consolidation mechanism
no independent evidence
Reference graph
Works this paper leans on
-
[1]
, " * write output.state after.block = add.period write newline
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint howpublished institution isbn journal key month note number organization pages publisher school series title type volume year label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block FUNCTION init.state.consts #0 'before.a...
-
[2]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[3]
Argilla. 2024. Capybara-Preferences Dataset. https://huggingface.co/datasets/argilla/Capybara-Preferences
work page 2024
-
[4]
Baddeley, A. 2000. The episodic buffer: a new component of working memory? Trends in cognitive sciences, 4(11): 417--423
work page 2000
-
[5]
Bai, Y.; Jones, A.; Ndousse, K.; Askell, A.; Chen, A.; DasSarma, N.; Drain, D.; Fort, S.; Ganguli, D.; Henighan, T.; et al. 2022 a . Training a helpful and harmless assistant with reinforcement learning from human feedback. arXiv preprint arXiv:2204.05862
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[6]
Bai, Y.; Kadavath, S.; Kundu, S.; Askell, A.; Kernion, J.; Jones, A.; Chen, A.; Goldie, A.; Mirhoseini, A.; McKinnon, C.; et al. 2022 b . Constitutional ai: Harmlessness from ai feedback. arXiv preprint arXiv:2212.08073
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[7]
Chaudhry, A.; Dokania, P. K.; Ajanthan, T.; and Torr, P. H. 2018. Riemannian walk for incremental learning: Understanding forgetting and intransigence. In Proceedings of the European conference on computer vision (ECCV), 532--547
work page 2018
-
[8]
Dai, J.; Pan, X.; Sun, R.; Ji, J.; Xu, X.; Liu, M.; Wang, Y.; and Yang, Y. 2023. Safe rlhf: Safe reinforcement learning from human feedback. arXiv preprint arXiv:2310.12773
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
Eckart, C.; and Young, G. 1936. The approximation of one matrix by another of lower rank. Psychometrika, 1(3): 211--218
work page 1936
- [10]
- [11]
- [12]
-
[13]
Jin, Q.; Yang, Y.; Chen, Q.; and Lu, Z. 2023. Genegpt: augmenting large language models with domain tools for improved access to biomedical information. arXiv. Ovadia, O., Brief, M., Mishaeli, M., & Elisha, O.(2023). Fine-tuning or retrieval
work page 2023
- [14]
-
[15]
R.; Bishop, C.; Hall, E.; Carbune, V.; Rastogi, A.; et al
Lee, H.; Phatale, S.; Mansoor, H.; Mesnard, T.; Ferret, J.; Lu, K. R.; Bishop, C.; Hall, E.; Carbune, V.; Rastogi, A.; et al. 2024. RLAIF vs. RLHF: Scaling Reinforcement Learning from Human Feedback with AI Feedback. In International Conference on Machine Learning, 26874--26901. PMLR
work page 2024
-
[16]
Lin, C.-Y. 2004. ROUGE : A Package for Automatic Evaluation of Summaries. In Text Summarization Branches Out, 74--81. Barcelona, Spain: Association for Computational Linguistics
work page 2004
-
[17]
Lin, S.; Hilton, J.; and Evans, O. 2022. TruthfulQA: Measuring How Models Mimic Human Falsehoods. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 3214--3252
work page 2022
-
[18]
Lopez-Paz, D.; and Ranzato, M. 2017. Gradient episodic memory for continual learning. Advances in neural information processing systems, 30
work page 2017
-
[19]
Mirsky, L. 1960. Symmetric gauge functions and unitarily invariant norms. The quarterly journal of mathematics, 11(1): 50--59
work page 1960
-
[20]
Ouyang, L.; Wu, J.; Jiang, X.; Almeida, D.; Wainwright, C.; Mishkin, P.; Zhang, C.; Agarwal, S.; Slama, K.; Ray, A.; et al. 2022. Training language models to follow instructions with human feedback. Advances in neural information processing systems, 35: 27730--27744
work page 2022
-
[21]
Papineni, K.; Roukos, S.; Ward, T.; and Zhu, W.-J. 2002. B leu: a Method for Automatic Evaluation of Machine Translation. In Isabelle, P.; Charniak, E.; and Lin, D., eds., Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, 311--318. Philadelphia, Pennsylvania, USA: Association for Computational Linguistics
work page 2002
-
[22]
Que, H.; Liu, J.; Zhang, G.; Zhang, C.; Qu, X.; Ma, Y.; Duan, F.; Bai, Z.; Wang, J.; Zhang, Y.; et al. 2024. D-cpt law: Domain-specific continual pre-training scaling law for large language models. Advances in Neural Information Processing Systems, 37: 90318--90354
work page 2024
-
[23]
Rafailov, R.; Sharma, A.; Mitchell, E.; Manning, C. D.; Ermon, S.; and Finn, C. 2023. Direct preference optimization: Your language model is secretly a reward model. Advances in neural information processing systems, 36: 53728--53741
work page 2023
-
[24]
Rolnick, D.; Ahuja, A.; Schwarz, J.; Lillicrap, T.; and Wayne, G. 2019. Experience replay for continual learning. Advances in neural information processing systems, 32
work page 2019
-
[25]
Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; and Klimov, O. 2017. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[26]
Shi, H.; Xu, Z.; Wang, H.; Qin, W.; Wang, W.; Wang, Y.; Wang, Z.; Ebrahimi, S.; and Wang, H. 2024. Continual learning of large language models: A comprehensive survey. ACM Computing Surveys
work page 2024
-
[27]
Tulving, E.; and Thomson, D. M. 1973. Encoding specificity and retrieval processes in episodic memory. Psychological review, 80(5): 352
work page 1973
-
[28]
Wang, X.; Chen, T.; Ge, Q.; Xia, H.; Bao, R.; Zheng, R.; Zhang, Q.; Gui, T.; and Huang, X. 2023 a . Orthogonal Subspace Learning for Language Model Continual Learning. In Bouamor, H.; Pino, J.; and Bali, K., eds., Findings of the Association for Computational Linguistics: EMNLP 2023, 10658--10671. Singapore: Association for Computational Linguistics
work page 2023
- [29]
-
[30]
Wang, Z.; Zhang, Z.; Lee, C.-Y.; Zhang, H.; Sun, R.; Ren, X.; Su, G.; Perot, V.; Dy, J.; and Pfister, T. 2022. Learning to prompt for continual learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 139--149
work page 2022
- [31]
-
[32]
Xie, Y.; Aggarwal, K.; and Ahmad, A. 2024. Efficient continual pre-training for building domain specific large language models. In Findings of the Association for Computational Linguistics ACL 2024, 10184--10201
work page 2024
-
[33]
Yadav, P.; Sun, Q.; Ding, H.; Li, X.; Zhang, D.; Tan, M.; Bhatia, P.; Ma, X.; Nallapati, R.; Ramanathan, M. K.; et al. 2023. Exploring Continual Learning for Code Generation Models. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), 782--792
work page 2023
-
[34]
Yang, Y.; Zhou, J.; Ding, X.; Huai, T.; Liu, S.; Chen, Q.; Xie, Y.; and He, L. 2025 a . Recent advances of foundation language models-based continual learning: A survey. ACM Computing Surveys, 57(5): 1--38
work page 2025
- [35]
-
[36]
Zhang, H.; Gui, L.; Lei, Y.; Zhai, Y.; Zhang, Y.; Zhang, Z.; He, Y.; Wang, H.; Yu, Y.; Wong, K.-F.; Liang, B.; and Xu, R. 2025. COPR : Continual Human Preference Learning via Optimal Policy Regularization. In Che, W.; Nabende, J.; Shutova, E.; and Pilehvar, M. T., eds., Findings of the Association for Computational Linguistics: ACL 2025, 5377--5398. Vienn...
work page 2025
-
[37]
Zhang, H.; Lei, Y.; Gui, L.; Yang, M.; He, Y.; WANG, H.; and Xu, R. 2024. CPPO: Continual Learning for Reinforcement Learning with Human Feedback. In Kim, B.; Yue, Y.; Chaudhuri, S.; Fragkiadaki, K.; Khan, M.; and Sun, Y., eds., International Conference on Representation Learning, volume 2024, 22719--22742
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.