ROPA: Synthetic Robot Pose Generation for RGB-D Bimanual Data Augmentation
Pith reviewed 2026-05-18 14:06 UTC · model grok-4.3
The pith
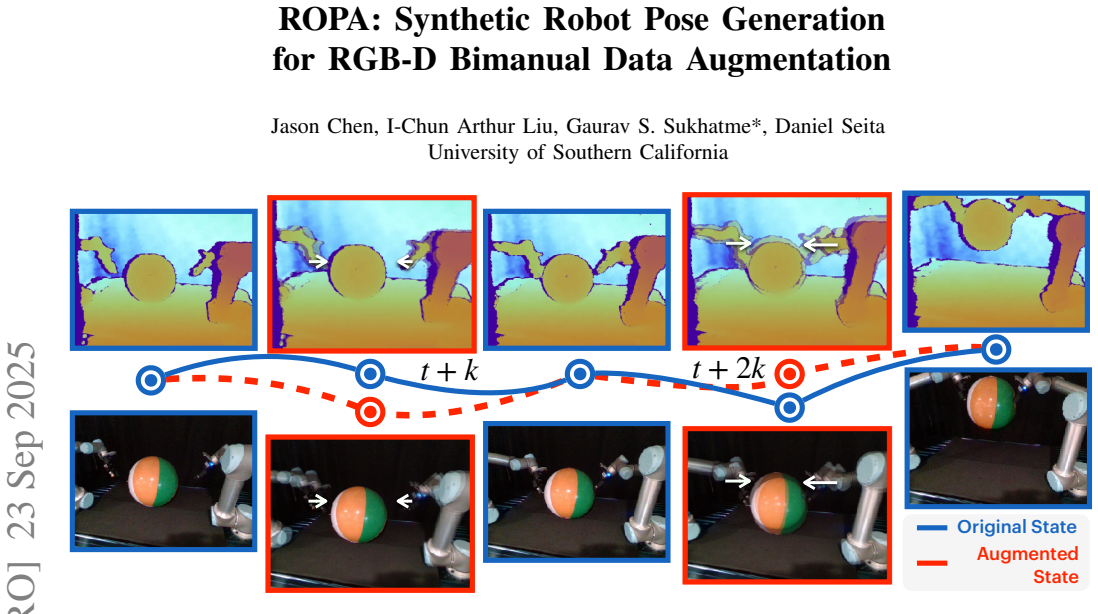
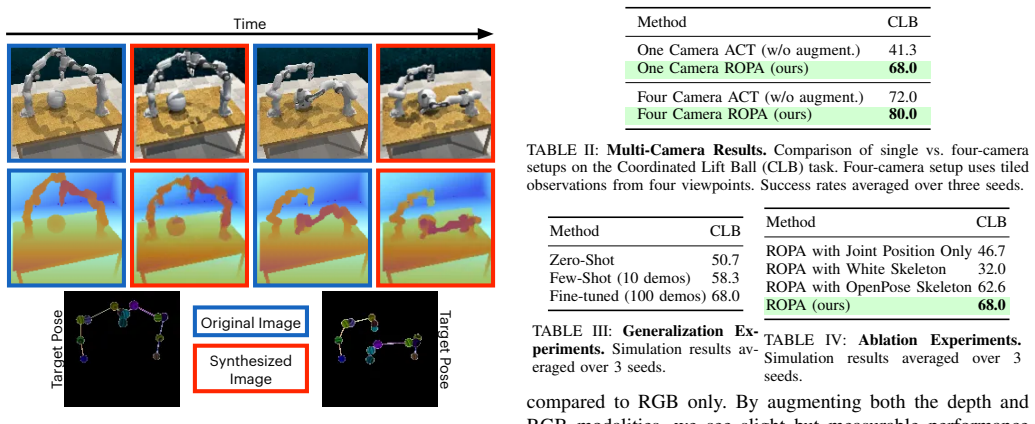
ROPA generates synthetic third-person RGB-D robot poses with matching actions to augment bimanual manipulation training data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ROPA fine-tunes Stable Diffusion to synthesize novel robot poses in third-person RGB and RGB-D views for bimanual scenarios, generates joint-space action labels, and applies constrained optimization to enforce physical consistency in gripper-to-object contacts, resulting in augmented datasets that improve policy performance on various tasks.
What carries the argument
The key mechanism is the combination of Stable Diffusion fine-tuning for pose synthesis and constrained optimization to ensure realistic bimanual contacts while producing action labels.
Load-bearing premise
The constrained optimization successfully enforces physical consistency in generated bimanual gripper-to-object contacts without introducing artifacts that degrade downstream policy performance.
What would settle it
A finding that policies trained on ROPA data do not outperform baselines in the real-world bimanual trials would challenge the effectiveness of the augmentation method.
Figures








read the original abstract
Training robust bimanual manipulation policies via imitation learning requires demonstration data with broad coverage over robot poses, contacts, and scene contexts. However, collecting diverse and precise real-world demonstrations is costly and time-consuming, which hinders scalability. Prior works have addressed this with data augmentation, typically for either eye-in-hand (wrist camera) setups with RGB inputs or for generating novel images without paired actions, leaving augmentation for eye-to-hand (third-person) RGB-D training with new action labels less explored. In this paper, we propose Synthetic Robot Pose Generation for RGB-D Bimanual Data Augmentation (ROPA), an offline imitation learning data augmentation method that fine-tunes Stable Diffusion to synthesize third-person RGB and RGB-D observations of novel robot poses. Our approach simultaneously generates corresponding joint-space action labels while employing constrained optimization to enforce physical consistency through appropriate gripper-to-object contact constraints in bimanual scenarios. We evaluate our method on 5 simulated and 3 real-world tasks. Our results across 2625 simulation trials and 300 real-world trials demonstrate that ROPA outperforms baselines and ablations, showing its potential for scalable RGB and RGB-D data augmentation in eye-to-hand bimanual manipulation. Our project website is available at: https://ropaaug.github.io/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ROPA, an offline imitation learning data augmentation method that fine-tunes Stable Diffusion to synthesize third-person RGB and RGB-D observations of novel robot poses for bimanual manipulation, while simultaneously generating corresponding joint-space action labels and applying constrained optimization to enforce physical consistency via gripper-to-object contact constraints. It reports outperformance over baselines and ablations across 5 simulated and 3 real-world tasks, based on 2625 simulation trials and 300 real-world trials.
Significance. If the central empirical claims hold, the work offers a practical route to scalable data augmentation for eye-to-hand RGB-D bimanual policies, where real demonstration collection is especially costly. The scale of the evaluation (hundreds of real-world trials plus thousands of simulated ones) and the explicit pairing of synthetic observations with action labels are strengths that could support broader adoption in imitation learning pipelines.
major comments (1)
- [Methods / constrained optimization] The constrained optimization for physical consistency (mentioned in the abstract and presumably detailed in the methods) is load-bearing for the claim that synthetic samples improve rather than degrade downstream policy performance. The manuscript should provide the explicit optimization formulation, the precise constraint types (e.g., kinematic contacts only, collision avoidance, or dynamics), solver tolerances, and quantitative validation (such as forward-simulation stability checks or contact-error metrics) that the generated bimanual poses remain artifact-free. Without these, it is difficult to rule out the possibility that under-constrained or over-relaxed solutions introduce implausible configurations that affect imitation learning results.
minor comments (2)
- [Experiments / results tables] Ensure all result tables report means with standard deviations or confidence intervals and include statistical significance tests for the reported improvements over baselines.
- [Methods] Clarify whether the Stable Diffusion fine-tuning and the constrained optimization steps are performed jointly or sequentially, and provide the exact loss terms or regularization used during fine-tuning.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and for recognizing the potential of ROPA for scalable data augmentation in bimanual imitation learning. We address the major comment on the constrained optimization below and will revise the manuscript to provide the requested details.
read point-by-point responses
-
Referee: [Methods / constrained optimization] The constrained optimization for physical consistency (mentioned in the abstract and presumably detailed in the methods) is load-bearing for the claim that synthetic samples improve rather than degrade downstream policy performance. The manuscript should provide the explicit optimization formulation, the precise constraint types (e.g., kinematic contacts only, collision avoidance, or dynamics), solver tolerances, and quantitative validation (such as forward-simulation stability checks or contact-error metrics) that the generated bimanual poses remain artifact-free. Without these, it is difficult to rule out the possibility that under-constrained or over-relaxed solutions introduce implausible configurations that affect imitation learning results.
Authors: We agree that the constrained optimization is central to ensuring the synthetic data does not degrade policy performance, and we appreciate the request for greater transparency. In Section 3.3 of the manuscript, the approach is described at a high level as a post-processing step that refines diffusion-generated poses. To address this comment, we will expand the section in the revision to include: (1) the explicit quadratic program formulation minimizing pose deviation subject to contact constraints; (2) the precise constraint types, which are purely kinematic (gripper fingertip positions constrained to lie on or within a small epsilon of the object surface for contact maintenance, with no penetration and no dynamics or full collision avoidance); (3) solver details using OSQP with a primal/dual tolerance of 1e-4 and maximum 1000 iterations; and (4) quantitative validation consisting of contact-error metrics (mean 1.8 mm across generated samples) and forward-simulation stability checks in the simulator, where 96.4% of poses exhibited no interpenetration or instability over 50 timesteps. These additions will allow readers to better assess the physical plausibility of the outputs. revision: yes
Circularity Check
No circularity: empirical augmentation method evaluated on external task benchmarks
full rationale
The paper describes an offline data augmentation pipeline that fine-tunes Stable Diffusion to produce novel third-person RGB/RGB-D observations paired with joint actions, then applies constrained optimization to enforce gripper-object contact constraints. All reported results consist of downstream policy performance measured on held-out simulation and real-world bimanual tasks (2625 sim trials, 300 real trials). No equations, predictions, or first-principles claims are presented that reduce by construction to fitted parameters, self-citations, or renamed inputs; the evaluation uses independent task success metrics rather than internal consistency checks. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Fine-tuned diffusion models can generate robot observations that are distributionally close enough to real data to improve policy training.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Our approach simultaneously generates corresponding joint-space action labels while employing constrained optimization to enforce physical consistency through appropriate gripper-to-object contact constraints in bimanual scenarios.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
A Bimanual Manipulation Taxonomy,
F. Krebs and T. Asfour, “A Bimanual Manipulation Taxonomy,” in IEEE Robotics and Automation Letters (RA-L), 2022
work page 2022
-
[2]
A System for Imi- tation Learning of Contact-Rich Bimanual Manipulation Policies,
S. Stepputtis, M. Bandari, S. Schaal, and H. Ben Amor, “A System for Imi- tation Learning of Contact-Rich Bimanual Manipulation Policies,” in IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2022
work page 2022
-
[3]
Deep Imitation Learning for Bimanual Robotic Manipulation,
F. Xie, A. Chowdhury, M. C. De Paolis Kaluza, L. Zhao, L. L. Wong, and R. Yu, “Deep Imitation Learning for Bimanual Robotic Manipulation,” in Neural Information Processing Systems (NeurIPS), 2020
work page 2020
-
[4]
SpeedFolding: Learning Efficient Bimanual Folding of Garments,
Y . Avigal, L. Berscheid, T. Asfour, T. Kr ¨oger, and K. Goldberg, “SpeedFolding: Learning Efficient Bimanual Folding of Garments,” in IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2022
work page 2022
-
[5]
Stabilize to Act: Learning to Coordinate for Bimanual Manipulation,
J. Grannen, Y . Wu, B. Vu, and D. Sadigh, “Stabilize to Act: Learning to Coordinate for Bimanual Manipulation,” in Conference on Robot Learning (CoRL), 2023
work page 2023
-
[6]
J. Maitin-Shepard, M. Cusumano-Towner, J. Lei, and P. Abbeel, “Cloth Grasp Point Detection Based on Multiple-View Geometric Cues with Application to Robotic Towel Folding,” in IEEE International Conference on Robotics and Automation (ICRA), 2010
work page 2010
-
[7]
FabricFlowNet: Bimanual Cloth Manipulation with a Flow-based Policy,
T. Weng, S. Bajracharya, Y . Wang, K. Agrawal, and D. Held, “FabricFlowNet: Bimanual Cloth Manipulation with a Flow-based Policy,” in Conference on Robot Learning (CoRL), 2021
work page 2021
-
[8]
V oxAct-B: V oxel-Based Acting and Stabilizing Policy for Bimanual Manipulation,
I.-C. A. Liu, S. He, D. Seita, and G. Sukhatme, “V oxAct-B: V oxel-Based Acting and Stabilizing Policy for Bimanual Manipulation,” in Conference on Robot Learning (CoRL), 2024
work page 2024
-
[9]
Twisting Lids Off with Two Hands,
T. Lin, Z.-H. Yin, H. Qi, P. Abbeel, and J. Malik, “Twisting Lids Off with Two Hands,” in Conference on Robot Learning (CoRL), 2024
work page 2024
-
[10]
An Algorithmic Perspective on Imitation Learning,
T. Osa, J. Pajarinen, G. Neumann, J. A. Bagnell, P. Abbeel, and J. Peters, “An Algorithmic Perspective on Imitation Learning,” F&T in Robotics, 2018
work page 2018
-
[11]
π0: A Vision-Language-Action Flow Model for General Robot Control,
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, and et al., “π0: A Vision-Language-Action Flow Model for General Robot Control,” in Robotics: Science and Systems (RSS), 2025
work page 2025
-
[12]
π 0.5: a Vision-Language-Action Model with Open-World Generalization,
P. Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, and et al., “π 0.5: a Vision-Language-Action Model with Open-World Generalization,” in Conference on Robot Learning (CoRL), 2025
work page 2025
-
[13]
RDT- 1B: a Diffusion Foundation Model for Bimanual Manipulation,
S. Liu, L. Wu, B. Li, H. Tan, H. Chen, Z. Wang, K. Xu, H. Su, and J. Zhu, “RDT- 1B: a Diffusion Foundation Model for Bimanual Manipulation,” in International Conference on Learning Representations (ICLR), 2025
work page 2025
-
[14]
View- Invariant Policy Learning via Zero-Shot Novel View Synthesis,
S. Tian, B. Wulfe, K. Sargent, K. Liu, S. Zakharov, V . Guizilini, and J. Wu, “View- Invariant Policy Learning via Zero-Shot Novel View Synthesis,” in Conference on Robot Learning (CoRL), 2024
work page 2024
-
[15]
D-CODA: Diffusion for Coordinated Dual-Arm Data Augmentation,
I.-C. A. Liu, J. Chen, G. Sukhatme, and D. Seita, “D-CODA: Diffusion for Coordinated Dual-Arm Data Augmentation,” in Conference on Robot Learning (CoRL), 2025
work page 2025
-
[16]
Diffusion Meets DAgger: Supercharging Eye-in-hand Imitation Learning,
X. Zhang, M. Chang, P. Kumar, and S. Gupta, “Diffusion Meets DAgger: Supercharging Eye-in-hand Imitation Learning,” in Robotics: Science and Systems (RSS), 2024
work page 2024
-
[17]
Pose Guided Person Image Generation,
L. Ma, X. Jia, Q. Sun, B. Schiele, T. Tuytelaars, and L. V . Gool, “Pose Guided Person Image Generation,” in Neural Information Processing Systems (NeurIPS), 2017
work page 2017
- [18]
-
[19]
Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware,
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn, “Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware,” in Robotics: Science and Systems (RSS), 2023
work page 2023
-
[20]
Constraints extraction from asymmetrical bimanual tasks and their use in coordinated behavior,
L. Ureche and A. Billard, “Constraints extraction from asymmetrical bimanual tasks and their use in coordinated behavior,” Robotics and Autonomous Systems, vol. 103, pp. 222–235, 2018
work page 2018
-
[21]
Towards Human-Level Bimanual Dexterous Manipula- tion with Reinforcement Learning,
Y . Chen, Y . Yang, T. Wu, S. Wang, X. Feng, J. Jiang, S. M. McAleer, H. Dong, Z. Lu, and S.-C. Zhu, “Towards Human-Level Bimanual Dexterous Manipula- tion with Reinforcement Learning,” in Neural Information Processing Systems (NeurIPS), 2022
work page 2022
-
[22]
Robopianist: Dexterous piano playing with deep reinforcement learning,
K. Zakka, P. Wu, L. Smith, N. Gileadi, T. Howell, X. B. Peng, S. Singh, Y . Tassa, P. Florence, A. Zeng, and P. Abbeel, “Robopianist: Dexterous piano playing with deep reinforcement learning,” in Conference on Robot Learning (CoRL), 2023
work page 2023
-
[23]
Efficient bimanual manipulation using learned task schemas,
R. Chitnis, S. Tulsiani, S. Gupta, and A. Gupta, “Efficient bimanual manipulation using learned task schemas,” in IEEE International Conference on Robotics and Automation (ICRA), 2020
work page 2020
-
[24]
Efficient Bimanual Handover and Rearrangement via Symmetry-Aware Actor-Critic Learning,
Y . Li, C. Pan, H. Xu, X. Wang, and Y . Wu, “Efficient Bimanual Handover and Rearrangement via Symmetry-Aware Actor-Critic Learning,” inIEEE International Conference on Robotics and Automation (ICRA), 2023
work page 2023
-
[25]
BiGym: A Demo-Driven Mobile Bi-Manual Manipulation Benchmark,
N. Chernyadev, N. Backshall, X. Ma, Y . Lu, Y . Seo, and S. James, “BiGym: A Demo-Driven Mobile Bi-Manual Manipulation Benchmark,” in Conference on Robot Learning (CoRL), 2024
work page 2024
-
[26]
Diffusion Policy: Visuomotor Policy Learning via Action Diffusion,
C. Chi, S. Feng, Y . Du, Z. Xu, E. Cousineau, B. Burchfiel, and S. Song, “Diffusion Policy: Visuomotor Policy Learning via Action Diffusion,” in Robotics: Science and Systems (RSS), 2023
work page 2023
-
[27]
Mobile ALOHA: Learning Bimanual Mobile Manipulation with Low-Cost Whole-Body Teleoperation,
Z. Fu, T. Z. Zhao, and C. Finn, “Mobile ALOHA: Learning Bimanual Mobile Manipulation with Low-Cost Whole-Body Teleoperation,” in Conference on Robot Learning (CoRL), 2024
work page 2024
-
[28]
ALOHA Unleashed: A Simple Recipe for Robot Dexterity,
T. Z. Zhao, J. Tompson, D. Driess, P. Florence, K. Ghasemipour, C. Finn, and A. Wahid, “ALOHA Unleashed: A Simple Recipe for Robot Dexterity,” in Conference on Robot Learning (CoRL), 2024
work page 2024
-
[29]
Bunny- visionpro: Real-time bimanual dexterous teleoperation for imitation learning,
R. Ding, Y . Qin, J. Zhu, C. Jia, S. Yang, R. Yang, X. Qi, and X. Wang, “Bunny- visionpro: Real-time bimanual dexterous teleoperation for imitation learning,” in IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2025
work page 2025
-
[30]
Open X-Embodiment: Robotic Learning Datasets and RT-X Models,
O. X.-E. Collaboration, “Open X-Embodiment: Robotic Learning Datasets and RT-X Models,” in IEEE International Conference on Robotics and Automation (ICRA), 2024
work page 2024
-
[31]
Imagenet classification with deep convolutional neural networks,
A. Krizhevsky, I. Sutskever, and G. E. Hinton, “Imagenet classification with deep convolutional neural networks,” in Neural Information Processing Systems (NeurIPS), 2012
work page 2012
-
[32]
A Reduction of Imitation Learning and Structured Prediction to No-Regret Online Learning,
S. Ross, G. J. Gordon, and J. A. Bagnell, “A Reduction of Imitation Learning and Structured Prediction to No-Regret Online Learning,” in International Conference on Artificial Intelligence and Statistics (AISTATS), 2011
work page 2011
-
[33]
DART: Noise Injection for Robust Imitation Learning,
M. Laskey, J. Lee, R. Fox, A. D. Dragan, and K. Goldberg, “DART: Noise Injection for Robust Imitation Learning,” in Conference on Robot Learning (CoRL), 2017
work page 2017
-
[34]
Semantically Controllable Augmentations for Generalizable Robot Learning,
Z. Chen, Z. Mandi, H. Bharadhwaj, M. Sharma, S. Song, A. Gupta, and V . Kumar, “Semantically Controllable Augmentations for Generalizable Robot Learning,” in International Journal of Robotics Research (IJRR), 2024
work page 2024
-
[35]
C. Yuan, S. Joshi, S. Zhu, H. Su, H. Zhao, and Y . Gao, “RoboEngine: Plug- and-Play Robot Data Augmentation with Semantic Robot Segmentation and Background Generation,” in IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2025
work page 2025
-
[36]
H. Bharadhwaj, J. Vakil, M. Sharma, A. Gupta, S. Tulsiani, and V . Kumar, “RoboAgent: Generalization and Efficiency in Robot Manipulation via Semantic Augmentations and Action Chunking,” in IEEE International Conference on Robotics and Automation (ICRA), 2024
work page 2024
-
[37]
Scaling Robot Learning with Semantically Imagined Experience,
T. Yu, T. Xiao, A. Stone, J. Tompson, A. Brohan, S. Wang, J. Singh, C. Tan, D. M, J. Peralta, B. Ichter, K. Hausman, and F. Xia, “Scaling Robot Learning with Semantically Imagined Experience,” in Robotics: Science and Systems (RSS), 2023
work page 2023
-
[38]
Novel demon- stration generation with gaussian splatting enables robust one-shot manipulation,
S. Yang, W. Yu, J. Zeng, J. Lv, K. Ren, C. Lu, D. Lin, and J. Pang, “Novel demon- stration generation with gaussian splatting enables robust one-shot manipulation,” in Robotics: Science and Systems (RSS), 2025
work page 2025
-
[39]
Data Augmentation for Manipulation,
P. Mitrano and D. Berenson, “Data Augmentation for Manipulation,” in Robotics: Science and Systems (RSS), 2022
work page 2022
-
[40]
CCIL: Continuity- based Data Augmentation for Corrective Imitation Learning,
L. Ke, Y . Zhang, A. Deshpande, S. Srinivasa, and A. Gupta, “CCIL: Continuity- based Data Augmentation for Corrective Imitation Learning,” in International Conference on Learning Representations (ICLR), 2024
work page 2024
-
[41]
NeRF in the Palm of Your Hand: Corrective Augmentation for Robotics via Novel-View Synthesis,
A. Zhou, M. J. Kim, L. Wang, P. Florence, and C. Finn, “NeRF in the Palm of Your Hand: Corrective Augmentation for Robotics via Novel-View Synthesis,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2023
work page 2023
-
[42]
MimicGen: A Data Generation System for Scalable Robot Learning using Human Demonstrations,
A. Mandlekar, S. Nasiriany, B. Wen, I. Akinola, Y . Narang, L. Fan, Y . Zhu, and D. Fox, “MimicGen: A Data Generation System for Scalable Robot Learning using Human Demonstrations,” in Conference on Robot Learning (CoRL), 2023
work page 2023
-
[43]
DexMimicGen: Automated Data Generation for Bimanual Dexterous Manipula- tion via Imitation Learning,
Z. Jiang, Y . Xie, K. Lin, Z. Xu, W. Wan, A. Mandlekar, L. Fan, and Y . Zhu, “DexMimicGen: Automated Data Generation for Bimanual Dexterous Manipula- tion via Imitation Learning,” in IEEE International Conference on Robotics and Automation (ICRA), 2025
work page 2025
-
[44]
RoVi-Aug: Robot and Viewpoint Augmentation for Cross-Embodiment Robot Learning,
L. Y . Chen, C. Xu, K. Dharmarajan, M. Z. Irshad, R. Cheng, K. Keutzer, M. Tomizuka, Q. Vuong, and K. Goldberg, “RoVi-Aug: Robot and Viewpoint Augmentation for Cross-Embodiment Robot Learning,” in Conference on Robot Learning (CoRL), 2024
work page 2024
-
[45]
Visual robotic manipulation with depth-aware pretraining,
J. Li, W. Wang, Y . Peng, C. Shen, Y . Zhu, and Z. Xu, “Visual robotic manipulation with depth-aware pretraining,” in IEEE International Conference on Robotics and Biomimetics (ROBIO), 2024
work page 2024
-
[46]
Person Image Synthesis via Denoising Diffusion Model,
A. K. Bhunia, S. Khan, H. Cholakkal, R. M. Anwer, J. Laaksonen, M. Shah, and F. S. Khan, “Person Image Synthesis via Denoising Diffusion Model,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2023
work page 2023
-
[47]
Coarse-to-Fine Latent Diffusion for Pose-Guided Person Image Synthesis,
Y . Lu, M. Zhang, A. J. Ma, X. Xie, and J.-H. Lai, “Coarse-to-Fine Latent Diffusion for Pose-Guided Person Image Synthesis,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024
work page 2024
-
[48]
Generative Image as Action Models,
M. Shridhar, Y . L. Lo, and S. James, “Generative Image as Action Models,” in Conference on Robot Learning (CoRL), 2024
work page 2024
-
[49]
Adding Conditional Control to Text-to- Image Diffusion Models,
L. Zhang, A. Rao, and M. Agrawala, “Adding Conditional Control to Text-to- Image Diffusion Models,” in IEEE/CVF International Conference on Computer Vision (ICCV), 2023
work page 2023
-
[50]
Diff- control: A stateful diffusion-based policy for imitation learning,
X. Liu, Y . Zhou, F. Weigend, S. Sonawani, S. Ikemoto, and H. B. Amor, “Diff- control: A stateful diffusion-based policy for imitation learning,” in IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2024
work page 2024
-
[51]
Differentiable robot rendering,
R. Liu, A. Canberk, S. Song, and C. V ondrick, “Differentiable robot rendering,” in Conference on Robot Learning (CoRL), 2024
work page 2024
-
[52]
Single-view robot pose and joint angle estimation via render & compare,
Y . Labb ´e, J. Carpentier, M. Aubry, and J. Sivic, “Single-view robot pose and joint angle estimation via render & compare,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2021
work page 2021
-
[53]
Openpose: Realtime multi-person 2d pose estimation using part affinity fields,
Z. Cao, G. Hidalgo, T. Simon, S.-E. Wei, and Y . Sheikh, “Openpose: Realtime multi-person 2d pose estimation using part affinity fields,” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019
work page 2019
-
[54]
High-resolution image synthesis with latent diffusion models,
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High-resolution image synthesis with latent diffusion models,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2022
work page 2022
-
[55]
Learning Transferable Visual Models From Natural Language Supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sas- try, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever, “Learning Transferable Visual Models From Natural Language Supervision,” in International Conference on Machine Learning (ICML), 2021
work page 2021
-
[56]
Denoising Diffusion Probabilistic Models,
J. Ho, A. Jain, and P. Abbeel, “Denoising Diffusion Probabilistic Models,” in Neural Information Processing Systems (NeurIPS), 2020
work page 2020
-
[57]
Denoising Diffusion Implicit Models,
J. Song, C. Meng, and S. Ermon, “Denoising Diffusion Implicit Models,” in International Conference on Learning Representations (ICLR), 2021
work page 2021
- [58]
-
[59]
Robot collision detection without external sensors based on time-series analysis,
T. Zhang, P. Ge, Y . Zou, and Y . He, “Robot collision detection without external sensors based on time-series analysis,”Journal of Dynamic Systems, Measurement, and Control, vol. 143, no. 4, 11 2020
work page 2020
-
[60]
Rlbench: The robot learning benchmark & learning environment,
S. James, Z. Ma, D. Rovick Arrojo, and A. J. Davison, “Rlbench: The robot learning benchmark & learning environment,” in IEEE Robotics and Automation Letters (RA-L), 2020
work page 2020
-
[61]
ZeroNVS: Zero-Shot 360-Degree View Synthesis from a Single Image,
K. Sargent, Z. Li, T. Shah, C. Herrmann, H.-X. Yu, Y . Zhang, E. R. Chan, D. Lagun, L. Fei-Fei, D. Sun, and J. Wu, “ZeroNVS: Zero-Shot 360-Degree View Synthesis from a Single Image,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024
work page 2024
-
[62]
Depth anything: Unleashing the power of large-scale unlabeled data,
L. Yang, B. Kang, Z. Huang, X. Xu, J. Feng, and H. Zhao, “Depth anything: Unleashing the power of large-scale unlabeled data,” in CVPR, 2024
work page 2024
-
[63]
GELLO: A General, Low-Cost, and Intuitive Teleoperation Framework for Robot Manipulators,
P. Wu, Y . Shentu, Z. Yi, X. Lin, and P. Abbeel, “GELLO: A General, Low-Cost, and Intuitive Teleoperation Framework for Robot Manipulators,” in IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2024
work page 2024
-
[64]
Generalized simulated annealing algorithm and its application to the thomson model,
Y . Xiang, D. Sun, W. Fan, and X. Gong, “Generalized simulated annealing algorithm and its application to the thomson model,” Physics Letters A, vol. 233, no. 3, pp. 216–220, 1997. [Online]. Available: https://www.sciencedirect.com/ science/article/pii/S037596019700474X
work page 1997
-
[65]
Controlnet++: Improving conditional controls with efficient consistency feedback,
M. Li, T. Yang, H. Kuang, J. Wu, Z. Wang, X. Xiao, and C. Chen, “Controlnet++: Improving conditional controls with efficient consistency feedback,” in European Conference on Computer Vision (ECCV), 2024
work page 2024
-
[66]
H. Yang, W. Han, Y . Zhou, and J. Shen, “Dc-controlnet: Decoupling inter- and intra-element conditions in image generation with diffusion models,”arXiv preprint arXiv:2502.14779, 2025
-
[67]
Uni-controlnet: All-in-one control to text-to-image diffusion models,
S. Zhao, D. Chen, Y .-C. Chen, J. Bao, S. Hao, L. Yuan, and K.-Y . K. Wong, “Uni-controlnet: All-in-one control to text-to-image diffusion models,” in Neural Information Processing Systems (NeurIPS), 2023
work page 2023
-
[68]
ControlNeXt: Powerful and efficient control for image and video generation,
B. Peng, J. Wang, Y . Zhang, W. Li, M.-C. Yang, and J. Jia, “Controlnext: Powerful and efficient control for image and video generation,” arXiv preprint arXiv:2408.06070, 2024
-
[69]
Cocktail: Mixing multi-modality controls for text-conditional image generation,
M. Hu, J. Zheng, D. Liu, C. Zheng, C. Wang, D. Tao, and T.-J. Cham, “Cocktail: Mixing multi-modality controls for text-conditional image generation,” arXiv preprint arXiv:2306.00964, 2023
-
[70]
Exploring bias in over 100 text-to- image generative models,
J. Vice, N. Akhtar, R. Hartley, and A. Mian, “Exploring bias in over 100 text-to- image generative models,” arXiv preprint arXiv: 2503.08012, 2025. APPENDIX A. Paper Changelog Version 1 on arXiv is the initial public release of the paper. B. Task Details Coordinated Lift Ball (CLB) Coordinated Lift Tray (CLT) Coordinated Push Box (CPB) Bimanual Straighten...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.