Retrieval-of-Thought: Efficient Reasoning via Reusing Thoughts
Pith reviewed 2026-05-18 13:38 UTC · model grok-4.3
The pith
Retrieval-of-Thought reuses past reasoning steps from a graph to direct new solutions, reducing tokens by up to 40 percent and latency by 82 percent with no accuracy loss.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Retrieval-of-Thought builds a thought graph from prior reasoning traces using sequential and semantic edges. At inference time relevant nodes are retrieved and a reward-guided traversal assembles them into a problem-specific template. This template then guides the model's generation process, which reduces redundant exploration in the reasoning trace. As a result output tokens decrease substantially while accuracy on reasoning tasks is maintained.
What carries the argument
The thought graph, which decomposes prior reasoning into nodes connected by sequential and semantic edges to support fast retrieval and flexible recombination into new templates.
Load-bearing premise
The load-bearing premise is that past reasoning traces can be broken into parts that connect meaningfully enough to be recombined accurately for entirely new problems.
What would settle it
Observing whether accuracy falls or token savings disappear when RoT is applied to problems whose required reasoning steps have no close match in the existing thought graph.
Figures









read the original abstract
Large reasoning models improve accuracy by producing long reasoning traces, but this inflates latency and cost, motivating inference-time efficiency. We propose Retrieval-of-Thought (RoT), which reuses prior reasoning as composable ``thought" steps to guide new problems. RoT organizes steps into a thought graph with sequential and semantic edges to enable fast retrieval and flexible recombination. At inference, RoT retrieves query-relevant nodes and applies reward-guided traversal to assemble a problem-specific template that guides generation. This dynamic template reuse reduces redundant exploration and, therefore, reduces output tokens while preserving accuracy. We evaluate RoT on reasoning benchmarks with multiple models, measuring accuracy, token usage, latency, and memory overhead. Findings show small prompt growth but substantial efficiency gains, with RoT reducing output tokens by up to 40%, inference latency by 82%, and cost by 59% while maintaining accuracy. RoT establishes a scalable paradigm for efficient LRM reasoning via dynamic template construction through retrieval.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Retrieval-of-Thought (RoT), which organizes prior reasoning traces into a thought graph with sequential and semantic edges. At inference, relevant nodes are retrieved and a reward-guided traversal assembles a problem-specific template to guide generation, reducing redundant steps. The central claim is that this yields up to 40% fewer output tokens, 82% lower inference latency, and 59% lower cost while preserving accuracy on reasoning benchmarks across multiple models.
Significance. If the efficiency gains are robust, RoT offers a practical engineering advance for lowering inference costs of large reasoning models through dynamic reuse of prior thoughts rather than full regeneration. The empirical focus on token, latency, and cost metrics with multiple models provides a direct, falsifiable test of the approach.
major comments (2)
- [Abstract] Abstract: the headline efficiency claims (40% token reduction, 82% latency reduction, 59% cost reduction while maintaining accuracy) are presented without benchmark names, number of runs, statistical tests, error bars, or explicit controls for prompt-length effects from retrieved context. These omissions make it impossible to verify that the reported gains are not confounded by problem selection or baseline prompt overhead.
- [Abstract (method and findings paragraphs)] The accuracy-preservation claim rests on the assumption that retrieved thought nodes recombine correctly for unseen problems via sequential/semantic edges and reward-guided traversal. However, aggregate accuracy numbers alone do not isolate cases where recombination succeeds from those where it silently degrades quality or triggers fallback to full generation; no per-problem similarity analysis or error-injection ablation is described.
minor comments (2)
- [Abstract] The abstract states 'small prompt growth' but does not quantify the added token overhead from retrieval or graph construction; a table or figure reporting average prompt length with/without RoT would clarify the net efficiency.
- [Abstract] Memory overhead is mentioned as part of the evaluation but receives no numerical results in the summary findings; adding a short table or sentence with peak memory figures would strengthen the practical assessment.
Simulated Author's Rebuttal
We thank the referee for the detailed and insightful comments. We address each major comment below and indicate the revisions planned for the updated manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline efficiency claims (40% token reduction, 82% latency reduction, 59% cost reduction while maintaining accuracy) are presented without benchmark names, number of runs, statistical tests, error bars, or explicit controls for prompt-length effects from retrieved context. These omissions make it impossible to verify that the reported gains are not confounded by problem selection or baseline prompt overhead.
Authors: We agree that the abstract would benefit from greater specificity on the headline claims. In the revised version we will name the primary benchmarks (GSM8K, MATH, and others), state that results are averaged over multiple runs with standard deviations, and reference the statistical tests and error bars already reported in Section 4. We will also add a short clause noting that prompt-length effects are controlled by comparing against a no-retrieval baseline that uses equivalent formatting and by separately reporting the incremental token cost of the retrieved context. Full per-benchmark tables, run counts, and controls remain in the experimental section. revision: yes
-
Referee: [Abstract (method and findings paragraphs)] The accuracy-preservation claim rests on the assumption that retrieved thought nodes recombine correctly for unseen problems via sequential/semantic edges and reward-guided traversal. However, aggregate accuracy numbers alone do not isolate cases where recombination succeeds from those where it silently degrades quality or triggers fallback to full generation; no per-problem similarity analysis or error-injection ablation is described.
Authors: We acknowledge that aggregate accuracy alone leaves open questions about recombination robustness. We will add a new subsection in the experiments that reports per-problem similarity scores between queries and retrieved nodes, together with an error-injection ablation that perturbs the thought graph and measures resulting fallback frequency and accuracy change. These additions will quantify when the reward-guided traversal succeeds versus when it triggers full regeneration. revision: yes
Circularity Check
No circularity; empirical engineering method with independent evaluation
full rationale
The paper presents Retrieval-of-Thought as a practical system that builds a thought graph from prior traces, retrieves nodes via sequential/semantic edges, and uses reward-guided traversal to form templates for generation. No equations, fitted parameters, or predictions are defined in the provided text that reduce by construction to the inputs (e.g., no self-definitional reuse of accuracy metrics or token counts). Efficiency gains are reported from direct benchmark measurements rather than tautological derivations. No self-citation chains or uniqueness theorems are invoked as load-bearing premises. The approach is self-contained as an algorithmic proposal tested empirically on external reasoning benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Reasoning traces from prior problems can be decomposed into composable thought steps connected by sequential and semantic relations that transfer usefully to new problems.
invented entities (1)
-
thought graph
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
RoT organizes steps into a thought graph with sequential and semantic edges... applies reward-guided traversal to assemble a problem-specific template
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
reduces output tokens by up to 40%, inference latency by 82%, and cost by 59% while maintaining accuracy
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Reflect, retry, reward: Self-improving llms via reinforcement learning.CoRR, abs/2505.24726, 2025
Shelly Bensal, Umar Jamil, Christopher Bryant, Melisa Russak, Kiran Kamble, Dmytro Mo- zolevskyi, Muayad Ali, and Waseem AlShikh. Reflect, retry, reward: Self-improving llms via reinforcement learning.arXiv preprint arXiv:2505.24726,
-
[2]
Aspd: Unlocking adaptive serial-parallel decoding by exploring intrinsic parallelism in llms
Keyu Chen, Zhifeng Shen, Daohai Yu, Haoqian Wu, Wei Wen, Jianfeng He, Ruizhi Qiao, and Xing Sun. Aspd: Unlocking adaptive serial-parallel decoding by exploring intrinsic parallelism in llms. arXiv preprint arXiv:2508.08895,
-
[3]
Seyyed Saeid Cheshmi, Azal Ahmad Khan, Xinran Wang, Zirui Liu, and Ali Anwar. Accelerating llm reasoning via early rejection with partial reward modeling.arXiv preprint arXiv:2508.01969,
-
[4]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capa- bilities.arXiv preprint arXiv:2507.06261,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Thinkless: Llm learns when to think.arXiv preprint arXiv:2505.13379,
Gongfan Fang, Xinyin Ma, and Xinchao Wang. Thinkless: Llm learns when to think.arXiv preprint arXiv:2505.13379,
-
[6]
Efficient reasoning models: A survey
Sicheng Feng, Gongfan Fang, Xinyin Ma, and Xinchao Wang. Efficient reasoning models: A survey. arXiv preprint arXiv:2504.10903,
-
[7]
Tingchen Fu, Jiawei Gu, Yafu Li, Xiaoye Qu, and Yu Cheng. Scaling reasoning, losing control: Evaluating instruction following in large reasoning models.arXiv preprint arXiv:2505.14810,
-
[8]
Michael Günther, Jackmin Ong, Isabelle Mohr, Alaeddine Abdessalem, Tanguy Abel, Moham- mad Kalim Akram, Susana Guzman, Georgios Mastrapas, Saba Sturua, Bo Wang, et al. Jina embeddings 2: 8192-token general-purpose text embeddings for long documents.arXiv preprint arXiv:2310.19923,
-
[9]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
10 Retrieval-of-Thought: Efficient Reasoning via Reusing Thoughts Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Token-budget-aware llm reasoning
Tingxu Han, Zhenting Wang, Chunrong Fang, Shiyu Zhao, Shiqing Ma, and Zhenyu Chen. Token- budget-aware llm reasoning.arXiv preprint arXiv:2412.18547,
-
[11]
Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, et al. Openai o1 system card.arXiv preprint arXiv:2412.16720,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Flashthink: An early exit method for efficient reasoning.arXiv preprint arXiv:2505.13949,
Guochao Jiang, Guofeng Quan, Zepeng Ding, Ziqin Luo, Dixuan Wang, and Zheng Hu. Flashthink: An early exit method for efficient reasoning.arXiv preprint arXiv:2505.13949,
-
[13]
Enhancing llm reasoning with reward-guided tree search.arXiv preprint arXiv:2411.11694, 2024a
Jinhao Jiang, Zhipeng Chen, Yingqian Min, Jie Chen, Xiaoxue Cheng, Jiapeng Wang, Yiru Tang, Haoxiang Sun, Jia Deng, Wayne Xin Zhao, et al. Enhancing llm reasoning with reward-guided tree search.arXiv preprint arXiv:2411.11694, 2024a. Yikun Jiang, Huanyu Wang, Lei Xie, Hanbin Zhao, Hui Qian, John Lui, et al. D-llm: A token adaptive computing resource alloc...
-
[14]
Xiaomin Li, Zhou Yu, Zhiwei Zhang, Xupeng Chen, Ziji Zhang, Yingying Zhuang, Narayanan Sadagopan, and Anurag Beniwal. When thinking fails: The pitfalls of reasoning for instruction- following in llms.arXiv preprint arXiv:2505.11423, 2025a. Zhong-Zhi Li, Duzhen Zhang, Ming-Liang Zhang, Jiaxin Zhang, Zengyan Liu, Yuxuan Yao, Haotian Xu, Junhao Zheng, Pei-Ji...
-
[15]
Datta Nimmaturi, Vaishnavi Bhargava, Rajat Ghosh, Johnu George, and Debojyoti Dutta. Pre- dictive scaling laws for efficient grpo training of large reasoning models.arXiv preprint arXiv:2507.18014,
-
[16]
Learning adaptive parallel reasoning with language models.arXiv preprint arXiv:2504.15466, 2025
Jiayi Pan, Xiuyu Li, Long Lian, Charlie Snell, Yifei Zhou, Adam Yala, Trevor Darrell, Kurt Keutzer, and Alane Suhr. Learning adaptive parallel reasoning with language models.arXiv preprint arXiv:2504.15466,
-
[17]
Md Rizwan Parvez. Evidence to generate (e2g): A single-agent two-step prompting for context grounded and retrieval augmented reasoning.arXiv preprint arXiv:2401.05787,
-
[18]
Shuai Peng, Ke Yuan, Liangcai Gao, and Zhi Tang. Mathbert: A pre-trained model for mathematical formula understanding.arXiv preprint arXiv:2105.00377,
-
[19]
Piotr Pi˛ ekos, Henryk Michalewski, and Mateusz Malinowski. Measuring and improving bert’s math- ematical abilities by predicting the order of reasoning.arXiv preprint arXiv:2106.03921,
-
[20]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathemati- cal reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling llm test-time compute optimally can be more effective than scaling model parameters.arXiv preprint arXiv:2408.03314,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Stop Overthinking: A Survey on Efficient Reasoning for Large Language Models
Yang Sui, Yu-Neng Chuang, Guanchu Wang, Jiamu Zhang, Tianyi Zhang, Jiayi Yuan, Hongyi Liu, Andrew Wen, Shaochen Zhong, Hanjie Chen, et al. Stop overthinking: A survey on efficient reasoning for large language models.arXiv preprint arXiv:2503.16419,
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Value-guided search for efficient chain-of-thought reasoning.arXiv preprint arXiv:2505.17373,
Kaiwen Wang, Jin Peng Zhou, Jonathan Chang, Zhaolin Gao, Nathan Kallus, Kianté Brantley, and Wen Sun. Value-guided search for efficient chain-of-thought reasoning.arXiv preprint arXiv:2505.17373,
-
[24]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdh- ery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. arXiv preprint arXiv:2203.11171,
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Rat: Retrieval augmented thoughts elicit context-aware reasoning in long-horizon generation
Zihao Wang, Anji Liu, Haowei Lin, Jiaqi Li, Xiaojian Ma, and Yitao Liang. Rat: Retrieval augmented thoughts elicit context-aware reasoning in long-horizon generation.arXiv preprint arXiv:2403.05313,
-
[26]
Tong Wu, Chong Xiang, Jiachen T Wang, G Edward Suh, and Prateek Mittal. Effectively controlling reasoning models through thinking intervention.arXiv preprint arXiv:2503.24370,
-
[27]
Monte carlo tree search boosts reasoning via iterative preference learning,
Yuxi Xie, Anirudh Goyal, Wenyue Zheng, Min-Yen Kan, Timothy P Lillicrap, Kenji Kawaguchi, and Michael Shieh. Monte carlo tree search boosts reasoning via iterative preference learning. arXiv preprint arXiv:2405.00451,
-
[28]
Towards Large Reasoning Models: A Survey of Reinforced Reasoning with Large Language Models
Fengli Xu, Qianyue Hao, Zefang Zong, Jingwei Wang, Yunke Zhang, Jingyi Wang, Xiaochong Lan, Jiahui Gong, Tianjian Ouyang, Fanjin Meng, et al. Towards large reasoning models: A survey of reinforced reasoning with large language models.arXiv preprint arXiv:2501.09686, 2025a. Zenan Xu, Zexuan Qiu, Guanhua Huang, Kun Li, Siheng Li, Chenchen Zhang, Kejiao Li, ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
Adam Younsi, Abdalgader Abubaker, Mohamed El Amine Seddik, Hakim Hacid, and Salem Lahlou. Accurate and diverse llm mathematical reasoning via automated prm-guided gflownets.arXiv preprint arXiv:2504.19981,
-
[30]
arXiv preprint arXiv:2505.24863 , year=
Junyu Zhang, Runpei Dong, Han Wang, Xuying Ning, Haoran Geng, Peihao Li, Xialin He, Yutong Bai, Jitendra Malik, Saurabh Gupta, et al. Alphaone: Reasoning models thinking slow and fast at test time.arXiv preprint arXiv:2505.24863, 2025a. Zhenru Zhang, Chujie Zheng, Yangzhen Wu, Beichen Zhang, Runji Lin, Bowen Yu, Dayiheng Liu, Jingren Zhou, and Junyang Lin...
-
[31]
OOT” stands for “Out of Tokens,
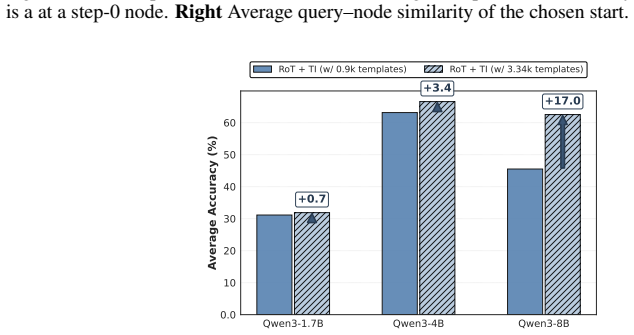
0.0 0.2 0.4 0.6 0.8 1.0 0.0 0.2 0.4 0.6 0.8 1.0Average Query Similarity Figure 9: First-step selection trade-off on the Thought Graph.LeftProbability that the chosen start is a at a step-0 node.RightAverage query–node similarity of the chosen start. Qwen3-1.7B Qwen3-4B Qwen3-8B 0.0 10 20 30 40 50 60Average Accuracy (%) RoT + TI (w/ 0.9k templates) RoT + T...
work page 2025
-
[32]
Out Tokens: 6746 Input:"You are given a template to solve the problem
Now substitute into the equations: First equation becomes: x·a= 10⇒a= 10 x Second equation becomes: 4y· 1 a = 10⇒ 4y a = 10 Substitutea= 10 x into the second equation: 4y 10 x = 10⇒ 4xy 10 = 10 Multiply both sides by 10: 4xy= 100⇒xy= 25 — Final Answer: 25 21 Retrieval-of-Thought: Efficient Reasoning via Reusing Thoughts RoT: Input and Output for AIME 2024...
work page 2024
-
[33]
Let me take the first equation
So now we have two equations:1)y x =x 10 2)x 4y =y 10 So maybe we can manipulate these equations. Let me take the first equation.......... I should have noticed that earlier instead of going through all the logarithmic manipulations and numerical solving. **Final Answer**25 </think> To solve the problem: We are given the following equations involving loga...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.