Polychromic Objectives for Reinforcement Learning
Pith reviewed 2026-05-18 11:51 UTC · model grok-4.3
The pith
A polychromic objective for policy gradients prevents pretrained RL policies from losing behavioral diversity during fine-tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
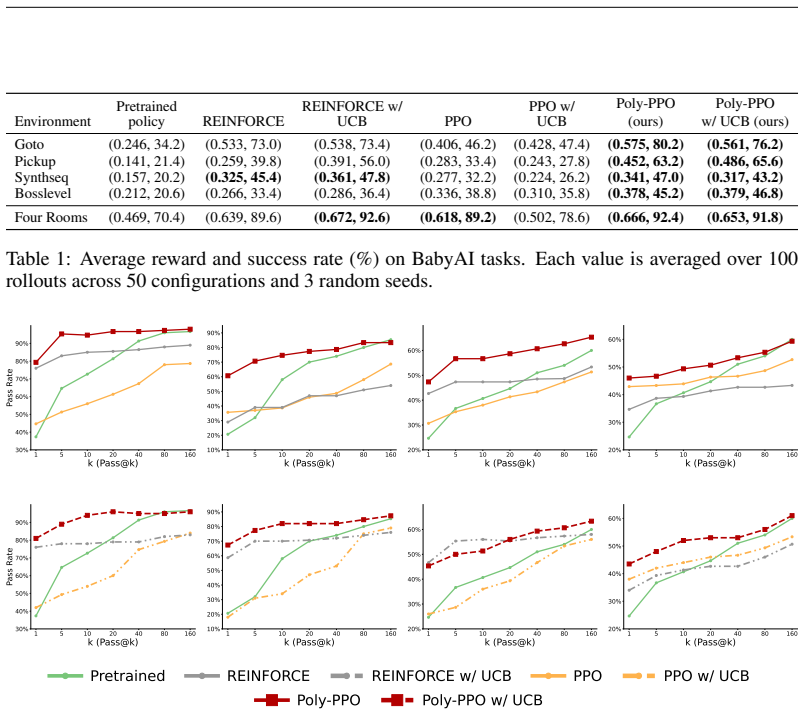
Optimizing a polychromic objective, which requires the policy to explore and refine a diverse set of generations, allows proximal policy optimization to avoid collapse into narrow behaviors and instead produce agents that reliably cover a larger fraction of solvable tasks while preserving a broad repertoire of strategies.
What carries the argument
The polychromic objective, realized by vine sampling to gather on-policy rollouts and a modified advantage function inside PPO that scores actions according to their contribution to diversity-preserving improvement.
If this is right
- Policies continue to explore new behaviors instead of converging to a handful of repeatable outputs.
- Higher success rates emerge because the agent solves a wider range of environment configurations.
- Generalization improves under large perturbations because multiple distinct strategies remain available.
- Pass@k performance rises because the policy retains and can deploy a broader set of successful trajectories.
Where Pith is reading between the lines
- The same objective could be applied to fine-tuning large language models where output diversity also collapses.
- Test-time compute scaling may yield larger gains when the base policy already maintains many distinct solution paths.
- Combining the polychromic term with other explicit exploration bonuses could further enlarge the set of reachable behaviors.
Load-bearing premise
Vine sampling plus the modified advantage produces on-policy data whose diversity statistics stay stable and representative without adding bias to the policy gradient estimate.
What would settle it
Run standard PPO and the polychromic variant side-by-side on the same BabyAI or Minigrid suite; if the polychromic version shows no increase in the number of solved configurations or in pass@k coverage after the same number of updates, the central claim does not hold.
Figures





read the original abstract
Reinforcement learning fine-tuning (RLFT) is a dominant paradigm for improving pretrained policies for downstream tasks. These pretrained policies, trained on large datasets, produce generations with a broad range of promising but unrefined behaviors. Often, a critical failure mode of RLFT arises when policies lose this diversity and collapse into a handful of easily exploitable outputs. This convergence hinders exploration, which is essential for expanding the capabilities of the pretrained policy and for amplifying the benefits of test-time compute scaling. To address this, we introduce an objective for policy gradient methods that explicitly enforces the exploration and refinement of diverse generations, which we call a polychromic objective. We then show how proximal policy optimization (PPO) can be adapted to optimize this objective. Our method (1) employs vine sampling to collect on-policy rollouts and (2) modifies the advantage function to reflect the advantage under our new objective. Experiments on BabyAI, Minigrid, and Algorithmic Creativity show that our method improves success rates by reliably solving a larger set of environment configurations and generalizes better under large perturbations. Moreover, when given multiple attempts in pass@$k$ experiments, the policy achieves substantially higher coverage, demonstrating its ability to maintain and exploit a diverse repertoire of strategies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes polychromic objectives for policy-gradient methods in reinforcement learning. These objectives explicitly encourage exploration and refinement of diverse generations during RL fine-tuning of pretrained policies, countering the common collapse into a small set of exploitable behaviors. The authors adapt PPO via vine sampling for on-policy rollouts and a modified advantage function that reflects the new objective. Experiments on BabyAI, Minigrid, and Algorithmic Creativity report higher success rates across more environment configurations, improved generalization under large perturbations, and substantially higher coverage in pass@k evaluations.
Significance. If the PPO adaptation is shown to optimize the polychromic objective without bias and the empirical gains are substantiated, the work would provide a practical mechanism for preserving behavioral diversity in RL fine-tuning. This directly targets a key limitation that reduces exploration and diminishes returns from test-time compute scaling. The approach could be relevant for domains where maintaining a repertoire of strategies is beneficial.
major comments (2)
- [§3] §3 (PPO adaptation): the manuscript does not verify that vine sampling combined with the modified advantage function yields an unbiased policy-gradient estimator for the polychromic objective. If the advantage modification does not exactly correspond to the gradient of the stated objective, or if vine sampling fails to keep the data distribution on-policy across iterations, then observed improvements cannot be attributed to the polychromic objective itself.
- [§4] §4 (Experiments): success-rate and pass@k results are presented without reported variance, statistical significance tests, ablation of the two proposed components (vine sampling and advantage modification), or comparison against strong diversity-preserving baselines. This leaves the central empirical claim without the quantitative support needed to assess reliability or generality.
minor comments (1)
- [Abstract] Notation for pass@k is written inconsistently as pass@$k$ in the abstract; adopt a uniform mathematical notation throughout.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and outline the revisions we plan to make in the next version of the manuscript.
read point-by-point responses
-
Referee: [§3] §3 (PPO adaptation): the manuscript does not verify that vine sampling combined with the modified advantage function yields an unbiased policy-gradient estimator for the polychromic objective. If the advantage modification does not exactly correspond to the gradient of the stated objective, or if vine sampling fails to keep the data distribution on-policy across iterations, then observed improvements cannot be attributed to the polychromic objective itself.
Authors: We appreciate the referee pointing out this gap. The current manuscript describes the PPO adaptation using vine sampling and the modified advantage but does not include an explicit derivation or proof of unbiasedness. Vine sampling collects multiple on-policy trajectories from the same starting state under the current policy to estimate the polychromic objective, and the advantage is redefined to reflect the expected improvement under that objective rather than the scalar reward. To address the concern directly, we will add a dedicated subsection to §3 that derives the policy gradient for the polychromic objective and shows that the combination of vine sampling and the modified advantage produces an unbiased estimator (under standard on-policy assumptions). This addition will make clear that the reported gains can be attributed to optimization of the proposed objective. revision: yes
-
Referee: [§4] §4 (Experiments): success-rate and pass@k results are presented without reported variance, statistical significance tests, ablation of the two proposed components (vine sampling and advantage modification), or comparison against strong diversity-preserving baselines. This leaves the central empirical claim without the quantitative support needed to assess reliability or generality.
Authors: We agree that the experimental presentation would be strengthened by additional statistical detail and controls. In the revised manuscript we will report means and standard deviations across multiple random seeds for all success-rate and pass@k metrics, along with appropriate statistical significance tests. We will also add ablation studies that isolate the contribution of vine sampling versus the modified advantage function. Finally, we will include comparisons against established diversity-preserving baselines such as entropy-regularized PPO and mutual-information-based exploration methods. These additions will be placed in an expanded §4 and will provide stronger quantitative support for the reliability and generality of the results. revision: yes
Circularity Check
Derivation chain is self-contained; no reduction to inputs by construction
full rationale
The paper introduces a new polychromic objective explicitly defined to enforce diversity across generations, distinct from the base reward signal, then describes a standard PPO adaptation via vine sampling for on-policy rollouts and an altered advantage function. These modifications are presented as technical steps to optimize the stated objective rather than as a re-derivation or fit that collapses back to the inputs. Experimental results on BabyAI, Minigrid, and Algorithmic Creativity are offered as external validation of improved success rates, generalization, and pass@k coverage, with diversity statistics measured separately. No self-definitional equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided derivation; the central claims therefore retain independent content.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Vine sampling produces unbiased on-policy estimates under the modified advantage function.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
fpoly(s, τ1:n) := (1/n) Σ R(τi) d(s, τ1:n) ... shared advantage term amplifies exploratory trajectories
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Minimax Regret Bounds for Reinforcement Learning
Mohammad Gheshlaghi Azar, Ian Osband, and R ´emi Munos. Minimax regret bounds for reinforcement learning, 2017. URLhttps://arxiv.org/abs/1703.05449
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[2]
Sutton, Mohammad Ghavamzadeh, and Mark Lee
Shalabh Bhatnagar, Richard S. Sutton, Mohammad Ghavamzadeh, and Mark Lee. Natural actor–critic algorithms.Automatica, 45(11):2471–2482, 2009. ISSN 0005-1098. doi: https:// doi.org/10.1016/j.automatica.2009.07.008. URLhttps://www.sciencedirect.com/ science/article/pii/S0005109809003549
-
[3]
Babyai: A platform to study the sample ef- ficiency of grounded language learning, 2019
Maxime Chevalier-Boisvert, Dzmitry Bahdanau, Salem Lahlou, Lucas Willems, Chitwan Sa- haria, Thien Huu Nguyen, and Yoshua Bengio. Babyai: A platform to study the sample ef- ficiency of grounded language learning, 2019. URLhttps://arxiv.org/abs/1810. 08272
work page 2019
-
[4]
Maxime Chevalier-Boisvert, Bolun Dai, Mark Towers, Rodrigo de Lazcano, Lucas Willems, Salem Lahlou, Suman Pal, Pablo Samuel Castro, and Jordan Terry. Minigrid and miniworld: Modular and customizable reinforcement learning environments for goal-oriented tasks, 2023. URLhttps://arxiv.org/abs/2306.13831
-
[5]
Inference-aware fine- 11 tuning for best-of-n sampling in large language models, 2024
Yinlam Chow, Guy Tennenholtz, Izzeddin Gur, Vincent Zhuang, Bo Dai, Sridhar Thiagarajan, Craig Boutilier, Rishabh Agarwal, Aviral Kumar, and Aleksandra Faust. Inference-aware fine- 11 tuning for best-of-n sampling in large language models, 2024. URLhttps://arxiv.org/ abs/2412.15287
-
[6]
The Entropy Mechanism of Reinforcement Learning for Reasoning Language Models
Ganqu Cui, Yuchen Zhang, Jiacheng Chen, Lifan Yuan, Zhi Wang, Yuxin Zuo, Haozhan Li, Yuchen Fan, Huayu Chen, Weize Chen, Zhiyuan Liu, Hao Peng, Lei Bai, Wanli Ouyang, Yu Cheng, Bowen Zhou, and Ning Ding. The entropy mechanism of reinforcement learning for reasoning language models, 2025. URLhttps://arxiv.org/abs/2505.22617
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
DeepSeek-AI, Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, Aixin Liu, Bing Xue, Bingxuan Wang, Bochao Wu, Bei Feng, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, Damai D...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Thomas Degris, Martha White, and Richard S. Sutton. Off-policy actor-critic, 2013. URL https://arxiv.org/abs/1205.4839
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[9]
The vendi score: A diversity evaluation metric for machine learning, 2023
Dan Friedman and Adji Bousso Dieng. The vendi score: A diversity evaluation metric for machine learning, 2023. URLhttps://arxiv.org/abs/2210.02410
-
[10]
Reinforcement Learning with Deep Energy-Based Policies
Tuomas Haarnoja, Haoran Tang, Pieter Abbeel, and Sergey Levine. Reinforcement learning with deep energy-based policies, 2017. URLhttps://arxiv.org/abs/1702.08165
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[11]
Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor
Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine. Soft actor-critic: Off- policy maximum entropy deep reinforcement learning with a stochastic actor, 2018. URL https://arxiv.org/abs/1801.01290
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[12]
Rewarding the unlikely: Lifting grpo beyond distribution sharpening, 2025
Andre He, Daniel Fried, and Sean Welleck. Rewarding the unlikely: Lifting grpo beyond distribution sharpening, 2025. URLhttps://arxiv.org/abs/2506.02355
-
[13]
Marginalized state distribution entropy regularization in policy optimization, 2019
Riashat Islam, Zafarali Ahmed, and Doina Precup. Marginalized state distribution entropy regularization in policy optimization, 2019. URLhttps://arxiv.org/abs/1912. 05128
work page 2019
-
[14]
Sham M Kakade. A natural policy gradient. In T. Dietterich, S. Becker, and Z. Ghahra- mani (eds.),Advances in Neural Information Processing Systems, volume 14. MIT Press, 12
-
[15]
URLhttps://proceedings.neurips.cc/paper_files/paper/2001/ file/4b86abe48d358ecf194c56c69108433e-Paper.pdf
work page 2001
-
[16]
Sham M. Kakade and John Langford. Approximately optimal approximate reinforcement learning. InInternational Conference on Machine Learning, 2002. URLhttps://api. semanticscholar.org/CorpusID:31442909
work page 2002
-
[17]
Vineppo: Refining credit assignment in rl training of llms, 2025
Amirhossein Kazemnejad, Milad Aghajohari, Eva Portelance, Alessandro Sordoni, Siva Reddy, Aaron Courville, and Nicolas Le Roux. Vineppo: Refining credit assignment in rl training of llms, 2025. URLhttps://arxiv.org/abs/2410.01679
-
[18]
One solution is not all you need: Few-shot extrapolation via structured maxent rl, 2020
Saurabh Kumar, Aviral Kumar, Sergey Levine, and Chelsea Finn. One solution is not all you need: Few-shot extrapolation via structured maxent rl, 2020. URLhttps://arxiv.org/ abs/2010.14484
-
[19]
Diverse Preference Optimization
Jack Lanchantin, Angelica Chen, Shehzaad Dhuliawala, Ping Yu, Jason Weston, Sainba- yar Sukhbaatar, and Ilia Kulikov. Diverse preference optimization, 2025. URLhttps: //arxiv.org/abs/2501.18101
-
[20]
Jointly reinforcing diversity and quality in language model generations
Tianjian Li, Yiming Zhang, Ping Yu, Swarnadeep Saha, Daniel Khashabi, Jason Weston, Jack Lanchantin, and Tianlu Wang. Jointly reinforcing diversity and quality in language model generations, 2025. URLhttps://arxiv.org/abs/2509.02534
-
[21]
Timothy P. Lillicrap, Jonathan J. Hunt, Alexander Pritzel, Nicolas Heess, Tom Erez, Yuval Tassa, David Silver, and Daan Wierstra. Continuous control with deep reinforcement learning. In Yoshua Bengio and Yann LeCun (eds.),4th International Conference on Learning Repre- sentations, ICLR 2016, San Juan, Puerto Rico, May 2-4, 2016, Conference Track Proceedings,
work page 2016
-
[22]
URLhttp://arxiv.org/abs/1509.02971
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Understanding R1-Zero-Like Training: A Critical Perspective
Zichen Liu, Changyu Chen, Wenjun Li, Penghui Qi, Tianyu Pang, Chao Du, Wee Sun Lee, and Min Lin. Understanding r1-zero-like training: A critical perspective, 2025. URLhttps: //arxiv.org/abs/2503.20783
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Vaishnavh Nagarajan, Chen Henry Wu, Charles Ding, and Aditi Raghunathan. Roll the dice and look before you leap: Going beyond the creative limits of next-token prediction, 2025. URLhttps://arxiv.org/abs/2504.15266
-
[25]
OpenAI, :, Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, Alex Iftimie, Alex Karpenko, Alex Tachard Passos, Alexander Neitz, Alexander Prokofiev, Alexander Wei, Alli- son Tam, Ally Bennett, Ananya Kumar, Andre Saraiva, Andrea Vallone, Andrew Duberstein, Andrew Kond...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with human feedback,...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[27]
Deepak Pathak, Pulkit Agrawal, Alexei A. Efros, and Trevor Darrell. Curiosity-driven ex- ploration by self-supervised prediction. In Doina Precup and Yee Whye Teh (eds.),Pro- ceedings of the 34th International Conference on Machine Learning, volume 70 ofPro- ceedings of Machine Learning Research, pp. 2778–2787. PMLR, 06–11 Aug 2017. URL https://proceeding...
work page 2017
-
[28]
Qwq-32b: Embracing the power of reinforcement learning, March 2025
Qwen. Qwq-32b: Embracing the power of reinforcement learning, March 2025. URLhttps: //qwenlm.github.io/blog/qwq-32b/
work page 2025
-
[29]
Nicolas Le Roux, Marc G. Bellemare, Jonathan Lebensold, Arnaud Bergeron, Joshua Greaves, Alex Fr´echette, Carolyne Pelletier, Eric Thibodeau-Laufer, S ´andor Toth, and Sam Work. Ta- pered off-policy reinforce: Stable and efficient reinforcement learning for llms, 2025. URL https://arxiv.org/abs/2503.14286
-
[30]
Trust Region Policy Optimization
John Schulman, Sergey Levine, Philipp Moritz, Michael I. Jordan, and Pieter Abbeel. Trust region policy optimization, 2017. URLhttps://arxiv.org/abs/1502.05477
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[31]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms, 2017. URLhttps://arxiv.org/abs/1707.06347
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[32]
High-Dimensional Continuous Control Using Generalized Advantage Estimation
John Schulman, Philipp Moritz, Sergey Levine, Michael Jordan, and Pieter Abbeel. High- dimensional continuous control using generalized advantage estimation, 2018. URLhttps: //arxiv.org/abs/1506.02438
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[33]
State entropy maximization with random encoders for efficient exploration, 2021
Younggyo Seo, Lili Chen, Jinwoo Shin, Honglak Lee, Pieter Abbeel, and Kimin Lee. State entropy maximization with random encoders for efficient exploration, 2021. URLhttps: //arxiv.org/abs/2102.09430
-
[34]
Deterministic policy gradient algorithms
David Silver, Guy Lever, Nicolas Heess, Thomas Degris, Daan Wierstra, and Martin Ried- miller. Deterministic policy gradient algorithms. In Eric P. Xing and Tony Jebara (eds.),Pro- ceedings of the 31st International Conference on Machine Learning, volume 32 ofProceedings of Machine Learning Research, pp. 387–395, Bejing, China, 22–24 Jun 2014. PMLR. URL h...
work page 2014
-
[35]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling llm test-time com- pute optimally can be more effective than scaling model parameters, 2024. URLhttps: //arxiv.org/abs/2408.03314
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
Outcome-based exploration for llm reasoning,
Yuda Song, Julia Kempe, and Remi Munos. Outcome-based exploration for llm reasoning,
- [37]
-
[38]
Richard S. Sutton and Andrew G. Barto.Reinforcement Learning: An Introduction. A Bradford Book, Cambridge, MA, USA, 2018. ISBN 0262039249
work page 2018
-
[39]
Sutton, David McAllester, Satinder Singh, and Yishay Mansour
Richard S. Sutton, David McAllester, Satinder Singh, and Yishay Mansour. Policy gra- dient methods for reinforcement learning with function approximation. InProceedings of the 13th International Conference on Neural Information Processing Systems, NIPS’99, pp. 1057–1063, Cambridge, MA, USA, 1999. MIT Press
work page 1999
-
[40]
Optimizing language models for inference time objectives using reinforcement learning, 2025
Yunhao Tang, Kunhao Zheng, Gabriel Synnaeve, and R ´emi Munos. Optimizing language models for inference time objectives using reinforcement learning, 2025. URLhttps:// arxiv.org/abs/2503.19595
-
[41]
Sample Efficient Actor-Critic with Experience Replay
Ziyu Wang, Victor Bapst, Nicolas Heess, V olodymyr Mnih, Remi Munos, Koray Kavukcuoglu, and Nando de Freitas. Sample efficient actor-critic with experience replay, 2017. URL https://arxiv.org/abs/1611.01224
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[42]
Ronald J. Williams. Simple statistical gradient-following algorithms for connectionist re- inforcement learning.Mach. Learn., 8(3–4):229–256, May 1992. ISSN 0885-6125. doi: 10.1007/BF00992696. URLhttps://doi.org/10.1007/BF00992696
-
[43]
The invisible leash: Why RLVR may not escape its origin.arXiv preprint arXiv:2507.14843,
Fang Wu, Weihao Xuan, Ximing Lu, Zaid Harchaoui, and Yejin Choi. The invisible leash: Why rlvr may not escape its origin, 2025. URLhttps://arxiv.org/abs/2507.14843
-
[44]
Younis, Rodrigo Perez-Vicente, John U
Omar G. Younis, Rodrigo Perez-Vicente, John U. Balis, Will Dudley, Alex Davey, and Jordan K Terry. Minari, September 2024. URLhttps://github.com/ Farama-Foundation/Minari
work page 2024
-
[45]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guangming Sheng, Yuxuan Tong, Chi Zhang, Mofan Zhang, Wang Zhang, Hang Zhu, Jinhua Zhu, Jiaze Chen, Jiangjie Chen, Chengyi Wang, Hongli Yu, Yuxuan Song, Xiangpeng Wei, Hao Zhou, Jingjing Liu, W...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
Yang Yue, Zhiqi Chen, Rui Lu, Andrew Zhao, Zhaokai Wang, Yang Yue, Shiji Song, and Gao Huang. Does reinforcement learning really incentivize reasoning capacity in llms beyond the base model?, 2025. URLhttps://arxiv.org/abs/2504.13837
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[47]
Noveltybench: Evaluating language models for humanlike diver- sity, 2025
Yiming Zhang, Harshita Diddee, Susan Holm, Hanchen Liu, Xinyue Liu, Vinay Samuel, Barry Wang, and Daphne Ippolito. Noveltybench: Evaluating language models for humanlike diver- sity, 2025. URLhttps://arxiv.org/abs/2504.05228
-
[48]
Echo chamber: Rl post-training amplifies behaviors learned in pretraining, 2025
Rosie Zhao, Alexandru Meterez, Sham Kakade, Cengiz Pehlevan, Samy Jelassi, and Eran Malach. Echo chamber: Rl post-training amplifies behaviors learned in pretraining, 2025. URLhttps://arxiv.org/abs/2504.07912
-
[49]
Group Sequence Policy Optimization
Chujie Zheng, Shixuan Liu, Mingze Li, Xiong-Hui Chen, Bowen Yu, Chang Gao, Kai Dang, Yuqiong Liu, Rui Men, An Yang, Jingren Zhou, and Junyang Lin. Group sequence policy optimization, 2025. URLhttps://arxiv.org/abs/2507.18071. 15 A IMPLEMENTATIONDETAILS BabyAI and MiniGrid.For BabyAI tasks, the policy conditions on the grid image, the agent’s direction emb...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.