Structured and Abstractive Reasoning on Multi-modal Relational Knowledge Images
Pith reviewed 2026-05-18 04:29 UTC · model grok-4.3
The pith
Two-stage training on synthetic relational images enables smaller MLLMs to outperform GPT-4o in abstractive reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
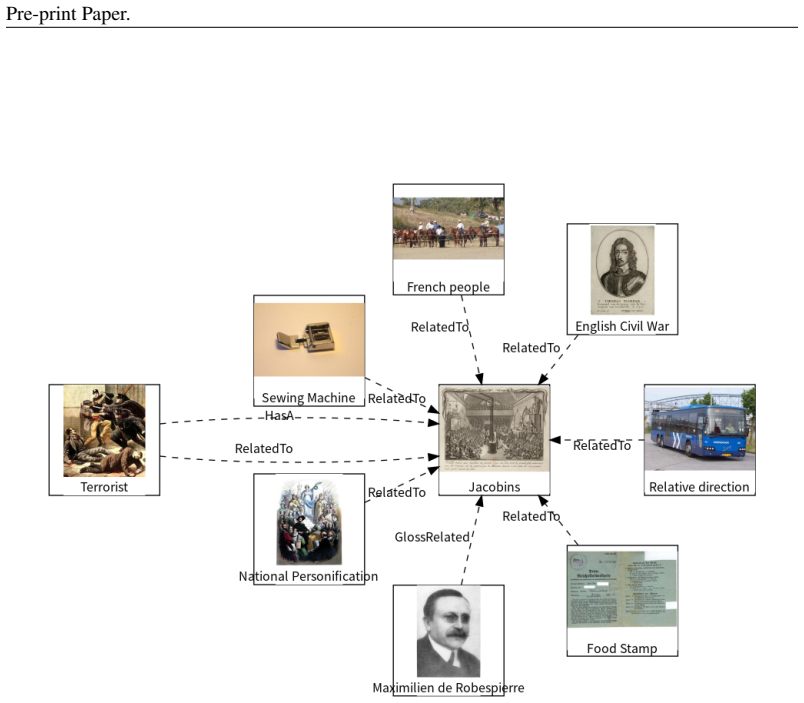
The authors introduce an automatic STAR data engine that synthesizes images with multi-modal relational knowledge and produces multi-modal instruction data containing reliable chain-of-thought thinking for various STAR tasks. They pair this with a comprehensive two-stage capability enhancement training framework and tailored evaluation protocols. Experiments on the resulting STAR-64K dataset demonstrate that the framework allows smaller 3B and 7B models to significantly outperform GPT-4o across multiple STAR tasks, with additional analysis of design effectiveness, data transferability, and scalability.
What carries the argument
The automatic STAR data engine that creates synthetic images and chain-of-thought annotations for multi-modal relational knowledge, together with the two-stage capability enhancement training framework.
If this is right
- Smaller open-source MLLMs can surpass much larger proprietary models on structured abstractive reasoning from images.
- Synthetic data generation can supply large volumes of reliable chain-of-thought supervision for under-explored multi-modal tasks.
- Task-specific evaluation protocols can be used to measure different aspects of relational reasoning performance.
- Performance gains from the framework hold across multiple model sizes and show signs of scaling with additional data.
Where Pith is reading between the lines
- The synthetic data pipeline could be adapted to generate training examples for other forms of abstract visual reasoning beyond relational structures.
- If the generated data generalizes well, similar engines might reduce dependence on expensive human annotation for multi-modal reasoning benchmarks.
- The two-stage framework might transfer to real-world applications that require understanding complex relationships in diagrams or scene graphs.
Load-bearing premise
The automatic STAR data engine produces images and chain-of-thought annotations that are high-quality, unbiased, and representative of genuine abstractive relational reasoning without introducing artifacts that artificially boost measured performance.
What would settle it
An independent test set of human-created multi-modal relational knowledge images on which the enhanced 3B/7B models show no improvement over GPT-4o or baseline models would falsify the central claim.
Figures













read the original abstract
Understanding and reasoning with abstractive information from the visual modality presents significant challenges for current multi-modal large language models (MLLMs). Among the various forms of abstractive information, Multi-Modal Relational Knowledge (MMRK), which represents abstract relational structures between multi-modal entities using node-edge formats, remains largely under-explored. In particular, STructured and Abstractive Reasoning (STAR) on such data has received little attention from the research community. To bridge the dual gaps in large-scale high-quality data and capability enhancement methodologies, this paper makes the following key contributions: (i). An automatic STAR data engine capable of synthesizing images with MMRK to build multi-modal instruction data with reliable chain-of-thought thinking for various STAR tasks and (ii). A comprehsive two-stage capability enhancement training framework, accompanied by a suite of evaluation protocols tailored to different STAR tasks. Based upon these contributions, we introduce STAR-64K, a dataset comprising 64K high-quality multi-modal instruction samples, and conduct experiments across 5 open-source MLLMs. Experimental results show that our two-stage enhancement framework enables smaller 3B/7B models to significantly outperform GPT-4o in STAR. Additionally, we provide in-depth analysis regarding the effectiveness of various designs, data transferability, and scalability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces an automatic STAR data engine for synthesizing images containing Multi-Modal Relational Knowledge (MMRK) structures in node-edge format along with reliable chain-of-thought annotations. It constructs the STAR-64K dataset of 64K multi-modal instruction samples and proposes a two-stage capability enhancement training framework with tailored evaluation protocols. Experiments on five open-source MLLMs show that fine-tuned 3B/7B models significantly outperform GPT-4o on STAR tasks.
Significance. If the synthetic data generation avoids systematic artifacts and the evaluations are robust, the result would indicate that targeted two-stage training on structured relational reasoning data can enable smaller MLLMs to exceed much larger general models on abstractive multi-modal tasks, supporting more efficient specialization of vision-language models.
major comments (2)
- [Abstract and §4] Abstract and §4 (Experiments): The headline claim that 3B/7B models after two-stage training significantly outperform GPT-4o rests on the automatic STAR data engine producing 64K samples free of distributional cues or simplifications. The abstract implies rule-based or template-driven generation of MMRK structures and CoT traces; without explicit human validation or OOD test sets referenced, it remains possible that fine-tuned models exploit regularities absent from zero-shot GPT-4o evaluation, rendering the gap an artifact of data construction rather than a genuine advance.
- [§3.1] §3.1 (Data Engine): The description of how node-edge MMRK structures are rendered into images and how step-by-step CoT annotations are automatically produced lacks sufficient detail on quality controls, bias mitigation, or verification against genuine abstractive reasoning. This is load-bearing because the entire performance comparison depends on the training distribution being representative.
minor comments (2)
- [Abstract] Abstract: 'comprehsive' is a typo and should read 'comprehensive'.
- [§5] §5 (Analysis): Clarify whether data transferability and scalability experiments include controls for dataset size or task difficulty to isolate the contribution of the two-stage framework.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive feedback on our manuscript. The concerns regarding potential artifacts in the synthetic STAR-64K dataset and the level of detail in the data engine description are important for establishing the validity of our claims. We address each point below and commit to revisions that strengthen the presentation of our methods and results without altering the core contributions.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): The headline claim that 3B/7B models after two-stage training significantly outperform GPT-4o rests on the automatic STAR data engine producing 64K samples free of distributional cues or simplifications. The abstract implies rule-based or template-driven generation of MMRK structures and CoT traces; without explicit human validation or OOD test sets referenced, it remains possible that fine-tuned models exploit regularities absent from zero-shot GPT-4o evaluation, rendering the gap an artifact of data construction rather than a genuine advance.
Authors: We appreciate the referee's emphasis on this issue, as it directly impacts the interpretation of our results. The STAR data engine employs extensive randomization across node attributes, relation types, visual layouts, and image rendering parameters to reduce systematic distributional cues. CoT traces are generated deterministically from the underlying MMRK graph structures rather than through templated language, ensuring they capture genuine step-by-step relational reasoning. While the initial submission did not detail human validation (due to the scale of 64K samples), we conducted automated consistency and logical coherence checks. In the revised manuscript, we will add an explicit subsection on bias mitigation strategies, randomization protocols, and any OOD test evaluations performed. We believe these additions will clarify that the performance advantage arises from the two-stage training on structured data rather than artifacts. revision: partial
-
Referee: [§3.1] §3.1 (Data Engine): The description of how node-edge MMRK structures are rendered into images and how step-by-step CoT annotations are automatically produced lacks sufficient detail on quality controls, bias mitigation, or verification against genuine abstractive reasoning. This is load-bearing because the entire performance comparison depends on the training distribution being representative.
Authors: We agree that §3.1 requires expansion to fully address these aspects. The current description outlines the high-level pipeline but omits granular details on rendering variations and CoT verification. In the revised version, we will substantially expand this section to include: (i) specifics on the image rendering process with randomization of visual elements to promote diversity; (ii) the algorithmic steps for extracting reliable CoT annotations directly from MMRK graphs; and (iii) quality control measures such as automated bias detection and consistency verification. These additions will demonstrate that the training distribution supports genuine abstractive reasoning capabilities rather than superficial patterns. revision: yes
Circularity Check
Empirical data synthesis and training framework with no self-referential derivations or fitted predictions.
full rationale
The paper describes an automatic STAR data engine for synthesizing 64K multi-modal instruction samples with MMRK images and chain-of-thought annotations, followed by a two-stage training framework evaluated on open-source MLLMs. The central claim rests on experimental outcomes showing performance gains for 3B/7B models over GPT-4o, without any equations, first-principles derivations, or parameter fits that reduce to the inputs by construction. No self-citation chains, uniqueness theorems, or ansatzes are invoked in a load-bearing manner within the abstract or described contributions; the work is self-contained as an empirical contribution introducing new data and protocols.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
An automatic STAR data engine capable of synthesizing images with MMRK... two-stage capability enhancement training framework
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
STAR-64K... 8 seed tasks (EC, RC, IC, TC, SD, ED, ER, RR)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Visualsem: a high-quality knowledge graph for vision and language.CoRR, abs/2008.09150,
Houda Alberts, Teresa Huang, Yash Deshpande, Yibo Liu, Kyunghyun Cho, Clara Vania, and Iacer Calixto. Visualsem: a high-quality knowledge graph for vision and language.CoRR, abs/2008.09150,
-
[2]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical report.ar...
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Pan, Ningyu Zhang, and Huajun Chen
Zhuo Chen, Yichi Zhang, Yin Fang, Yuxia Geng, Lingbing Guo, Xiang Chen, Qian Li, Wen Zhang, Jiaoyan Chen, Yushan Zhu, Jiaqi Li, Xiaoze Liu, Jeff Z. Pan, Ningyu Zhang, and Huajun Chen. Knowledge graphs meet multi-modal learning: A comprehensive survey.CoRR, abs/2402.05391,
-
[4]
Chaoyou Fu, Yifan Zhang, Shukang Yin, Bo Li, Xinyu Fang, Sirui Zhao, Haodong Duan, Xing Sun, Ziwei Liu, Liang Wang, Caifeng Shan, and Ran He. Mme-survey: A comprehensive survey on evaluation of multimodal llms.CoRR, abs/2411.15296,
-
[5]
arXiv preprint arXiv:2411.16594 , year=
Dawei Li, Bohan Jiang, Liangjie Huang, Alimohammad Beigi, Chengshuai Zhao, Zhen Tan, Amrita Bhattacharjee, Yuxuan Jiang, Canyu Chen, Tianhao Wu, Kai Shu, Lu Cheng, and Huan Liu. From generation to judgment: Opportunities and challenges of llm-as-a-judge.arXiv preprint arXiv: 2411.16594,
-
[6]
Ye Liu, Hui Li, Alberto García-Durán, Mathias Niepert, Daniel Oñoro-Rubio, and David S
URLhttps:// llava-vl.github.io/blog/2024-01-30-llava-next/. Ye Liu, Hui Li, Alberto García-Durán, Mathias Niepert, Daniel Oñoro-Rubio, and David S. Rosen- blum. MMKG: multi-modal knowledge graphs. InESWC, volume 11503 ofLecture Notes in Computer Science, pp. 459–474. Springer,
work page 2024
-
[7]
OpenAI. GPT-4 technical report.CoRR, abs/2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
URLhttps://arxiv.org/abs/2410.21276. Haojie Pan, Yuzhou Zhang, Zepeng Zhai, Ruiji Fu, Ming Liu, Yangqiu Song, Zhongyuan Wang, and Bing Qin. Kuaipedia: a large-scale multi-modal short-video encyclopedia.CoRR, abs/2211.00732,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Shezheng Song, Xiaopeng Li, and Shasha Li. How to bridge the gap between modalities: A com- prehensive survey on multimodal large language model.CoRR, abs/2311.07594,
-
[10]
URLhttps://arxiv.org/abs/2507.20804. Zirui Wang, Mengzhou Xia, Luxi He, Howard Chen, Yitao Liu, Richard Zhu, Kaiqu Liang, Xindi Wu, Haotian Liu, Sadhika Malladi, Alexis Chevalier, Sanjeev Arora, and Danqi Chen. Charxiv: Charting gaps in realistic chart understanding in multimodal llms. InNeurIPS,
-
[11]
doi:10.48550/arXiv.1909.03193 , abstract =
Liang Yao, Chengsheng Mao, and Yuan Luo. KG-BERT: BERT for knowledge graph completion. CoRR, abs/1909.03193,
-
[12]
VideoLLaMA 3: Frontier Multimodal Foundation Models for Image and Video Understanding
Xiang Yue, Yuansheng Ni, Kai Zhang, Tianyu Zheng, Ruoqi Liu, Ge Zhang, Samuel Stevens, Dongfu Jiang, Weiming Ren, Yuxuan Sun, Cong Wei, Botao Yu, Ruibin Yuan, Renliang Sun, Ming Yin, Boyuan Zheng, Zhenzhu Yang, Yibo Liu, Wenhao Huang, Huan Sun, Yu Su, and Wenhu Chen. Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for exp...
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
ACM, 2024b. 12 Pre-print Paper. Yichi Zhang, Zhuo Chen, Lingbing Guo, Yajing Xu, Binbin Hu, Ziqi Liu, Wen Zhang, and Huajun Chen. Multiple heads are better than one: Mixture of modality knowledge experts for entity representation learning. InICLR. OpenReview.net, 2025c. Yichi Zhang, Zhuo Chen, Lingbing Guo, Yajing Xu, Min Zhang, Wen Zhang, and Huajun Chen...
-
[14]
LlamaFactory: Unified Efficient Fine-Tuning of 100+ Language Models
Association for Computational Linguis- tics. URLhttp://arxiv.org/abs/2403.13372. Deyao Zhu, Jun Chen, Xiaoqian Shen, Xiang Li, and Mohamed Elhoseiny. Minigpt-4: Enhancing vision-language understanding with advanced large language models,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models
URLhttps:// arxiv.org/abs/2304.10592. Hongyan Zhu, Shuai Qin, Min Su, Chengzhi Lin, Anjie Li, and Junfeng Gao. Harnessing large vision and language models in agriculture: A review.CoRR, abs/2407.19679,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Connector-s: A survey of connectors in multi-modal large language models.CoRR, abs/2502.11453,
Xun Zhu, Zheng Zhang, Xi Chen, Yiming Shi, Miao Li, and Ji Wu. Connector-s: A survey of connectors in multi-modal large language models.CoRR, abs/2502.11453,
-
[17]
Table 3: Statistical information about the MMKG data source used in our data engine. Dataset Entity Relation Triple Data Source FB15K-237 14541 237 310116 FreeBase MKG-Y 15000 16 26638 Y AGO VisualSem 89896 13 1481007 Wikipedia, ImageNet, BabelNet A DETAILS OF THEDATAENGINE ANDTRAININGPIPELINE A.1 DETAILS OF OURDATASOURCE We present the detailed informati...
work page 2008
-
[18]
and SimPO (Meng et al., 2024), are also employed in stage
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.