DVPO: Distributional Value Modeling-based Policy Optimization for LLM Post-Training
Pith reviewed 2026-05-17 01:42 UTC · model grok-4.3
The pith
Token-level value distributions with asymmetric risk shaping enable more robust and generalizable LLM policies under noisy supervision.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
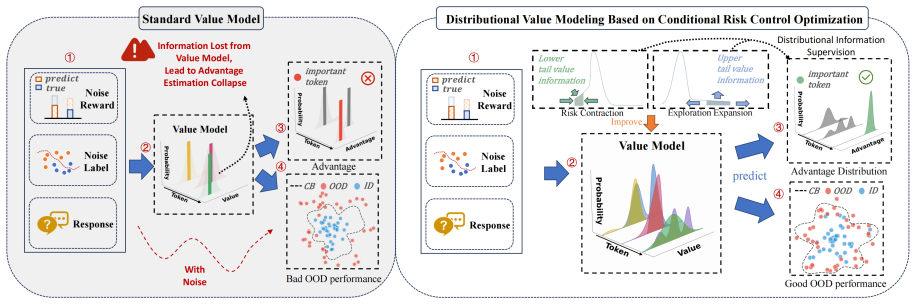
DVPO is a new RL framework that combines conditional risk theory with distributional value modeling to learn token-level value distributions, applying asymmetric risk regularization that contracts the lower tail to dampen noisy negative deviations while expanding the upper tail to preserve exploratory diversity, consistently outperforming PPO, GRPO, and robust Bellman-based PPO across experiments in multi-turn dialogue, math reasoning, and scientific QA under noisy supervision.
What carries the argument
Token-level distributional value modeling with asymmetric risk regularization that contracts lower tails and expands upper tails
Load-bearing premise
That token-level distributional modeling combined with asymmetric tail shaping will deliver fine-grained supervision that improves both robustness and generalization without introducing new instabilities or overfitting to the specific noise patterns in the test environments.
What would settle it
A controlled experiment using a new noise type, such as symmetric random reward perturbations on an unseen task, where DVPO shows no advantage or reduced stability relative to PPO baselines.
Figures








read the original abstract
Reinforcement learning (RL) has shown strong performance in LLM post-training, but real-world deployment often involves noisy or incomplete supervision. In such settings, complex and unreliable supervision signals can destabilize training and harm generalization. While existing approaches such as worst-case optimization (e.g., RFQI, CQL) and mean-based methods (e.g., PPO, GRPO) can improve stability, they often overlook generalization and may produce overly conservative policies, leading to uneven performance across diverse real scenarios. To this end, we introduce DVPO (Distributional Value Modeling with Risk-aware Policy Optimization), a new RL framework that combines conditional risk theory with distributional value modeling to better balance robustness and generalization. DVPO learns token-level value distributions to provide fine-grained supervision, and applies an asymmetric risk regularization to shape the distribution tails: it contracts the lower tail to dampen noisy negative deviations, while expanding the upper tail to preserve exploratory diversity. Across extensive experiments and analysis in multi-turn dialogue, math reasoning, and scientific QA, DVPO consistently outperforms PPO, GRPO, and robust Bellman-based PPO under noisy supervision, showing its potential for LLM post-training in the real-world.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces DVPO, a distributional RL framework for LLM post-training under noisy supervision. It learns token-level value distributions and applies asymmetric risk regularization that contracts the lower tail while expanding the upper tail, drawing on conditional risk theory. The central empirical claim is consistent outperformance versus PPO, GRPO, and robust Bellman-based PPO across multi-turn dialogue, math reasoning, and scientific QA tasks.
Significance. If the reported gains are robust to controls, the combination of token-level distributional modeling and tail-specific risk shaping could improve stability and generalization in real-world LLM alignment where supervision is unreliable. This extends risk-sensitive RL ideas to the LLM setting in a way that directly targets the robustness-exploration trade-off.
major comments (2)
- Experiments section: the claim of consistent outperformance under noisy supervision is load-bearing, yet the manuscript provides no details on the exact noise models, number of independent runs, statistical significance tests, or ablation controls that isolate asymmetric tail shaping from plain distributional value modeling.
- Method section (asymmetric risk regularization): the description of contracting the lower tail and expanding the upper tail lacks an explicit equation or risk-measure definition, making it impossible to verify whether the shaping is parameter-free or whether it risks overfitting to the particular noise patterns used in the reported tasks.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments identify key areas where additional rigor and clarity will strengthen the manuscript. We address each major comment below and commit to revisions that improve verifiability without altering the core claims.
read point-by-point responses
-
Referee: Experiments section: the claim of consistent outperformance under noisy supervision is load-bearing, yet the manuscript provides no details on the exact noise models, number of independent runs, statistical significance tests, or ablation controls that isolate asymmetric tail shaping from plain distributional value modeling.
Authors: We agree that these details are essential for substantiating the central empirical claim. In the revised manuscript we will expand the Experiments section to explicitly describe the noise models (synthetic perturbations including token-level label noise and solution corruption at controlled rates across the dialogue, math, and QA benchmarks). We will report all main results as means and standard deviations over five independent random seeds. Statistical significance will be evaluated with paired t-tests and reported p-values. We will also add ablation tables that directly compare the full DVPO objective against a distributional-value-only baseline (identical architecture and training but without the asymmetric tail regularization). These additions will isolate the contribution of the tail-shaping component and allow readers to assess robustness under noisy supervision. revision: yes
-
Referee: Method section (asymmetric risk regularization): the description of contracting the lower tail and expanding the upper tail lacks an explicit equation or risk-measure definition, making it impossible to verify whether the shaping is parameter-free or whether it risks overfitting to the particular noise patterns used in the reported tasks.
Authors: We acknowledge that the current textual description is insufficient for exact reproduction and verification. In the revised Method section we will insert a formal definition of the asymmetric risk regularization term, expressed as an additive objective that applies distinct conditional risk measures to the lower and upper tails of the learned token-level value distribution (drawing directly on the conditional risk theory referenced in the paper). The formulation will include the quantile thresholds and the balancing coefficient, together with a brief analysis of how these hyperparameters are chosen and their sensitivity across noise levels. This explicit equation will clarify the degree of parameterization and enable assessment of potential overfitting to the specific noise patterns used in our experiments. revision: yes
Circularity Check
No significant circularity; DVPO presented as independent framework with external empirical validation
full rationale
The paper introduces DVPO as a novel RL framework that combines conditional risk theory with distributional value modeling and asymmetric tail shaping for token-level supervision in LLM post-training. The abstract and described method present this as an original construction validated through experiments on multi-turn dialogue, math reasoning, and scientific QA, with no visible equations, derivations, or self-citations that reduce the central claims to fitted inputs or tautological definitions by construction. Claims of outperformance rest on external empirical tests rather than self-referential reductions, rendering the derivation self-contained.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Asymmetric risk regularization on value distribution tails
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
asymmetric risk regularization to shape the distribution tails: it contracts the lower tail to dampen noisy negative deviations, while expanding the upper tail to preserve exploratory diversity
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
LShape = E[ReLU(Var(Θ;Iα)−Var(Θ′;Iα)) + ReLU(Var(Θ′;Iβ)−Var(Θ;Iβ))]
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
- [1]
-
[2]
A Distributional Perspective on Reinforcement Learning
A distributional perspective on reinforcement learning.Preprint, arXiv:1707.06887. Tao Bian and Zhong-Ping Jiang
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Continuous-Time Robust Dynamic Programming
Continuous- time robust dynamic programming.Preprint, arXiv:1809.05867. Angelo Caregnato-Neto, Luciano Cavalcante Siebert, Arkady Zgonnikov, Marcos Ricardo Omena de Al- buquerque Maximo, and Rubens Junqueira Magal- hães Afonso
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Will Dabney, Georg Ostrovski, David Silver, and Rémi Munos
ARMCHAIR: integrated inverse reinforcement learning and model predictive con- trol for human-robot collaboration.arXiv e-prints, arXiv:2402.19128. Will Dabney, Georg Ostrovski, David Silver, and Rémi Munos
-
[5]
Implicit Quantile Networks for Distributional Reinforcement Learning
Implicit quantile networks for distributional reinforcement learning.Preprint, arXiv:1806.06923. Will Dabney, Mark Rowland, Marc G. Bellemare, and Rémi Munos
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Distributional Reinforcement Learning with Quantile Regression
Distributional reinforce- ment learning with quantile regression.Preprint, arXiv:1710.10044. Yiwen Ding, Zhiheng Xi, Wei He, Zhuoyuan Li, Yitao Zhai, Xiaowei Shi, Xunliang Cai, Tao Gui, Qi Zhang, and Xuanjing Huang
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Mitigating tail narrow- ing in llm self-improvement via socratic-guided sam- pling.Preprint, arXiv:2411.00750. Nicolai Dorka
-
[8]
Wei Geng, Baidi Xiao, Rongpeng Li, Ning Wei, Dong Wang, and Zhifeng Zhao
Quantile regression for dis- tributional reward models in rlhf.Preprint, arXiv:2409.10164. Wei Geng, Baidi Xiao, Rongpeng Li, Ning Wei, Dong Wang, and Zhifeng Zhao
-
[9]
Noise distribution decomposition based multi-agent distributional rein- forcement learning.Preprint, arXiv:2312.07025. Alex Havrilla and Maia Iyer
-
[10]
Understanding the effect of noise in llm training data with algorithmic chains of thought.Preprint, arXiv:2402.04004. Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt
-
[11]
Measuring Mathematical Problem Solving With the MATH Dataset
Measuring mathematical problem solving with the math dataset.Preprint, arXiv:2103.03874. Jakob Kisiala
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Conditional Value-at-Risk: Theory and Applications
Conditional value-at-risk: Theory and applications.Preprint, arXiv:1511.00140. Aviral Kumar, Aurick Zhou, George Tucker, and Sergey Levine
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Conservative q-learning for offline reinforcement learning.Preprint, arXiv:2006.04779. 9 Aitor Lewkowycz, Anders Andreassen, David Dohan, Ethan Dyer, Henryk Michalewski, Vinay Ramasesh, Ambrose Slone, Cem Anil, Imanol Schlag, Theo Gutman-Solo, Yuhuai Wu, Behnam Neyshabur, Guy Gur-Ari, and Vedant Misra
-
[14]
Solving Quantitative Reasoning Problems with Language Models
Solving quan- titative reasoning problems with language models. Preprint, arXiv:2206.14858. Zongkai Liu, Fanqing Meng, Lingxiao Du, Zhixi- ang Zhou, Chao Yu, Wenqi Shao, and Qiaosheng Zhang
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Cpgd: Toward stable rule-based rein- forcement learning for language models.Preprint, arXiv:2505.12504. MiniMax, :, Aili Chen, Aonian Li, Bangwei Gong, Binyang Jiang, Bo Fei, Bo Yang, Boji Shan, Changqing Yu, Chao Wang, Cheng Zhu, Chengjun Xiao, Chengyu Du, Chi Zhang, Chu Qiao, Chun- hao Zhang, Chunhui Du, Congchao Guo, and 109 others
-
[16]
MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention
Minimax-m1: Scaling test-time com- pute efficiently with lightning attention.Preprint, arXiv:2506.13585. Arnab Nilim and Laurent El Ghaoui
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Robust rein- forcement learning using offline data.Preprint, arXiv:2208.05129. Roko Para ´c, Lorenzo Nodari, Leo Ardon, Daniel Furelos-Blanco, Federico Cerutti, and Alessandra Russo
-
[18]
Learning robust reward machines from noisy labels. InProceedings of the TwentyFirst Inter- national Conference on Principles of Knowledge Rep- resentation and Reasoning, KR-2024, page 909–919. International Joint Conferences on Artificial Intelli- gence Organization. Long Phan, Alice Gatti, Ziwen Han, Nathaniel Li, Josephina Hu, Hugh Zhang, Chen Bo Calvin...
work page 2024
-
[19]
Hu- manity’s last exam.Preprint, arXiv:2501.14249. John Schulman, Philipp Moritz, Sergey Levine, Michael Jordan, and Pieter Abbeel
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
High-Dimensional Continuous Control Using Generalized Advantage Estimation
High-dimensional continuous control using generalized advantage esti- mation.Preprint, arXiv:1506.02438. Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Deepseekmath: Pushing the limits of mathemati- cal reasoning in open language models.Preprint, arXiv:2402.03300. Laixi Shi and Yuejie Chi
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Yi Su, Dian Yu, Linfeng Song, Juntao Li, Haitao Mi, Zhaopeng Tu, Min Zhang, and Dong Yu
Distributionally robust model-based offline reinforcement learning with near-optimal sample complexity.Preprint, arXiv:2208.05767. Yi Su, Dian Yu, Linfeng Song, Juntao Li, Haitao Mi, Zhaopeng Tu, Min Zhang, and Dong Yu
-
[23]
Crossing the reward bridge: Expanding rl with ver- ifiable rewards across diverse domains.Preprint, arXiv:2503.23829. M-A-P Team, Xinrun Du, Yifan Yao, Kaijing Ma, Bingli Wang, Tianyu Zheng, Kang Zhu, Minghao Liu, Yim- ing Liang, Xiaolong Jin, Zhenlin Wei, Chujie Zheng, Kaixing Deng, Shuyue Guo, Shian Jia, Sichao Jiang, Yiyan Liao, Rui Li, Qinrui Li, and ...
-
[24]
SuperGPQA: Scaling LLM Evaluation across 285 Graduate Disciplines
Supergpqa: Scaling llm evaluation across 285 gradu- ate disciplines.Preprint, arXiv:2502.14739. Yue Wang, Alvaro Velasquez, George Atia, Ashley Prater-Bennette, and Shaofeng Zou
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Robust average-reward markov decision processes.Preprint, arXiv:2301.00858. Jason Wei, Nguyen Karina, Hyung Won Chung, Yunxin Joy Jiao, Spencer Papay, Amelia Glaese, John Schulman, and William Fedus
-
[26]
Measuring short-form factuality in large language models
Mea- suring short-form factuality in large language models. Preprint, arXiv:2411.04368. Liang Wen, Yunke Cai, Fenrui Xiao, Xin He, Qi An, Zhenyu Duan, Yimin Du, Junchen Liu, Lifu Tang, Xiaowei Lv, Haosheng Zou, Yongchao Deng, Shousheng Jia, and Xiangzheng Zhang
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Light- r1: Curriculum sft, dpo and rl for long cot from scratch and beyond.Preprint, arXiv:2503.10460. Zhiheng Xi, Wenxiang Chen, Boyang Hong, Senjie Jin, Rui Zheng, Wei He, Yiwen Ding, Shichun Liu, Xin Guo, Junzhe Wang, Honglin Guo, Wei Shen, Xiaoran Fan, Yuhao Zhou, Shihan Dou, Xiao Wang, Xinbo Zhang, Peng Sun, Tao Gui, and 2 others. 2024a. Training lar...
-
[28]
Qwen3 technical report.Preprint, arXiv:2505.09388. Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guangming Sheng, Yuxuan Tong, Chi Zhang, Mofan Zhang, Wang Zhang, and 16 others
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Dapo: An open-source llm re- inforcement learning system at scale.Preprint, arXiv:2503.14476. Moritz A. Zanger, Wendelin Böhmer, and Matthijs T. J. Spaan
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Jin Peng Zhou, Kaiwen Wang, Jonathan Chang, Zhaolin Gao, Nathan Kallus, Kilian Q
Diverse projection ensembles for distributional reinforcement learning.Preprint, arXiv:2306.07124. Jin Peng Zhou, Kaiwen Wang, Jonathan Chang, Zhaolin Gao, Nathan Kallus, Kilian Q. Weinberger, Kianté Brantley, and Wen Sun
-
[31]
A Additional Details for VRPO A.1 Pseudocode The full algorithm of VRPO is detailed in Algo- rithm
q♯: Provably opti- mal distributional rl for llm post-training.Preprint, arXiv:2502.20548. A Additional Details for VRPO A.1 Pseudocode The full algorithm of VRPO is detailed in Algo- rithm
-
[32]
B Mathematical Analysis of Stability and Generalization in Robust Bellman PPO and DVPO This section provides a rigorous mathematical derivation of the training dynamics for Standard PPO, Robust Bellman PPO, and our DVPO frame- work. We demonstrate why the pessimistic contrac- tion of Robust Bellman PPO leads to stability at the cost of generalization, and...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.