Recognition: no theorem link
Training Multi-Image Vision Agents via End2End Reinforcement Learning
Pith reviewed 2026-05-17 00:54 UTC · model grok-4.3
The pith
IMAgent learns effective tool use for multi-image reasoning through pure end-to-end reinforcement learning without supervised fine-tuning data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Equipped with two dedicated tools for visual reflection and verification, IMAgent trains a base VLM end-to-end via reinforcement learning. A two-layer motion trajectory masking strategy and tool-use reward gain produce an effective tool-use paradigm without any supervised fine-tuning data. The method reveals that tool usage enhances performance by maintaining attention on image content and reaches SOTA results on single- and multi-image benchmarks.
What carries the argument
Two-layer motion trajectory masking strategy together with tool-use reward gain, which together shape the reinforcement learning signal to develop and sustain tool-use behavior.
Load-bearing premise
The combination of visual reflection and verification tools with the specific masking and reward design will cause the base VLM to learn and maintain an effective tool-use policy through reinforcement learning alone.
What would settle it
An ablation experiment in which removing the two-layer masking or the tool-use reward gain causes the model to stop using the reflection tools and produces no improvement over the base VLM on multi-image tasks.
Figures
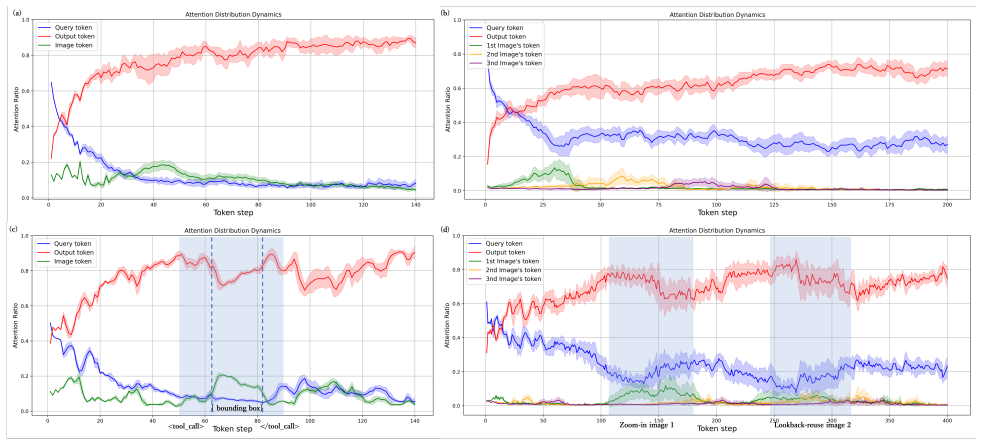


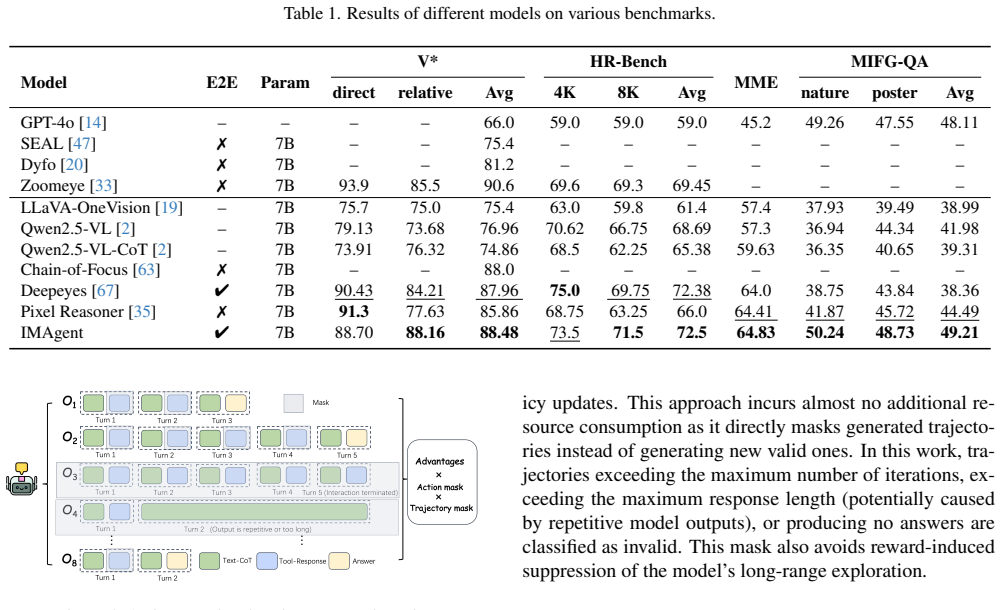




read the original abstract
Recent VLM-based agents aim to replicate OpenAI O3's "thinking with images" via tool use, yet most open-source methods restrict inputs to a single image, limiting their applicability to real-world multi-image QA tasks. To address this gap, we propose IMAgent, an open-source visual agent trained with end-to-end reinforcement learning for fine-grained single/multi-image reasoning. During inference, VLMs tend to gradually neglect visual inputs; to mitigate this issue, we design two dedicated tools for visual reflection and verification, enabling the model to actively refocus attention on image content. Beyond that, we, for the first time, reveal how tool usage enhances agent performance from an attention perspective. Equipped with a carefully designed two-layer motion trajectory masking strategy and tool-use reward gain, IMAgent acquires an effective tool-use paradigm through pure reinforcement learning, eliminating the need for costly supervised fine-tuning data. To further unleash the inherent tool-usage potential of the base VLM and fill data gaps, we construct a challenging, visually enriched multi-image QA dataset via multi-agent system. Extensive experiments validate that IMAgent achieves SOTA performance across mainstream single and multi-image benchmarks, and our in-depth analysis offers actionable insights for the community. Code and data will be released soon.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces IMAgent, a VLM-based agent for fine-grained single- and multi-image reasoning trained entirely via end-to-end reinforcement learning. It adds two dedicated tools (visual reflection and verification) to counteract gradual neglect of visual tokens, introduces a two-layer motion-trajectory masking strategy together with a tool-use reward gain, and claims that these components allow the base VLM to acquire an effective tool-use policy through pure RL without any supervised fine-tuning data. A multi-agent system is used to construct a visually enriched multi-image QA dataset, and the authors report SOTA results on mainstream single- and multi-image benchmarks while providing an attention-based analysis of why tool use improves performance.
Significance. If the performance claims and the causal contribution of the masking and reward components are substantiated by rigorous ablations and attention measurements, the work would constitute a meaningful step toward training multi-image VLM agents with minimal supervised data. The explicit attention-perspective analysis and the release of code and data would be additional strengths.
major comments (3)
- [§4] §4 (Experiments) and associated tables: The central SOTA claim and the assertion that the two-layer masking plus tool-use reward gain enable pure-RL acquisition of tool-use policy rest on performance numbers, error bars, and ablation tables that are not visible in the provided sections. Without these, it is impossible to verify whether the reported gains are robust or whether the masking and reward components are load-bearing.
- [§3.2] §3.2 (Method, attention analysis): The claim that tool usage enhances performance “from an attention perspective” and that the two-layer masking prevents gradual neglect of visual tokens requires quantitative attention-shift metrics or visualizations before and after the masking strategy; the current text supplies only qualitative description.
- [§3.1–3.3] §3.1–3.3 (Reward design and masking): The tool-use reward gain and the two-layer motion-trajectory masking are presented as key enablers of credit assignment across tool calls and image tokens, yet no ablation isolating each component (e.g., performance with/without masking, with/without reward gain) is shown; such ablations are necessary to support the “eliminating the need for costly supervised fine-tuning data” claim.
minor comments (2)
- [Abstract] The abstract states that code and data “will be released soon”; a concrete release plan or repository link should be added before publication.
- [§3.2] Notation for the two-layer masking (e.g., which layers correspond to which trajectory segments) should be defined explicitly in §3.2 with a small diagram or pseudocode.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and have revised the manuscript to provide the requested quantitative evidence, tables, and ablations.
read point-by-point responses
-
Referee: [§4] §4 (Experiments) and associated tables: The central SOTA claim and the assertion that the two-layer masking plus tool-use reward gain enable pure-RL acquisition of tool-use policy rest on performance numbers, error bars, and ablation tables that are not visible in the provided sections. Without these, it is impossible to verify whether the reported gains are robust or whether the masking and reward components are load-bearing.
Authors: We acknowledge the need for clear visibility of the supporting data. The full manuscript contains the SOTA results with error bars (from three independent runs) and ablation tables in Section 4. To improve accessibility, we have added a consolidated main-text table summarizing key metrics and component contributions, ensuring the robustness of the reported gains is directly verifiable. revision: yes
-
Referee: [§3.2] §3.2 (Method, attention analysis): The claim that tool usage enhances performance “from an attention perspective” and that the two-layer masking prevents gradual neglect of visual tokens requires quantitative attention-shift metrics or visualizations before and after the masking strategy; the current text supplies only qualitative description.
Authors: We agree that quantitative metrics strengthen the analysis. The revised manuscript now includes attention-shift metrics (average visual-token attention weight over reasoning steps) and before/after attention map visualizations. These additions quantify how the masking strategy counters visual neglect and how tool use alters attention distribution. revision: yes
-
Referee: [§3.1–3.3] §3.1–3.3 (Reward design and masking): The tool-use reward gain and the two-layer motion-trajectory masking are presented as key enablers of credit assignment across tool calls and image tokens, yet no ablation isolating each component (e.g., performance with/without masking, with/without reward gain) is shown; such ablations are necessary to support the “eliminating the need for costly supervised fine-tuning data” claim.
Authors: We concur that isolating each component is essential. We have added a dedicated ablation table in the revised manuscript comparing variants (no masking, no reward gain, and full model). The results demonstrate that both the two-layer masking and tool-use reward gain are necessary for successful pure-RL tool-use policy learning, directly supporting the claim regarding elimination of supervised fine-tuning data. revision: yes
Circularity Check
No circularity: empirical RL training with independent dataset and rewards
full rationale
The paper presents an empirical training procedure for a multi-image VLM agent using end-to-end RL, custom reflection/verification tools, two-layer motion trajectory masking, and a tool-use reward gain. No equations, derivations, or first-principles predictions are offered that reduce performance claims to fitted parameters or self-referential definitions. The dataset is constructed separately via a multi-agent system to address data gaps, and results are validated on external benchmarks. The central claim—that these components enable effective tool-use policy acquisition without SFT—rests on experimental outcomes rather than any self-definitional or fitted-input reduction, rendering the approach self-contained.
Axiom & Free-Parameter Ledger
free parameters (1)
- tool-use reward gain
axioms (1)
- domain assumption VLMs tend to gradually neglect visual inputs during inference
invented entities (1)
-
IMAgent
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Agentic ai: Autonomous intelligence for complex goals–a comprehensive survey.IEEe Access, 2025
Deepak Bhaskar Acharya, Karthigeyan Kuppan, and B Di- vya. Agentic ai: Autonomous intelligence for complex goals–a comprehensive survey.IEEe Access, 2025. 1
work page 2025
-
[2]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923, 2025. 5
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Meng Cao, Haoze Zhao, Can Zhang, Xiaojun Chang, Ian Reid, and Xiaodan Liang. Ground-r1: Incentivizing grounded visual reasoning via reinforcement learning.arXiv preprint arXiv:2505.20272, 2025. 1, 3
-
[4]
Jiajun Chai, Guojun Yin, Zekun Xu, Chuhuai Yue, Yi Jia, Siyu Xia, Xiaohan Wang, Jiwen Jiang, Xiaoguang Li, Chengqi Dong, Hang He, and Wei Lin. Rlfactory: A plug- and-play reinforcement learning post-training framework for llm multi-turn tool-use, 2025. 2
work page 2025
-
[5]
Deepseek-r1: Incentivizing reasoning capa- bility in llms via reinforcement learning, 2025
DeepSeek-AI. Deepseek-r1: Incentivizing reasoning capa- bility in llms via reinforcement learning, 2025. 2
work page 2025
-
[6]
Insight-v: Ex- ploring long-chain visual reasoning with multimodal large language models, 2025
Yuhao Dong, Zuyan Liu, Hai-Long Sun, Jingkang Yang, Winston Hu, Yongming Rao, and Ziwei Liu. Insight-v: Ex- ploring long-chain visual reasoning with multimodal large language models, 2025. 2
work page 2025
-
[7]
Retool: Reinforcement learning for strategic tool use in llms, 2025
Jiazhan Feng, Shijue Huang, Xingwei Qu, Ge Zhang, Yu- jia Qin, Baoquan Zhong, Chengquan Jiang, Jinxin Chi, and Wanjun Zhong. Retool: Reinforcement learning for strategic tool use in llms, 2025. 3
work page 2025
-
[8]
Video-r1: Reinforcing video reasoning in mllms, 2025
Kaituo Feng, Kaixiong Gong, Bohao Li, Zonghao Guo, Yibing Wang, Tianshuo Peng, Junfei Wu, Xiaoying Zhang, Benyou Wang, and Xiangyu Yue. Video-r1: Reinforcing video reasoning in mllms, 2025. 2
work page 2025
-
[9]
Xingyu Fu, Minqian Liu, Zhengyuan Yang, John Cor- ring, Yijuan Lu, Jianwei Yang, Dan Roth, Dinei Floren- cio, and Cha Zhang. Refocus: Visual editing as a chain of thought for structured image understanding.arXiv preprint arXiv:2501.05452, 2025. 1
-
[10]
Multi-modal agent tuning: Building a vlm-driven agent for efficient tool usage, 2025
Zhi Gao, Bofei Zhang, Pengxiang Li, Xiaojian Ma, Tao Yuan, Yue Fan, Yuwei Wu, Yunde Jia, Song-Chun Zhu, and Qing Li. Multi-modal agent tuning: Building a vlm-driven agent for efficient tool usage, 2025. 2
work page 2025
-
[11]
Webwatcher: Breaking new frontier of vision- language deep research agent, 2025
Xinyu Geng, Peng Xia, Zhen Zhang, Xinyu Wang, Qiuchen Wang, Ruixue Ding, Chenxi Wang, Jialong Wu, Yida Zhao, Kuan Li, Yong Jiang, Pengjun Xie, Fei Huang, and Jin- gren Zhou. Webwatcher: Breaking new frontier of vision- language deep research agent, 2025. 3
work page 2025
-
[12]
Tora: A tool-integrated reasoning agent for mathematical problem solving, 2024
Zhibin Gou, Zhihong Shao, Yeyun Gong, Yelong Shen, Yu- jiu Yang, Minlie Huang, Nan Duan, and Weizhu Chen. Tora: A tool-integrated reasoning agent for mathematical problem solving, 2024. 3
work page 2024
-
[13]
Xiaojun Guo, Runyu Zhou, Yifei Wang, Qi Zhang, Chen- heng Zhang, Stefanie Jegelka, Xiaohan Wang, Jiajun Chai, Guojun Yin, Wei Lin, and Yisen Wang. Ssl4rl: Revisit- ing self-supervised learning as intrinsic reward for visual- language reasoning, 2025. 2
work page 2025
-
[14]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perel- man, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Weli- hinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card. arXiv preprint arXiv:2410.21276, 2024. 5
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Mmsearch: Benchmarking the potential of large models as multi-modal search engines, 2024
Dongzhi Jiang, Renrui Zhang, Ziyu Guo, Yanmin Wu, Jiayi Lei, Pengshuo Qiu, Pan Lu, Zehui Chen, Chaoyou Fu, Guan- glu Song, Peng Gao, Yu Liu, Chunyuan Li, and Hongsheng Li. Mmsearch: Benchmarking the potential of large models as multi-modal search engines, 2024. 2
work page 2024
-
[16]
Dongzhi Jiang, Renrui Zhang, Ziyu Guo, Yanmin Wu, Jiayi Lei, Pengshuo Qiu, Pan Lu, Zehui Chen, Chaoyou Fu, Guan- glu Song, et al. Mmsearch: Benchmarking the potential of large models as multi-modal search engines.arXiv preprint arXiv:2409.12959, 2024. 1
-
[17]
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
Bowen Jin, Hansi Zeng, Zhenrui Yue, Jinsung Yoon, Sercan Arik, Dong Wang, Hamed Zamani, and Jiawei Han. Search- r1: Training llms to reason and leverage search engines with reinforcement learning.arXiv preprint arXiv:2503.09516,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Mini-o3: Scaling up reasoning patterns and interaction turns for visual search, 2025
Xin Lai, Junyi Li, Wei Li, Tao Liu, Tianjian Li, and Heng- shuang Zhao. Mini-o3: Scaling up reasoning patterns and interaction turns for visual search, 2025. 3
work page 2025
-
[19]
LLaVA-OneVision: Easy Visual Task Transfer
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Zi- wei Liu, et al. Llava-onevision: Easy visual task transfer. arXiv preprint arXiv:2408.03326, 2024. 5
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Geng Li, Jinglin Xu, Yunzhen Zhao, and Yuxin Peng. Dyfo: A training-free dynamic focus visual search for enhancing lmms in fine-grained visual understanding. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 9098–9108, 2025. 5, 6
work page 2025
-
[21]
Torl: Scaling tool-integrated rl, 2025
Xuefeng Li, Haoyang Zou, and Pengfei Liu. Torl: Scaling tool-integrated rl, 2025. 3
work page 2025
-
[22]
You Li, Heyu Huang, Chi Chen, Kaiyu Huang, Chao Huang, Zonghao Guo, Zhiyuan Liu, Jinan Xu, Yuhua Li, Ruix- uan Li, et al. Migician: Revealing the magic of free-form multi-image grounding in multimodal large language mod- els.arXiv preprint arXiv:2501.05767, 2025. 1, 4
-
[23]
Perception, reason, think, and plan: A survey on large multimodal reasoning models, 2025
Yunxin Li, Zhenyu Liu, Zitao Li, Xuanyu Zhang, Zhen- ran Xu, Xinyu Chen, Haoyuan Shi, Shenyuan Jiang, Xin- tong Wang, Jifang Wang, Shouzheng Huang, Xinping Zhao, Borui Jiang, Lanqing Hong, Longyue Wang, Zhuotao Tian, Baoxing Huai, Wenhan Luo, Weihua Luo, Zheng Zhang, Baotian Hu, and Min Zhang. Perception, reason, think, and plan: A survey on large multimo...
work page 2025
-
[24]
Modomodo: Multi-domain data mixtures for multimodal llm reinforcement learning,
Yiqing Liang, Jielin Qiu, Wenhao Ding, Zuxin Liu, James Tompkin, Mengdi Xu, Mengzhou Xia, Zhengzhong Tu, Laixi Shi, and Jiacheng Zhu. Modomodo: Multi-domain data mixtures for multimodal llm reinforcement learning,
-
[25]
Mibench: Evaluating multimodal large language models over multiple images.CoRR, 2024
Haowei Liu, Xi Zhang, Haiyang Xu, Yaya Shi, Chaoya Jiang, Ming Yan, Ji Zhang, Fei Huang, Chunfeng Yuan, Bing Li, et al. Mibench: Evaluating multimodal large language models over multiple images.CoRR, 2024. 1
work page 2024
-
[26]
Seg-zero: Reasoning-chain guided segmentation via cognitive reinforcement, 2025
Yuqi Liu, Bohao Peng, Zhisheng Zhong, Zihao Yue, Fanbin Lu, Bei Yu, and Jiaya Jia. Seg-zero: Reasoning-chain guided segmentation via cognitive reinforcement, 2025. 2
work page 2025
-
[27]
Visual- rft: Visual reinforcement fine-tuning, 2025
Ziyu Liu, Zeyi Sun, Yuhang Zang, Xiaoyi Dong, Yuhang Cao, Haodong Duan, Dahua Lin, and Jiaqi Wang. Visual- rft: Visual reinforcement fine-tuning, 2025. 2
work page 2025
-
[28]
Fanqing Meng, Lingxiao Du, Zongkai Liu, Zhixiang Zhou, Quanfeng Lu, Daocheng Fu, Tiancheng Han, Botian Shi, Wenhai Wang, Junjun He, Kaipeng Zhang, Ping Luo, Yu Qiao, Qiaosheng Zhang, and Wenqi Shao. Mm-eureka: Ex- ploring the frontiers of multimodal reasoning with rule-based reinforcement learning, 2025. 2
work page 2025
-
[29]
Thinking with images.https://openai.com/index/ thinking-with-images/, 2025
OpenAI. Thinking with images.https://openai.com/index/ thinking-with-images/, 2025. 1
work page 2025
-
[30]
Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Er- mon, Christopher D. Manning, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model, 2024. 2
work page 2024
-
[31]
Poster- Sum: a multimodal benchmark for scientific poster summa- rization
Rohit Saxena, Pasquale Minervini, and Frank Keller. Poster- sum: A multimodal benchmark for scientific poster summa- rization.arXiv preprint arXiv:2502.17540, 2025. 1, 4
-
[32]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models, 2024. 2
work page 2024
-
[33]
Haozhan Shen, Kangjia Zhao, Tiancheng Zhao, Ruochen Xu, Zilun Zhang, Mingwei Zhu, and Jianwei Yin. Zoom- eye: Enhancing multimodal llms with human-like zooming capabilities through tree-based image exploration. InPro- ceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 6613–6629, 2025. 5, 6
work page 2025
-
[34]
Joykirat Singh, Raghav Magazine, Yash Pandya, and Akshay Nambi. Agentic reasoning and tool integration for llms via reinforcement learning.arXiv preprint arXiv:2505.01441,
-
[35]
Pixel Reasoner: Incentivizing Pixel-Space Reasoning with Curiosity-Driven Reinforcement Learning
Alex Su, Haozhe Wang, Weiming Ren, Fangzhen Lin, and Wenhu Chen. Pixel reasoner: Incentivizing pixel-space rea- soning with curiosity-driven reinforcement learning.arXiv preprint arXiv:2505.15966, 2025. 1, 3, 5, 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
OpenThinkIMG: Learning to Think with Images via Visual Tool Reinforcement Learning
Zhaochen Su, Linjie Li, Mingyang Song, Yunzhuo Hao, Zhengyuan Yang, Jun Zhang, Guanjie Chen, Jiawei Gu, Jun- tao Li, Xiaoye Qu, et al. Openthinkimg: Learning to think with images via visual tool reinforcement learning.arXiv preprint arXiv:2505.08617, 2025. 1
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [37]
-
[38]
Mllm-tool: A mul- timodal large language model for tool agent learning, 2025
Chenyu Wang, Weixin Luo, Sixun Dong, Xiaohua Xuan, Zhengxin Li, Lin Ma, and Shenghua Gao. Mllm-tool: A mul- timodal large language model for tool agent learning, 2025. 2
work page 2025
-
[39]
Mathcoder: Seamless code integration in llms for enhanced mathematical reasoning, 2023
Ke Wang, Houxing Ren, Aojun Zhou, Zimu Lu, Sichun Luo, Weikang Shi, Renrui Zhang, Linqi Song, Mingjie Zhan, and Hongsheng Li. Mathcoder: Seamless code integration in llms for enhanced mathematical reasoning, 2023. 3
work page 2023
-
[40]
Qiuchen Wang, Ruixue Ding, Yu Zeng, Zehui Chen, Lin Chen, Shihang Wang, Pengjun Xie, Fei Huang, and Feng Zhao. Vrag-rl: Empower vision-perception-based rag for vi- sually rich information understanding via iterative reasoning with reinforcement learning, 2025. 3
work page 2025
-
[41]
Wenbin Wang, Liang Ding, Minyan Zeng, Xiabin Zhou, Li Shen, Yong Luo, Wei Yu, and Dacheng Tao. Divide, conquer and combine: A training-free framework for high-resolution image perception in multimodal large language models. In Proceedings of the AAAI Conference on Artificial Intelli- gence, pages 7907–7915, 2025. 6
work page 2025
-
[42]
Vicrit: A verifiable reinforcement learning proxy task for visual perception in vlms, 2025
Xiyao Wang, Zhengyuan Yang, Chao Feng, Yongyuan Liang, Yuhang Zhou, Xiaoyu Liu, Ziyi Zang, Ming Li, Chung-Ching Lin, Kevin Lin, Linjie Li, Furong Huang, and Lijuan Wang. Vicrit: A verifiable reinforcement learning proxy task for visual perception in vlms, 2025. 2
work page 2025
-
[43]
Simple o3: To- wards interleaved vision-language reasoning.arXiv preprint arXiv:2508.12109, 2025
Ye Wang, Qianglong Chen, Zejun Li, Siyuan Wang, Shi- jie Guo, Zhirui Zhang, and Zhongyu Wei. Simple o3: To- wards interleaved vision-language reasoning.arXiv preprint arXiv:2508.12109, 2025. 1
-
[44]
Unified multimodal chain-of-thought reward model through reinforcement fine- tuning, 2025
Yibin Wang, Zhimin Li, Yuhang Zang, Chunyu Wang, Qinglin Lu, Cheng Jin, and Jiaqi Wang. Unified multimodal chain-of-thought reward model through reinforcement fine- tuning, 2025. 2
work page 2025
-
[45]
Mmsearch-r1: Incentivizing lmms to search, 2025
Jinming Wu, Zihao Deng, Wei Li, Yiding Liu, Bo You, Bo Li, Zejun Ma, and Ziwei Liu. Mmsearch-r1: Incentivizing lmms to search, 2025. 3
work page 2025
-
[46]
Vtool-r1: Vlms learn to think with images via reinforcement learning on multimodal tool use
Mingyuan Wu, Jingcheng Yang, Jize Jiang, Meitang Li, Kaizhuo Yan, Hanchao Yu, Minjia Zhang, Chengxiang Zhai, and Klara Nahrstedt. Vtool-r1: Vlms learn to think with images via reinforcement learning on multimodal tool use. arXiv preprint arXiv:2505.19255, 2025. 1
-
[47]
V?: Guided visual search as a core mechanism in multimodal llms
Penghao Wu and Saining Xie. V?: Guided visual search as a core mechanism in multimodal llms. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13084–13094, 2024. 5, 6
work page 2024
-
[48]
Synthrl: Scaling visual reasoning with verifiable data synthesis, 2025
Zijian Wu, Jinjie Ni, Xiangyan Liu, Zichen Liu, Hang Yan, and Michael Qizhe Shieh. Synthrl: Scaling visual reasoning with verifiable data synthesis, 2025. 2
work page 2025
-
[49]
Lillicrap, Kenji Kawaguchi, and Michael Shieh
Yuxi Xie, Anirudh Goyal, Wenyue Zheng, Min-Yen Kan, Timothy P. Lillicrap, Kenji Kawaguchi, and Michael Shieh. Monte carlo tree search boosts reasoning via iterative prefer- ence learning, 2024. 2
work page 2024
-
[50]
Llava-cot: Let vision language models reason step-by-step, 2025
Guowei Xu, Peng Jin, Ziang Wu, Hao Li, Yibing Song, Lichao Sun, and Li Yuan. Llava-cot: Let vision language models reason step-by-step, 2025. 2
work page 2025
-
[51]
Redstar: Does scaling long-cot data unlock better slow-reasoning systems?, 2025
Haotian Xu, Xing Wu, Weinong Wang, Zhongzhi Li, Da Zheng, Boyuan Chen, Yi Hu, Shijia Kang, Jiaming Ji, Yingy- ing Zhang, Zhijiang Guo, Yaodong Yang, Muhan Zhang, and Debing Zhang. Redstar: Does scaling long-cot data unlock better slow-reasoning systems?, 2025. 2
work page 2025
-
[52]
Mixed-r1: Unified reward perspective for reasoning capability in multimodal large language models,
Shilin Xu, Yanwei Li, Rui Yang, Tao Zhang, Yueyi Sun, Wei Chow, Linfeng Li, Hang Song, Qi Xu, Yunhai Tong, Xiangtai Li, and Hao Fei. Mixed-r1: Unified reward perspective for reasoning capability in multimodal large language models,
-
[53]
Zhenghai Xue, Longtao Zheng, Qian Liu, Yingru Li, Xi- aosen Zheng, Zejun Ma, and Bo An. Simpletir: End-to-end reinforcement learning for multi-turn tool-integrated reason- ing.arXiv preprint arXiv:2509.02479, 2025. 5
-
[54]
Huanjin Yao, Jiaxing Huang, Wenhao Wu, Jingyi Zhang, Yibo Wang, Shunyu Liu, Yingjie Wang, Yuxin Song, Haocheng Feng, Li Shen, and Dacheng Tao. Mulberry: Em- powering mllm with o1-like reasoning and reflection via col- lective monte carlo tree search, 2024. 2
work page 2024
-
[55]
Tianyu Yu, Yuan Yao, Haoye Zhang, Taiwen He, Yifeng Han, Ganqu Cui, Jinyi Hu, Zhiyuan Liu, Hai-Tao Zheng, Maosong Sun, and Tat-Seng Chua. Rlhf-v: Towards trust- worthy mllms via behavior alignment from fine-grained cor- rectional human feedback, 2024. 2
work page 2024
-
[56]
UIOrchestra: Generating high-fidelity code from UI designs with a multi-agent sys- tem
Chuhuai Yue, Jiajun Chai, Yufei Zhang, Zixiang Ding, Xihao Liang, Peixin Wang, Shihai Chen, Wang Yixuan, Wangyan- ping, Guojun Yin, and Wei Lin. UIOrchestra: Generating high-fidelity code from UI designs with a multi-agent sys- tem. InFindings of the Association for Computational Lin- guistics: EMNLP 2025, pages 2769–2782, Suzhou, China,
work page 2025
-
[57]
Association for Computational Linguistics. 2
-
[58]
Promoting efficient reason- ing with verifiable stepwise reward, 2025
Chuhuai Yue, Chengqi Dong, Yinan Gao, Hang He, Jiajun Chai, Guojun Yin, and Wei Lin. Promoting efficient reason- ing with verifiable stepwise reward, 2025. 2
work page 2025
-
[59]
Yufei Zhan, Yousong Zhu, Shurong Zheng, Hongyin Zhao, Fan Yang, Ming Tang, and Jinqiao Wang. Vision-r1: Evolv- ing human-free alignment in large vision-language models via vision-guided reinforcement learning, 2025. 2
work page 2025
-
[60]
The Landscape of Agentic Reinforcement Learning for LLMs: A Survey
Guibin Zhang, Hejia Geng, Xiaohang Yu, Zhenfei Yin, Zaibin Zhang, Zelin Tan, Heng Zhou, Zhongzhi Li, Xi- angyuan Xue, Yijiang Li, et al. The landscape of agentic reinforcement learning for llms: A survey.arXiv preprint arXiv:2509.02547, 2025. 1
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[61]
Viper: Empowering the self-evolution of visual perception abilities in vision-language model, 2025
Juntian Zhang, Song Jin, Chuanqi Cheng, Yuhan Liu, Yankai Lin, Xun Zhang, Yufei Zhang, Fei Jiang, Guojun Yin, Wei Lin, and Rui Yan. Viper: Empowering the self-evolution of visual perception abilities in vision-language model, 2025. 2
work page 2025
-
[62]
Improve vision language model chain-of- thought reasoning, 2024
Ruohong Zhang, Bowen Zhang, Yanghao Li, Haotian Zhang, Zhiqing Sun, Zhe Gan, Yinfei Yang, Ruoming Pang, and Yiming Yang. Improve vision language model chain-of- thought reasoning, 2024. 2
work page 2024
-
[63]
Chain-of-focus: Adaptive visual search and zooming for multimodal reasoning via rl,
Xintong Zhang, Zhi Gao, Bofei Zhang, Pengxiang Li, Xi- aowen Zhang, Yang Liu, Tao Yuan, Yuwei Wu, Yunde Jia, Song-Chun Zhu, and Qing Li. Chain-of-focus: Adaptive visual search and zooming for multimodal reasoning via rl,
-
[64]
Adaptive Chain-of-Focus Reasoning via Dynamic Visual Search and Zooming for Efficient VLMs
Xintong Zhang, Zhi Gao, Bofei Zhang, Pengxiang Li, Xi- aowen Zhang, Yang Liu, Tao Yuan, Yuwei Wu, Yunde Jia, Song-Chun Zhu, et al. Chain-of-focus: Adaptive visual search and zooming for multimodal reasoning via rl.arXiv preprint arXiv:2505.15436, 2025. 1, 3, 5, 6
work page internal anchor Pith review arXiv 2025
-
[65]
Yi-Fan Zhang, Huanyu Zhang, Haochen Tian, Chaoyou Fu, Shuangqing Zhang, Junfei Wu, Feng Li, Kun Wang, Qing- song Wen, Zhang Zhang, et al. Mme-realworld: Could your multimodal llm challenge high-resolution real-world scenarios that are difficult for humans?arXiv preprint arXiv:2408.13257, 2024. 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[66]
R1-reward: Train- ing multimodal reward model through stable reinforcement learning, 2025
Yi-Fan Zhang, Xingyu Lu, Xiao Hu, Chaoyou Fu, Bin Wen, Tianke Zhang, Changyi Liu, Kaiyu Jiang, Kaibing Chen, Kaiyu Tang, Haojie Ding, Jiankang Chen, Fan Yang, Zhang Zhang, Tingting Gao, and Liang Wang. R1-reward: Train- ing multimodal reward model through stable reinforcement learning, 2025. 2
work page 2025
-
[67]
R1-omni: Ex- plainable omni-multimodal emotion recognition with rein- forcement learning, 2025
Jiaxing Zhao, Xihan Wei, and Liefeng Bo. R1-omni: Ex- plainable omni-multimodal emotion recognition with rein- forcement learning, 2025. 2
work page 2025
-
[68]
DeepEyes: Incentivizing "Thinking with Images" via Reinforcement Learning
Ziwei Zheng, Michael Yang, Jack Hong, Chenxiao Zhao, Guohai Xu, Le Yang, Chao Shen, and Xing Yu. Deep- eyes: Incentivizing” thinking with images” via reinforce- ment learning.arXiv preprint arXiv:2505.14362, 2025. 1, 3, 5, 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[69]
R1-zero’s ”aha moment” in visual reasoning on a 2b non-sft model, 2025
Hengguang Zhou, Xirui Li, Ruochen Wang, Minhao Cheng, Tianyi Zhou, and Cho-Jui Hsieh. R1-zero’s ”aha moment” in visual reasoning on a 2b non-sft model, 2025. 2
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.