Recognition: 2 theorem links
· Lean TheoremUnified Multimodal Brain Decoding via Cross-Subject Soft-ROI Fusion
Pith reviewed 2026-05-16 20:13 UTC · model grok-4.3
The pith
A BrainROI model uses soft functional brain regions to decode fMRI signals into natural language captions that generalize across subjects.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
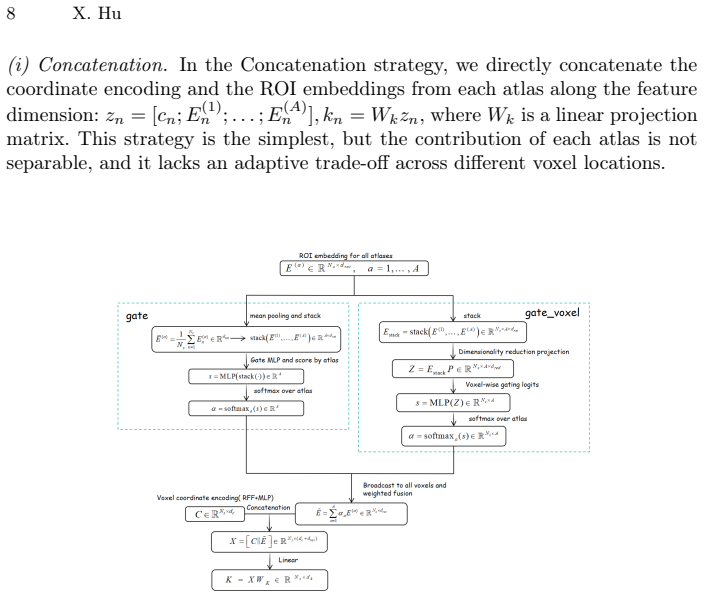
We propose a BrainROI model that achieves leading results in brain-captioning evaluation on the NSD dataset under cross-subject settings. The model maps fMRI voxels into a consistent shared space via multi-atlas soft functional parcellations, extends discrete ROI concatenation into a voxel-wise gated fusion mechanism, enforces consistent ROI mapping through global label alignment, runs an interpretable prompt optimization loop with a locally deployed language model, and applies parameterized decoding constraints at inference time.
What carries the argument
multi-atlas soft functional parcellations (soft-ROI) serving as a shared space, combined with voxel-wise gated fusion and global label alignment to enable cross-subject transfer
If this is right
- The same decoder can be deployed on new subjects without collecting large subject-specific training sets.
- Generated captions become more stable because prompt selection follows an explicit, auditable optimization trajectory.
- Parameterized constraints during inference reduce hallucinations and improve description quality on held-out stimuli.
- The soft-ROI representation may support unified training across multiple fMRI datasets collected under different scanners or protocols.
Where Pith is reading between the lines
- If the soft-ROI alignment holds for other imaging modalities, the same fusion strategy could be tested on EEG or MEG data for cross-subject decoding.
- The automated prompt loop could be adapted to other generation tasks where prompt stability matters, such as medical report generation from images.
- Success would imply that functional brain topology contains enough invariant structure to support parameter-free transfer between individuals once the right parcellation is chosen.
Load-bearing premise
That multi-atlas soft functional parcellations create a sufficiently consistent shared space across subjects to enable reliable transfer without subject-specific retraining.
What would settle it
A substantial drop in BLEU-4 and CIDEr scores when the trained model is applied to an entirely new group of subjects without any additional fine-tuning or retraining would falsify the claimed cross-subject generalization.
Figures



read the original abstract
Multimodal brain decoding aims to reconstruct semantic information that is consistent with visual stimuli from brain activity signals such as fMRI, and then generate readable natural language descriptions. However, multimodal brain decoding still faces key challenges in cross-subject generalization and interpretability. We propose a BrainROI model and achieve leading-level results in brain-captioning evaluation on the NSD dataset. Under the cross-subject setting, compared with recent state-of-the-art methods and representative baselines, metrics such as BLEU-4 and CIDEr show clear improvements. Firstly, to address the heterogeneity of functional brain topology across subjects, we design a new fMRI encoder. We use multi-atlas soft functional parcellations (soft-ROI) as a shared space. We extend the discrete ROI Concatenation strategy in MINDLLM to a voxel-wise gated fusion mechanism (Voxel-gate). We also ensure consistent ROI mapping through global label alignment, which enhances cross-subject transferability. Secondly, to overcome the limitations of manual and black-box prompting methods in stability and transparency, we introduce an interpretable prompt optimization process. In a small-sample closed loop, we use a locally deployed Qwen model to iteratively generate and select human-readable prompts. This process improves the stability of prompt design and preserves an auditable optimization trajectory. Finally, we impose parameterized decoding constraints during inference to further improve the stability and quality of the generated descriptions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the BrainROI model for multimodal brain decoding from fMRI signals to generate natural language captions consistent with visual stimuli. It addresses cross-subject generalization and interpretability on the NSD dataset by using multi-atlas soft functional parcellations (soft-ROI) as a shared space, extending to a voxel-wise gated fusion mechanism (Voxel-gate) with global label alignment, an interpretable prompt optimization loop via a locally deployed Qwen model in a small-sample closed loop, and parameterized decoding constraints during inference. The central empirical claim is leading-level performance with clear improvements in BLEU-4 and CIDEr under cross-subject settings compared to recent SOTA methods and baselines.
Significance. If the cross-subject transfer holds and the reported metric gains are robust, the approach could advance unified brain decoding by providing a more consistent shared representation space across subjects without per-subject retraining and by improving prompt stability through an auditable optimization process. The emphasis on soft parcellations and interpretable prompting offers potential for greater transparency in neuroscience ML applications.
major comments (2)
- [Methods (soft-ROI, Voxel-gate, and global label alignment description)] The central claim of reliable cross-subject transfer without subject-specific retraining rests on multi-atlas soft functional parcellations plus global label alignment creating a sufficiently consistent voxel-wise space, yet no quantitative validation of alignment quality (e.g., inter-subject Dice overlap on soft assignments, correlation of voxel-wise gating vectors, or variance of soft weights across subjects) is provided to confirm that the fused representations support the observed BLEU-4/CIDEr gains rather than arising from the prompt optimization loop or inference constraints.
- [Results (NSD brain-captioning evaluation)] The abstract states clear improvements in BLEU-4 and CIDEr over SOTA and baselines in the cross-subject setting, but the absence of detailed quantitative tables, error bars, statistical tests, or ablation studies isolating the contribution of Voxel-gate fusion versus prompt optimization makes it difficult to verify robustness and attribute the gains specifically to the proposed mechanisms.
minor comments (2)
- [Methods (interpretable prompt optimization)] The description of the prompt optimization process could clarify the exact selection criteria used in the small-sample closed loop and how human-readable prompts are ensured to remain auditable without introducing post-hoc bias.
- [Methods (fMRI encoder)] Notation for the voxel-gate parameters and soft-ROI fusion could be made more explicit (e.g., defining the gating function and alignment mapping formally) to improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments. We address each major point below and will revise the manuscript to strengthen the validation of our claims.
read point-by-point responses
-
Referee: [Methods (soft-ROI, Voxel-gate, and global label alignment description)] The central claim of reliable cross-subject transfer without subject-specific retraining rests on multi-atlas soft functional parcellations plus global label alignment creating a sufficiently consistent voxel-wise space, yet no quantitative validation of alignment quality (e.g., inter-subject Dice overlap on soft assignments, correlation of voxel-wise gating vectors, or variance of soft weights across subjects) is provided to confirm that the fused representations support the observed BLEU-4/CIDEr gains rather than arising from the prompt optimization loop or inference constraints.
Authors: We agree that explicit quantitative validation of alignment quality would strengthen the central claim. In the revised manuscript we will add a dedicated analysis subsection reporting inter-subject Dice overlap on soft-ROI assignments, Pearson correlations of voxel-wise gating vectors across subjects, and the variance of soft weights. These metrics will be computed on the NSD training subjects and presented alongside the main results to demonstrate that the fused space is sufficiently consistent and that the reported gains are not solely attributable to the prompt optimization loop. revision: yes
-
Referee: [Results (NSD brain-captioning evaluation)] The abstract states clear improvements in BLEU-4 and CIDEr over SOTA and baselines in the cross-subject setting, but the absence of detailed quantitative tables, error bars, statistical tests, or ablation studies isolating the contribution of Voxel-gate fusion versus prompt optimization makes it difficult to verify robustness and attribute the gains specifically to the proposed mechanisms.
Authors: We acknowledge that the current presentation lacks sufficient detail for full verification. We will expand the Results section with complete tables that include means, standard deviations, error bars, and statistical significance tests (paired t-tests with p-values corrected for multiple comparisons). In addition, we will include ablation studies that systematically remove or replace the Voxel-gate fusion, global label alignment, and prompt optimization components while keeping all other factors fixed, thereby isolating their individual contributions to the BLEU-4 and CIDEr improvements. revision: yes
Circularity Check
No load-bearing circularity; central gains are empirical outcomes
full rationale
The paper's derivation chain consists of an fMRI encoder using multi-atlas soft-ROI parcellations extended to voxel-wise gated fusion, plus a separate prompt optimization loop and inference constraints. Reported BLEU-4 and CIDEr improvements on NSD under cross-subject transfer are presented as direct empirical comparisons to baselines rather than quantities derived by construction from fitted parameters or self-referential definitions. Any reference to prior ROI concatenation work (e.g., MINDLLM) is an extension step, not a load-bearing self-citation that forces the main metrics. The shared-space consistency assumption is an unvalidated premise but does not reduce any equation or prediction to its own inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- voxel-gate parameters
axioms (1)
- domain assumption Multi-atlas soft functional parcellations provide a shared space that reduces cross-subject heterogeneity
invented entities (1)
-
BrainROI model
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We use multi-atlas soft functional parcellations (soft-ROI) as a shared space... voxel-wise gated fusion mechanism (Voxel-gate)... global label alignment
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We extend the discrete ROI Concatenation strategy in MINDLLM to a voxel-wise gated fusion mechanism (Voxel-gate)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
In: Leonardis, A., Ricci, E., Roth, S., Russakovsky, O., Sattler, T., Varol, G
Xia, W., de Charette, R., Oztireli, C., Xue, J.-H.: UMBRAE: Unified multimodal brain decoding. In: Leonardis, A., Ricci, E., Roth, S., Russakovsky, O., Sattler, T., Varol, G. (eds.) Computer Vision – ECCV 2024, LNCS, vol. 15065, pp. 242–259. Springer, Cham (2024).https://doi.org/10.1007/978-3-031-72667-5_14
-
[2]
In: Proceedings of the 42nd International Conference on Machine Learning, Proc
Qiu, W., Huang, Z., Hu, H., Feng, A., Yan, Y., Ying, Z.: MindLLM: A subject- agnostic and versatile model for fMRI-to-text decoding. In: Proceedings of the 42nd International Conference on Machine Learning, Proc. Mach. Learn. Res., vol. 267, pp. 50572–50593. PMLR (2025)
work page 2025
-
[3]
In: Advances in Neural Information Processing Systems 37 (2024).https://doi.org/10.52202/079017-4025
Du, Y., Sun, W., Snoek, C.G.M.: IPO: Interpretable prompt optimization for vision-language models. In: Advances in Neural Information Processing Systems 37 (2024).https://doi.org/10.52202/079017-4025
-
[4]
In: Proceedings of the 38th International Conference on Machine Learning, Proc
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., Sutskever, I.: Learning transfer- able visual models from natural language supervision. In: Proceedings of the 38th International Conference on Machine Learning, Proc. Mach. Learn. Res., vol. 139, pp. 8748–8763. PMLR (2021)
work page 2021
-
[5]
Nature Neuroscience26(5), 858–866 (2023).https://doi.org/10.1038/s41593-023-01304-9
Tang, J., LeBel, A., Jain, S., Huth, A.G.: Semantic reconstruction of continuous language from noninvasive brain recordings. Nature Neuroscience26(5), 858–866 (2023).https://doi.org/10.1038/s41593-023-01304-9
-
[6]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp
Han, J., Gong, K., Zhang, Y., Wang, J., Zhang, K., Lin, D., Qiao, Y., Gao, P., Yue, X.: OneLLM: One framework to align all modalities with language. In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 26584–26595 (2024).https://doi.org/10.1109/CVPR52733.2024. 02510
-
[7]
arXiv:2001.11761 (2020).https://doi.org/10.48550/ arXiv.2001.11761
Mozafari, M., Reddy, L., VanRullen, R.: Reconstructing natural scenes from fMRI patterns using BigBiGAN. arXiv:2001.11761 (2020).https://doi.org/10.48550/ arXiv.2001.11761
-
[8]
In: Proceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition (CVPR), pp
Takagi, Y., Nishimoto, S.: High-resolution image reconstruction with latent diffu- sion models from human brain activity. In: Proceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition (CVPR), pp. 14453–14463 (2023).https://doi.org/10.1109/CVPR52729.2023.01389
-
[9]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp
Wang, S., Liu, S., Tan, Z., Wang, X.: MindBridge: A cross-subject brain decoding framework. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 11333–11342 (2024).https://doi.org/10. 1109/CVPR52733.2024.01077
-
[10]
arXiv:2412.19487 (2024).https://doi.org/10.48550/ arXiv.2412.19487
Wang, Z., Zhao, Z., Zhou, L., Nachev, P.: UniBrain: A unified model for cross- subject brain decoding. arXiv:2412.19487 (2024).https://doi.org/10.48550/ arXiv.2412.19487
-
[11]
Li, X.L., Liang, P.: Prefix-tuning: Optimizing continuous prompts for generation. In: Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 4582–4597. Association for Computa- tional Linguistics (2021).https://doi.org/10.18653/v1/2021.acl-long.353
-
[12]
Zhou, K., Yang, J., Loy, C.C., Liu, Z.: Learning to prompt for vision-language models. International Journal of Computer Vision130, 2337–2348 (2022).https: //doi.org/10.1007/s11263-022-01653-1
-
[13]
In: Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition (CVPR), pp
Zhou, K., Yang, J., Loy, C.C., Liu, Z.: Conditional prompt learning for vision- language models. In: Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition (CVPR), pp. 16816–16825 (2022).https://doi. org/10.1109/CVPR52688.2022.01631 Unified Multimodal Brain Decoding via Cross-Subject Soft-ROI Fusion 21
-
[14]
Jia,M.,Tang,L.,Chen,B.C.,Cardie,C.,Belongie,S.,Hariharan,B.,Lim,S.N.:Vi- sualprompttuning.In:ComputerVision–ECCV2022,LNCS,vol.13693,pp.709–
-
[15]
Springer, Cham (2022).https://doi.org/10.1007/978-3-031-19827-4_41
-
[16]
In: International Conference on Learning Representations (ICLR) (2023)
Zhou, Y., Muresanu, A.I., Han, Z., Paster, K., Pitis, S., Chan, H., Ba, J.: Large language models are human-level prompt engineers. In: International Conference on Learning Representations (ICLR) (2023)
work page 2023
-
[17]
Pryzant, R., Iter, D., Li, J., Lee, Y.T., Zhu, C., Zeng, M.: Automatic prompt optimization with "gradient descent" and beam search. In: Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 7957–7968. Association for Computational Linguistics (2023).https://doi.org/ 10.18653/v1/2023.emnlp-main.494
-
[18]
Qwen Team: Qwen2.5 technical report. arXiv:2412.15115 (2024).https://doi. org/10.48550/arXiv.2412.15115
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2412.15115 2024
-
[19]
Shikra: Unleashing Multimodal LLM's Referential Dialogue Magic
Chen, K., Zhang, Z., Zeng, W., Zhang, R., Zhu, F., Zhao, R.: Shikra: Unleashing multimodal LLM’s referential dialogue magic. arXiv:2306.15195 (2023).https: //doi.org/10.48550/arXiv.2306.15195
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2306.15195 2023
-
[20]
arXiv:2306.11536 (2023).https://doi.org/10.48550/arXiv.2306.11536
Takagi, Y., Nishimoto, S.: Improving visual image reconstruction from hu- man brain activity using latent diffusion models via multiple decoded inputs. arXiv:2306.11536 (2023).https://doi.org/10.48550/arXiv.2306.11536
-
[21]
In: Proceedings of UniReps: the First Workshop on Unifying Representations in Neural Models, Proc
Ferrante, M., Boccato, T., Ozcelik, F., VanRullen, R., Toschi, N.: Multimodal decoding of human brain activity into images and text. In: Proceedings of UniReps: the First Workshop on Unifying Representations in Neural Models, Proc. Mach. Learn. Res., vol. 243, pp. 87–101. PMLR (2024)
work page 2024
-
[22]
Xia, W., Oztireli, C.: Exploring the visual feature space for multimodal neural decoding.In:ProceedingsoftheIEEE/CVFInternationalConferenceonComputer Vision (ICCV) (2025)
work page 2025
-
[23]
In: Proceedings of the 41st International Conference on Machine Learning, Proc
Scotti, P.S., Tripathy, M., Torrico, C., Kneeland, R., Chen, T., Narang, A., San- thirasegaran, C., Xu, J., Naselaris, T., Norman, K.A., Abraham, T.M.: MindEye2: Shared-subject models enable fMRI-to-image with 1 hour of data. In: Proceedings of the 41st International Conference on Machine Learning, Proc. Mach. Learn. Res., vol. 235, pp. 44038–44059. PMLR (2024)
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.