Recognition: no theorem link
SpatialMosaic: A Multiview VLM Dataset for Partial Visibility
Pith reviewed 2026-05-16 19:40 UTC · model grok-4.3
The pith
A new 2-million-pair multi-view dataset trains vision-language models to reason about 3D scenes from partial and occluded views.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A scalable pipeline that renders multi-view images from indoor and outdoor scenes, then automatically produces realistic spatial-reasoning question-answer pairs, yields SpatialMosaic with 2 million training pairs and SpatialMosaic-Bench with 1 million evaluation pairs across six tasks; when used to fine-tune a hybrid SpatialMosaicVLM that inserts 3D geometry encoders into a vision-language model, the data measurably improves performance on partial-visibility, occlusion, and low-overlap spatial reasoning.
What carries the argument
The multi-view data generation and annotation pipeline that automatically constructs spatial-reasoning QA pairs capturing partial visibility and low-overlap conditions.
If this is right
- Training on the dataset improves model accuracy on multi-view spatial tasks that involve occlusion and fragmented views.
- The accompanying benchmark provides a standardized testbed for comparing methods across six distinct spatial-reasoning skills.
- Hybrid models that combine 3D geometry encoders with vision-language models become more robust when fine-tuned on the generated pairs.
- The same pipeline scales to both indoor and outdoor scenes, supporting evaluation in diverse real-world environments.
- Automatic QA generation removes the need for manual annotation while still producing challenging questions that require 3D inference from 2D cues.
Where Pith is reading between the lines
- If the pipeline generalizes, similar automatic generation could be applied to video sequences to add temporal spatial reasoning.
- The approach suggests that large synthetic multi-view corpora may substitute for explicit 3D supervision in downstream robotics tasks.
- Low-overlap camera configurations common in drone mapping could benefit directly from models trained on the dataset.
- Future benchmarks might incorporate adversarial occlusions to test whether performance gains persist under more extreme visibility limits.
Load-bearing premise
Automatically generated question-answer pairs capture real-world partial visibility, occlusion, and low-overlap conditions without systematic biases or annotation errors.
What would settle it
A controlled test in which models trained on SpatialMosaic are evaluated on newly captured real-world multi-view images with known ground-truth occlusions and low overlap; if accuracy gains disappear relative to models trained on existing multi-view datasets, the claim that the generated data is representative would be falsified.
Figures






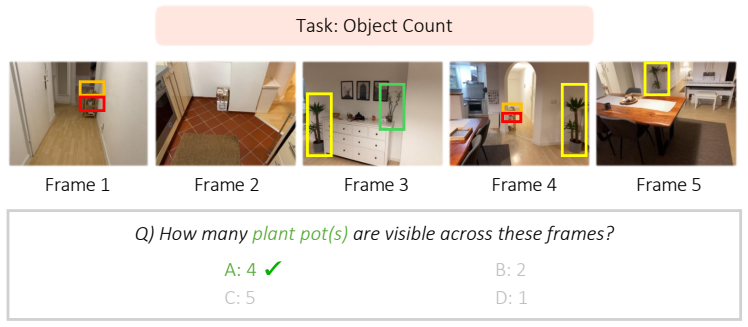




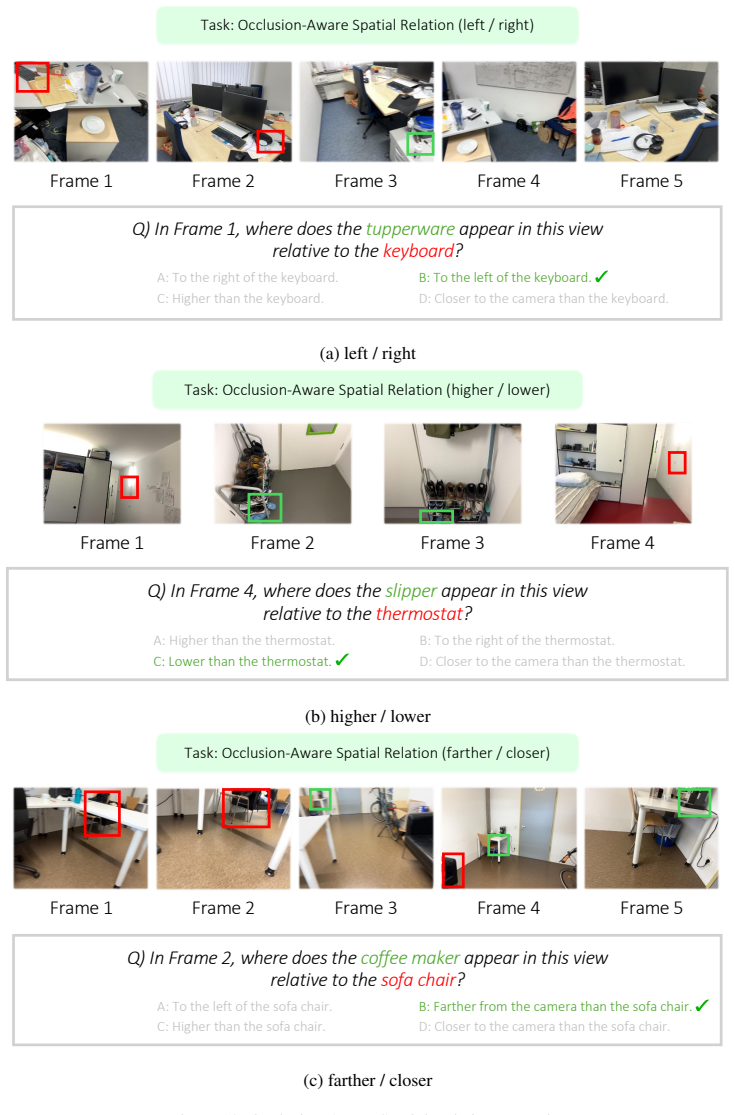
read the original abstract
The rapid progress of Multimodal Large Language Models (MLLMs) has unlocked the potential for enhanced 3D scene understanding and spatial reasoning. A recent line of work explores learning spatial reasoning directly from multi-view images, enabling MLLMs to understand 3D scenes without explicit 3D reconstructions. Nevertheless, key challenges that frequently arise in real-world environments, such as partial visibility, occlusion, and low-overlap conditions that require spatial reasoning from fragmented visual cues, remain under-explored. To address these limitations, we propose a scalable multi-view data generation and annotation pipeline that constructs realistic spatial reasoning QAs, resulting in SpatialMosaic, a comprehensive instruction-tuning dataset featuring 2M QA pairs. We further introduce SpatialMosaic-Bench, a challenging benchmark for evaluating multi-view spatial reasoning under complex and diverse scenarios, consisting of 1M QA pairs across 6 tasks. Our proposed dataset spans both indoor and outdoor scenes, enabling comprehensive evaluation in diverse real-world scenarios. In addition, we introduce a new baseline for multi-view settings, SpatialMosaicVLM, a hybrid framework that integrates 3D reconstruction models as geometry encoders within VLMs for robust spatial reasoning. Extensive experiments demonstrate that our proposed dataset effectively enhances spatial reasoning under challenging multi-view conditions, validating the effectiveness of our data generation pipeline in constructing realistic and challenging QAs. Code and dataset will be available soon.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SpatialMosaic, a scalable multi-view data generation pipeline that produces a 2M-pair instruction-tuning dataset of spatial reasoning QA pairs focused on partial visibility, occlusion, and low-overlap conditions across indoor and outdoor scenes. It also releases SpatialMosaic-Bench (1M QA pairs across 6 tasks) and proposes SpatialMosaicVLM, a hybrid VLM that integrates 3D reconstruction models as geometry encoders. The central claim is that the dataset and baseline enhance spatial reasoning under challenging multi-view conditions, as demonstrated by extensive experiments validating the data generation pipeline.
Significance. If the empirical validation holds under independent testing, the work would supply a large-scale resource addressing an under-explored gap in multi-view VLM training for fragmented visual cues, potentially improving robustness without requiring explicit 3D reconstructions. The dataset scale and new baseline could serve as a foundation for future research on real-world spatial reasoning.
major comments (2)
- Abstract: the assertion that 'extensive experiments demonstrate that our proposed dataset effectively enhances spatial reasoning under challenging multi-view conditions' provides no quantitative metrics, baseline comparisons, error analysis, or protocol details on how partial-visibility cases were constructed or measured, leaving the central empirical claim without verifiable support.
- Evaluation setup (implied by abstract and skeptic note): the test distribution in SpatialMosaic-Bench is generated by the identical pipeline used for the 2M training pairs, creating a circularity risk where gains may exploit synthetic cues (e.g., depth noise patterns or QA phrasing) rather than transferable multi-view reasoning; no transfer results on real captures such as ScanNet or Matterport, nor human realism ratings, are reported to anchor the 'realistic' claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below with clarifications and indicate where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: Abstract: the assertion that 'extensive experiments demonstrate that our proposed dataset effectively enhances spatial reasoning under challenging multi-view conditions' provides no quantitative metrics, baseline comparisons, error analysis, or protocol details on how partial-visibility cases were constructed or measured, leaving the central empirical claim without verifiable support.
Authors: We agree that the abstract, constrained by length, summarizes the empirical results at a high level without specific numbers or protocol details. The full manuscript provides these elements in Sections 4 and 5, including quantitative gains over baselines, error breakdowns, and the exact construction protocol for partial-visibility, occlusion, and low-overlap cases described in Section 3. To improve verifiability, we will revise the abstract to include key metrics (e.g., accuracy improvements on the six benchmark tasks) while preserving brevity. revision: yes
-
Referee: Evaluation setup (implied by abstract and skeptic note): the test distribution in SpatialMosaic-Bench is generated by the identical pipeline used for the 2M training pairs, creating a circularity risk where gains may exploit synthetic cues (e.g., depth noise patterns or QA phrasing) rather than transferable multi-view reasoning; no transfer results on real captures such as ScanNet or Matterport, nor human realism ratings, are reported to anchor the 'realistic' claim.
Authors: We acknowledge the valid concern about potential distribution overlap and synthetic cue exploitation. The benchmark uses disjoint scenes and deliberately varied generation parameters (visibility ratios, overlap thresholds, and noise levels) to reduce this risk, as detailed in Section 3.2. However, the current experiments do not include transfer evaluations on real captures such as ScanNet or Matterport, nor human realism ratings. We will add an explicit limitations subsection discussing this gap and outlining future real-world validation steps. revision: partial
Circularity Check
No circularity: empirical dataset construction with no derivation chain or self-referential reductions.
full rationale
The paper introduces a data generation pipeline to produce the SpatialMosaic dataset (2M QA pairs) and SpatialMosaic-Bench (1M QA pairs), then reports empirical gains from training SpatialMosaicVLM on the data. No equations, fitted parameters, uniqueness theorems, or ansatzes are defined in terms of the target results. Claims rest on the new artifacts and standard train/test splits rather than any step that reduces by construction to its own inputs. The shared generation pipeline between train and test data is a standard empirical setup for synthetic benchmarks and does not meet the criteria for circularity (no quoted self-definition or load-bearing self-citation that collapses the central claim).
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The automated multi-view data generation and annotation pipeline produces realistic and challenging spatial reasoning QAs that match real-world partial-visibility conditions.
Reference graph
Works this paper leans on
-
[1]
Referit3d: Neural listeners for fine-grained 3d object identification in real-world scenes
Panos Achlioptas, Ahmed Abdelreheem, Fei Xia, Mohamed Elhoseiny, and Leonidas Guibas. Referit3d: Neural listeners for fine-grained 3d object identification in real-world scenes. InEuropean conference on computer vision, pages 422–440. Springer, 2020. 3
work page 2020
-
[2]
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, et al. Flamingo: a visual language model for few-shot learning.Advances in neural information processing systems, 35:23716–23736,
-
[3]
Jacob Andreas, Marcus Rohrbach, Trevor Darrell, and Dan Klein. Neural module networks. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 39–48, 2016. 3
work page 2016
-
[4]
Scanqa: 3d question answering for spatial scene understanding
Daichi Azuma, Taiki Miyanishi, Shuhei Kurita, and Motoaki Kawanabe. Scanqa: 3d question answering for spatial scene understanding. Inproceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 19129– 19139, 2022. 3
work page 2022
-
[5]
Grounded 3d-llm with referent tokens.arXiv preprint arXiv:2405.10370,
Yilun Chen, Shuai Yang, Haifeng Huang, Tai Wang, Runsen Xu, Ruiyuan Lyu, Dahua Lin, and Jiangmiao Pang. Grounded 3d-llm with referent tokens.arXiv preprint arXiv:2405.10370,
-
[6]
How far are we to gpt-4v? closing the gap to commercial multimodal models with open-source suites
Zhe Chen, Weiyun Wang, Hao Tian, Shenglong Ye, Zhangwei Gao, Erfei Cui, Wenwen Tong, Kongzhi Hu, Jiapeng Luo, Zheng Ma, et al. How far are we to gpt-4v? closing the gap to commercial multimodal models with open-source suites. Science China Information Sciences, 67(12):220101, 2024. 7, 8, 1
work page 2024
-
[7]
Hsfm: Hybrid structure-from-motion
Hainan Cui, Xiang Gao, Shuhan Shen, and Zhanyi Hu. Hsfm: Hybrid structure-from-motion. 2017. 3
work page 2017
-
[8]
Scannet: Richly-annotated 3d reconstructions of indoor scenes
Angela Dai, Angel X Chang, Manolis Savva, Maciej Hal- ber, Thomas Funkhouser, and Matthias Nießner. Scannet: Richly-annotated 3d reconstructions of indoor scenes. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 5828–5839, 2017. 5
work page 2017
-
[9]
Mm-spatial: Exploring 3d spatial understanding in multimodal llms
Erik Daxberger, Nina Wenzel, David Griffiths, Haiming Gang, Justin Lazarow, Gefen Kohavi, Kai Kang, Marcin Eichner, Yinfei Yang, Afshin Dehghan, et al. Mm-spatial: Exploring 3d spatial understanding in multimodal llms. InProceed- ings of the IEEE/CVF International Conference on Computer Vision, pages 7395–7408, 2025. 2
work page 2025
-
[10]
3d-llava: Towards generalist 3d lmms with omni superpoint transformer
Jiajun Deng, Tianyu He, Li Jiang, Tianyu Wang, Feras Day- oub, and Ian Reid. 3d-llava: Towards generalist 3d lmms with omni superpoint transformer. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 3772–3782,
-
[11]
VLM-3R: Vision-Language Models Augmented with Instruction-Aligned 3D Reconstruction
Zhiwen Fan, Jian Zhang, Renjie Li, Junge Zhang, Runjin Chen, Hezhen Hu, Kevin Wang, Huaizhi Qu, Dilin Wang, Zhicheng Yan, et al. Vlm-3r: Vision-language models aug- mented with instruction-aligned 3d reconstruction.arXiv preprint arXiv:2505.20279, 2025. 2, 3, 6, 7, 8
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Rao Fu, Jingyu Liu, Xilun Chen, Yixin Nie, and Wen- han Xiong. Scene-llm: Extending language model for 3d visual understanding and reasoning.arXiv preprint arXiv:2403.11401, 2024. 3
-
[13]
Blink: Multimodal large language mod- els can see but not perceive
Xingyu Fu, Yushi Hu, Bangzheng Li, Yu Feng, Haoyu Wang, Xudong Lin, Dan Roth, Noah A Smith, Wei-Chiu Ma, and Ranjay Krishna. Blink: Multimodal large language mod- els can see but not perceive. InEuropean Conference on Computer Vision, pages 148–166. Springer, 2024. 2
work page 2024
-
[14]
Yasutaka Furukawa, Carlos Hern ´andez, et al. Multi-view stereo: A tutorial.Foundations and trends® in Computer Graphics and Vision, 9(1-2):1–148, 2015. 3
work page 2015
-
[15]
Cambridge university press, 2003
Richard Hartley and Andrew Zisserman.Multiple view geom- etry in computer vision. Cambridge university press, 2003. 3
work page 2003
-
[16]
Yining Hong, Haoyu Zhen, Peihao Chen, Shuhong Zheng, Yilun Du, Zhenfang Chen, and Chuang Gan. 3d-llm: Injecting the 3d world into large language models.Advances in Neural Information Processing Systems, 36:20482–20494, 2023. 3
work page 2023
-
[17]
Multi- view transformer for 3d visual grounding
Shijia Huang, Yilun Chen, Jiaya Jia, and Liwei Wang. Multi- view transformer for 3d visual grounding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15524–15533, 2022. 3
work page 2022
-
[18]
Text2scene: Text-driven indoor scene stylization with part- aware details
Inwoo Hwang, Hyeonwoo Kim, and Young Min Kim. Text2scene: Text-driven indoor scene stylization with part- aware details. InProceedings of the ieee/cvf conference on computer vision and pattern recognition, pages 1890–1899,
-
[19]
Ground- ing image matching in 3d with mast3r
Vincent Leroy, Yohann Cabon, and J´erˆome Revaud. Ground- ing image matching in 3d with mast3r. InEuropean Confer- ence on Computer Vision, pages 71–91. Springer, 2024. 2, 3
work page 2024
-
[20]
LLaVA-OneVision: Easy Visual Task Transfer
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Zi- wei Liu, et al. Llava-onevision: Easy visual task transfer. arXiv preprint arXiv:2408.03326, 2024. 7
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Dingming Li, Hongxing Li, Zixuan Wang, Yuchen Yan, Hang Zhang, Siqi Chen, Guiyang Hou, Shengpei Jiang, Wenqi Zhang, Yongliang Shen, et al. Viewspatial-bench: Evaluat- ing multi-perspective spatial localization in vision-language models.arXiv preprint arXiv:2505.21500, 2025. 2
-
[22]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip- 2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InInternational conference on machine learning, pages 19730–19742. PMLR,
-
[23]
Mvbench: A comprehensive multi-modal video understand- ing benchmark
Kunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Yi Liu, Zun Wang, Jilan Xu, Guo Chen, Ping Luo, et al. Mvbench: A comprehensive multi-modal video understand- ing benchmark. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22195– 22206, 2024. 2
work page 2024
-
[24]
V oxformer: Sparse voxel transformer for camera- based 3d semantic scene completion
Yiming Li, Zhiding Yu, Christopher Choy, Chaowei Xiao, Jose M Alvarez, Sanja Fidler, Chen Feng, and Anima Anand- kumar. V oxformer: Sparse voxel transformer for camera- based 3d semantic scene completion. InProceedings of the IEEE/CVF conference on computer vision and pattern recog- nition, pages 9087–9098, 2023. 2
work page 2023
-
[25]
Vila: On pre-training for visual 9 language models
Ji Lin, Hongxu Yin, Wei Ping, Pavlo Molchanov, Mohammad Shoeybi, and Song Han. Vila: On pre-training for visual 9 language models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 26689– 26699, 2024. 7, 8
work page 2024
-
[26]
Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023. 2, 3
work page 2023
-
[27]
Sqa3d: Situated question answering in 3d scenes.arXiv preprint arXiv:2210.07474, 2022
Xiaojian Ma, Silong Yong, Zilong Zheng, Qing Li, Yitao Liang, Song-Chun Zhu, and Siyuan Huang. Sqa3d: Sit- uated question answering in 3d scenes.arXiv preprint arXiv:2210.07474, 2022. 3
-
[28]
Nerf in the wild: Neural radiance fields for uncon- strained photo collections
Ricardo Martin-Brualla, Noha Radwan, Mehdi SM Sajjadi, Jonathan T Barron, Alexey Dosovitskiy, and Daniel Duck- worth. Nerf in the wild: Neural radiance fields for uncon- strained photo collections. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 7210–7219, 2021. 2
work page 2021
-
[29]
Muhammad Ferjad Naeem, Muhammad Gul Zain Ali Khan, Yongqin Xian, Muhammad Zeshan Afzal, Didier Stricker, Luc Van Gool, and Federico Tombari. I2mvformer: Large language model generated multi-view document supervi- sion for zero-shot image classification. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15169–15179, 2023. 2
work page 2023
-
[30]
Global structure-from-motion revisited
Linfei Pan, D´aniel Bar´ath, Marc Pollefeys, and Johannes L Sch¨onberger. Global structure-from-motion revisited. InEuro- pean Conference on Computer Vision, pages 58–77. Springer,
-
[31]
Structure- from-motion revisited
Johannes L Sch¨onberger and Jan-Michael Frahm. Structure- from-motion revisited. InProceedings of the IEEE confer- ence on computer vision and pattern recognition, pages 4104– 4113, 2016. 3
work page 2016
-
[32]
Pixelwise view selection for unstructured multi-view stereo
Johannes L Sch¨onberger, Enliang Zheng, Jan-Michael Frahm, and Marc Pollefeys. Pixelwise view selection for unstructured multi-view stereo. InComputer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, Octo- ber 11-14, 2016, Proceedings, Part III 14, pages 501–518. Springer, 2016. 3
work page 2016
-
[33]
Vipergpt: Vi- sual inference via python execution for reasoning
D´ıdac Sur´ıs, Sachit Menon, and Carl V ondrick. Vipergpt: Vi- sual inference via python execution for reasoning. InProceed- ings of the IEEE/CVF international conference on computer vision, pages 11888–11898, 2023. 3
work page 2023
-
[34]
Vggt: Visual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. Vggt: Visual geometry grounded transformer. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5294–5306, 2025. 2, 3, 6
work page 2025
-
[35]
Continuous 3d perception model with persistent state
Qianqian Wang, Yifei Zhang, Aleksander Holynski, Alexei A Efros, and Angjoo Kanazawa. Continuous 3d perception model with persistent state. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 10510– 10522, 2025. 3
work page 2025
-
[36]
Dust3r: Geometric 3d vision made easy
Shuzhe Wang, Vincent Leroy, Yohann Cabon, Boris Chidlovskii, and Jerome Revaud. Dust3r: Geometric 3d vision made easy. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 20697–20709, 2024. 2, 3
work page 2024
-
[37]
Runsen Xu, Weiyao Wang, Hao Tang, Xingyu Chen, Xi- aodong Wang, Fu-Jen Chu, Dahua Lin, Matt Feiszli, and Kevin J Liang. Multi-spatialmllm: Multi-frame spatial un- derstanding with multi-modal large language models.arXiv preprint arXiv:2505.17015, 2025. 2, 3
-
[38]
Thinking in space: How multimodal large language models see, remember, and recall spaces
Jihan Yang, Shusheng Yang, Anjali W Gupta, Rilyn Han, Li Fei-Fei, and Saining Xie. Thinking in space: How multimodal large language models see, remember, and recall spaces. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 10632–10643, 2025. 2, 3, 7
work page 2025
-
[39]
Seeing from another perspective: Evaluating multi-view understanding in mllms
Chun-Hsiao Yeh, Chenyu Wang, Shengbang Tong, Ta-Ying Cheng, Ruoyu Wang, Tianzhe Chu, Yuexiang Zhai, Yubei Chen, Shenghua Gao, and Yi Ma. Seeing from another perspective: Evaluating multi-view understanding in mllms. arXiv preprint arXiv:2504.15280, 2025. 2
-
[40]
inerf: Inverting neural radiance fields for pose estimation
Lin Yen-Chen, Pete Florence, Jonathan T Barron, Alberto Rodriguez, Phillip Isola, and Tsung-Yi Lin. inerf: Inverting neural radiance fields for pose estimation. In2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 1323–1330. IEEE, 2021. 2
work page 2021
-
[41]
Scannet++: A high-fidelity dataset of 3d indoor scenes
Chandan Yeshwanth, Yueh-Cheng Liu, Matthias Nießner, and Angela Dai. Scannet++: A high-fidelity dataset of 3d indoor scenes. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 12–22, 2023. 4, 5, 6
work page 2023
-
[42]
Neural-symbolic vqa: Dis- entangling reasoning from vision and language understanding
Kexin Yi, Jiajun Wu, Chuang Gan, Antonio Torralba, Push- meet Kohli, and Josh Tenenbaum. Neural-symbolic vqa: Dis- entangling reasoning from vision and language understanding. Advances in neural information processing systems, 31, 2018. 3
work page 2018
-
[43]
CLEVRER: CoLlision Events for Video REpresentation and Reasoning
Kexin Yi, Chuang Gan, Yunzhu Li, Pushmeet Kohli, Jiajun Wu, Antonio Torralba, and Joshua B Tenenbaum. Clevrer: Collision events for video representation and reasoning.arXiv preprint arXiv:1910.01442, 2019. 2
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[44]
Jiahui Zhang, Yurui Chen, Yanpeng Zhou, Yueming Xu, Ze Huang, Jilin Mei, Junhui Chen, Yu-Jie Yuan, Xinyue Cai, Guowei Huang, et al. From flatland to space: Teaching vision-language models to perceive and reason in 3d.arXiv preprint arXiv:2503.22976, 2025. 2, 3
-
[45]
Long Context Transfer from Language to Vision
Peiyuan Zhang, Kaichen Zhang, Bo Li, Guangtao Zeng, Jingkang Yang, Yuanhan Zhang, Ziyue Wang, Haoran Tan, Chunyuan Li, and Ziwei Liu. Long context transfer from language to vision.arXiv preprint arXiv:2406.16852, 2024. 7
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[46]
Llava- next: A strong zero-shot video understanding model, 2024
Yuanhan Zhang, Bo Li, haotian Liu, Yong jae Lee, Liangke Gui, Di Fu, Jiashi Feng, Ziwei Liu, and Chunyuan Li. Llava- next: A strong zero-shot video understanding model, 2024. 6, 7, 8
work page 2024
-
[47]
Mmicl: Empowering vision-language model with multi-modal in-context learn- ing
Haozhe Zhao, Zefan Cai, Shuzheng Si, Xiaojian Ma, Kaikai An, Liang Chen, Zixuan Liu, Sheng Wang, Wenjuan Han, and Baobao Chang. Mmicl: Empowering vision-language model with multi-modal in-context learning.arXiv preprint arXiv:2309.07915, 2023. 2
-
[48]
Lscenellm: Enhancing large 3d scene understanding using adaptive visual preferences
Hongyan Zhi, Peihao Chen, Junyan Li, Shuailei Ma, Xinyu Sun, Tianhang Xiang, Yinjie Lei, Mingkui Tan, and Chuang Gan. Lscenellm: Enhancing large 3d scene understanding using adaptive visual preferences. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 3761–3771, 2025. 3
work page 2025
-
[49]
MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models
Deyao Zhu, Jun Chen, Xiaoqian Shen, Xiang Li, and Mo- hamed Elhoseiny. Minigpt-4: Enhancing vision-language 10 understanding with advanced large language models.arXiv preprint arXiv:2304.10592, 2023. 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[50]
Yiming Zuo, Karhan Kayan, Maggie Wang, Kevin Jeon, Jia Deng, and Thomas L Griffiths. Towards foundation models for 3d vision: How close are we? In2025 International Conference on 3D Vision (3DV), pages 1285–1296. IEEE,
-
[51]
2 11 SpatialMosaic: A Multiview VLM Dataset for Partial Visibility Supplementary Material A. Statistics of SpatialMosaic-Bench We provide detailed statistics ofSpatialMosaic-Benchacross different difficulty levels in Fig. 5. Our benchmark contains total 1M QA pairs distributed across six main task categories: Count, Best-View Selection, Existence, Attribu...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.