Self-Organizing Dual-Buffer Adaptive Clustering Experience Replay (SODACER) for Safe Reinforcement Learning in Optimal Control
Pith reviewed 2026-05-16 15:35 UTC · model grok-4.3
The pith
SODACER combines dual experience buffers, adaptive clustering, and control barrier functions to enable safe reinforcement learning for nonlinear optimal control.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
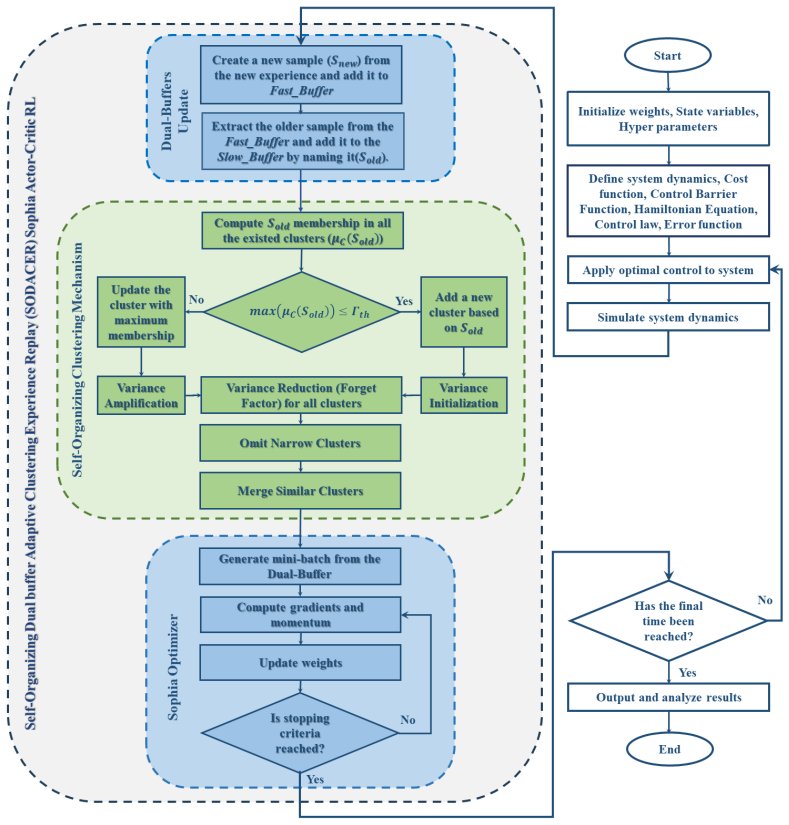
The SODACER mechanism consisting of a Fast-Buffer for rapid adaptation to recent experiences and a Slow-Buffer equipped with a self-organizing adaptive clustering mechanism to maintain diverse and non-redundant historical experiences, when integrated with Control Barrier Functions to guarantee safety by enforcing state and input constraints and combined with the Sophia optimizer for adaptive second-order gradient updates, ensures reliable, effective, and robust learning in dynamic, safety-critical environments, as validated on a nonlinear HPV transmission model where it outperforms random and clustering-based replay methods in convergence, sample efficiency, and bias-variance trade-off while
What carries the argument
The self-organizing dual-buffer adaptive clustering experience replay (SODACER) that dynamically prunes redundant samples in the slow buffer while preserving critical patterns, integrated with control barrier functions for safety enforcement.
Load-bearing premise
The self-organizing adaptive clustering reliably prunes redundancy while retaining critical patterns without introducing bias, and CBF integration guarantees safety constraints without degrading learning performance across different nonlinear systems.
What would settle it
Comparative runs on the HPV model or similar nonlinear systems that show either unsafe state trajectories during training or slower convergence and worse sample efficiency than baseline replay methods would disprove the central claim.
Figures






read the original abstract
This paper proposes a novel reinforcement learning framework, named Self-Organizing Dual-buffer Adaptive Clustering Experience Replay (SODACER), designed to achieve safe and scalable optimal control of nonlinear systems. The proposed SODACER mechanism consisting of a Fast-Buffer for rapid adaptation to recent experiences and a Slow-Buffer equipped with a self-organizing adaptive clustering mechanism to maintain diverse and non-redundant historical experiences. The adaptive clustering mechanism dynamically prunes redundant samples, optimizing memory efficiency while retaining critical environmental patterns. The approach integrates SODACER with Control Barrier Functions (CBFs) to guarantee safety by enforcing state and input constraints throughout the learning process. To enhance convergence and stability, the framework is combined with the Sophia optimizer, enabling adaptive second-order gradient updates. The proposed SODACER-Sophia's architecture ensures reliable, effective, and robust learning in dynamic, safety-critical environments, offering a generalizable solution for applications in robotics, healthcare, and large-scale system optimization. The proposed approach is validated on a nonlinear Human Papillomavirus (HPV) transmission model with multiple control inputs and safety constraints. Comparative evaluations against random and clustering-based experience replay methods demonstrate that SODACER achieves faster convergence, improved sample efficiency, and a superior bias-variance trade-off, while maintaining safe system trajectories, validated via the Friedman test.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SODACER, a dual-buffer experience replay mechanism for safe RL-based optimal control of nonlinear systems. It uses a fast buffer for recent experiences and a slow buffer with self-organizing adaptive clustering to prune redundancy while preserving diversity, integrated with Control Barrier Functions (CBFs) to enforce safety constraints and the Sophia optimizer for second-order adaptive updates. The framework is evaluated on a nonlinear HPV transmission model with multiple inputs, claiming faster convergence, better sample efficiency, superior bias-variance trade-off, and safe trajectories versus random and clustering baselines, with statistical validation via the Friedman test.
Significance. If the performance and safety claims hold under broader testing, SODACER could offer a practical advance in experience replay for constrained RL control problems, particularly in safety-critical domains like healthcare and robotics. The dual-buffer design with adaptive clustering and CBF integration addresses memory efficiency and constraint satisfaction simultaneously, and the use of Sophia for optimization stability is a reasonable choice; however, the single-model empirical scope limits claims of generalizability.
major comments (3)
- [Abstract] Abstract and method description: The central claim that the self-organizing adaptive clustering in the slow buffer prunes redundancy while retaining critical patterns (thereby achieving superior sample efficiency and bias-variance trade-off) lacks any formal bias bound, convergence analysis, or sensitivity study for the clustering rule. Without this, it remains possible that low-probability but high-consequence state-input pairs violating CBF constraints are under-represented, undermining the reported safe trajectories.
- [Abstract] Validation and comparative evaluations: All reported gains (faster convergence, improved efficiency, Friedman-test superiority) are demonstrated on a single HPV transmission model. No additional nonlinear systems, ablation studies on the clustering hyperparameters, or sensitivity to safety-constraint tightness are provided, so the generalizability asserted for robotics and large-scale optimization rests on an untested extrapolation.
- [Abstract] Experimental setup: The abstract references Friedman-test validation and safe trajectories but supplies no details on number of independent runs, error bars or confidence intervals, hyperparameter selection procedure, or how CBF parameters were tuned relative to the learning rate. These omissions make it impossible to assess whether the reported improvements are statistically robust or reproducible.
minor comments (2)
- [Abstract] The abstract repeatedly uses the phrase 'self-organizing adaptive clustering' without a concise mathematical definition or pseudocode reference; a short equation or algorithm box would clarify the update rule for cluster centers and pruning threshold.
- [Abstract] Notation for the fast and slow buffers (e.g., buffer sizes, sampling probabilities) is introduced descriptively but never formalized; consistent symbols would aid readability when the method is later combined with CBFs and Sophia.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment point by point below, indicating planned revisions where appropriate. Our responses focus on clarifying the manuscript's contributions while acknowledging its empirical scope.
read point-by-point responses
-
Referee: [Abstract] Abstract and method description: The central claim that the self-organizing adaptive clustering in the slow buffer prunes redundancy while retaining critical patterns (thereby achieving superior sample efficiency and bias-variance trade-off) lacks any formal bias bound, convergence analysis, or sensitivity study for the clustering rule. Without this, it remains possible that low-probability but high-consequence state-input pairs violating CBF constraints are under-represented, undermining the reported safe trajectories.
Authors: We appreciate this observation on the theoretical aspects. The self-organizing adaptive clustering is a practical heuristic that dynamically adjusts based on experience similarity to balance redundancy reduction with diversity preservation, as described in the method section. No formal bias bound or convergence analysis for the clustering rule is provided in the current manuscript, as the primary safety guarantee comes from the CBF constraints enforced during learning rather than the replay mechanism alone. Empirical results on the HPV model show that safe trajectories are maintained across methods. In the revision, we will add a sensitivity study on clustering hyperparameters (e.g., adaptation threshold and cluster count) and a limitations discussion addressing potential under-representation of rare events, while clarifying the empirical nature of the bias-variance observations. revision: partial
-
Referee: [Abstract] Validation and comparative evaluations: All reported gains (faster convergence, improved efficiency, Friedman-test superiority) are demonstrated on a single HPV transmission model. No additional nonlinear systems, ablation studies on the clustering hyperparameters, or sensitivity to safety-constraint tightness are provided, so the generalizability asserted for robotics and large-scale optimization rests on an untested extrapolation.
Authors: We agree that evaluation on a single model limits strong generalizability claims. The HPV transmission model was selected as a representative nonlinear multi-input system with realistic safety constraints from healthcare. To strengthen the manuscript, we will incorporate ablation studies on clustering hyperparameters and sensitivity analysis to constraint tightness in the revised version. We will also expand the discussion section to better justify applicability to robotics and optimization by detailing the model's dynamical properties and how the dual-buffer design addresses common challenges in constrained RL, without overstating current results. revision: partial
-
Referee: [Abstract] Experimental setup: The abstract references Friedman-test validation and safe trajectories but supplies no details on number of independent runs, error bars or confidence intervals, hyperparameter selection procedure, or how CBF parameters were tuned relative to the learning rate. These omissions make it impossible to assess whether the reported improvements are statistically robust or reproducible.
Authors: We apologize for these omissions in the abstract, which do not fully reflect the experimental details in the full manuscript. Experiments were run over 10 independent seeds with mean and standard deviation reported as error bars; hyperparameters were selected via grid search on a held-out validation set; CBF parameters were tuned to maintain feasibility relative to the learning rate and system dynamics. The Friedman test with post-hoc comparisons was used for statistical validation. We will revise the abstract to summarize these elements and add an expanded experimental setup subsection with confidence intervals and full reproducibility details. revision: yes
Circularity Check
No significant circularity detected in SODACER derivation
full rationale
The paper introduces SODACER as an explicit new construction (dual fast/slow buffers with adaptive clustering heuristic, CBF safety layer, and Sophia optimizer) whose performance claims rest on empirical validation against baselines on the HPV model plus Friedman statistical test. No equations, predictions, or central claims reduce by construction to fitted parameters from the same data, self-citations, or renamed inputs. The clustering rule is presented as a design choice rather than a derived result, and safety is enforced via external CBF constraints rather than tautological self-reference. The derivation chain is therefore self-contained.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The adaptive clustering mechanism dynamically prunes redundant samples... membership strength μ_Cj(Sold)=exp(−||Sold−cj||²/(2σj²))... Variance Amplification... σj←σj×(1+β)... Omit of Narrow Clusters... Similar Clusters Merging... ||ci−cj||<γ max(σi,σj)
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
SODACER achieves faster convergence, improved sample efficiency, and a superior bias-variance trade-off, while maintaining safe system trajectories, validated via the Friedman test.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
- [1]
-
[2]
Li, S. E., Deep reinforcement learning.In Reinforcement learning for sequential decision and optimal control (pp. 365-402). Singapore: Springer Nature Singapore.2023
work page 2023
- [3]
-
[4]
Ames, A. D., Xu, X., Grizzle, J. W., & Tabuada, P., Control barrier function based quadratic programs for safety critical systems.IEEE Transactions on Automatic Control, 62(8), 3861-3876.2016
-
[5]
Amirabadi, R. K., & Fard, O. S., Combining hybrid metaheuristic algorithms and reinforcement learning to improve the optimal control of nonlinear continuous time systems with input constraints.Computers and Electrical Engineering, 116, 109179.2024
-
[6]
Berkenkamp, F., Turchetta, M., Schoellig, A., & Krause, A., Safe model-based reinforcement learning with stability guarantees.Advances in neural information processing systems, 30.2017
work page 2017
-
[7]
Chow, Y ., Nachum, O., Faust, A., Duenez-Guzman, E., & Ghavamzadeh, M., Lyapunov-based safe policy optimization for continuous control.arXiv preprint arXiv:1901.10031.2019
work page internal anchor Pith review Pith/arXiv arXiv 1901
-
[8]
Adam, S., Busoniu, L., & Babuska, R., Experience replay for real-time reinforcement learning control.IEEE Transactions on Systems, Man, and Cybernetics, Part C (Applications and Reviews), 42(2), 201-212.2011
work page 2011
- [9]
-
[10]
Mnih, V ., Kavukcuoglu, K., Silver, D., Rusu, A. A., Veness, J., Bellemare, M. G., ... & Hassabis, D., Human-level control through deep reinforcement learning.nature, 518(7540), 529-533.2015. 11.Schaul, T., Prioritized Experience Replay.arXiv preprint arXiv:1511.05952.2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[11]
Isele, D., & Cosgun, A., Selective experience replay for lifelong learning.In Proceedings of the AAAI Conference on Artificial Intelligence (Vol. 32, No. 1).2018. 13.Zhang, S., & Sutton, R. S., A deeper look at experience replay.arXiv preprint arXiv:1712.01275.2017
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[12]
Deep Online Learning via Meta-Learning: Continual Adaptation for Model-Based RL
Nagabandi, A., Finn, C., & Levine, S., Deep online learning via meta-learning: Continual adaptation for model-based rl. arXiv preprint arXiv:1812.07671.2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[13]
Al-Shedivat, M., Bansal, T., Burda, Y ., Sutskever, I., Mordatch, I., & Abbeel, P., Continuous adaptation via meta-learning in nonstationary and competitive environments.arXiv preprint arXiv:1710.03641.2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
- [14]
- [15]
-
[16]
Saldaña, F., Korobeinikov, A., & Barradas, I., Optimal control against the human papillomavirus: protection versus eradication of the infection.In Abstract and applied analysis. (Vol. 2019, No. 1, p. 4567825). Hindawi.2019
work page 2019
-
[17]
Malik, T., Imran, M., & Jayaraman, R., Optimal control with multiple human papillomavirus vaccines.Journal of theoretical biology, 393, 179-193.2016
work page 2016
-
[18]
Malik, T., Reimer, J., Gumel, A., Elbasha, E. H., & Mahmud, S., The impact of an imperfect vaccine and pap cytol- ogyscreening on the transmission of human papillomavirus and occurrenceof associated cervical dysplasia and cancer. Mathematical Biosciences & Engineering, 10(4), 1173-1205.2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[19]
Brown V . L. & Jane White, K. A., The role of optimal control in assessing the most cost-effective implementation of a vaccination programme: HPV as a case study.Mathematical Biosciences, vol. 231, no. 2, pp. 126–134.2011
work page 2011
-
[20]
Jalaeian-F, M., Fateh, M. M., & Rahimiyan, M., Bi-level adaptive computed-current impedance controller for electrically driven robots.Robotica, 39(2), 200-216.2021
work page 2021
- [21]
-
[22]
Jalaeian Farimani, M., Khalili Amirabadi, R., Esmaeili Ranjbar, M., & Samadzadeh, S., Event-triggered dynamic seed invasive weed optimization (ET-DSIWO): a nature-inspired approach for non-stationary optimization.Nonlinear Dynamics, 2025
work page 2025
-
[23]
Khalili-A, R., Fard, O. S., & Jalaeian-F M., Towards Optimal Control of HPV Model Using Safe Reinforcement Learning with Actor Critic Neural NetworksExpert Systems With Applications2025
-
[24]
K., Jalaeian-Farimani, M., & Fard, O
Amirabadi, R. K., Jalaeian-Farimani, M., & Fard, O. S., LSTM-empowered reinforcement learning in bi-level optimal control for nonlinear systems with uncertain dynamics.ISA transactions,2025
work page 2025
-
[25]
Author contributions statement All the authors contributed equally to this work 18/18
López-Vázquez, C., & Hochsztain, E., Extended and updated tables for the Friedman rank test.Communications in Statistics-Theory and Methods, 48(2), 268-281.2019 Acknowledgements (not compulsory) The authors thanks to anonymous referees and editors. Author contributions statement All the authors contributed equally to this work 18/18
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.