Recognition: 2 theorem links
· Lean TheoremEmergent Structured Representations Support Flexible In-Context Inference in Large Language Models
Pith reviewed 2026-05-16 06:48 UTC · model grok-4.3
The pith
Large language models construct a persistent conceptual subspace in middle layers that causally drives in-context inference.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
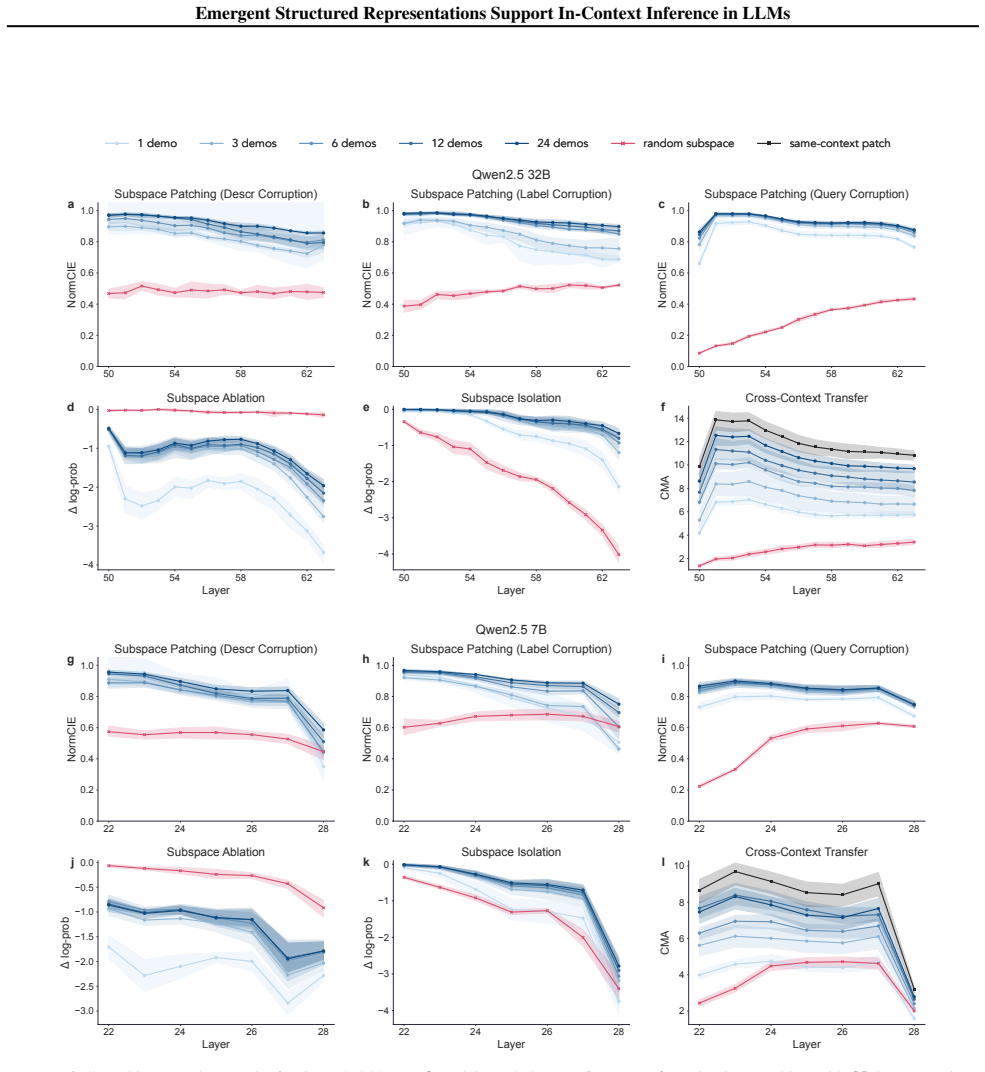
LLMs dynamically build a conceptual subspace in middle-to-late layers whose representational structure remains stable across contexts. Attention heads in early-to-middle layers integrate contextual cues to construct and refine the subspace. Later layers then leverage this subspace to generate predictions. Causal mediation analyses confirm the subspace plays a direct functional role in inference rather than arising as a byproduct.
What carries the argument
The conceptual subspace, a persistent structured representation in middle-to-late layers that encodes contextual information and supports inference.
If this is right
- Early-to-middle attention heads integrate contextual cues to build the subspace.
- Later layers depend on the subspace to generate final predictions.
- Altering activity in the subspace changes model outputs on inference tasks.
- LLMs achieve flexible adaptation by constructing and reusing these latent structures.
Where Pith is reading between the lines
- The same subspace mechanism may support other emergent behaviors such as multi-step reasoning.
- Focusing interpretability tools on this subspace could enable more targeted editing of model behavior.
- The layer-wise progression offers a concrete target for testing whether smaller models exhibit the same internal structure.
- Extending the analysis to non-text modalities could show whether the subspace construction is modality-specific.
Load-bearing premise
The chosen causal mediation interventions isolate the subspace's contribution without creating artifacts or overlooking other pathways in the model's computation.
What would settle it
Targeted disruption of the identified subspace through ablation or activation patching produces no measurable change in the model's accuracy on in-context inference tasks.
Figures






















read the original abstract
Large language models (LLMs) exhibit emergent behaviors suggestive of human-like reasoning. While recent work has identified structured conceptual representations within these models, it remains unclear whether they functionally rely on such representations for reasoning. Here we investigate the internal processing of LLMs during in-context inference across diverse tasks. Our results reveal a conceptual subspace emerging in middle to late layers, whose representational structure persists across contexts. Using causal mediation analyses, we demonstrate that this subspace is not merely an epiphenomenon but is functionally central to model predictions, establishing its causal role in inference. We further identify a layer-wise progression where attention heads in early-to-middle layers integrate contextual cues to construct and refine the subspace, which is subsequently leveraged by later layers to generate predictions. Together, these findings provide evidence that LLMs dynamically construct and use structured latent representations in context for inference, offering insights into the computational processes underlying flexible adaptation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that LLMs dynamically construct a persistent conceptual subspace in middle-to-late layers during in-context inference across tasks. Attention heads in early-to-middle layers integrate contextual cues to build and refine this subspace, which later layers then leverage for predictions. Causal mediation analyses are used to argue that the subspace is not epiphenomenal but plays a functionally causal role in model outputs.
Significance. If the causal mediation results hold under rigorous controls for parallel pathways, the work would offer a mechanistic account of how structured latent representations enable flexible in-context adaptation in transformers, strengthening links between interpretability findings and emergent reasoning behaviors.
major comments (2)
- [Abstract and Methods] Abstract and Methods: The causal mediation claim that the subspace is 'functionally central to model predictions' rests on interventions whose ability to isolate the subspace is not demonstrated. In a transformer, the subspace is built via attention integration in middle layers; without explicit controls that also ablate or orthogonalize residual streams and unpatched attention heads, measured effects on logits could be carried by confounding pathways rather than the target subspace.
- [Results] Results (layer-wise progression): The description of the progression from contextual integration to subspace readout lacks quantitative metrics (e.g., intervention effect sizes, ablation baselines, or statistical controls) showing that the identified subspace accounts for the bulk of the predictive signal once parallel routes are blocked.
minor comments (1)
- [Abstract] Abstract: The term 'conceptual subspace' is introduced without a precise operational definition (e.g., how it is extracted from activations or what dimensionality it occupies), which could be clarified for readers.
Simulated Author's Rebuttal
Thank you for the constructive feedback on our manuscript. We address each major comment below, agreeing that additional controls and quantitative metrics will strengthen the causal claims. We propose revisions accordingly.
read point-by-point responses
-
Referee: [Abstract and Methods] The causal mediation claim that the subspace is 'functionally central to model predictions' rests on interventions whose ability to isolate the subspace is not demonstrated. In a transformer, the subspace is built via attention integration in middle layers; without explicit controls that also ablate or orthogonalize residual streams and unpatched attention heads, measured effects on logits could be carried by confounding pathways rather than the target subspace.
Authors: We agree that rigorous isolation from parallel pathways is essential to support the causal claim. Our mediation interventions target subspace activations while preserving other components, but we acknowledge the potential for confounding. In the revision, we will add explicit controls that ablate or orthogonalize residual streams and unpatched attention heads to demonstrate that measured logit effects are attributable to the subspace rather than alternative routes. revision: yes
-
Referee: [Results] The description of the progression from contextual integration to subspace readout lacks quantitative metrics (e.g., intervention effect sizes, ablation baselines, or statistical controls) showing that the identified subspace accounts for the bulk of the predictive signal once parallel routes are blocked.
Authors: We will strengthen this section with quantitative support. The revised manuscript will include intervention effect sizes, ablation baselines (comparing subspace interventions to full-model and parallel-pathway-ablated performance), and statistical controls to show the subspace accounts for the majority of the predictive signal after blocking parallel routes. revision: yes
Circularity Check
No circularity: empirical causal mediation stands independent of inputs
full rationale
The paper's core argument rests on experimental identification of a conceptual subspace via activation analysis followed by causal mediation interventions to test functional necessity. No equations, fitted parameters, or derivations are presented that reduce to the inputs by construction. The subspace is located observationally in middle-to-late layers and its causal role is assessed through interventions on model activations; these steps are falsifiable against held-out data and do not rely on self-referential definitions, self-citation chains, or renaming of known results. The provided abstract and skeptic notes contain no load-bearing self-citations or ansatz smuggling that would collapse the claim into its own premises.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Causal mediation analysis can isolate the functional role of specific subspaces in transformer forward passes
invented entities (1)
-
conceptual subspace
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We applied singular value decomposition (SVD) to Xℓ and retained the top k principal components... GCCA to isolate a shared subspace... activation patching... hpatchℓ = hcorrℓ + Pℓ(hcleanℓ − hcorrℓ)
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
layer-wise progression where attention heads in early-to-middle layers integrate contextual cues to construct and refine the subspace
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Benton, A., Khayrallah, H., Gujral, B., Reisinger, D. A., Zhang, S., and Arora, R. Deep generalized canonical correlation analysis. In Augenstein, I., Gella, S., Ruder, S., Kann, K., Can, B., Welbl, J., Conneau, A., Ren, X., and Rei, M. (eds.),Proceedings of the 4th Workshop on Representation Learning for NLP (RepL4NLP-2019), pp. 1–6, Florence, Italy, August
work page 2019
-
[2]
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., Agarwal, S., Herbert-V oss, A., Krueger, G., Henighan, T., Child, R., Ramesh, A., Ziegler, D., Wu, J., Winter, C., Hesse, C., Chen, M., Sigler, E., Litwin, M., Gray, S., Chess, B., Clark, J., Berner, C., McCandlish, S., Radford, A....
work page 1901
-
[3]
Sparks of Artificial General Intelligence: Early experiments with GPT-4
Bubeck, S., Chandrasekaran, V ., Eldan, R., Gehrke, J., Horvitz, E., Kamar, E., Lee, P., Lee, Y . T., Li, Y ., Lundberg, S., et al. Sparks of artificial general intel- ligence: Early experiments with gpt-4.arXiv preprint arXiv:2303.12712,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
ISSN 2045-2322. Elhage, N., Nanda, N., Olsson, C., Henighan, T., Joseph, N., Mann, B., Askell, A., Bai, Y ., Chen, A., Conerly, T., et al. A mathematical framework for transformer circuits. Transformer Circuits Thread, 1(1):12,
work page 2045
-
[5]
Do neural language representations learn physical commonsense?arXiv preprint arXiv:1908.02899,
Forbes, M., Holtzman, A., and Choi, Y . Do neural language representations learn physical commonsense?arXiv preprint arXiv:1908.02899,
-
[6]
Dis- secting recall of factual associations in auto-regressive language models
Geva, M., Bastings, J., Filippova, K., and Globerson, A. Dis- secting recall of factual associations in auto-regressive language models. In Bouamor, H., Pino, J., and Bali, K. (eds.),Proceedings of the 2023 Conference on Em- pirical Methods in Natural Language Processing, pp. 12216–12235, Singapore, December
work page 2023
-
[7]
Association for Computational Linguistics. Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Vaughan, A., et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
10 Emergent Structured Representations Support In-Context Inference in LLMs Griffiths, T. L., Lake, B. M., McCoy, R. T., Pavlick, E., and Webb, T. W. Whither symbols in the era of advanced neu- ral networks?arXiv preprint arXiv:2508.05776,
- [9]
-
[10]
In-context learning creates task vectors
Hendel, R., Geva, M., and Globerson, A. In-context learning creates task vectors. In Bouamor, H., Pino, J., and Bali, K. (eds.),Findings of the Association for Computational Linguistics: EMNLP 2023, pp. 9318–9333, Singapore, December
work page 2023
-
[11]
Lampinen, A. K., Chan, S. C., Singh, A. K., and Shanahan, M. The broader spectrum of in-context learning.arXiv preprint arXiv:2412.03782, 2024a. Lampinen, A. K., Dasgupta, I., Chan, S. C. Y ., Sheahan, H. R., Creswell, A., Kumaran, D., McClelland, J. L., and Hill, F. Language models, like humans, show content effects on reasoning tasks.PNAS Nexus, 3(7):pg...
-
[12]
Min, S., Lyu, X., Holtzman, A., Artetxe, M., Lewis, M., Hajishirzi, H., and Zettlemoyer, L. Rethinking the role of demonstrations: What makes in-context learning work? In Goldberg, Y ., Kozareva, Z., and Zhang, Y . (eds.),Pro- ceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pp. 11048–11064, Abu Dhabi, United Arab Emira...
work page 2022
-
[13]
In-context Learning and Induction Heads
Association for Computational Linguistics. Olsson, C., Elhage, N., Nanda, N., Joseph, N., DasSarma, N., Henighan, T., Mann, B., Askell, A., Bai, Y ., Chen, A., et al. In-context learning and induction heads.arXiv preprint arXiv:2209.11895,
work page internal anchor Pith review Pith/arXiv arXiv
- [14]
-
[15]
ISSN 1364-6613. Qwen, :, Yang, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Li, C., Liu, D., Huang, F., Wei, H., Lin, H., Yang, J., Tu, J., Zhang, J., Yang, J., Yang, J., Zhou, J., Lin, J., Dang, K., Lu, K., Bao, K., Yang, K., Yu, L., Li, M., Xue, M., Zhang, P., Zhu, Q., Men, R., Lin, R., Li, T., Tang, T., Xia, T., Ren, X., Ren, X., Fan, Y ., Su, ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
HuggingFace's Transformers: State-of-the-art Natural Language Processing
Wolf, T., Debut, L., Sanh, V ., Chaumond, J., Delangue, C., Moi, A., Cistac, P., Rault, T., Louf, R., Funtowicz, M., et al. Huggingface’s transformers: State-of-the-art natural language processing.arXiv preprint arXiv:1910.03771,
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[17]
Wu, Z., Qiu, L., Ross, A., Aky ¨urek, E., Chen, B., Wang, B., Kim, N., Andreas, J., and Kim, Y . Reasoning or reciting? exploring the capabilities and limitations of language models through counterfactual tasks. In Duh, K., Gomez, H., and Bethard, S. (eds.),Proceedings of the 2024 Conference of the North American Chapter of the Association for Computation...
work page 2024
-
[18]
Xu, N., Zhang, Q., Zhang, M., Qian, P., and Huang, X. On the tip of the tongue: Analyzing conceptual representation in large language models with reverse-dictionary probe. arXiv preprint arXiv:2402.14404,
-
[19]
13 Emergent Structured Representations Support In-Context Inference in LLMs A. Data, Code, and Materials Availability This work uses publicly available datasets and materials (Hebart et al., 2019; Todd et al., 2024; Nguyen et al., 2017; Hernandez et al., 2024). Code for reproducing all experiments is available at https://github.com/ningyuxu/ llm_structure...
work page 2019
-
[20]
(available at https://osf.io/ jum2f/), which contains 1,854 concrete, nameable object concepts selected to be representative of everyday objects commonly used in American English. Each concept is paired with its WordNet synset ID, definitional descriptions, and multiple associated images, providing a suitable testbed for analyzing conceptual representatio...
work page 2024
-
[21]
(https://huggingface.co). Series Model #Layers Sel. Layers (0-indexed) Dim. Subspace Dim. Llama 3.1 meta-llama/Llama-3.1-70B meta-llama/Llama-3.1-8B 81 33 38–79 16–31 8192 4096 1180 [1176–1181] 1250 [1242–1254] Llama 3meta-llama/Meta-Llama-3-8B33 16–31 4096 1245 [1244–1249] Qwen2.5 Qwen/Qwen2.5-32B Qwen/Qwen2.5-7B Qwen/Qwen2.5-3B 65 29 37 50–63 22–28 32–3...
work page 2048
-
[22]
(2024) (https://github.com/ericwtodd/function_vectors)
( https://osf.io/jum2f/); data for the remaining four tasks were taken from Todd et al. (2024) (https://github.com/ericwtodd/function_vectors). Task Examples Source Concept Inference a small very thin pancake⇒crepe a small guitar having four strings⇒ukulele dried grape⇒raisin Hebart et al. (2019) Antonym true⇒false difficult⇒easy proceed⇒halt Nguyen et al...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.