Recognition: 2 theorem links
· Lean TheoremSpecificity-aware reinforcement learning for fine-grained open-world classification
Pith reviewed 2026-05-15 16:41 UTC · model grok-4.3
The pith
A reinforcement learning method steers large multimodal models toward both correct and specific predictions in open-world fine-grained image classification.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SpeciaRL fine-tunes reasoning LMMs for fine-grained image classification under the open-world setting by introducing a dynamic, verifier-based reward signal anchored to the best predictions within online rollouts, promoting specificity while respecting the model's capabilities to prevent incorrect predictions.
What carries the argument
The verifier-based reward signal anchored to the best predictions within online rollouts, which encourages more specific outputs without reducing correctness.
If this is right
- SpeciaRL delivers the best trade-off between correctness and specificity across extensive fine-grained benchmarks.
- The method surpasses existing approaches in out-of-domain experiments for open-world fine-grained image classification.
- Reasoning LMMs can be steered to use their intrinsic fine-grained knowledge more effectively through this rollout-based reward design.
- Open-world fine-grained classification advances by balancing accuracy and detail without relying on a predefined label set.
Where Pith is reading between the lines
- The same rollout-verification reward pattern could be tested on tasks such as generating detailed image captions or attribute lists where specificity also matters.
- Similar mechanisms might reduce overly broad outputs when LMMs are applied to medical or scientific image domains with subtle distinctions.
- Extending the approach to video or 3D data would require checking whether the verifier remains reliable across temporal or spatial rollouts.
- Combining SpeciaRL with other alignment techniques could further stabilize performance when the model encounters entirely novel fine-grained categories.
Load-bearing premise
The verifier-based reward signal derived from online rollouts can reliably promote specificity without introducing bias or reducing the model's ability to produce correct predictions on unseen fine-grained concepts.
What would settle it
An experiment in which models fine-tuned with SpeciaRL show either lower accuracy on held-out fine-grained classes or no measurable increase in specificity compared with standard fine-tuning or prompting baselines.
Figures















read the original abstract
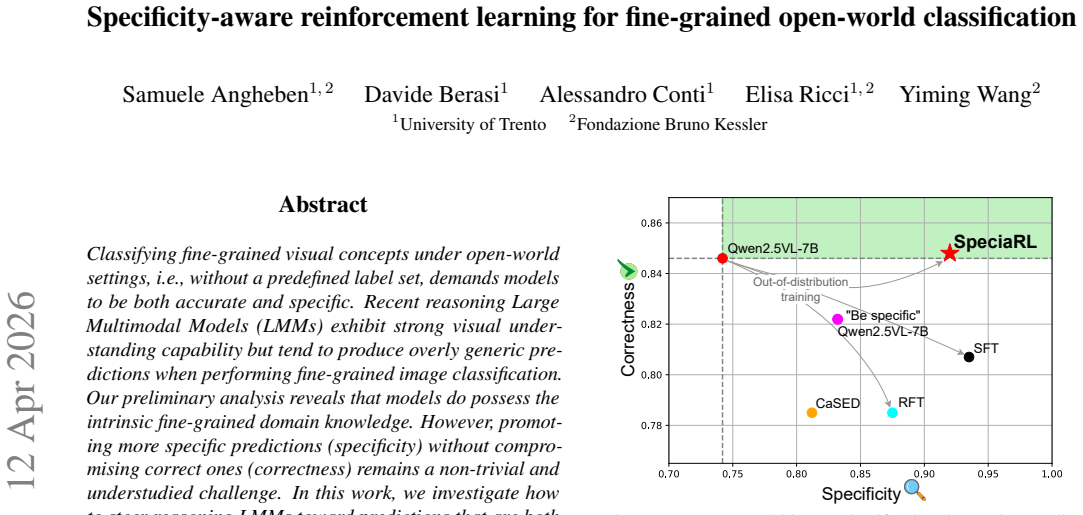
Classifying fine-grained visual concepts under open-world settings, i.e., without a predefined label set, demands models to be both accurate and specific. Recent reasoning Large Multimodal Models (LMMs) exhibit strong visual understanding capability but tend to produce overly generic predictions when performing fine-grained image classification. Our preliminary analysis reveals that models do possess the intrinsic fine-grained domain knowledge. However, promoting more specific predictions (specificity) without compromising correct ones (correctness) remains a non-trivial and understudied challenge. In this work, we investigate how to steer reasoning LMMs toward predictions that are both correct and specific. We propose a novel specificity-aware reinforcement learning framework, SpeciaRL, to fine-tune reasoning LMMs on fine-grained image classification under the open-world setting. SpeciaRL introduces a dynamic, verifier-based reward signal anchored to the best predictions within online rollouts, promoting specificity while respecting the model's capabilities to prevent incorrect predictions. Our out-of-domain experiments show that SpeciaRL delivers the best trade-off between correctness and specificity across extensive fine-grained benchmarks, surpassing existing methods and advancing open-world fine-grained image classification. Code and model are publicly available at https://github.com/s-angheben/SpeciaRL.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SpeciaRL, a specificity-aware reinforcement learning framework for fine-tuning reasoning large multimodal models on fine-grained open-world image classification. It introduces a dynamic verifier-based reward signal derived from the best predictions among online rollouts to promote specificity while respecting model capabilities and avoiding incorrect predictions, claiming superior correctness-specificity trade-offs on out-of-domain benchmarks relative to prior methods.
Significance. If the empirical claims hold after clarification, the work would advance open-world fine-grained classification by providing a practical RL mechanism to steer LMMs toward more precise outputs without accuracy loss. The public release of code and models supports reproducibility.
major comments (2)
- [Abstract] Abstract: the central claim of best trade-off on extensive out-of-domain benchmarks is asserted without any reported metrics, baselines, statistical tests, or verifier implementation details, leaving the empirical support for the main result invisible.
- [Method] Method (verifier reward definition): the dynamic reward anchored to the 'best' rollout prediction requires an explicit definition of the verifier (e.g., separate model, rule-based, or self-consistency) and the scoring rule for 'best' when ground truth is unavailable; without this, it is impossible to verify that specificity gains are not achieved at the expense of correctness on unseen fine-grained classes.
minor comments (1)
- [Abstract] The abstract would benefit from naming the specific fine-grained benchmarks and at least one quantitative result to ground the superiority claim.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments on our manuscript. We address each major comment below and propose revisions to improve clarity and completeness.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of best trade-off on extensive out-of-domain benchmarks is asserted without any reported metrics, baselines, statistical tests, or verifier implementation details, leaving the empirical support for the main result invisible.
Authors: We agree that the abstract, as a high-level summary, omits specific numbers to maintain brevity. The full paper includes comprehensive results in Section 4 with metrics, baselines, and analyses demonstrating the best trade-off. In the revised version, we will incorporate key empirical highlights into the abstract, such as the superior performance on out-of-domain benchmarks, and ensure a brief reference to the verifier approach. revision: yes
-
Referee: [Method] Method (verifier reward definition): the dynamic reward anchored to the 'best' rollout prediction requires an explicit definition of the verifier (e.g., separate model, rule-based, or self-consistency) and the scoring rule for 'best' when ground truth is unavailable; without this, it is impossible to verify that specificity gains are not achieved at the expense of correctness on unseen fine-grained classes.
Authors: Thank you for this important clarification request. The current manuscript introduces the verifier-based reward in Section 3 but does not provide sufficient implementation details. We will revise the method section to explicitly define the verifier (as a self-consistency mechanism across rollouts combined with a specificity scoring rule based on prediction granularity), and detail the scoring for selecting the 'best' prediction without ground truth by prioritizing consistent and specific outputs while penalizing potential inaccuracies through capability-aware clipping. This will include pseudocode and examples to allow verification that correctness is preserved. revision: yes
Circularity Check
No circularity: empirical RL method with no self-referential derivations or fitted predictions
full rationale
The paper proposes SpeciaRL as an empirical reinforcement learning framework that introduces a dynamic verifier-based reward anchored to online rollouts. No equations, derivations, or parameter-fitting steps are presented that reduce the claimed trade-off between correctness and specificity to a self-definition, fitted input, or self-citation chain. The approach is described as steering LMMs via RL without invoking uniqueness theorems, ansatzes smuggled through citations, or renaming known results. The central claim rests on experimental outcomes rather than a closed mathematical loop, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Marwa Abdulhai, Isadora White, Charlie Snell, Charles Sun, Joey Hong, Yuexiang Zhai, Kelvin Xu, and Sergey Levine. Lmrl gym: Benchmarks for multi-turn reinforcement learning with language models.arXiv preprint arXiv:2311.18232,
-
[2]
Flamingo: a visual language model for few-shot learning.NeurIPS, 2022
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, et al. Flamingo: a visual language model for few-shot learning.NeurIPS, 2022. 2
work page 2022
-
[3]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923, 2025. 1, 2, 4, 5, 6, 7, 16, 17
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Towards open world recognition
Abhijit Bendale and Terrance Boult. Towards open world recognition. InCVPR, pages 1893–1902, 2015. 1
work page 1902
-
[5]
Food-101–mining discriminative components with random forests
Lukas Bossard, Matthieu Guillaumin, and Luc Van Gool. Food-101–mining discriminative components with random forests. InECCV, 2014. 4, 16, 17, 19
work page 2014
-
[6]
Zhe Chen, Weiyun Wang, Yue Cao, Yangzhou Liu, Zhang- wei Gao, Erfei Cui, Jinguo Zhu, Shenglong Ye, Hao Tian, Zhaoyang Liu, et al. Expanding performance boundaries of open-source multimodal models with model, data, and test- time scaling.arXiv preprint arXiv:2412.05271, 2024. 7, 16, 17
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Internvl: Scaling up vision foundation mod- els and aligning for generic visual-linguistic tasks
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al. Internvl: Scaling up vision foundation mod- els and aligning for generic visual-linguistic tasks. InCVPR,
-
[8]
V ocabulary-free image classification.NeurIPS, 2023
Alessandro Conti, Enrico Fini, Massimiliano Mancini, Paolo Rota, Yiming Wang, and Elisa Ricci. V ocabulary-free image classification.NeurIPS, 2023. 1, 6, 7, 16, 17
work page 2023
-
[9]
On large multimodal models as open-world image classifiers
Alessandro Conti, Massimiliano Mancini, Enrico Fini, Yim- ing Wang, Paolo Rota, and Elisa Ricci. On large multimodal models as open-world image classifiers. InICCV, 2025. 1, 2, 3, 4, 5, 6, 7, 12, 14, 19
work page 2025
-
[10]
Bryan LM de Oliveira, Felipe V Frujeri, Marcos PCM Queiroz, Luana GB Martins, Telma W de L Soares, and Luckeciano C Melo. Learning without critics? revisiting grpo in classical reinforcement learning environments.arXiv preprint arXiv:2511.03527, 2025. 8
-
[11]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. InCVPR, pages 248–255. Ieee, 2009. 1
work page 2009
-
[12]
The llama 3 herd of models.arXiv e-prints, pages arXiv–2407,
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Ab- hishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. The llama 3 herd of models.arXiv e-prints, pages arXiv–2407,
-
[13]
Mme: A comprehensive evaluation benchmark for multi- modal large language models, 2023
Chaoyou Fu, Peixian Chen, Yunhang Shen, Yulei Qin, Meng- dan Zhang, Xu Lin, Jinrui Yang, Xiawu Zheng, Ke Li, Xing Sun, Yunsheng Wu, Rongrong Ji, Caifeng Shan, and Ran He. Mme: A comprehensive evaluation benchmark for multi- modal large language models, 2023. 2
work page 2023
-
[14]
Rubrics as Rewards: Reinforcement Learning Beyond Verifiable Domains
Anisha Gunjal, Anthony Wang, Elaine Lau, Vaskar Nath, Yunzhong He, Bing Liu, and Sean Hendryx. Rubrics as rewards: Reinforcement learning beyond verifiable domains. arXiv preprint arXiv:2507.17746, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025. 2, 3, 5, 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jiajun Zhang, Bowen Yu, Keming Lu, et al. Qwen2. 5-coder technical report.arXiv preprint arXiv:2409.12186, 2024. 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, et al. Openai o1 system card.arXiv preprint arXiv:2412.16720, 2024. 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Scaling up visual and vision-language representation learning with noisy text supervision
Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc Le, Yun-Hsuan Sung, Zhen Li, and Tom Duerig. Scaling up visual and vision-language representation learning with noisy text supervision. InICML, pages 4904–
-
[19]
Large language models are zero-shot reasoners.NeurIPS, 35:22199–22213, 2022
Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. Large language models are zero-shot reasoners.NeurIPS, 35:22199–22213, 2022. 2
work page 2022
-
[20]
3d object representations for fine-grained categorization
Jonathan Krause, Michael Stark, Jia Deng, and Li Fei-Fei. 3d object representations for fine-grained categorization. In ICCV-WS, 2013. 4, 17
work page 2013
-
[21]
Efficient memory management for large language model serving with pagedattention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. InProceedings of the symposium on operating systems principles, pages 611– 626, 2023. 12, 14
work page 2023
-
[22]
Tulu 3: Pushing Frontiers in Open Language Model Post-Training
Nathan Lambert, Jacob Morrison, Valentina Pyatkin, Shengyi Huang, Hamish Ivison, Faeze Brahman, Lester James V Mi- randa, Alisa Liu, Nouha Dziri, Shane Lyu, et al. Tulu 3: Push- ing frontiers in open language model post-training.arXiv preprint arXiv:2411.15124, 2024. 3, 5
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
The measurement of observer agreement for categorical data.biometrics, 1977
J Richard Landis and Gary G Koch. The measurement of observer agreement for categorical data.biometrics, 1977. 20
work page 1977
-
[24]
Seed-bench: Benchmarking multimodal large language models
Bohao Li, Yuying Ge, Yixiao Ge, Guangzhi Wang, Rui Wang, Ruimao Zhang, and Ying Shan. Seed-bench: Benchmarking multimodal large language models. InCVPR, 2024. 2
work page 2024
-
[25]
Llava- next: Stronger llms supercharge multimodal capabilities in the wild, 2024
Bo Li, Kaichen Zhang, Hao Zhang, Dong Guo, Renrui Zhang, Feng Li, Yuanhan Zhang, Ziwei Liu, and Chunyuan Li. Llava- next: Stronger llms supercharge multimodal capabilities in the wild, 2024. 1
work page 2024
-
[26]
LLaVA-OneVision: Easy Visual Task Transfer
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Zi- wei Liu, et al. Llava-onevision: Easy visual task transfer. arXiv preprint arXiv:2408.03326, 2024. 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip- 2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InICML, 2023. 1, 2
work page 2023
-
[28]
Mvbench: A comprehensive multi-modal video understand- ing benchmark
Kunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Yi Liu, Zun Wang, Jilan Xu, Guo Chen, Ping Luo, et al. Mvbench: A comprehensive multi-modal video understand- ing benchmark. InCVPR, 2024. 2
work page 2024
-
[29]
Ming Li, Jike Zhong, Shitian Zhao, Yuxiang Lai, and Kaipeng Zhang. Think or not think: A study of explicit thinking in rule-based visual reinforcement fine-tuning.arXiv preprint arXiv:2503.16188, 2025. 3, 6
-
[30]
Huan Liu, Lingyu Xiao, Jiangjiang Liu, Xiaofan Li, Ze Feng, Sen Yang, and Jingdong Wang. Revisiting mllms: An in- depth analysis of image classification abilities.arXiv preprint arXiv:2412.16418, 2024. 1, 2
-
[31]
Mmbench: Is your multi-modal model an all-around player? InECCV, 2024
Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, et al. Mmbench: Is your multi-modal model an all-around player? InECCV, 2024. 2
work page 2024
-
[32]
Understanding R1-Zero-Like Training: A Critical Perspective
Zichen Liu, Changyu Chen, Wenjun Li, Penghui Qi, Tianyu Pang, Chao Du, Wee Sun Lee, and Min Lin. Understanding r1-zero-like training: A critical perspective.arXiv preprint arXiv:2503.20783, 2025. 20
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Visual-RFT: Visual Reinforcement Fine-Tuning
Ziyu Liu, Zeyi Sun, Yuhang Zang, Xiaoyi Dong, Yuhang Cao, Haodong Duan, Dahua Lin, and Jiaqi Wang. Visual-rft: Visual reinforcement fine-tuning.arXiv preprint arXiv:2503.01785,
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
Fine-Grained Visual Classification of Aircraft
Subhransu Maji, Esa Rahtu, Juho Kannala, Matthew Blaschko, and Andrea Vedaldi. Fine-grained visual clas- sification of aircraft.arXiv preprint arXiv:1306.5151, 2013. 4, 17
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[35]
Automated flower classification over a large number of classes
Maria-Elena Nilsback and Andrew Zisserman. Automated flower classification over a large number of classes. InIndian conference on computer vision, graphics & image processing. IEEE, 2008. 4, 16, 17, 19
work page 2008
-
[36]
Training language models to follow instructions with human feedback.NeurIPS, 35:27730–27744, 2022
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Car- roll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.NeurIPS, 35:27730–27744, 2022. 2
work page 2022
-
[37]
Omkar M Parkhi, Andrea Vedaldi, Andrew Zisserman, and CV Jawahar. Cats and dogs. InCVPR, 2012. 4, 16, 17, 19
work page 2012
-
[38]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InICML, 2021. 1, 2, 6
work page 2021
-
[39]
Lars Schmarje, Monty Santarossa, Simon-Martin Schr¨oder, and Reinhard Koch. A survey on semi-, self-and unsupervised learning for image classification.IEEE Access, 9:82146– 82168, 2021. 1
work page 2021
-
[40]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathe- matical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024. 2, 3, 6, 20
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[41]
HybridFlow: A Flexible and Efficient RLHF Framework
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient rlhf frame- work.arXiv preprint arXiv:2409.19256, 2024. 6, 14
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[42]
Flava: A foundational language and vision alignment model
Amanpreet Singh, Ronghang Hu, Vedanuj Goswami, Guil- laume Couairon, Wojciech Galuba, Marcus Rohrbach, and Douwe Kiela. Flava: A foundational language and vision alignment model. InCVPR, 2022. 2
work page 2022
-
[43]
Taxonomy-aware evaluation of vision-language models
V´esteinn Snæbjarnarson, Kevin Du, Niklas Stoehr, Serge Belongie, Ryan Cotterell, Nico Lang, and Stella Frank. Taxonomy-aware evaluation of vision-language models. In CVPR, pages 9109–9120, 2025. 2, 3
work page 2025
-
[44]
Learning to summarize with human feedback.NeurIPS, 33:3008–3021, 2020
Nisan Stiennon, Long Ouyang, Jeffrey Wu, Daniel Ziegler, Ryan Lowe, Chelsea V oss, Alec Radford, Dario Amodei, and Paul F Christiano. Learning to summarize with human feedback.NeurIPS, 33:3008–3021, 2020. 2
work page 2020
-
[45]
Yi Su, Dian Yu, Linfeng Song, Juntao Li, Haitao Mi, Zhaopeng Tu, Min Zhang, and Dong Yu. Crossing the reward bridge: Expanding rl with verifiable rewards across diverse domains.arXiv preprint arXiv:2503.23829, 2025. 3
-
[46]
Richard S Sutton, Andrew G Barto, et al.Reinforcement learning: An introduction. MIT press Cambridge, 1998. 2
work page 1998
-
[47]
Yuwen Tan, Yuan Qing, and Boqing Gong. Vision llms are bad at hierarchical visual understanding, and llms are the bottleneck.arXiv preprint arXiv:2505.24840, 2025. 2
-
[48]
Kimi K2: Open Agentic Intelligence
Kimi Team, Yifan Bai, Yiping Bao, Guanduo Chen, Jiahao Chen, Ningxin Chen, Ruijue Chen, Yanru Chen, Yuankun Chen, Yutian Chen, et al. Kimi k2: Open agentic intelligence. arXiv preprint arXiv:2507.20534, 2025. 3, 5
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [49]
-
[50]
The caltech-ucsd birds-200-2011 dataset,
Catherine Wah, Steve Branson, Peter Welinder, Pietro Perona, and Serge Belongie. The caltech-ucsd birds-200-2011 dataset,
work page 2011
-
[51]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024. 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[52]
Chain-of- thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of- thought prompting elicits reasoning in large language models. NeurIPS, 35:24824–24837, 2022. 2
work page 2022
-
[53]
An Yang, Beichen Zhang, Binyuan Hui, Bofei Gao, Bowen Yu, Chengpeng Li, Dayiheng Liu, Jianhong Tu, Jingren Zhou, Junyang Lin, et al. Qwen2. 5-math technical report: To- ward mathematical expert model via self-improvement.arXiv preprint arXiv:2409.12122, 2024. 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[54]
Huaiyuan Ying, Shuo Zhang, Linyang Li, Zhejian Zhou, Yun- fan Shao, Zhaoye Fei, Yichuan Ma, Jiawei Hong, Kuikun Liu, Ziyi Wang, et al. Internlm-math: Open math large lan- guage models toward verifiable reasoning.arXiv preprint arXiv:2402.06332, 2024. 3
-
[55]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xi- aochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476,
work page internal anchor Pith review Pith/arXiv arXiv
-
[56]
Object recognition as next token prediction
Kaiyu Yue, Bor-Chun Chen, Jonas Geiping, Hengduo Li, Tom Goldstein, and Ser-Nam Lim. Object recognition as next token prediction. InCVPR, 2024. 2
work page 2024
-
[57]
Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
Yang Yue, Zhiqi Chen, Rui Lu, Andrew Zhao, Zhaokai Wang, Yang Yue, Shiji Song, and Gao Huang. Does reinforcement learning really incentivize reasoning capacity in llms beyond the base model?arXiv preprint arXiv:2504.13837, 2025. 5
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[58]
Star: Self-taught reasoner bootstrapping reasoning with reasoning
Eric Zelikman, Yuhuai Wu, Jesse Mu, and Noah D Good- man. Star: Self-taught reasoner bootstrapping reasoning with reasoning. InNeurIPS, 2024. 7
work page 2024
-
[59]
Sigmoid loss for language image pre-training
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre-training. InICCV, 2023. 1, 2
work page 2023
-
[60]
Codedpo: Aligning code models with self generated and verified source code
Kechi Zhang, Ge Li, Yihong Dong, Jingjing Xu, Jun Zhang, Jing Su, Yongfei Liu, and Zhi Jin. Codedpo: Aligning code models with self generated and verified source code. InACL, pages 15854–15871, 2025. 3
work page 2025
-
[61]
Improve vision language model chain-of-thought reasoning
Ruohong Zhang, Bowen Zhang, Yanghao Li, Haotian Zhang, Zhiqing Sun, Zhe Gan, Yinfei Yang, Ruoming Pang, and Yim- ing Yang. Improve vision language model chain-of-thought reasoning. InACL, pages 1631–1662, 2025. 7
work page 2025
-
[62]
Why are visually-grounded language models bad at image classifi- cation?NeurIPS, 2024
Yuhui Zhang, Alyssa Unell, Xiaohan Wang, Dhruba Ghosh, Yuchang Su, Ludwig Schmidt, and Serena Yeung-Levy. Why are visually-grounded language models bad at image classifi- cation?NeurIPS, 2024. 1, 2
work page 2024
-
[63]
Automated generation of challenging multiple-choice questions for vision language model evaluation
Yuhui Zhang, Yuchang Su, Yiming Liu, Xiaohan Wang, James Burgess, Elaine Sui, Chenyu Wang, Josiah Aklilu, Alejandro Lozano, Anjiang Wei, et al. Automated generation of challenging multiple-choice questions for vision language model evaluation. InCVPR, pages 29580–29590, 2025. 2
work page 2025
-
[64]
Minigpt-4: Enhancing vision-language understanding with advanced large language models
Deyao Zhu, Jun Chen, Xiaoqian Shen, Xiang Li, and Mo- hamed Elhoseiny. Minigpt-4: Enhancing vision-language understanding with advanced large language models. InICLR,
-
[65]
TTRL: Test-Time Reinforcement Learning
Yuxin Zuo, Kaiyan Zhang, Li Sheng, Shang Qu, Ganqu Cui, Xuekai Zhu, Haozhan Li, Yuchen Zhang, Xinwei Long, Ermo Hua, et al. Ttrl: Test-time reinforcement learning.arXiv preprint arXiv:2504.16084, 2025. 2 Specificity-aware reinforcement learning for fine-grained open-world classification Supplementary Material In this supplementary material, we present add...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[66]
If prediction is an abstention/refusal/uncertainty (e.g., ”none”, ”cannot tell”, ”I don’t know”): outputAbstain
-
[67]
If prediction is malformed, nonsense, unrelated, contradictory, or gives multiple options (e.g., ”A or B”, lists): outputWrong
-
[68]
If prediction and ground truth denote the same entity via exact match or direct synonym: outputSpecific
-
[69]
• if the parent is broad/coarse (e.g., animal for dog): outputGeneric
Ifpredictionis aparent categoryofground truth: • if the parent is close (e.g., genus for species): outputLess Specific. • if the parent is broad/coarse (e.g., animal for dog): outputGeneric
-
[70]
Ifpredictionis achild/subtype/instanceofground truth: outputMore Specific
-
[71]
Otherwise: outputWrong. Input Format: {"ground_truth": "<the_ground_truth_label>", "prediction": "<the_vlm_prediction>"} Output Format: A single word from the allowed categories. Prompt: Apply the decision procedure to classify the following JSON object. Output exactly one category word. INPUT: %s Figure 16. Generated Prompt for the LLM-as-a-judge verifie...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.