WestWorld: A Knowledge-Encoded Scalable Trajectory World Model for Diverse Robotic Systems
Pith reviewed 2026-05-21 11:36 UTC · model grok-4.3
The pith
WestWorld uses a system-aware mixture of experts and structural embeddings to build one trajectory world model that generalizes across many different robots.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
WestWorld is a knowledge-encoded scalable trajectory world model for diverse robotic systems. It employs a novel system-aware Mixture-of-Experts (Sys-MoE) that dynamically routes and combines experts via a learnable system embedding, together with a structural embedding that aligns trajectory representations with robot physical morphologies. After pretraining on 89 complex environments across simulation and real-world settings, it delivers significant gains over baselines in zero- and few-shot trajectory prediction, exhibits strong scalability, improves downstream model-based control, and produces stable locomotion when deployed on a real Unitree Go1.
What carries the argument
System-aware Mixture-of-Experts (Sys-MoE) with learnable system embedding, augmented by structural embedding for morphological alignment.
Load-bearing premise
The learnable system embedding will let the mixture-of-experts reliably select and align experts for unseen robots without expert interference or per-system retraining.
What would settle it
Train on the 89 environments then measure zero-shot prediction error on a robot whose morphology is absent from training; high error or clear performance drop when more systems are added would falsify the central claim.
Figures





read the original abstract
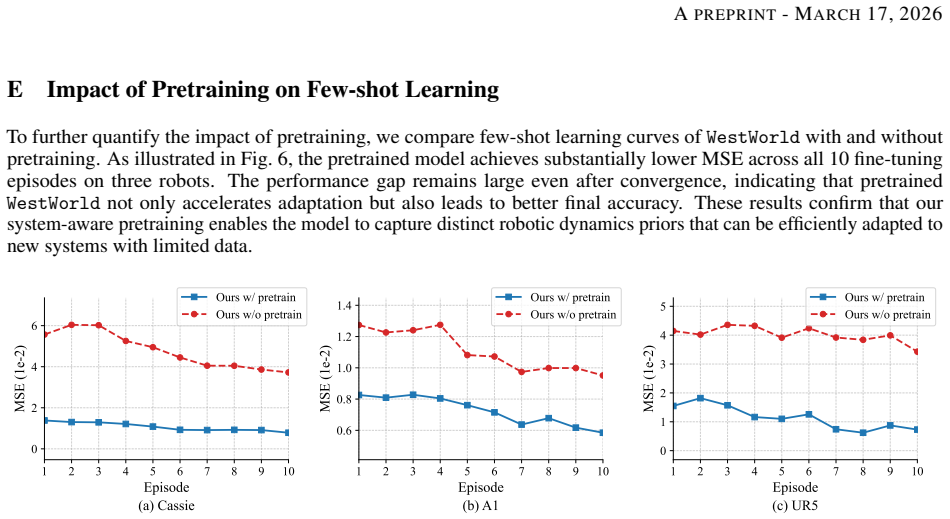
Trajectory world models play a crucial role in robotic dynamics learning, planning, and control. While recent works have explored trajectory world models for diverse robotic systems, they struggle to scale to a large number of distinct system dynamics and overlook domain knowledge of physical structures. To address these limitations, we introduce WestWorld, a knoWledge-Encoded Scalable Trajectory World model for diverse robotic systems. To tackle the scalability challenge, we propose a novel system-aware Mixture-of-Experts (Sys-MoE) that dynamically combines and routes specialized experts for different robotic systems via a learnable system embedding. To further enhance zero-shot generalization, we incorporate domain knowledge of robot physical structures by introducing a structural embedding that aligns trajectory representations with morphological information. After pretraining on 89 complex environments spanning diverse morphologies across both simulation and real-world settings, WestWorld achieves significant improvements over competitive baselines in zero- and few-shot trajectory prediction. Additionally, it shows strong scalability across a wide range of robotic environments and significantly improves performance on downstream model-based control for different robots. Finally, we deploy our model on a real-world Unitree Go1, where it demonstrates stable locomotion performance. The code is available at https://github.com/511205787/WestWorld.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces WestWorld, a knowledge-encoded scalable trajectory world model for diverse robotic systems. It proposes a system-aware Mixture-of-Experts (Sys-MoE) that uses a learnable system embedding to dynamically route and combine specialized experts, combined with a structural embedding that aligns representations with robot morphological information. The model is pretrained on 89 complex environments spanning simulation and real-world settings with diverse morphologies, and the authors claim significant gains over baselines in zero- and few-shot trajectory prediction, strong scalability, improved model-based control performance, and successful real-world deployment on a Unitree Go1 quadruped.
Significance. If the quantitative results and generalization claims hold under rigorous evaluation, this work would represent a meaningful step toward scalable world models that handle many distinct robotic dynamics without per-system retraining. The combination of learnable system embeddings with explicit structural knowledge injection is a concrete technical contribution, and the scale of pretraining (89 environments) plus public code release are positive aspects that could support reproducibility and follow-on research in robotics and model-based RL.
major comments (3)
- [§3.2] §3.2 (Sys-MoE architecture): The zero-shot generalization claim for unseen morphologies depends on the learnable system embedding reliably selecting and combining experts without interference. The manuscript provides no ablation on expert count, routing loss formulation, or explicit OOD morphology splits (e.g., training on 70 environments and testing on 19 held-out morphologies), so it is unclear whether the routing mechanism actually supports the no-retraining scalability assertion or collapses for novel systems.
- [Table 2, §4.3] Table 2 and §4.3 (zero-shot prediction results): The reported improvements over baselines lack error bars, statistical significance tests, and details on baseline implementations or hyperparameter matching. Without these, it is impossible to determine whether the gains are robust or sensitive to post-hoc choices, which directly affects the strength of the central empirical claim.
- [§5] §5 (real-world deployment): The Unitree Go1 locomotion results are presented without quantitative metrics (e.g., tracking error, success rate, or comparison to a non-pretrained baseline) or discussion of sim-to-real gaps in the structural embedding, weakening the claim that the pretrained model transfers stably to hardware.
minor comments (3)
- [Abstract] The abstract states performance gains but supplies no numerical values or baseline names; moving at least one key quantitative result (with error bars) into the abstract would improve readability.
- [§2.3] Notation for the structural embedding (e.g., how morphological features are encoded and fused with trajectory tokens) is introduced without a clear equation or diagram in §2.3, making the alignment mechanism harder to follow.
- [§4] The paper mentions 'competitive baselines' in §4 but does not list them explicitly in a table or appendix; adding this would aid comparison.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive review. We address each major comment below and have revised the manuscript accordingly to strengthen the presentation of our results and claims.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Sys-MoE architecture): The zero-shot generalization claim for unseen morphologies depends on the learnable system embedding reliably selecting and combining experts without interference. The manuscript provides no ablation on expert count, routing loss formulation, or explicit OOD morphology splits (e.g., training on 70 environments and testing on 19 held-out morphologies), so it is unclear whether the routing mechanism actually supports the no-retraining scalability assertion or collapses for novel systems.
Authors: We appreciate the referee's emphasis on rigorous validation of the Sys-MoE routing for zero-shot generalization. While the current experiments already evaluate on diverse held-out morphologies within the 89-environment pretraining corpus, we agree that explicit ablations and OOD splits would provide clearer evidence. In the revised manuscript we will add ablations varying the number of experts and the routing loss formulation. We will also report results on an explicit 70/19 train/test morphology split to directly demonstrate that the system embedding enables reliable expert selection without retraining on novel systems. revision: yes
-
Referee: [Table 2, §4.3] Table 2 and §4.3 (zero-shot prediction results): The reported improvements over baselines lack error bars, statistical significance tests, and details on baseline implementations or hyperparameter matching. Without these, it is impossible to determine whether the gains are robust or sensitive to post-hoc choices, which directly affects the strength of the central empirical claim.
Authors: We agree that the absence of error bars and statistical tests limits the interpretability of the reported gains. In the revision we will augment Table 2 with standard error bars across multiple random seeds, include paired statistical significance tests, and expand §4.3 with explicit descriptions of baseline implementations together with the hyperparameter search ranges used to ensure fair and reproducible comparisons. revision: yes
-
Referee: [§5] §5 (real-world deployment): The Unitree Go1 locomotion results are presented without quantitative metrics (e.g., tracking error, success rate, or comparison to a non-pretrained baseline) or discussion of sim-to-real gaps in the structural embedding, weakening the claim that the pretrained model transfers stably to hardware.
Authors: The referee correctly identifies that the current real-world section relies primarily on qualitative description. We will revise §5 to report quantitative metrics including tracking error and success rate for the Unitree Go1 experiments, add a comparison against a non-pretrained baseline, and include a dedicated paragraph discussing observed sim-to-real gaps in the structural embedding along with the mechanisms (e.g., morphology alignment) that support stable transfer. revision: yes
Circularity Check
No significant circularity in derivation or claims
full rationale
The paper introduces a new model architecture (Sys-MoE with learnable system embedding and structural embedding) that is pretrained on external data from 89 environments and then evaluated on held-out zero-shot and few-shot trajectory prediction tasks plus downstream control. No equations, derivations, or first-principles results are shown that reduce by construction to the inputs, fitted parameters renamed as predictions, or self-citation chains. The central claims rest on empirical performance against baselines rather than tautological re-derivation, so the work is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- learnable system embedding
invented entities (2)
-
Sys-MoE
no independent evidence
-
structural embedding
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we propose a novel system-aware Mixture-of-Experts (Sys-MoE) that dynamically combines and routes specialized experts for different robotic systems via a learnable system embedding... structural embedding that aligns trajectory representations with morphological information
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we first model each articulated object as a rooted kinematic tree and convert it to a binary tree using the left-child-right-sibling (LCRS) transformation... embed these indices to obtain a structure embedding
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
- [1]
-
[2]
Cosmos World Foundation Model Platform for Physical AI
N. Agarwal, A. Ali, M. Bala, Y . Balaji, E. Barker, T. Cai, P. Chattopadhyay, Y . Chen, Y . Cui, Y . Ding, et al. Cosmos world foundation model platform for physical ai.arXiv preprint arXiv:2501.03575, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
J. Alvarez-Padilla, J. Z. Zhang, S. Kwok, J. M. Dolan, and Z. Manchester. Real-time whole-body control of legged robots with model-predictive path integral control. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 14721–14727. IEEE, 2025
work page 2025
-
[4]
S. Belkhale, Y . Cui, and D. Sadigh. Hydra: Hybrid robot actions for imitation learning. InConference on Robot Learning, pages 2113–2133. PMLR, 2023
work page 2023
-
[5]
L. Chen, S. Bahl, and D. Pathak. Playfusion: Skill acquisition via diffusion from language-annotated play. In Conference on Robot Learning, pages 2012–2029. PMLR, 2023
work page 2012
-
[6]
Z. Chen, V . Badrinarayanan, C.-Y . Lee, and A. Rabinovich. Gradnorm: Gradient normalization for adaptive loss balancing in deep multitask networks. InInternational conference on machine learning, pages 794–803. PMLR, 2018. 10 APREPRINT- MARCH17, 2026
work page 2018
- [7]
-
[8]
K. Chua, R. Calandra, R. McAllister, and S. Levine. Deep reinforcement learning in a handful of trials using probabilistic dynamics models.Advances in neural information processing systems, 31, 2018
work page 2018
-
[9]
Visual Foresight: Model-Based Deep Reinforcement Learning for Vision-Based Robotic Control
F. Ebert, C. Finn, S. Dasari, A. Xie, A. Lee, and S. Levine. Visual foresight: Model-based deep reinforcement learning for vision-based robotic control.arXiv preprint arXiv:1812.00568, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[10]
J. Fu, A. Kumar, O. Nachum, G. Tucker, and S. Levine. D4rl: Datasets for deep data-driven reinforcement learning.arXiv preprint arXiv:2004.07219, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2004
-
[11]
Q. Gallouédec, E. Beeching, C. Romac, and E. Dellandréa. Jack of all trades, master of some, a multi-purpose transformer agent.arXiv preprint arXiv:2402.09844, 2024
- [12]
-
[13]
C. Gulcehre, Z. Wang, A. Novikov, T. Paine, S. Gómez, K. Zolna, R. Agarwal, J. S. Merel, D. J. Mankowitz, C. Paduraru, et al. Rl unplugged: A suite of benchmarks for offline reinforcement learning.Advances in neural information processing systems, 33:7248–7259, 2020
work page 2020
-
[14]
Y . Guo, L. X. Shi, J. Chen, and C. Finn. Ctrl-world: A controllable generative world model for robot manipulation. arXiv preprint arXiv:2510.10125, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [15]
- [16]
- [17]
- [18]
- [19]
-
[20]
M. Heo, Y . Lee, D. Lee, and J. J. Lim. Furniturebench: Reproducible real-world benchmark for long-horizon complex manipulation.The International Journal of Robotics Research, 44(10-11):1863–1891, 2025
work page 2025
-
[21]
Distilling the Knowledge in a Neural Network
G. Hinton, O. Vinyals, and J. Dean. Distilling the knowledge in a neural network.arXiv preprint arXiv:1503.02531, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[22]
S. Hong, D. Yoon, and K.-E. Kim. Structure-aware transformer policy for inhomogeneous multi-task reinforcement learning. InInternational Conference on Learning Representations, 2021
work page 2021
- [23]
-
[24]
M. A. Lee, Y . Zhu, K. Srinivasan, P. Shah, S. Savarese, L. Fei-Fei, A. Garg, and J. Bohg. Making sense of vision and touch: Self-supervised learning of multimodal representations for contact-rich tasks. In2019 International conference on robotics and automation (ICRA), pages 8943–8950. IEEE, 2019
work page 2019
-
[25]
H. Liu, S. Nasiriany, L. Zhang, Z. Bao, and Y . Zhu. Robot learning on the job: Human-in-the-loop autonomy and learning during deployment.The International Journal of Robotics Research, 44(10-11):1727–1742, 2025
work page 2025
- [26]
-
[27]
A. Parthasarathy, N. Kalra, R. Agrawal, Y . LeCun, O. Bounou, P. Izmailov, and M. Goldblum. Closing the train-test gap in world models for gradient-based planning.arXiv preprint arXiv:2512.09929, 2025
- [28]
-
[29]
M. H. Raibert, H. B. Brown Jr, M. Chepponis, J. Koechling, and J. K. Hodgins. Dynamically stable legged locomotion. Technical report, 1989
work page 1989
-
[30]
A. Sawhney, S. Lee, K. Zhang, M. Veloso, and O. Kroemer. Playing with food: Learning food item representations through interactive exploration. InInternational Symposium on Experimental Robotics, pages 309–322. Springer, 2020. 11 APREPRINT- MARCH17, 2026
work page 2020
- [31]
-
[32]
G. Schiavi, P. Wulkop, G. Rizzi, L. Ott, R. Siegwart, and J. J. Chung. Learning agent-aware affordances for closed- loop interaction with articulated objects. In2023 IEEE International Conference on Robotics and Automation (ICRA), pages 5916–5922. IEEE, 2023
work page 2023
-
[33]
A generalist dynamics model for control
I. Schubert, J. Zhang, J. Bruce, S. Bechtle, E. Parisotto, M. Riedmiller, J. T. Springenberg, A. Byravan, L. Hasen- clever, and N. Heess. A generalist dynamics model for control.arXiv preprint arXiv:2305.10912, 2023
-
[34]
W. J. Schwind.Spring loaded inverted pendulum running: A plant model. University of Michigan, 1998
work page 1998
- [35]
-
[36]
Y . Tang, W. Yu, J. Tan, H. Zen, A. Faust, and T. Harada. Saytap: Language to quadrupedal locomotion. In7th Annual Conference on Robot Learning
-
[37]
Gymnasium: A Standard Interface for Reinforcement Learning Environments
M. Towers, A. Kwiatkowski, J. Terry, J. U. Balis, G. De Cola, T. Deleu, M. Goulão, A. Kallinteris, M. Krimmel, A. KG, et al. Gymnasium: A standard interface for reinforcement learning environments.arXiv preprint arXiv:2407.17032, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [38]
-
[39]
Y . Wang, H. Zhao, H. Lin, E. Xu, L. He, and H. Shao. A generalizable physics-enhanced state space model for long-term dynamics forecasting in complex environments. InF orty-second International Conference on Machine Learning, 2025
work page 2025
- [40]
- [41]
-
[42]
Model Predictive Path Integral Control using Covariance Variable Importance Sampling
G. Williams, A. Aldrich, and E. Theodorou. Model predictive path integral control using covariance variable importance sampling.arXiv preprint arXiv:1509.01149, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[43]
P. Wu, A. Escontrela, D. Hafner, P. Abbeel, and K. Goldberg. Daydreamer: World models for physical robot learning. InConference on robot learning, pages 2226–2240. PMLR, 2023
work page 2023
-
[44]
F. Xie, S. Wei, Y . Song, Y . Yue, and L. Gan. Morphological-symmetry-equivariant heterogeneous graph neural network for robotic dynamics learning. In7th Annual Learning for Dynamics \& Control Conference, pages 1392–1405. PMLR, 2025
work page 2025
- [45]
-
[46]
S. Yin, J. Wu, S. Huang, X. Su, X. He, J. HAO, and M. Long. Trajectory world models for heterogeneous environments. InF orty-second International Conference on Machine Learning, 2025
work page 2025
-
[47]
Y . Zhou, S. Sonawani, M. Phielipp, H. Ben Amor, and S. Stepputtis. Learning modular language-conditioned robot policies through attention.Autonomous Robots, 47(8):1013–1033, 2023
work page 2023
-
[48]
F. Zhu, H. Wu, S. Guo, Y . Liu, C. Cheang, and T. Kong. Irasim: A fine-grained world model for robot manipulation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 9834–9844, 2025
work page 2025
-
[49]
X. Zhu, R. Tian, C. Xu, M. Huo, W. Zhan, M. Tomizuka, and M. Ding. Fanuc manipulation: A dataset for learning-based manipulation with fanuc mate 200id robot, 2023. 12 APREPRINT- MARCH17, 2026 A Notations The table below summarizes the notation used in this paper. Lowercase letters (e.g., x) denote scalars, bold lowercase letters (e.g.,x) represent vectors...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.