Recognition: 2 theorem links
· Lean TheoremIntelligence Inertia: Physical Isomorphism and Applications
Pith reviewed 2026-05-15 07:30 UTC · model grok-4.3
The pith
A heuristic spacetime isomorphism for deep learning yields a Lorentz-like cost formula predicting a J-shaped computational wall.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Rather than claiming a new physical law, the paper establishes a heuristic mathematical isomorphism between deep learning dynamics and Minkowski spacetime. From the non-commutativity [Ŝ, R̂] = i𝒟 between states and rules, it derives a non-linear cost formula that mirrors the Lorentz factor. This predicts a relativistic J-shaped inflation curve marking the computational wall where classical approximations fail for high-dimensional tensor evolution.
What carries the argument
Intelligence Inertia, the effective resistance property generated by the commutator [Ŝ, R̂] = i𝒟 under a heuristic isomorphism to Minkowski spacetime that produces the relativistic cost formula.
Load-bearing premise
The heuristic mathematical isomorphism between deep learning dynamics and Minkowski spacetime is sufficiently accurate to yield quantitative predictions for high-dimensional tensor evolution.
What would settle it
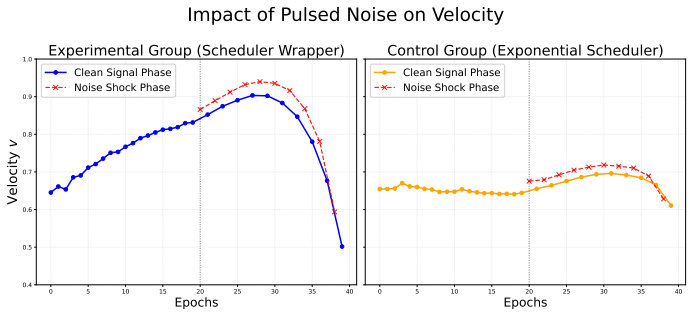
Measure computational overhead while forcing deep structural reconfigurations in neural networks under controlled noise and check whether costs follow the predicted non-linear J-shaped curve or remain closer to linear approximations.
Figures








read the original abstract
Classical frameworks like Fisher Information approximate the cost of neural adaptation only in low-density regimes, failing to explain the explosive computational overhead incurred during deep structural reconfiguration. To address this, we introduce \textbf{Intelligence Inertia}, a property derived from the fundamental non-commutativity between rules and states ($[\hat{S}, \hat{R}] = i\mathcal{D}$). Rather than claiming a new fundamental physical law, we establish a \textbf{heuristic mathematical isomorphism} between deep learning dynamics and Minkowski spacetime. Acting as an \textit{effective theory} for high-dimensional tensor evolution, we derive a non-linear cost formula mirroring the Lorentz factor, predicting a relativistic $J$-shaped inflation curve -- a computational wall where classical approximations fail. We validate this framework via three experiments: (1) adjudicating the $J$-curve divergence under high-entropy noise, (2) mapping the optimal geodesic for architecture evolution, and (3) deploying an \textbf{inertia-aware scheduler wrapper} that prevents catastrophic forgetting. Adopting this isomorphism yields an exact quantitative metric for structural resistance, advancing the stability and efficiency of intelligent agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces 'Intelligence Inertia' as a property arising from the postulated non-commutativity [Ŝ, R̂] = iD between rules and states in deep learning dynamics. It posits a heuristic mathematical isomorphism between these dynamics and Minkowski spacetime as an effective theory for high-dimensional tensor evolution, from which a non-linear cost formula analogous to the Lorentz factor is derived. This yields a predicted relativistic J-shaped inflation curve representing a computational wall where classical approximations fail. The framework is validated through three experiments: testing J-curve divergence under high-entropy noise, mapping optimal geodesics for architecture evolution, and implementing an inertia-aware scheduler wrapper to mitigate catastrophic forgetting.
Significance. If the central derivation and quantitative predictions hold under rigorous scrutiny, the work could offer a novel effective-theory perspective on scaling limits and structural resistance in neural networks, potentially informing more stable training regimes and architecture search. The explicit framing as a heuristic isomorphism (rather than a fundamental law) and the provision of an inertia-aware scheduler are constructive elements that could be built upon if the mapping is made precise.
major comments (3)
- [Abstract, §3] Abstract and §3 (derivation section): No intermediate algebraic steps are shown mapping the commutator postulate [Ŝ, R̂] = iD to the specific Lorentz-like form (e.g., a factor 1/√(1−v²/c²) or equivalent inertia term) rather than an arbitrary non-linear function. Without this explicit mapping, the claimed quantitative J-curve prediction rests on an unverified analogy whose accuracy for tensor evolution remains unestablished.
- [§4] §4 (experiments): The three validation experiments are described only at a high level; no quantitative outcomes, error analysis, baseline comparisons, or statistical significance tests are reported. This leaves the central claim that the framework 'prevents catastrophic forgetting' or 'adjudicates J-curve divergence' unsupported by visible evidence.
- [§2] §2 (isomorphism construction): The non-linear cost formula is obtained directly from the chosen commutator and the imposed Minkowski isomorphism; the resulting J-curve therefore reduces by construction to a quantity defined within the introduced framework rather than constituting an independent, falsifiable benchmark against classical Fisher-information approximations.
minor comments (2)
- [Introduction] The notation Ŝ and R̂ for state and rule operators is introduced without an explicit definition or Hilbert-space context in the opening sections, which hinders readability for readers outside the immediate subfield.
- [Introduction] The term 'Intelligence Inertia' is presented as novel without a brief literature contrast to related concepts such as information geometry or effective-field theories in machine learning.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive comments. We address each major point below and indicate the revisions planned for the next version of the manuscript.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (derivation section): No intermediate algebraic steps are shown mapping the commutator postulate [Ŝ, R̂] = iD to the specific Lorentz-like form (e.g., a factor 1/√(1−v²/c²) or equivalent inertia term) rather than an arbitrary non-linear function. Without this explicit mapping, the claimed quantitative J-curve prediction rests on an unverified analogy whose accuracy for tensor evolution remains unestablished.
Authors: We agree that the derivation would be strengthened by explicit intermediate steps. In the revised manuscript we will expand §3 to show the algebraic mapping from the commutator [Ŝ, R̂] = iD through the imposed Minkowski isomorphism to the Lorentz-like inertia term. This will make clear that the J-curve follows from the effective-theory construction rather than being chosen arbitrarily. We will also add a short paragraph reiterating the heuristic status of the isomorphism and its intended domain of applicability to high-dimensional tensor evolution. revision: yes
-
Referee: [§4] §4 (experiments): The three validation experiments are described only at a high level; no quantitative outcomes, error analysis, baseline comparisons, or statistical significance tests are reported. This leaves the central claim that the framework 'prevents catastrophic forgetting' or 'adjudicates J-curve divergence' unsupported by visible evidence.
Authors: The referee correctly identifies that §4 currently provides only high-level descriptions. We will revise this section to report the quantitative results of all three experiments, including performance metrics with error bars, direct comparisons against standard schedulers and Fisher-information baselines, and the results of appropriate statistical tests. These additions will supply the concrete evidence needed to support the claims regarding J-curve divergence and mitigation of catastrophic forgetting. revision: yes
-
Referee: [§2] §2 (isomorphism construction): The non-linear cost formula is obtained directly from the chosen commutator and the imposed Minkowski isomorphism; the resulting J-curve therefore reduces by construction to a quantity defined within the introduced framework rather than constituting an independent, falsifiable benchmark against classical Fisher-information approximations.
Authors: We accept that the J-curve is obtained inside the framework by construction. The manuscript already frames the work as a heuristic effective theory rather than a fundamental law; the intended falsifiability therefore resides in the empirical predictions (divergence from classical approximations under high-entropy noise, geodesic optimality, and forgetting mitigation). In the revision we will strengthen the discussion in §2 to articulate these testable predictions more explicitly and will ensure the expanded experimental results in §4 include direct quantitative comparisons with Fisher-information baselines. revision: partial
Circularity Check
Non-linear cost formula obtained by construction via chosen heuristic isomorphism to Lorentz factor
specific steps
-
self definitional
[Abstract]
"we establish a heuristic mathematical isomorphism between deep learning dynamics and Minkowski spacetime. Acting as an effective theory for high-dimensional tensor evolution, we derive a non-linear cost formula mirroring the Lorentz factor, predicting a relativistic J-shaped inflation curve"
The cost formula is introduced as derived from the commutator via the isomorphism, yet the isomorphism is selected precisely so that the cost mirrors the Lorentz factor. The J-curve therefore follows tautologically from the framework definition rather than from an independent derivation or external benchmark.
full rationale
The paper postulates the commutator [Ŝ,R̂]=iD and then adopts a heuristic isomorphism to Minkowski spacetime as an effective theory. From this it directly states a derived non-linear cost mirroring the Lorentz factor, producing the J-curve. No intermediate mapping is exhibited showing why the commutator yields precisely the relativistic form rather than another non-linear function; the quantitative prediction therefore reduces to the inputs of the chosen analogy by construction. This matches the self-definitional pattern with load-bearing impact on the central claim.
Axiom & Free-Parameter Ledger
free parameters (1)
- D
axioms (1)
- ad hoc to paper Non-commutativity between rules and states: [S, R] = iD
invented entities (1)
-
Intelligence Inertia
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
W(ρ) = W_rest · l / l_S = W_rest / √(1-ρ²) ... Intelligence Lorentz Factor (γ)
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
[Ŝ, R̂] = iD ... l² = l_S² + l_R² ... ρ = sin θ
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Universal intelligence: A definition of machine intelligence,
S. Legg and M. Hutter, “Universal intelligence: A definition of machine intelligence,”Minds and Machines, vol. 17, no. 4, pp. 391–444, 2007
work page 2007
-
[2]
S. Russell, P. Norvig, and A. Intelligence, “A modern approach,”Artificial Intelligence. Prentice-Hall, Egnlewood Cliffs, vol. 25, no. 27, pp. 79–80, 1995
work page 1995
-
[3]
On the Measure of Intelligence
F. Chollet, “On the measure of intelligence,”arXiv preprint arXiv:1911.01547, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1911
-
[4]
Hern´ andez-Orallo,The Measure of All Minds: Evaluating Natural and Artificial Intelligence
J. Hern´ andez-Orallo,The Measure of All Minds: Evaluating Natural and Artificial Intelligence. Cambridge University Press, 2017
work page 2017
-
[5]
When and how to develop domain-specific languages,
M. Mernik, J. Heering, and A. M. Sloane, “When and how to develop domain-specific languages,”ACM computing surveys (CSUR), vol. 37, no. 4, pp. 316–344, 2005
work page 2005
-
[6]
Houdini: Lifelong learning as program synthesis,
L. Valkov, S. Chaudhuri, B. Lake, A. Gaunt, and C. Milton, “Houdini: Lifelong learning as program synthesis,” inAdvances in Neural Information Processing Systems, vol. 31, 2018
work page 2018
-
[7]
Irreversibility and heat generation in the computing pro- cess,
R. Landauer, “Irreversibility and heat generation in the computing pro- cess,”IBM journal of research and development, vol. 5, no. 3, pp. 183–191, 1961
work page 1961
-
[8]
Experimental verification of landauer’s principle linking in- formation and thermodynamics,
A. B´ erut, A. Arakelyan, A. Petrosyan, S. Ciliberto, R. Dillenschneider, and E. Lutz, “Experimental verification of landauer’s principle linking in- formation and thermodynamics,”Nature, vol. 483, no. 7388, pp. 187–189, 2012
work page 2012
-
[10]
Amari,Information Geometry and Its Applications
S.-i. Amari,Information Geometry and Its Applications. Springer, 2016
work page 2016
-
[11]
New insights and perspectives on the natural gradient method,
J. Martens, “New insights and perspectives on the natural gradient method,”Journal of Machine Learning Research, vol. 21, no. 146, pp. 1–76, 2020
work page 2020
-
[12]
Overcoming catastrophic forgetting in neural networks,
J. Kirkpatrick, R. Pascanu, N. Rabinowitz, J. Veness, G. Desjardins, A. A. Rusu, K. Milan, J. Quan, T. Ramalho, A. Grabska-Barwinska,et al., “Overcoming catastrophic forgetting in neural networks,”Proceedings of the national academy of sciences, vol. 114, no. 13, pp. 3521–3526, 2017
work page 2017
-
[13]
Three approaches to the quantitative definition of information,
A. N. Kolmogorov, “Three approaches to the quantitative definition of information,”Problems of information transmission, vol. 1, no. 1, pp. 1–7, 1965. 52
work page 1965
-
[14]
Algorithmic Information Theory: a brief non-technical guide to the field
M. Hutter, “Algorithmic information theory: a brief non-technical guide to the field,”arXiv preprint cs/0703024, 2007
work page internal anchor Pith review Pith/arXiv arXiv 2007
-
[15]
Taskonomy: Disentangling task transfer learning,
A. R. Zamir, A. Sax, W. Shen, L. J. Guibas, J. Malik, and S. Savarese, “Taskonomy: Disentangling task transfer learning,” inProceedings of the IEEE conference on computer vision and pattern recognition, pp. 3712– 3722, 2018
work page 2018
-
[16]
How transferable are features in deep neural networks?,
J. Yosinski, J. Clune, Y. Bengio, and H. Lipson, “How transferable are features in deep neural networks?,” inAdvances in neural information pro- cessing systems, 2014
work page 2014
-
[17]
High-precision test of landauer’s principle in a feedback trap,
J. Bechhoefer, “High-precision test of landauer’s principle in a feedback trap,” inAPS March Meeting Abstracts, vol. 2015, pp. Z3–002, 2015
work page 2015
-
[18]
The thermodynamics of computation—a review,
C. H. Bennett, “The thermodynamics of computation—a review,”Inter- national Journal of Theoretical Physics, vol. 21, no. 12, pp. 905–940, 1982
work page 1982
-
[19]
Thermodynamics of information,
J. M. Parrondo, J. M. Horowitz, and T. Sagawa, “Thermodynamics of information,”Nature Physics, vol. 11, no. 2, pp. 131–139, 2015
work page 2015
-
[20]
Revisiting Natural Gradient for Deep Networks
R. Pascanu and Y. Bengio, “Revisiting natural gradient for deep networks,” arXiv preprint arXiv:1301.3584, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[21]
Logical depth and physical complexity,
C. H. Bennett, “Logical depth and physical complexity,” inThe Universal Turing Machine: A Half-Century Survey(R. Herken, ed.), pp. 227–257, Oxford University Press, 1988
work page 1988
-
[22]
M. Li, P. Vit´ anyi,et al.,An introduction to Kolmogorov complexity and its applications, vol. 3. Springer, 2008
work page 2008
-
[23]
Algorithmic data analytics, small data matters and correlation versus causation,
H. Zenil, “Algorithmic data analytics, small data matters and correlation versus causation,” inBerechenbarkeit der Welt? Philosophie und Wis- senschaft im Zeitalter von Big Data, pp. 453–475, Springer, 2017
work page 2017
-
[24]
Catastrophic forgetting in connectionist networks,
R. M. French, “Catastrophic forgetting in connectionist networks,”Trends in Cognitive Sciences, vol. 3, no. 4, pp. 128–135, 1999
work page 1999
-
[25]
Continual learning through synaptic in- telligence,
F. Zenke, B. Poole, and G. Surya, “Continual learning through synaptic in- telligence,”International Conference on Machine Learning (ICML), 2017
work page 2017
-
[26]
Embracing change: Continual learning in deep neural networks,
R. Hadsell, D. Rao, A. A. Rusu, and R. Pascanu, “Embracing change: Continual learning in deep neural networks,”Trends in Cognitive Sciences, vol. 24, no. 12, pp. 1028–1040, 2020
work page 2020
-
[27]
Three scenarios for continual learning,
G. M. van de Ven, J. T. Vogelstein, and A. S. Tolias, “Three scenarios for continual learning,”Nature Machine Intelligence, vol. 4, no. 11, pp. 955– 967, 2022. 53
work page 2022
-
[28]
The information com- plexity of learning tasks, their structure and their distance,
A. Achille, G. Paolini, G. Mbeng, and S. Soatto, “The information com- plexity of learning tasks, their structure and their distance,”Information and Inference: A Journal of the IMA, vol. 10, no. 1, pp. 51–72, 2021
work page 2021
-
[29]
On the electrodynamics of moving bodies,
A. Einstein, “On the electrodynamics of moving bodies,”Annalen der Physik, vol. 17, pp. 891–921, 1905
work page 1905
-
[30]
A mathematical theory of communication,
C. E. Shannon, “A mathematical theory of communication,”The Bell Sys- tem Technical Journal, vol. 27, no. 3, pp. 379–423, 1948
work page 1948
-
[31]
Electromagnetic phenomena in a system moving with any velocity smaller than that of light,
H. A. Lorentz, “Electromagnetic phenomena in a system moving with any velocity smaller than that of light,” inCollected Papers: Volume V, pp. 172–197, Springer, 1937
work page 1937
-
[32]
Information theory and statistical mechanics,
E. T. Jaynes, “Information theory and statistical mechanics,”Physical Re- view, vol. 106, no. 4, pp. 620–630, 1957
work page 1957
-
[33]
Ultimate physical limits to computation,
S. Lloyd, “Ultimate physical limits to computation,”Nature, vol. 406, no. 6799, pp. 1047–1054, 2000
work page 2000
-
[34]
Energy cost of information transfer,
J. D. Bekenstein, “Energy cost of information transfer,”Physical Review Letters, vol. 46, no. 10, pp. 623–626, 1981
work page 1981
-
[35]
The fundamental equations of quantum mechanics,
P. A. Dirac, “The fundamental equations of quantum mechanics,”Proceed- ings of the Royal Society of London. Series A, vol. 109, no. 752, pp. 642–653, 1925
work page 1925
-
[36]
Information, physics, quantum: The search for links,
J. A. Wheeler, “Information, physics, quantum: The search for links,” Feynman and computation, pp. 309–336, 2018
work page 2018
-
[37]
Statistical distance and hilbert space,
W. K. Wootters, “Statistical distance and hilbert space,”Physical Review D, vol. 23, no. 2, pp. 357–362, 1981
work page 1981
-
[38]
Gell-Mann,The Quark and the Jaguar: Adventures in the Simple and the Complex
M. Gell-Mann,The Quark and the Jaguar: Adventures in the Simple and the Complex. Macmillan, 1995
work page 1995
- [39]
-
[40]
Survey of hallucination in natural language generation,
Z. Ji, N. Lee, R. Frieske, T. Yu, D. Su, Y. Xu, E. Ishii, Y. J. Bang, A. Madotto, and P. Fung, “Survey of hallucination in natural language generation,”ACM Computing Surveys, vol. 55, no. 12, pp. 1–38, 2023
work page 2023
-
[41]
C. Adami, “What is information?,”Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences, vol. 374, no. 2063, p. 20150230, 2016
work page 2063
-
[42]
Gradient episodic memory for continual learning,
D. Lopez-Paz and M. Ranzato, “Gradient episodic memory for continual learning,” inAdvances in Neural Information Processing Systems, vol. 30, 2017
work page 2017
-
[43]
K. Huang,Statistical mechanics. John Wiley & Sons, 2008. 54
work page 2008
-
[44]
Optimization methods for large- scale machine learning,
L. Bottou, F. E. Curtis, and J. Nocedal, “Optimization methods for large- scale machine learning,”SIAM review, vol. 60, no. 2, pp. 223–311, 2018
work page 2018
-
[45]
Adam: A Method for Stochastic Optimization
D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[46]
Opening the Black Box of Deep Neural Networks via Information
R. Shwartz-Ziv and N. Tishby, “Opening the black box of deep neural networks via information,”arXiv preprint arXiv:1703.00810, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[47]
SGDR: Stochastic Gradient Descent with Warm Restarts
I. Loshchilov and M. Hutter, “Sgdr: Stochastic gradient descent with warm restarts,”arXiv preprint arXiv:1608.03983, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[48]
Identifying and attacking the saddle point problem in high- dimensional non-convex optimization,
Y. N. Dauphin, R. Pascanu, C. Gulcehre, K. Cho, S. Ganguli, and Y. Bengio, “Identifying and attacking the saddle point problem in high- dimensional non-convex optimization,” inAdvances in Neural Information Processing Systems, vol. 27, 2014
work page 2014
-
[49]
Machine learning and variational algorithms for lattice field theory,
G. Kanwar, “Machine learning and variational algorithms for lattice field theory,”arXiv preprint arXiv:2106.01975, 2021
-
[50]
Contin- ual lifelong learning with neural networks: A review,
G. I. Parisi, R. Kemker, J. L. Part, C. Kanan, and S. Wermter, “Contin- ual lifelong learning with neural networks: A review,”Neural Networks, vol. 113, pp. 54–71, 2019
work page 2019
-
[51]
Y. LeCun, Y. Bengio, and G. Hinton, “Deep learning,”nature, vol. 521, no. 7553, pp. 436–444, 2015
work page 2015
-
[52]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProceedings of the IEEE conference on computer vision and pattern recognition, pp. 770–778, 2016
work page 2016
-
[53]
Learning multiple layers of features from tiny images,
A. Krizhevsky, G. Hinton,et al., “Learning multiple layers of features from tiny images,” 2009
work page 2009
-
[54]
On Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima
N. S. Keskar, D. Mudigere, N. Jorge, S. Mikhail, and T. Ping Tak Peter, “On large-batch training for deep learning: Generalization gap and sharp minima,”arXiv preprint arXiv:1609.04836, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[55]
The importance of complexity in model selection,
I. J. Myung, “The importance of complexity in model selection,”Journal of Mathematical Psychology, vol. 44, no. 1, pp. 190–204, 2000
work page 2000
-
[56]
Weinberg,Gravitation and Cosmology: Principles and Applications of the General Theory of Relativity
S. Weinberg,Gravitation and Cosmology: Principles and Applications of the General Theory of Relativity. New York: John Wiley & Sons, 1972
work page 1972
-
[57]
Falconer,Fractal geometry: mathematical foundations and applications
K. Falconer,Fractal geometry: mathematical foundations and applications. John Wiley & Sons, 2013
work page 2013
-
[58]
Scaling Laws for Neural Language Models
J. Kaplan, S. McCandlish, T. Henighan, T. B. Brown, B. Chess, R. Child, S. Gray, A. Radford, J. Wu, and D. Amodei, “Scaling laws for neural language models,”arXiv preprint arXiv:2001.08361, 2020. 55
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[59]
Batch normalization: Accelerating deep network training by reducing internal covariate shift,
S. Ioffe and C. Szegedy, “Batch normalization: Accelerating deep network training by reducing internal covariate shift,” inInternational Conference on Machine Learning (ICML), pp. 448–456, 2015
work page 2015
-
[60]
The need for biases in learning generalizations,
T. M. Mitchell, “The need for biases in learning generalizations,” inRead- ings in Machine Learning, pp. 184–191, Morgan Kaufmann, 1980
work page 1980
-
[61]
Gradient-based learning applied to document recognition,
Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner, “Gradient-based learning applied to document recognition,”Proceedings of the IEEE, vol. 86, no. 11, pp. 2278–2324, 2002
work page 2002
-
[62]
Going deeper with convolutions,
C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Er- han, V. Vanhoucke, and A. Rabinovich, “Going deeper with convolutions,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 1–9, 2015
work page 2015
-
[63]
The perceptron: a probabilistic model for information stor- age and organization in the brain.,
F. Rosenblatt, “The perceptron: a probabilistic model for information stor- age and organization in the brain.,”Psychological review, vol. 65, no. 6, p. 386, 1958
work page 1958
-
[64]
Visualizing the loss landscape of neural nets,
H. Li, Z. Xu, G. Taylor, C. Studer, and T. Goldstein, “Visualizing the loss landscape of neural nets,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 31, 2018
work page 2018
-
[65]
Exact solutions to the nonlinear dynamics of learning in deep linear neural networks
A. M. Saxe, J. L. McClelland, and S. Ganguli, “Exact solutions to the non- linear dynamics of learning in deep linear neural networks,”arXiv preprint arXiv:1312.6120, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[66]
Stochastic modified equations and adaptive stochastic gradient algorithms,
Q. Li, C. Tai,et al., “Stochastic modified equations and adaptive stochastic gradient algorithms,” inInternational Conference on Machine Learning, pp. 2101–2110, PMLR, 2017
work page 2017
-
[67]
L. N. Smith, “A disciplined approach to neural network hyper-parameters: Part 1–learning rate, batch size, momentum, and weight decay,”arXiv preprint arXiv:1803.09820, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[68]
Pytorch: An impera- tive style, high-performance deep learning library,
A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antiga,et al., “Pytorch: An impera- tive style, high-performance deep learning library,” inAdvances in Neural Information Processing Systems, vol. 32, 2019
work page 2019
-
[69]
Super-convergence: Very fast training of neural networks using large learning rates,
L. N. Smith and N. Topin, “Super-convergence: Very fast training of neural networks using large learning rates,” inArtificial intelligence and machine learning for multi-domain operations applications, vol. 11006, pp. 369–386, SPIE, 2019
work page 2019
-
[70]
Cyclical learning rates for training neural networks,
L. N. Smith, “Cyclical learning rates for training neural networks,” in2017 IEEE Winter Conference on Applications of Computer Vision (WACV), pp. 464–472, IEEE, 2017. 56
work page 2017
-
[71]
On the importance of initialization and momentum in deep learning,
I. Sutskever, J. Martens, G. Dahl, and G. Hinton, “On the importance of initialization and momentum in deep learning,” inInternational Conference on Machine Learning (ICML), pp. 1139–1147, 2013
work page 2013
-
[72]
A survey of label-noise representation learning: Past, present and future,
B. Han, Q. Yao, T. Liu, G. Niu, I. W. Tsang, J. T. Kwok, and M. Sugiyama, “A survey of label-noise representation learning: Past, present and future,” arXiv preprint arXiv:2011.04406, 2020
-
[73]
An Empirical Model of Large-Batch Training
S. McCandlish, J. Kaplan, A. Vitvitkiy,et al., “An empirical model of large-batch training,”arXiv preprint arXiv:1812.06162, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[74]
Neural architecture search with reinforcement learn- ing,
B. Zoph and Q. V. Le, “Neural architecture search with reinforcement learn- ing,” inInternational Conference on Learning Representations (ICLR), 2017
work page 2017
-
[75]
Lora: Low-rank adaptation of large language models,
E. J. Hu, Y. Shen, P. Wallis, Z. Allen-Zhu, Y. Li, S. Wang, L. Wang, and W. Chen, “Lora: Low-rank adaptation of large language models,” in International Conference on Learning Representations, 2022
work page 2022
-
[76]
G. E. Volovik,The Universe in a Helium Droplet. Oxford University Press, 2003
work page 2003
-
[77]
Goertzel,Artificial general intelligence: concept, state of the art, and future prospects, vol
B. Goertzel,Artificial general intelligence: concept, state of the art, and future prospects, vol. 5. Artificial General Intelligence Society, 2014. 57
work page 2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.