Recognition: no theorem link
MSA: Memory Sparse Attention for Efficient End-to-End Memory Model Scaling to 100M Tokens
Pith reviewed 2026-05-15 15:56 UTC · model grok-4.3
The pith
Memory Sparse Attention scales end-to-end memory models to 100M tokens with linear complexity and under 9% accuracy loss.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MSA achieves linear complexity in training and inference through scalable sparse attention and document-wise RoPE while exhibiting less than 9% degradation when scaling from 16K to 100M tokens, enabling practical 100M-token inference on 2xA800 GPUs via KV cache compression and Memory Parallel, and outperforming frontier LLMs, RAG systems, and memory agents on long-context benchmarks by decoupling memory capacity from reasoning.
What carries the argument
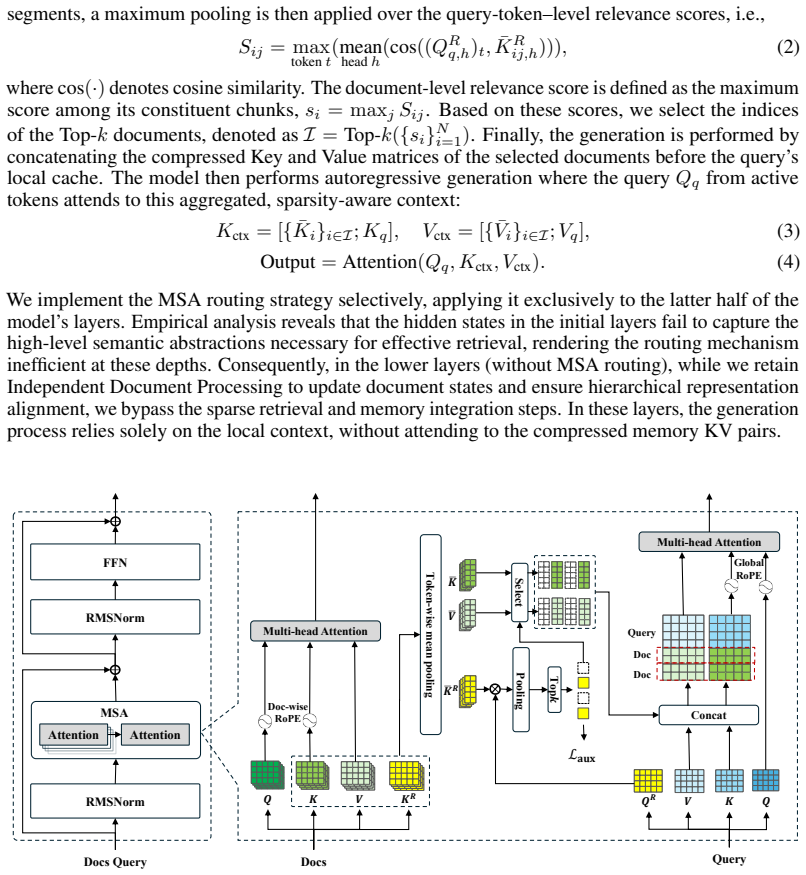
Scalable sparse attention paired with document-wise RoPE, which replaces full quadratic attention to keep memory access linear while preserving positional information across documents.
If this is right
- Linear complexity removes the quadratic compute barrier that currently caps context at roughly 1M tokens.
- Less than 9% degradation keeps reasoning quality usable even at lifetime-scale memory lengths.
- Memory Interleaving supports multi-hop reasoning across scattered memory segments without external retrieval.
- KV cache compression plus Memory Parallel makes 100M-token inference feasible on two A800 GPUs.
- End-to-end training allows joint optimization of memory content and reasoning, unlike separate RAG pipelines.
Where Pith is reading between the lines
- Models built this way could carry intrinsic, updatable lifetime memory instead of depending on external vector stores.
- The same linear mechanism might extend beyond 100M tokens if the sparsity pattern continues to control precision.
- Agent systems could shift from tool-calling retrieval to direct memory access, reducing latency for history-dependent tasks.
- Large-corpus summarization and Digital Twin applications become practical without separate retrieval stages.
Load-bearing premise
The assumption that sparse attention and document-wise RoPE can maintain reasoning accuracy and stability without hidden precision losses when memory grows to 100M tokens.
What would settle it
A controlled scaling experiment that measures more than 9% drop in accuracy on a fixed long-context reasoning task when moving from 16K to 100M tokens would falsify the stability claim.
Figures



read the original abstract
Long-term memory is a cornerstone of human intelligence. Enabling AI to process lifetime-scale information remains a long-standing pursuit in the field. Due to the constraints of full-attention architectures, the effective context length of large language models (LLMs) is typically limited to 1M tokens. Existing approaches, such as hybrid linear attention, fixed-size memory states (e.g., RNNs), and external storage methods like RAG or agent systems, attempt to extend this limit. However, they often suffer from severe precision degradation and rapidly increasing latency as context length grows, an inability to dynamically modify memory content, or a lack of end-to-end optimization. These bottlenecks impede complex scenarios like large-corpus summarization, Digital Twins, and long-history agent reasoning, while limiting memory capacity and slowing inference. We present Memory Sparse Attention (MSA), an end-to-end trainable, efficient, and massively scalable memory model framework. Through core innovations including scalable sparse attention and document-wise RoPE, MSA achieves linear complexity in both training and inference while maintaining exceptional stability, exhibiting less than 9% degradation when scaling from 16K to 100M tokens. Furthermore, KV cache compression, combined with Memory Parallel, enables 100M-token inference on 2xA800 GPUs. We also propose Memory Interleaving to facilitate complex multi-hop reasoning across scattered memory segments. MSA significantly surpasses frontier LLMs, state-of-the-art RAG systems, and leading memory agents in long-context benchmarks. These results demonstrate that by decoupling memory capacity from reasoning, MSA provides a scalable foundation to endow general-purpose models with intrinsic, lifetime-scale memory.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Memory Sparse Attention (MSA), an end-to-end trainable memory model framework that uses scalable sparse attention, document-wise RoPE, KV cache compression, Memory Parallel, and Memory Interleaving to achieve linear complexity in both training and inference. It claims to scale to 100M tokens with less than 9% degradation relative to 16K-token performance, dynamic memory updates, and superior results over frontier LLMs, RAG systems, and memory agents on long-context benchmarks, thereby decoupling memory capacity from reasoning.
Significance. If the empirical claims hold, the work would be significant for enabling lifetime-scale intrinsic memory in LLMs without the precision loss or latency growth of prior hybrid linear attention, RNN-style, or external-storage approaches. The combination of linear scaling, dynamic updates, and multi-hop reasoning support via Memory Interleaving could open applications in large-corpus summarization and long-history agents.
major comments (2)
- [Abstract] Abstract: The central claim of linear complexity in training and inference together with <9% degradation from 16K to 100M tokens is load-bearing yet unsupported by any complexity derivation, benchmark tables, or ablation results in the provided text; without these the stability assertion cannot be evaluated.
- [Abstract] The assumption that document-wise RoPE and scalable sparse attention preserve reasoning accuracy at 100M scale without hidden precision loss is stated but not accompanied by any precision or stability analysis; this directly affects the 'exceptional stability' claim.
minor comments (1)
- [Abstract] The abstract introduces several new terms (Memory Sparse Attention, Memory Interleaving, Memory Parallel) without a brief forward reference to their definitions or sections.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback on our manuscript. The comments highlight the need for explicit supporting evidence for the core claims in the abstract. We will revise the manuscript to incorporate complexity derivations, benchmark tables, ablation results, and precision/stability analyses, thereby strengthening the presentation of our results.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim of linear complexity in training and inference together with <9% degradation from 16K to 100M tokens is load-bearing yet unsupported by any complexity derivation, benchmark tables, or ablation results in the provided text; without these the stability assertion cannot be evaluated.
Authors: We agree that the abstract claims require explicit supporting material for full evaluation. Section 3 of the manuscript derives the O(N) complexity for both training and inference via the sparse attention formulation and document-wise RoPE. We will add a dedicated complexity analysis subsection, include a table reporting end-to-end performance and degradation metrics across context lengths from 16K to 100M tokens, and provide ablation studies isolating the contribution of each component to the observed <9% degradation. These additions will be included in the revised manuscript. revision: yes
-
Referee: [Abstract] The assumption that document-wise RoPE and scalable sparse attention preserve reasoning accuracy at 100M scale without hidden precision loss is stated but not accompanied by any precision or stability analysis; this directly affects the 'exceptional stability' claim.
Authors: We acknowledge the absence of a dedicated precision/stability analysis in the current text. We will add a new subsection (likely in Section 4 or 5) that reports numerical precision metrics (e.g., attention score distributions, KV cache quantization effects) and stability measurements (e.g., perplexity and downstream task variance) when scaling from 16K to 100M tokens under document-wise RoPE and sparse attention. Empirical results from our 100M-token experiments will be presented to substantiate the stability claim. This analysis will be incorporated in the revision. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The abstract and framework description introduce MSA via explicit innovations (scalable sparse attention, document-wise RoPE, KV cache compression, Memory Parallel, Memory Interleaving) that are positioned as direct engineering solutions for linear complexity and <9% degradation scaling. No equations, self-referential definitions, fitted inputs renamed as predictions, or load-bearing self-citations appear that would reduce any claim to its own inputs by construction. The stability and scaling assertions are tied to the listed mechanisms without internal loops or uniqueness theorems imported from the same authors. The derivation remains self-contained against external benchmarks as described.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Sparse attention mechanisms can maintain near-full-attention accuracy at 100M-token scales.
invented entities (1)
-
Memory Sparse Attention (MSA)
no independent evidence
Forward citations
Cited by 1 Pith paper
-
A Comprehensive Survey on Agent Skills: Taxonomy, Techniques, and Applications
The paper surveys agent skills for LLM agents, organizing the literature into a four-stage lifecycle of representation, acquisition, retrieval, and evolution while highlighting their role in system scalability.
Reference graph
Works this paper leans on
-
[1]
LongBench: A Bilingual, Multitask Benchmark for Long Context Understanding
Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, et al. Longbench: A bilingual, multitask benchmark for long context understanding.arXiv preprint arXiv:2308.14508, 2023. 14
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
MS MARCO: A Human Generated MAchine Reading COmprehension Dataset
Payal Bajaj, Daniel Campos, Nick Craswell, Li Deng, Jianfeng Gao, Xiaodong Liu, Rangan Majumder, Andrew McNamara, Bhaskar Mitra, Tri Nguyen, et al. Ms marco: A human generated machine reading comprehension dataset.arXiv preprint arXiv:1611.09268, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[3]
Ali Behrouz, Meisam Razaviyayn, Peilin Zhong, and Vahab Mirrokni. It’s all connected: A journey through test-time memorization, attentional bias, retention, and online optimization. arXiv preprint arXiv:2504.13173, 2025
-
[4]
Nested learning: The illusion of deep learning architectures.arXiv preprint arXiv:2512.24695, 2025
Ali Behrouz, Meisam Razaviyayn, Peilin Zhong, and Vahab Mirrokni. Nested learning: The illusion of deep learning architectures.arXiv preprint arXiv:2512.24695, 2025
-
[5]
Titans: Learning to Memorize at Test Time
Ali Behrouz, Peilin Zhong, and Vahab Mirrokni. Titans: Learning to memorize at test time. arXiv preprint arXiv:2501.00663, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Fireact: Toward language agent fine-tuning, 2023
Baian Chen, Chang Shu, Ehsan Shareghi, Nigel Collier, Karthik Narasimhan, and Shunyu Yao. Fireact: Toward language agent fine-tuning, 2023
work page 2023
-
[7]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[8]
Yuxuan Chen, Dewen Guo, Sen Mei, Xinze Li, Hao Chen, Yishan Li, Yixuan Wang, Chaoyue Tang, Ruobing Wang, Dingjun Wu, et al. Ultrarag: A modular and automated toolkit for adaptive retrieval-augmented generation.arXiv preprint arXiv:2504.08761, 2025
-
[9]
Xin Cheng, Wangding Zeng, Damai Dai, Qinyu Chen, Bingxuan Wang, Zhenda Xie, Kezhao Huang, Xingkai Yu, Zhewen Hao, Yukun Li, et al. Conditional memory via scalable lookup: A new axis of sparsity for large language models.arXiv preprint arXiv:2601.07372, 2026
-
[10]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Behrooz, Fan Rider, Ryan Abbott, Or Honovich, Naveen Jain, Yashar Babaei, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[11]
Agentrefine: Enhancing agent generalization through refinement tuning, 2025
Dayuan Fu, Keqing He, Yejie Wang, Wentao Hong, Zhuoma Gongque, Weihao Zeng, Wei Wang, Jingang Wang, Xunliang Cai, and Weiran Xu. Agentrefine: Enhancing agent generalization through refinement tuning, 2025
work page 2025
-
[12]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Bernal Jiménez Gutiérrez, Yiheng Shu, Weijian Qi, Sizhe Zhou, and Yu Su. From rag to memory: Non-parametric continual learning for large language models.arXiv preprint arXiv:2502.14802, 2025
-
[14]
Dureader: a chinese machine reading comprehension dataset from real-world applications
Wei He, Kai Liu, Jing Liu, Yajuan Lyu, Shiqi Zhao, Xinyan Xiao, Yuan Liu, Yizhong Wang, Hua Wu, Qiaoqiao She, et al. Dureader: a chinese machine reading comprehension dataset from real-world applications. InProceedings of the workshop on machine reading for question answering, pages 37–46, 2018
work page 2018
-
[15]
Measuring Mathematical Problem Solving With the MATH Dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Xi- aodong Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset.ArXiv, abs/2103.03874, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[16]
Xanh Ho, Anh-Khoa Duong Nguyen, Saku Sugawara, and Akiko Aizawa. Constructing a multi-hop qa dataset for comprehensive evaluation of reasoning steps.arXiv preprint arXiv:2011.01060, 2020
-
[17]
RULER: What's the Real Context Size of Your Long-Context Language Models?
Cheng-Ping Hsieh, Simeng Sun, Samuel Kriman, Shantanu Acharya, Dima Rekesh, Fei Jia, Yang Zhang, and Boris Ginsburg. Ruler: What’s the real context size of your long-context language models?arXiv preprint arXiv:2404.06654, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022. 15
work page 2022
-
[19]
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. Swe-bench: Can language models resolve real-world github issues? InThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[20]
TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension
Mandar Joshi, Eunsol Choi, Daniel S Weld, and Luke Zettlemoyer. Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension.arXiv preprint arXiv:1705.03551, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[21]
Prannay Khosla, Piotr Teterwak, Chen Wang, Aaron Sarna, Yonglong Tian, Phillip Isola, Aaron Maschinot, Ce Liu, and Dilip Krishnan. Supervised contrastive learning.Advances in neural information processing systems, 33:18661–18673, 2020
work page 2020
-
[22]
Tomáš Koˇcisk`y, Jonathan Schwarz, Phil Blunsom, Chris Dyer, Karl Moritz Hermann, Gábor Melis, and Edward Grefenstette. The narrativeqa reading comprehension challenge.Transac- tions of the Association for Computational Linguistics, 6:317–328, 2018
work page 2018
-
[23]
The narrativeqa reading comprehension challenge, 2017
Tomáš Koˇciský, Jonathan Schwarz, Phil Blunsom, Chris Dyer, Karl Moritz Hermann, Gábor Melis, and Edward Grefenstette. The narrativeqa reading comprehension challenge, 2017
work page 2017
-
[24]
Toutanova, Llion Jones, Ming-Wei Chang, Andrew Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Matthew Kelcey, Jacob Devlin, Kenton Lee, Kristina N. Toutanova, Llion Jones, Ming-Wei Chang, Andrew Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov. Natural questions: a benchmark for question answering research.Transact...
work page 2019
-
[25]
Thomas K Landauer. How much do people remember? some estimates of the quantity of learned information in long-term memory.Cognitive science, 10(4):477–493, 1986
work page 1986
-
[26]
Retrieval-augmented generation for knowledge-intensive nlp tasks
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. Retrieval-augmented generation for knowledge-intensive nlp tasks. In H. Larochelle, M. Ranzato, R. Hadsell, M.F. Balcan, and H. Lin, editors,Advances in Neural Informa...
work page 2020
-
[27]
Camel: Communicative agents for "mind" exploration of large scale model society
Guohao Li, Hasan Abed Al Kader Hammoud, Hani Itani, Dmitriy Khizanishvili, and Bernard Ghanem. Camel: Communicative agents for "mind" exploration of large scale model society. InThirty-seventh Conference on Neural Information Processing Systems, 2023
work page 2023
-
[28]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, et al. Deepseek-v3. 2: Pushing the frontier of open large language models.arXiv preprint arXiv:2512.02556, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Nelson F Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the middle: How language models use long contexts.Transactions of the Association for Computational Linguistics, 12:157–173, 2024
work page 2024
-
[30]
Alex Mallen, Akari Asai, Victor Zhong, Rajarshi Das, Daniel Khashabi, and Hannaneh Ha- jishirzi. When not to trust language models: Investigating effectiveness of parametric and non-parametric memories, 2023
work page 2023
-
[31]
OpenAI, Aaron Hurst, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
Generative agents: Interactive simulacra of human behavior
Joon Sung Park, Joseph C O’Brien, Carrie J Cai, Meredith Ringel Morris, Percy Liang, and Michael S Bernstein. Generative agents: Interactive simulacra of human behavior. InProceed- ings of the 36th Annual ACM Symposium on User Interface Software and Technology, pages 1–22, 2023
work page 2023
-
[33]
Rwkv: Reinventing rnns for the transformer era, 2023
Bo Peng, Eric Alcaide, Quentin Anthony, Alon Albalak, Samuel Arcadinho, Stella Biderman, Huanqi Cao, Xin Cheng, Michael Chung, Matteo Grella, et al. Rwkv: Reinventing rnns for the transformer era, 2023
work page 2023
-
[34]
Linear transformers are secretly fast weight programmers
Imanol Schlag, Kazuki Irie, and Jürgen Schmidhuber. Linear transformers are secretly fast weight programmers. InInternational conference on machine learning, pages 9355–9366. PMLR, 2021. 16
work page 2021
-
[35]
Smith, Luke Zettlemoyer, Pang Wei Koh, Hannaneh Hajishirzi, Ali Farhadi, and Sewon Min
Weijia Shi, Akshita Bhagia, Kevin Farhat, Niklas Muennighoff, Pete Walsh, Jacob Morrison, Dustin Schwenk, Shayne Longpre, Jake Poznanski, Allyson Ettinger, Daogao Liu, Margaret Li, Dirk Groeneveld, Mike Lewis, Wen tau Yih, Luca Soldaini, Kyle Lo, Noah A. Smith, Luke Zettlemoyer, Pang Wei Koh, Hannaneh Hajishirzi, Ali Farhadi, and Sewon Min. Flexolmo: Open...
work page 2025
-
[36]
Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
work page 2024
-
[37]
Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal. Musique: Multihop questions via single-hop question composition.Transactions of the Association for Computational Linguistics, 10:539–554, 2022
work page 2022
-
[38]
Rolellm: Benchmarking, eliciting, and enhancing role-playing abilities of large language models
Zekun Wang, Jianan Liu, Weizhi Ren, Zhimin Zhou, Shuyuan Chen, Ge Shen, Yujun Zhang, TianmAo Wu, Chunhua Wu, Tao Gui, et al. Rolellm: Benchmarking, eliciting, and enhancing role-playing abilities of large language models. InThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[39]
Mlp memory: A retriever-pretrained memory for large language models, 2025
Rubin Wei, Jiaqi Cao, Jiarui Wang, Jushi Kai, Qipeng Guo, Bowen Zhou, and Zhouhan Lin. Mlp memory: A retriever-pretrained memory for large language models, 2025
work page 2025
-
[40]
Parallelcomp: Parallel long-context compressor for length extrapolation, 2025
Jing Xiong, Jianghan Shen, Chuanyang Zheng, Zhongwei Wan, Chenyang Zhao, Chiwun Yang, Fanghua Ye, Hongxia Yang, Lingpeng Kong, and Ngai Wong. Parallelcomp: Parallel long-context compressor for length extrapolation, 2025
work page 2025
-
[41]
Derong Xu, Yi Wen, Pengyue Jia, Yingyi Zhang, wenlin zhang, Yichao Wang, Huifeng Guo, Ruiming Tang, Xiangyu Zhao, Enhong Chen, and Tong Xu. From single to multi-granularity: Toward long-term memory association and selection of conversational agents, 2025
work page 2025
-
[42]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, and Bo Zheng et al. Qwen3 technical report, 2025
work page 2025
-
[43]
Qwen2.5 technical report, 2025
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li, Tianyi T...
work page 2025
-
[44]
Memory 3: Language modeling with explicit memory.Journal of Machine Learning, 3:300–346, 09 2024
Hongkang Yang, Zehao Lin, Wenjin Wang, Hao Wu, Zhiyu Li, Bo Tang, Wenqiang Wei, Jinbo Wang, Zeyun Tang, Shichao Song, Chenyang Xi, Yu Yu, Kai Chen, Feiyu Xiong, Linpeng Tang, and Weinan E. Memory 3: Language modeling with explicit memory.Journal of Machine Learning, 3:300–346, 09 2024
work page 2024
-
[45]
Songlin Yang, Bailin Wang, Yu Zhang, Yikang Shen, and Yoon Kim. Parallelizing linear transformers with the delta rule over sequence length.Advances in neural information processing systems, 37:115491–115522, 2024
work page 2024
-
[46]
HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William W Cohen, Ruslan Salakhut- dinov, and Christopher D Manning. Hotpotqa: A dataset for diverse, explainable multi-hop question answering.arXiv preprint arXiv:1809.09600, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[47]
Agent lumos: Unified and modular training for open-source language agents, 2024
Da Yin, Faeze Brahman, Abhilasha Ravichander, Khyathi Chandu, Kai-Wei Chang, Yejin Choi, and Bill Yuchen Lin. Agent lumos: Unified and modular training for open-source language agents, 2024
work page 2024
-
[49]
MemAgent: Reshaping Long-Context LLM with Multi-Conv RL-based Memory Agent
Hongli Yu, Tinghong Chen, Jiangtao Feng, Jiangjie Chen, Weinan Dai, Qiying Yu, Ya-Qin Zhang, Wei-Ying Ma, Jingjing Liu, Mingxuan Wang, and Hao Zhou. Memagent: Reshaping long-context llm with multi-conv rl-based memory agent.ArXiv, abs/2507.02259, 2025. 17
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[50]
Memgen: Weaving generative latent memory for self-evolving agents, 2025
Guibin Zhang, Muxin Fu, and Shuicheng Yan. Memgen: Weaving generative latent memory for self-evolving agents, 2025
work page 2025
-
[51]
Agentohana: Design unified data and training pipeline for effective agent learning, 2024
Jianguo Zhang, Tian Lan, Rithesh Murthy, Zhiwei Liu, Weiran Yao, Ming Zhu, Juntao Tan, Thai Hoang, Zuxin Liu, Liangwei Yang, Yihao Feng, Shirley Kokane, Tulika Awalgaonkar, Juan Carlos Niebles, Silvio Savarese, Shelby Heinecke, Huan Wang, and Caiming Xiong. Agentohana: Design unified data and training pipeline for effective agent learning, 2024
work page 2024
-
[52]
Xinrong Zhang, Yingfa Chen, Shengding Hu, Zihang Xu, Junhao Chen, Moo Hao, Xu Han, Zhen Thai, Shuo Wang, Zhiyuan Liu, et al. Infinitebench: Extending long context evaluation beyond 100k tokens.arXiv preprint arXiv:2402.13718, 2024
-
[53]
Qwen3 embedding: Advancing text embedding and reranking through foundation models, 2025
Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, Fei Huang, and Jingren Zhou. Qwen3 embedding: Advancing text embedding and reranking through foundation models, 2025
work page 2025
-
[54]
Xinping Zhao, Xinshuo Hu, Zifei Shan, Shouzheng Huang, Yao Zhou, Xin Zhang, Zetian Sun, Zhenyu Liu, Dongfang Li, Xinyuan Wei, et al. Kalm-embedding-v2: Superior training techniques and data inspire a versatile embedding model.arXiv preprint arXiv:2506.20923, 2025. 18 A Prompts PROMPTTEMPLATE FORLLMAS AJUDGE Based on the accuracy, completeness, and relevan...
-
[55]
The predicted answer is completely unrelated to the query, consists of gibberish, or is a pure hallucination that shares no logical connection with the real answer. Query: {query} True Answer: {gold_answer} Predicted Answer: {model_answer} Output only a single number (0, 1, 2, 3, 4, or 5): B Pre-training Data Composition To ensure the model possesses both...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.