Recognition: no theorem link
SlopCodeBench: Benchmarking How Coding Agents Degrade Over Long-Horizon Iterative Tasks
Pith reviewed 2026-05-15 00:11 UTC · model grok-4.3
The pith
Coding agents cannot complete any full problem and their code grows more verbose and structurally eroded with each iterative extension.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
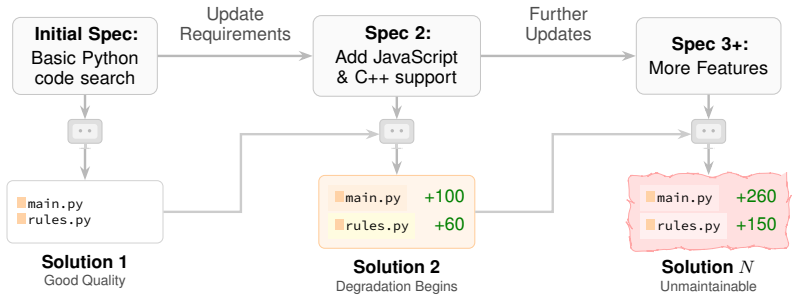
SlopCodeBench consists of 36 problems and 196 checkpoints where agents must extend their own solutions according to evolving specifications that require architectural decisions but leave internal structure open. Across 15 evaluated agents, none solve any problem completely end-to-end and the strongest passes only 14.8 percent of checkpoints. Structural erosion increases in 77 percent of trajectories and verbosity increases in 75.5 percent. Agent code is on average 2.3 times more verbose and 2.0 times more eroded than code in 473 human open-source Python repositories, which show smaller and less frequent degradation across their git histories. Adding explicit quality guidance to prompts cuts
What carries the argument
SlopCodeBench benchmark that tracks structural erosion as concentrated complexity and verbosity as redundant code across sequences of agent-generated code extensions.
If this is right
- Explicit quality guidance in prompts reduces initial verbosity and erosion by up to one third but does not slow subsequent degradation rates.
- Agent code starts worse than typical human repositories and diverges further with each extension.
- No evaluated agent maintains solution quality while performing the required iterative extensions.
- Human repositories degrade less often and by smaller margins across their commit histories than agent trajectories.
Where Pith is reading between the lines
- Teams using agents for ongoing development may incur rising maintenance costs from accumulating bloat and complexity.
- Future benchmarks could add periodic refactoring steps to test whether agents can self-correct degradation.
- The gap between agent and human code quality suggests agents need built-in mechanisms for pruning or simplifying prior work.
- Architectural freedom in the benchmark may expose decision-making weaknesses that more constrained setups hide.
Load-bearing premise
The chosen metrics for structural erosion and verbosity accurately reflect meaningful degradation that would matter in real software projects beyond the 36 selected problems.
What would settle it
Finding even one agent that completes multiple full problems while keeping both structural erosion and verbosity stable or decreasing across all 196 checkpoints would falsify the central degradation claim.
Figures





read the original abstract
Software development is iterative, yet agentic coding benchmarks hide design issues through their single-shot setup. Recent iterative benchmarks attempt to remedy this but heavily constrain an agent's design decision space, making it impossible to faithfully measure how their decisions shape future extensions. We introduce SlopCodeBench, a benchmark of 36 problems and 196 checkpoints where agents repeatedly extend their own solutions. Unlike prior iterative benchmarks, our evolving specifications demand architectural decisions but leave internal structure to the agent. We measure two forms of degradation: structural erosion (concentrated complexity) and verbosity (redundant code). Evaluating 15 coding agents across open and closed models, we find that no agent fully solves any problem end-to-end, and the best agent passes 14.8% of checkpoints. Quality degrades across checkpoints, with structural erosion rising in 77% of trajectories and verbosity in 75.5%. Compared to 473 open-source Python repositories, agent code is 2.3x more verbose and 2.0x more eroded, and the human repositories degrade less often and by smaller margins across their git histories. Explicit quality guidance reduces initial verbosity and erosion by up to a third, without affecting degradation rates. SlopCodeBench provides the first measurement of code degradation under iterative extension, revealing that agents pass checkpoints while producing code that erodes and bloats with each turn.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SlopCodeBench, a benchmark of 36 problems and 196 checkpoints for evaluating coding agents on long-horizon iterative extension tasks where agents build on their own prior solutions under evolving specifications. It reports that no agent fully solves any problem end-to-end, with the best agent passing only 14.8% of checkpoints. Quality degrades over iterations, with structural erosion (concentrated complexity) rising in 77% of trajectories and verbosity (redundant code) in 75.5%. Agent code is 2.3x more verbose and 2.0x more eroded than code from 473 open-source Python repositories, while human git histories show less frequent and smaller degradation; explicit quality guidance reduces initial issues by up to a third but does not alter degradation rates.
Significance. If the custom metrics prove valid, the work fills a gap in agent evaluation by moving beyond single-shot benchmarks to measure iterative degradation, with the open comparison to real repositories and git histories providing a useful empirical anchor. The finding that agents pass checkpoints while producing progressively eroded and bloated code has direct implications for deploying coding agents in sustained software development.
major comments (2)
- [§4.1] §4.1 (Metric Definitions): The central claims of degradation and the 2.0x/2.3x comparisons to the 473 repositories rest on the structural erosion and verbosity metrics, yet the manuscript provides no validation (e.g., correlation with bug density, maintenance effort, or developer surveys) that these proxies capture practically meaningful quality loss rather than superficial syntactic changes.
- [§5.3] §5.3 (Human Repository Comparison): The assertion that human repositories degrade less often and by smaller margins requires explicit confirmation that the same erosion and verbosity formulas were applied to the git histories with equivalent checkpoint alignment; without this, the differential degradation result is not directly comparable.
minor comments (2)
- [Table 2] Table 2: The checkpoint pass-rate column would be clearer if it distinguished first-attempt versus cumulative success across the 196 checkpoints.
- [Figure 4] Figure 4: Axis labels on the erosion/verbosity trajectory plots should explicitly state the units or normalization used for the y-axes.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and have revised the manuscript to strengthen the presentation of our metrics and comparisons.
read point-by-point responses
-
Referee: [§4.1] §4.1 (Metric Definitions): The central claims of degradation and the 2.0x/2.3x comparisons to the 473 repositories rest on the structural erosion and verbosity metrics, yet the manuscript provides no validation (e.g., correlation with bug density, maintenance effort, or developer surveys) that these proxies capture practically meaningful quality loss rather than superficial syntactic changes.
Authors: We agree that explicit validation against external criteria such as bug density would strengthen the claims. Our structural erosion metric quantifies concentration of cyclomatic complexity (following McCabe 1976 and subsequent maintainability studies), while verbosity detects redundant code via AST-based duplication. These draw on established software engineering proxies rather than being ad-hoc. In the revised manuscript we have expanded §4.1 with additional citations to prior work validating similar metrics and have added an explicit limitations paragraph acknowledging the absence of new correlation studies in this paper. We view the metrics as reasonable proxies for the degradation phenomenon we measure, but we do not claim they are fully validated substitutes for direct quality outcomes. revision: partial
-
Referee: [§5.3] §5.3 (Human Repository Comparison): The assertion that human repositories degrade less often and by smaller margins requires explicit confirmation that the same erosion and verbosity formulas were applied to the git histories with equivalent checkpoint alignment; without this, the differential degradation result is not directly comparable.
Authors: We confirm that identical formulas were used. For the 473 repositories we sampled commit histories and aligned measurement points to intervals comparable to the benchmark checkpoints (i.e., after each logical extension step). We have added a new paragraph in §5.3 and a short appendix subsection that explicitly describes the extraction procedure, commit selection criteria, and alignment method to make the comparison transparent and reproducible. revision: yes
Circularity Check
No significant circularity in empirical benchmark evaluation
full rationale
The paper introduces SlopCodeBench with 36 problems and 196 checkpoints, evaluates 15 agents by direct execution on iterative extensions, computes structural erosion and verbosity via code analysis metrics, and compares results to 473 external open-source Python repositories plus git histories. All central claims (14.8% checkpoint pass rate, 77% erosion rise, 75.5% verbosity rise, 2.3x/2.0x factors) follow from these measurements without any derivation step reducing to a fitted parameter, self-definition, or self-citation chain. Metrics are applied as defined to observed code; no ansatz, uniqueness theorem, or renaming of known results is invoked to force outcomes. The evaluation stands as self-contained against external data.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Structural erosion and verbosity metrics validly measure code quality degradation
Reference graph
Works this paper leans on
-
[1]
Jianming Chang, Songqiang Chen, Chao Peng, Hao Yu, Zhiming Li, Pengfei Gao, and Tao Xie
URLhttps://arxiv.org/abs/2511.13972. Jianming Chang, Songqiang Chen, Chao Peng, Hao Yu, Zhiming Li, Pengfei Gao, and Tao Xie. LessLeak-Bench: A first investigation of data leakage in LLMs across 83 software engineering benchmarks, 2026. Jialong Chen, Xander Xu, Hu Wei, Chuan Chen, and Bing Zhao. Swe-ci: Evaluating agent capabilities in maintaining codebas...
-
[2]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
ISBN 978-0201485677. 13 International Organization for Standardization. ISO/IEC 25010:2011 systems and software engineer- ing – systems and software quality requirements and evaluation (SQuaRE) – system and software quality models, 2011. Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. Swe-bench: C...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2310.06770 2011
-
[3]
URLhttps://arxiv.org/abs/2601.11868. Chunyu Miao, Henry Peng Zou, Yangning Li, Yankai Chen, Yibo Wang, Fangxin Wang, Yifan Li, Wooseong Yang, Bowei He, Xinni Zhang, Dianzhi Yu, Hanchen Yang, Hoang Nguyen, Yue Zhou, Jie Yang, Jizhou Guo, Wenzhe Fan, Chin-Yuan Yeh, Panpan Meng, Liancheng Fang, Jinhu Qi, Wei-Chieh Huang, Zhengyao Gu, Yuwei Han, Langzhou He, ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2302.01973 2025
-
[4]
URLhttps://github.com/SWE-agent/mini-swe-agent. GitHub repository. 15 Boxi Yu, Yang Cao, Yuzhong Zhang, Liting Lin, Junjielong Xu, Zhiqing Zhong, Qinghua Xu, Guancheng Wang, Jialun Cao, Shing-Chi Cheung, Pinjia He, and Lionel Briand. SWE-ABS: Adversarial benchmark strengthening exposes inflated success rates on test-based benchmark, 2026. Daoguang Zan, Zh...
work page internal anchor Pith review doi:10.48550/arxiv 2026
-
[5]
BigCodeBench: Benchmarking Code Generation with Diverse Function Calls and Complex Instructions
URLhttps://arxiv.org/abs/2511.04064. Zexun Zhan, Shuzheng Gao, Ruida Hu, and Cuiyun Gao. Sr-eval: Evaluating llms on code generation under stepwise requirement refinement, 2025. Binquan Zhang, Li Zhang, Lin Shi, Song Wang, Yuwei Qian, Linhui Zhao, Fang Liu, An Fu, and Yida Ye. An empirical study of interaction smells in multi-turn human-llm collaborative ...
work page internal anchor Pith review doi:10.48550/arxiv.2406.15877 2025
-
[6]
Before coding plan out what you need to implement
-
[7]
Write the simple solution first
-
[8]
Ensure it is 100% correct and you have covered all edge cases
-
[9]
id": "<non-empty string>
Refactor to ensure the code is high quality. Here are the basic style rules you must follow: - Make sure the code is documented appropriately so that it is easy to pick up. - Minimize the following gotchas: - Extra defensive checks or try/catch blocks that are abnormal. - Casts to get around type checking - Variables that are only used a single time after...
-
[10]
Ordering: Matches must appear by file (lexicographically), then start.line, then start.col, then rule_id
-
[11]
Coordinates: Lines and columns are 1-based
-
[12]
Path format: file is relative to <root_dir> with ’/’ separators
-
[13]
languages
Encoding: Read files using --encoding (default utf-8); skip files 20 that fail to decode. Listing 7: Specification forcode_searchcheckpoint 1 D.2 Checkpoint 2: Multi-language Support with Filtering Extend your code searcher to support JavaScript and C++ source files. --- ## New Requirements ### File type -> language Scan these extensions: | Language | Ext...
-
[14]
Pattern determinism: When multiple matches share the same start position, sort by end position (earlier end first), then by rule_id
-
[15]
Listing 9: Specification forcode_searchcheckpoint 3 E Problem Overview Table 5 lists all 20 problems in SlopCodeBench
Captures key order: Serialize captures with keys sorted lexicographically by metavariable name (e.g., $A before $X). Listing 9: Specification forcode_searchcheckpoint 3 E Problem Overview Table 5 lists all 20 problems in SlopCodeBench. Problems span CLIs, REST APIs, DSL interpreters, and file-processing pipelines. Each begins with a focused deliverable an...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.