Recognition: 2 theorem links
· Lean TheoremEnvironment-Aware Channel Prediction for Vehicular Communications: A Multimodal Visual Feature Fusion Framework
Pith reviewed 2026-05-13 21:53 UTC · model grok-4.3
The pith
Fusing semantic and depth features from vehicle cameras predicts radio channel metrics like path loss and angular spreads in urban settings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
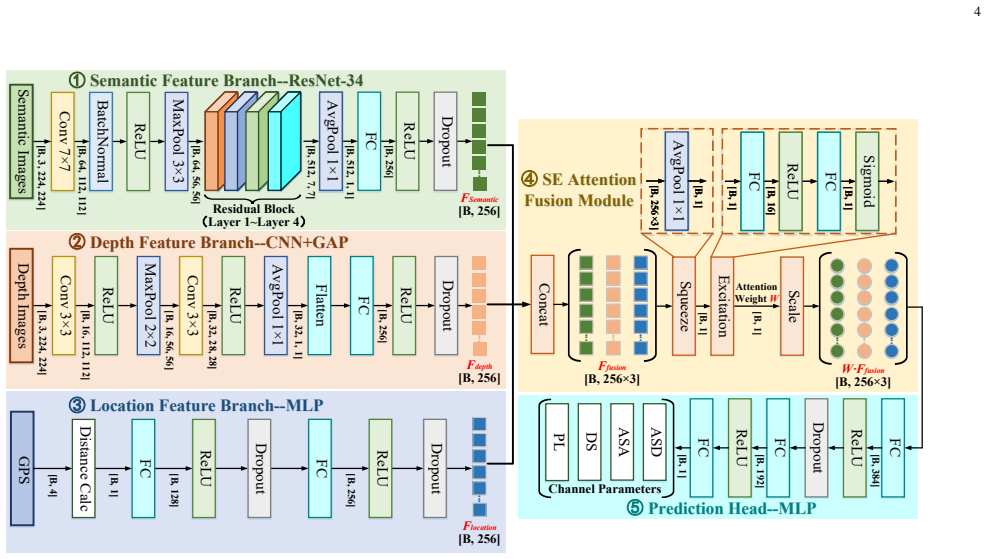
The environment-aware framework extracts semantic, depth, and position features via a three-branch network from vehicle-side panoramic RGB images and GPS, fuses them adaptively through a squeeze-excitation attention module, and applies a dedicated regression head with composite loss to jointly predict path loss, delay spread, azimuth spread of arrival, azimuth spread of departure, and 360-dimensional angular power spectrum, reaching 3.26 dB RMSE for path loss and 0.9342 mean cosine similarity for the spectrum on urban V2I data.
What carries the argument
Three-branch architecture that extracts semantic segmentation, depth estimation, and position features from RGB images, then performs adaptive fusion via squeeze-excitation attention gating before regression to channel parameters.
If this is right
- Path loss can be predicted to 3.26 dB RMSE using only onboard visual and position data.
- Delay spread reaches 37.66 ns RMSE accuracy without direct channel sounding.
- Azimuth spreads of arrival and departure achieve roughly 5 degree RMSE.
- Full angular power spectrum maintains mean cosine similarity above 0.93.
- Joint multi-metric prediction supports lower-latency adaptation in vehicular links.
Where Pith is reading between the lines
- The same visual pipeline could reduce pilot overhead by supplying priors that cut the frequency of explicit channel measurements.
- Extending the fusion module to include LiDAR or radar point clouds might tighten predictions in low-visibility conditions.
- Retraining on mixed indoor-outdoor datasets could test whether the same structure transfers beyond pure urban V2I.
Load-bearing premise
Visual semantic and depth features from RGB images supply enough information about scattering, blockage, and other radio effects to generalize across different urban scenes.
What would settle it
A sharp rise in prediction error when the trained model is evaluated on synchronized measurements collected in a new city whose building layouts and materials differ substantially from the training set.
Figures













read the original abstract
The deep integration of communication with intelligence and sensing, as a defining vision of 6G, renders environment-aware channel prediction a key enabling technology. As a representative 6G application, vehicular communications require accurate and forward-looking channel prediction under stringent reliability, latency, and adaptability demands. Traditional empirical and deterministic models remain limited in balancing accuracy, generalization, and deployability, while the growing availability of onboard and roadside sensing devices offers a promising source of environmental priors. This paper proposes an environment-aware channel prediction framework based on multimodal visual feature fusion. Using GPS data and vehicle-side panoramic RGB images, together with semantic segmentation and depth estimation, the framework extracts semantic, depth, and position features through a three-branch architecture and performs adaptive multimodal fusion via a squeeze-excitation attention gating module. For 360-dimensional angular power spectrum (APS) prediction, a dedicated regression head and a composite multi-constraint loss are further designed. As a result, joint prediction of path loss (PL), delay spread (DS), azimuth spread of arrival (ASA), azimuth spread of departure (ASD), and APS is achieved. Experiments on a synchronized urban V2I measurement dataset yield the best root mean square error (RMSE) of 3.26 dB for PL, RMSEs of 37.66 ns, 5.05 degrees, and 5.08 degrees for DS, ASA, and ASD, respectively, and mean/median APS cosine similarities of 0.9342/0.9571, demonstrating strong accuracy, generalization, and practical potential for intelligent channel prediction in 6G vehicular communications.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an environment-aware channel prediction framework for vehicular communications that fuses multimodal visual features from panoramic RGB images (via semantic segmentation and depth estimation) with GPS data using a three-branch architecture and squeeze-excitation attention for adaptive fusion. It predicts path loss (PL), delay spread (DS), azimuth spreads (ASA, ASD), and 360-dimensional angular power spectrum (APS) with a dedicated regression head and multi-constraint loss. On a synchronized urban V2I measurement dataset, it reports RMSE of 3.26 dB for PL, 37.66 ns for DS, 5.05° for ASA, 5.08° for ASD, and mean/median APS cosine similarities of 0.9342/0.9571.
Significance. If the reported performance holds under rigorous validation, this work could advance 6G vehicular communications by showing how onboard sensing enables more accurate forward-looking channel prediction, potentially outperforming traditional empirical models in dynamic environments. The multimodal fusion approach aligns with the vision of integrating communication, intelligence, and sensing.
major comments (3)
- [Experiments] Experimental evaluation: No ablation studies are reported that isolate the contribution of the visual semantic and depth branches (e.g., by removing them and retraining on GPS alone), so it is unclear whether the reported RMSE and cosine similarity gains are attributable to multimodal fusion or to dataset-specific correlations.
- [Experiments] Dataset and evaluation protocol: The results are obtained on a single synchronized urban V2I measurement campaign with no cross-scenario splits (different street layouts, building materials, or cities) or held-out test environments, leaving the generalization claims unsupported by evidence.
- [Experiments] Statistical reporting: The abstract and results provide point estimates for RMSE and APS similarities but omit training/validation split details, number of samples, error bars, or statistical significance tests, which are required to substantiate the central performance claims.
minor comments (2)
- [Methodology] The abstract mentions a 'composite multi-constraint loss' for APS regression but does not specify the individual loss terms or their weighting; this should be clarified in the methodology section.
- [Figures] Figure captions and axis labels for any performance plots should explicitly state the number of test samples and whether results are averaged over multiple runs.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help improve the rigor of our work. We address each major comment point-by-point below, indicating planned revisions where feasible.
read point-by-point responses
-
Referee: [Experiments] Experimental evaluation: No ablation studies are reported that isolate the contribution of the visual semantic and depth branches (e.g., by removing them and retraining on GPS alone), so it is unclear whether the reported RMSE and cosine similarity gains are attributable to multimodal fusion or to dataset-specific correlations.
Authors: We agree that ablation studies are necessary to isolate modality contributions. The revised manuscript will include new ablation experiments: full model vs. GPS-only, semantic-only, depth-only, and pairwise combinations, with quantitative comparisons of RMSE and APS similarity to demonstrate the gains from multimodal fusion. revision: yes
-
Referee: [Experiments] Dataset and evaluation protocol: The results are obtained on a single synchronized urban V2I measurement campaign with no cross-scenario splits (different street layouts, building materials, or cities) or held-out test environments, leaving the generalization claims unsupported by evidence.
Authors: Our results are from one comprehensive urban campaign. We will add intra-dataset splits (e.g., by route segments or time-of-day) for better internal validation and explicitly discuss limitations on broader generalization. Cross-city experiments are not possible without new measurements. revision: partial
-
Referee: [Experiments] Statistical reporting: The abstract and results provide point estimates for RMSE and APS similarities but omit training/validation split details, number of samples, error bars, or statistical significance tests, which are required to substantiate the central performance claims.
Authors: We will revise the results section to report dataset size, exact train/validation/test splits, standard deviations from multiple runs, and statistical significance tests (e.g., t-tests) to support the performance claims. revision: yes
- Cross-scenario validation on datasets from different cities or environments, as this requires new synchronized measurement campaigns beyond the scope of the current study.
Circularity Check
No significant circularity in derivation chain
full rationale
The paper presents a standard supervised multimodal neural network for regressing channel statistics (PL, DS, ASA, ASD, APS) from fused visual semantic/depth features and GPS inputs. The architecture, attention gating, and composite loss are conventional design choices; the reported RMSE and cosine similarity values are model outputs evaluated on held-out measurement data rather than quantities defined by construction from the same fitted parameters. No equations reduce predictions to inputs, no self-citation chain supplies a uniqueness theorem, and no ansatz is smuggled via prior work. The derivation is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
three-branch architecture ... squeeze-excitation attention gating module ... composite multi-constraint loss
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Experiments on a synchronized urban V2I measurement dataset
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Environment- aware path loss prediction using panoramic images for vehicular com- munications,
X. Zhang, M. Kim, I. Calist, R. He, M. Yang, and Z. Qi, “Environment- aware path loss prediction using panoramic images for vehicular com- munications,” inProc. IEEE Int. Conf. Commun. (ICC), accepted, 2026, pp. 1–6
work page 2026
-
[2]
Framework and overall objectives of the future development of IMT for 2030 and beyond,
ITU-R, “Framework and overall objectives of the future development of IMT for 2030 and beyond,”DRAFT NEW RECOMMENDATION, Jun. 2023
work page 2030
-
[3]
A general channel model for integrated sensing and communication scenarios,
Z. Zhanget al., “A general channel model for integrated sensing and communication scenarios,”IEEE Commun. Mag., vol. 61, no. 5, pp. 68–74, 2022
work page 2022
-
[4]
COST CA20120 INTERACT framework of artificial intelligence-based channel modeling,
R. He, N. D. Cicco, B. Ai, M. Yang, Y . Miao, and M. Boban, “COST CA20120 INTERACT framework of artificial intelligence-based channel modeling,”IEEE Wirel. Commun., vol. 32, no. 4, pp. 200–207, 2025
work page 2025
-
[5]
R. Heet al., “Propagation channels of 5G millimeter-wave vehicle-to- vehicle communications: Recent advances and future challenges,”IEEE Veh. Technol. Mag., vol. 15, no. 1, pp. 16–26, 2020
work page 2020
-
[6]
R. He, M. Yang, Z. Zhang, B. Ai, and Z. Zhong, “Artificial intelligence empowered channel prediction: A new paradigm for propagation channel modeling,”arXiv preprint arXiv:2601.09205, 2026
-
[7]
C. Huanget al., “Artificial intelligence enabled radio propagation for communications—Part I: Channel characterization and antenna-channel optimization,”IEEE Trans. Antennas Propag., vol. 70, no. 6, pp. 3939– 3954, 2022
work page 2022
-
[8]
Multi-modal intelligent channel modeling: A new modeling paradigm via synesthesia of machines,
L. Bai, Z. Huang, M. Sun, X. Cheng, and L. Cui, “Multi-modal intelligent channel modeling: A new modeling paradigm via synesthesia of machines,”IEEE Commun. Surveys Tuts., vol. 28, pp. 2612–2649, 2026
work page 2026
-
[9]
Y . Tian, G. Pan, and M.-S. Alouini, “Applying deep-learning-based com- puter vision to wireless communications: Methodologies, opportunities, and challenges,”IEEE Open J. Commun. Society, vol. 2, pp. 132–143, 2021
work page 2021
-
[10]
When wireless communications meet computer vision in beyond 5G,
T. Nishio, Y . Koda, J. Park, M. Bennis, and K. Doppler, “When wireless communications meet computer vision in beyond 5G,”IEEE Commun. Standards Mag., vol. 5, no. 2, pp. 76–83, 2021
work page 2021
-
[11]
Vision-aided 6G wireless communications: Blockage prediction and proactive handoff,
G. Charan, M. Alrabeiah, and A. Alkhateeb, “Vision-aided 6G wireless communications: Blockage prediction and proactive handoff,”IEEE Trans. Veh. Technol., vol. 70, no. 10, pp. 10 193–10 208, 2021
work page 2021
-
[12]
Y . Yang, F. Gao, X. Tao, G. Liu, and C. Pan, “Environment semantics aided wireless communications: A case study of mmWave beam pre- diction and blockage prediction,”IEEE J. Sel. Areas Commun., vol. 41, no. 7, pp. 2025–2040, 2023
work page 2025
-
[13]
Environment semantic com- munication: Enabling distributed sensing aided networks,
S. Imran, G. Charan, and A. Alkhateeb, “Environment semantic com- munication: Enabling distributed sensing aided networks,”IEEE Open Journal of the Communications Society, vol. 5, pp. 7767–7786, 2024
work page 2024
-
[14]
Camera based mmWave beam prediction: Towards multi-candidate real-world scenarios,
G. Charan, M. Alrabeiah, T. Osman, and A. Alkhateeb, “Camera based mmWave beam prediction: Towards multi-candidate real-world scenarios,”IEEE Trans. Veh. Technol., vol. 74, no. 4, pp. 5897–5913, 2025
work page 2025
-
[15]
Deepsense 6G: A large-scale real-world multi-modal sensing and communication dataset,
A. Alkhateeb, G. Charan, T. Osman, A. Hredzak, J. Morais, U. Demirhan, and N. Srinivas, “Deepsense 6G: A large-scale real-world multi-modal sensing and communication dataset,”IEEE Commun. Mag., vol. 61, no. 9, pp. 122–128, 2023
work page 2023
-
[16]
Environment sensing- aided beam prediction with transfer learning for smart factory,
Y . Feng, C. Zhao, F. Gao, Y . Zhang, and S. Ma, “Environment sensing- aided beam prediction with transfer learning for smart factory,”IEEE Trans. Wireless Commun., vol. 24, no. 1, pp. 676–690, 2025
work page 2025
-
[17]
Proactive received power prediction using machine learning and depth images for mmWave networks,
T. Nishio, H. Okamoto, K. Nakashima, Y . Koda, K. Yamamoto, M. Morikura, Y . Asai, and R. Miyatake, “Proactive received power prediction using machine learning and depth images for mmWave networks,”IEEE J. Sel. Areas Commun., vol. 37, no. 11, pp. 2413–2427, 2019
work page 2019
-
[18]
X. Zhang, R. He, M. Yang, Z. Zhang, Z. Qi, and B. Ai, “Vision aided channel prediction for vehicular communications: A case study of received power prediction using RGB images,”IEEE Trans. Veh. Technol., vol. 74, no. 11, pp. 17 531–17 544, 2025
work page 2025
-
[19]
Multi- modal environmental information sensing based path loss prediction for V2I communications,
K. Wang, L. Yu, J. Zhang, Y . Tian, E. Guo, and G. Liu, “Multi- modal environmental information sensing based path loss prediction for V2I communications,” inProc. IEEE 101st Veh. Technol. Conf. (VTC- Spring), 2025, pp. 1–5
work page 2025
-
[20]
Z. Wei, B. Mao, H. Guo, Y . Xun, J. Liu, and N. Kato, “An intelligent path loss prediction approach based on integrated sensing and communi- cations for future vehicular networks,”IEEE Open J. Commun. Society, vol. 5, pp. 170–180, 2024
work page 2024
-
[21]
M. Lu, L. Bai, Z. Huang, M. Yang, and X. Cheng, “Path loss pre- diction for vehicle-to-infrastructure communications via synesthesia of machines (SoM),”Radio Sci., vol. 60, no. 6, pp. 1–15, 2025
work page 2025
-
[22]
M. Sun, L. Bai, Z. Huang, and X. Cheng, “Multi-modal sensing data- based real-time path loss prediction for 6G UA V-to-ground communi- cations,”IEEE Wireless Commun. Lett., vol. 13, no. 9, pp. 2462–2466, 2024
work page 2024
-
[23]
Vision-aided channel prediction based on image segmentation at street intersection scenarios,
X. Zhang, R. He, M. Yang, Z. Qi, Z. Zhang, B. Ai, and Z. Zhong, “Vision-aided channel prediction based on image segmentation at street intersection scenarios,”IEEE Trans. on Cogn. Commun. Netw., vol. 12, pp. 1678–1693, 2026
work page 2026
-
[24]
A multimodal predictive channel model based on dual-camera images for IIoT communications,
S. Zhou, Y . Liu, R. Wang, Z. Li, Z. Xin, J. Huang, and J. Bian, “A multimodal predictive channel model based on dual-camera images for IIoT communications,”IEEE Internet Things J., vol. 12, no. 12, pp. 20 530–20 543, 2025
work page 2025
-
[25]
Multimodal fusion-based channel prediction and characterization for mmWave UA V A2G communications,
Z. Xin, Y . Liu, J. Xing, J. Huang, J. Bian, Z. Bai, and C. Wang, “Multimodal fusion-based channel prediction and characterization for mmWave UA V A2G communications,”IEEE Trans. Commun., vol. 74, pp. 5089–5104, 2026
work page 2026
-
[26]
B. Yin, Y . Miao, A. Bodi, R. Caromi, J. Senic, C. Gentile, W. Joseph, and M. Deruyck, “A cluster-based predictive channel modeling for mmwave communications via deep transfer learning: A multimodal data-driven approach,”IEEE Trans. Veh. Technol., pp. 1–16, 2026
work page 2026
-
[27]
M3SC: A generic dataset for mixed multi-modal (MMM) sensing and communication integration,
X. Cheng, Z. Huang, L. Bai, H. Zhang, M. Sun, B. Liu, S. Li, J. Zhang, and M. Lee, “M3SC: A generic dataset for mixed multi-modal (MMM) sensing and communication integration,”China Commun., vol. 20, no. 11, pp. 13–29, 2023
work page 2023
-
[28]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), June 2016
work page 2016
-
[29]
M. Kim, J.-i. Takada, and Y . Konishi, “Novel scalable MIMO chan- nel sounding technique and measurement accuracy evaluation with transceiver impairments,”IEEE Trans. Instrum. Meas., vol. 61, no. 12, pp. 3185–3197, 2012
work page 2012
-
[30]
I. Calist and M. Kim, “Bridging FR1 to FR3: Frequency-continuous urban macro/microcellular channel parameterization anchored at 4.85 GHz,”arXiv preprint arXiv:2512.00707, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Masked-attention mask transformer for universal image segmentation,
B. Cheng, I. Misra, A. G. Schwing, A. Kirillov, and R. Girdhar, “Masked-attention mask transformer for universal image segmentation,” inProc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2022, pp. 1280–1289
work page 2022
-
[32]
L. Yang, B. Kang, Z. Huang, Z. Zhao, X. Xu, J. Feng, and H. Zhao, “Depth anything v2,” inProc. Int. Conf. Neural Inf. Process. Syst., 2024, pp. 21 875–21 911
work page 2024
-
[33]
The cityscapes dataset for semantic urban scene understanding,
M. Cordtset al., “The cityscapes dataset for semantic urban scene understanding,” inProc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2016
work page 2016
-
[34]
Imagenet large scale visual recognition chal- lenge,
O. Russakovskyet al., “Imagenet large scale visual recognition chal- lenge,”Int. J. Comput. Vis., vol. 115, pp. 211–252, 2015
work page 2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.