Recognition: 1 theorem link
· Lean TheoremOverconfidence and Calibration in Medical VQA: Empirical Findings and Hallucination-Aware Mitigation
Pith reviewed 2026-05-13 21:21 UTC · model grok-4.3
The pith
Post-hoc calibration such as Platt scaling reduces overconfidence in medical vision-language models more effectively than prompting, and hallucination signals further lift both calibration and AUROC.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
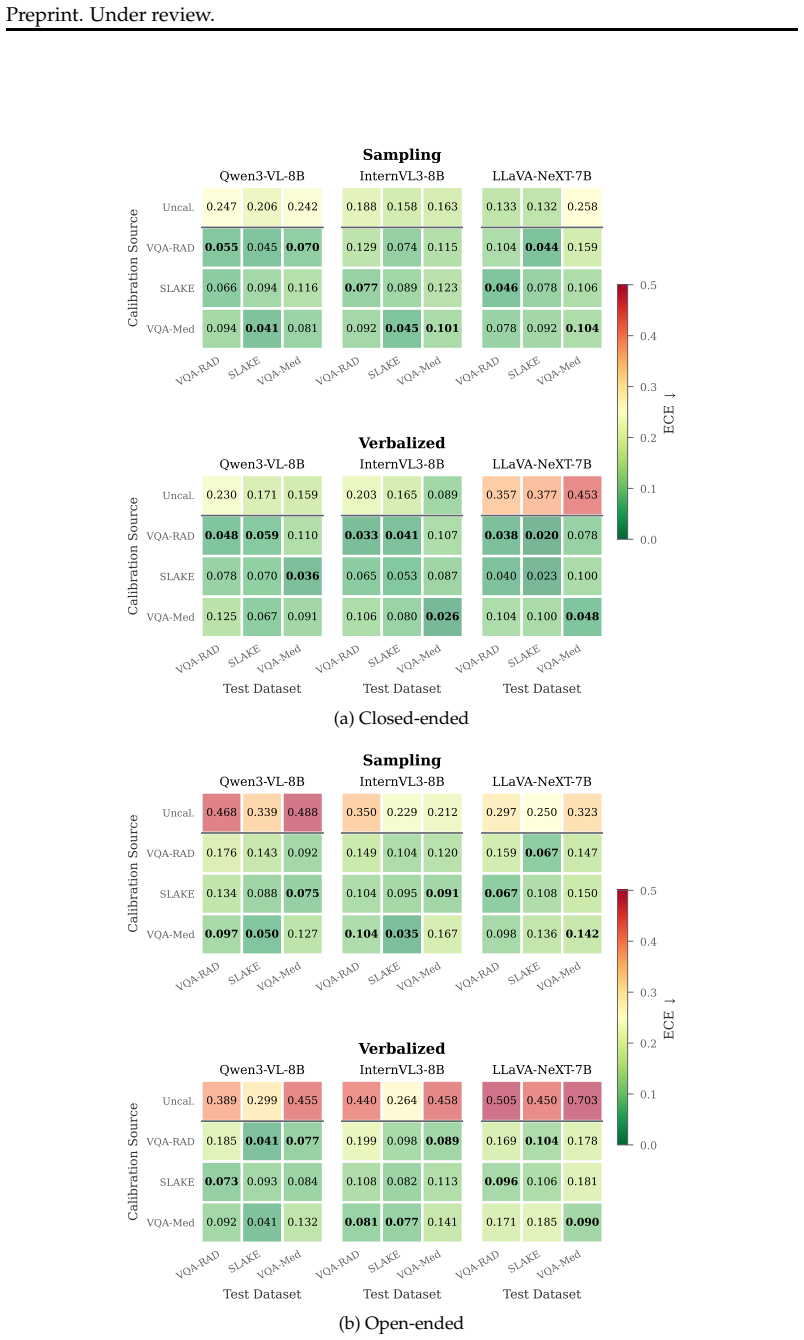
Overconfidence persists across model families, scales, and prompting strategies in medical VQA. Post-hoc calibration approaches such as Platt scaling reduce calibration error and outperform prompt-based methods, but their strict monotonicity prevents AUROC improvement. Hallucination-aware calibration that adds vision-grounded hallucination signals as complementary inputs improves both calibration and AUROC, with the biggest gains on open-ended questions.
What carries the argument
Hallucination-aware calibration (HAC), which refines confidence estimates by treating vision-grounded hallucination detection signals as additional inputs.
If this is right
- Post-hoc calibration becomes standard practice for medical VLM deployment instead of raw confidence estimates.
- Hallucination signals enable more reliable use of VLMs in medical VQA by lifting both calibration and discrimination.
- Prompting strategies alone, including chain-of-thought and verbalized confidence, leave overconfidence unresolved.
- Open-ended questions show the largest calibration and AUROC gains from hallucination-aware adjustments.
Where Pith is reading between the lines
- Deploying these models in hospitals would benefit from routine post-hoc recalibration on site-specific data before clinical use.
- The same hallucination signals could be tested as features in downstream tasks such as uncertainty-guided referral to human experts.
- Combining HAC with non-monotonic recalibration techniques might further raise AUROC while preserving calibration gains.
Load-bearing premise
The hallucination detection signals are reliable, vision-grounded, and supply independent value without introducing bias.
What would settle it
A new medical VQA benchmark where applying hallucination-aware calibration produces no reduction in calibration error and no AUROC increase compared with raw or Platt-scaled outputs.
Figures











read the original abstract
As vision-language models (VLMs) are increasingly deployed in clinical decision support, more than accuracy is required: knowing when to trust their predictions is equally critical. Yet, a comprehensive and systematic investigation into the overconfidence of these models remains notably scarce in the medical domain. We address this gap through a comprehensive empirical study of confidence calibration in VLMs, spanning three model families (Qwen3-VL, InternVL3, LLaVA-NeXT), three model scales (2B--38B), and multiple confidence estimation prompting strategies, across three medical visual question answering (VQA) benchmarks. Our study yields three key findings: First, overconfidence persists across model families and is not resolved by scaling or prompting, such as chain-of-thought and verbalized confidence variants. Second, simple post-hoc calibration approaches, such as Platt scaling, reduce calibration error and consistently outperform the prompt-based strategy. Third, due to their (strict) monotonicity, these post-hoc calibration methods are inherently limited in improving the discriminative quality of predictions, leaving AUROC at the same level. Motivated by these findings, we investigate hallucination-aware calibration (HAC), which incorporates vision-grounded hallucination detection signals as complementary inputs to refine confidence estimates. We find that leveraging these hallucination signals improves both calibration and AUROC, with the largest gains on open-ended questions. Overall, our findings suggest post-hoc calibration as standard practice for medical VLM deployment over raw confidence estimates, and highlight the practical usefulness of hallucination signals to enable more reliable use of VLMs in medical VQA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a comprehensive empirical study of overconfidence and calibration in vision-language models (VLMs) for medical visual question answering, evaluating three model families (Qwen3-VL, InternVL3, LLaVA-NeXT) across scales from 2B to 38B and multiple prompting strategies on three benchmarks. It reports that overconfidence persists despite scaling and prompting, that post-hoc methods such as Platt scaling reduce calibration error more effectively than prompting but cannot improve AUROC due to monotonicity, and that a proposed hallucination-aware calibration (HAC) method leveraging vision-grounded hallucination signals improves both calibration and AUROC, with largest gains on open-ended questions.
Significance. The broad empirical scope across models, scales, and benchmarks provides useful practical guidance for VLM deployment in clinical settings. If the HAC signals are shown to be computable at inference time without label leakage, the work could establish post-hoc calibration as standard practice and demonstrate the additive value of hallucination detection for improving both calibration and discriminative quality.
major comments (2)
- [HAC method description] HAC method description: the manuscript must explicitly detail the inference-time procedure for computing vision-grounded hallucination signals (e.g., cross-attention or consistency checks) and confirm that no test-benchmark answer labels were used for tuning or evaluation, as any such dependence would render the reported AUROC gains non-generalizable to deployment.
- [Experimental results section] Experimental results section: the claim that post-hoc methods 'consistently outperform' prompting requires reporting of exact calibration-error values, AUROC numbers, and statistical significance tests across all model-benchmark combinations; without these, the comparative findings remain difficult to assess.
minor comments (2)
- [Abstract] The abstract should specify the exact calibration metrics (e.g., ECE) and the three benchmarks by name.
- [Tables] Tables comparing methods should include standard deviations or confidence intervals over multiple runs to convey variability.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below and describe the revisions that will be incorporated into the next version of the manuscript.
read point-by-point responses
-
Referee: [HAC method description] HAC method description: the manuscript must explicitly detail the inference-time procedure for computing vision-grounded hallucination signals (e.g., cross-attention or consistency checks) and confirm that no test-benchmark answer labels were used for tuning or evaluation, as any such dependence would render the reported AUROC gains non-generalizable to deployment.
Authors: We appreciate the referee's emphasis on transparency regarding the HAC procedure. In the revised manuscript we will add a dedicated subsection (Section 4.3) that explicitly describes the inference-time computation: vision-grounded hallucination signals are extracted from (i) cross-attention maps between image patch tokens and generated text tokens and (ii) consistency scores obtained by running the model on two lightly perturbed versions of the same image (random crop + color jitter) and measuring token-level disagreement. All operations use only the model's internal activations and the input image at inference time; no ground-truth answers from any test benchmark are accessed during signal extraction, hyper-parameter selection, or evaluation. We will also include pseudocode and confirm that the reported AUROC improvements therefore remain valid for real-world deployment without label leakage. revision: yes
-
Referee: [Experimental results section] Experimental results section: the claim that post-hoc methods 'consistently outperform' prompting requires reporting of exact calibration-error values, AUROC numbers, and statistical significance tests across all model-benchmark combinations; without these, the comparative findings remain difficult to assess.
Authors: We agree that exact numerical reporting and statistical tests are necessary for rigorous comparison. In the revised manuscript we will replace the current summary statements with two new tables (Table 3 and Table 4) that list, for every model-scale-benchmark triplet: (a) exact Expected Calibration Error (ECE) and Brier score for raw, prompt-based, Platt-scaled, and HAC confidences; (b) AUROC values; and (c) p-values from paired Wilcoxon signed-rank tests comparing post-hoc methods against prompting. These tables will be accompanied by a short statistical-methods paragraph. The added numbers will directly support the claim that post-hoc calibration consistently outperforms prompting while also documenting the further gains from HAC. revision: yes
Circularity Check
No circularity: purely empirical application of standard post-hoc methods
full rationale
The paper reports experimental results on VLM confidence calibration across models and benchmarks. It applies established techniques such as Platt scaling (fitted on held-out data) and augments them with hallucination detection signals as additional inputs. No equations, derivations, or predictions are presented that reduce to self-definition, fitted inputs renamed as outputs, or load-bearing self-citations. The central claims rest on observed performance differences rather than any closed logical loop.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Medical VQA benchmarks are representative of clinical scenarios and standard metrics (ECE, AUROC) validly measure calibration and discrimination.
invented entities (1)
-
Hallucination-aware calibration (HAC)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
simple post-hoc calibration approaches, such as Platt scaling, reduce calibration error... HAC, which incorporates vision-grounded hallucination detection signals as complementary inputs to refine confidence estimates
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A versatile vision-language model for understanding, localization, text reading, and beyond.arXiv preprint arXiv:2308.12966,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
InWorking Notes of CLEF 2019, volume 2380 ofCEUR Workshop Proceedings, Lugano, Switzerland, September 9-12
work page 2019
-
[3]
Assessing gpt-4 multimodal performance in radiological image analysis
Dana Brin, Vera Sorin, Yiftach Barash, Eli Konen, Benjamin S Glicksberg, Girish N Nadkarni, and Eyal Klang. Assessing gpt-4 multimodal performance in radiological image analysis. European Radiology, 35(4):1959–1965,
work page 1959
-
[4]
Pierre Chambon, Jean-Benoit Delbrouck, Thomas Sounack, Shih-Cheng Huang, Zhihong Chen, Maya Varma, Steven QH Truong, Chu The Chuong, and Curtis P Langlotz. Chex- pert plus: Augmenting a large chest x-ray dataset with text radiology reports, patient demographics and additional image formats.arXiv preprint arXiv:2405.19538,
-
[5]
Prateek Chhikara. Mind the confidence gap: Overconfidence, calibration, and distractor effects in large language models.arXiv preprint arXiv:2502.11028,
-
[6]
Calibration of pre-trained transformers
Shrey Desai and Greg Durrett. Calibration of pre-trained transformers. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 295–302. Association for Computational Linguistics,
work page 2020
-
[7]
arXiv preprint arXiv:2508.15260 , year=
Yichao Fu, Xuewei Wang, Yuandong Tian, and Jiawei Zhao. Deep think with confidence. arXiv preprint arXiv:2508.15260,
-
[8]
Sushant Gautam, Michael A Riegler, and P ˚al Halvorsen. Hedge: Hallucination estima- tion via dense geometric entropy for vqa with vision-language models.arXiv preprint arXiv:2511.12693,
-
[9]
A survey of confidence estimation and calibration in large language models
Jiahui Geng, Fengyu Cai, Yuxia Wang, Heinz Koeppl, Preslav Nakov, and Iryna Gurevych. A survey of confidence estimation and calibration in large language models. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pp. 6577–6595,
work page 2024
-
[10]
Tobias Groot and Matias Valdenegro-Toro. Overconfidence is key: Verbalized uncertainty evaluation in large language and vision-language models. InProceedings of the 4th Workshop on Trustworthy Natural Language Processing (TrustNLP 2024), pp. 145–171,
work page 2024
-
[11]
DeBERTa: Decoding-enhanced BERT with Disentangled Attention
Pengcheng He, Xiaodong Liu, Jianfeng Gao, and Weizhu Chen. Deberta: Decoding- enhanced bert with disentangled attention.arXiv preprint arXiv:2006.03654,
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[12]
Calibrating long-form generations from large language models
Yukun Huang, Yixin Liu, Raghuveer Thirukovalluru, Arman Cohan, and Bhuwan Dhingra. Calibrating long-form generations from large language models. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen (eds.),Findings of the Association for Computational Linguistics: EMNLP 2024, pp. 13441–13460, Miami, Florida, USA, November
work page 2024
-
[13]
doi: 10.18653/v1/2024.findings-emnlp.785
Associ- ation for Computational Linguistics. doi: 10.18653/v1/2024.findings-emnlp.785. URL https://aclanthology.org/2024.findings-emnlp.785/. Jeremy Irvin, Pranav Rajpurkar, Michael Ko, Yifan Yu, Silviana Ciurea-Ilcus, Chris Chute, Henrik Marklund, Behzad Haghgoo, Robyn Ball, Katie Shpanskaya, et al. Chexpert: A large chest radiograph dataset with uncerta...
-
[14]
Language Models (Mostly) Know What They Know
Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran-Johnson, et al. Language models (mostly) know what they know.arXiv preprint arXiv:2207.05221,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
LLaVA-NeXT-Interleave: Tackling Multi-image, Video, and 3D in Large Multimodal Models
Feng Li, Renrui Zhang, Hao Zhang, Yuanhan Zhang, Bo Li, Wei Li, Zejun Ma, and Chunyuan Li. Llava-next-interleave: Tackling multi-image, video, and 3d in large multimodal models. arXiv preprint arXiv:2407.07895,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
12 Preprint. Under review. Zhen Lin, Shubhendu Trivedi, and Jimeng Sun. Generating with confidence: Uncertainty quantification for black-box large language models.arXiv preprint arXiv:2305.19187,
-
[17]
Xiaoou Liu, Tiejin Chen, Longchao Da, Chacha Chen, Zhen Lin, and Hua Wei
URL https://llava-vl.github.io/blog/2024-01-30-llava-next/. Xiaoou Liu, Tiejin Chen, Longchao Da, Chacha Chen, Zhen Lin, and Hua Wei. Uncertainty quantification and confidence calibration in large language models: A survey. InProceed- ings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V . 2, pp. 6107–6117,
work page 2024
-
[18]
Shiyu Ni, Keping Bi, Jiafeng Guo, and Xueqi Cheng. When do llms need retrieval augmen- tation? mitigating llms’ overconfidence helps retrieval augmentation. InFindings of the Association for Computational Linguistics: ACL 2024, pp. 11375–11388,
work page 2024
-
[19]
Young-Jin Park, Kristjan Greenewald, Kaveh Alim, Hao Wang, and Navid Azizan. Know what you don’t know: Uncertainty calibration of process reward models.arXiv preprint arXiv:2506.09338,
-
[20]
Thomas Savage, John Wang, Robert Gallo, Abdessalem Boukil, Vishwesh Patel, Seyed Amir Ahmad Safavi-Naini, Ali Soroush, and Jonathan H Chen. Large language model uncer- tainty measurement and calibration for medical diagnosis and treatment.medRxiv, pp. 2024–06,
work page 2024
-
[21]
Aviv Slobodkin, Omer Goldman, Avi Caciularu, Ido Dagan, and Shauli Ravfogel
Maohao Shen, Subhro Das, Kristjan Greenewald, Prasanna Sattigeri, Gregory Wornell, and Soumya Ghosh. Thermometer: Towards universal calibration for large language models. arXiv preprint arXiv:2403.08819,
-
[22]
URLhttps://arxiv.org/abs/2505.09388. 13 Preprint. Under review. Alberto Testoni and Iacer Calixto. Mind the gap: Benchmarking LLM uncertainty and calibration with specialty-aware clinical QA and reasoning-based behavioural features. In Vera Demberg, Kentaro Inui, and Llu´ıs Marquez (eds.),Proceedings of the 19th Conference of the European Chapter of the A...
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Association for Computational Linguistics. ISBN 979-8-89176-380-7. doi: 10.18653/v1/2026.eacl-long.106. URL https: //aclanthology.org/2026.eacl-long.106/. Katherine Tian, Eric Mitchell, Allan Zhou, Archit Sharma, Rafael Rafailov, Huaxiu Yao, Chelsea Finn, and Christopher D Manning. Just ask for calibration: Strategies for eliciting calibrated confidence s...
-
[24]
Towards generalist biomedical ai.Nejm Ai, 1(3):AIoa2300138, 2024a
Tao Tu, Shekoofeh Azizi, Danny Driess, Mike Schaekermann, Mohamed Amin, Pi-Chuan Chang, Andrew Carroll, Charles Lau, Ryutaro Tanno, Ira Ktena, et al. Towards generalist biomedical ai.Nejm Ai, 1(3):AIoa2300138, 2024a. Weijie Tu, Weijian Deng, Dylan Campbell, Stephen Gould, and Tom Gedeon. An empirical study into what matters for calibrating vision-language...
work page 2024
-
[25]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models.arXiv preprint arXiv:2203.11171,
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Weihao Xuan, Qingcheng Zeng, Heli Qi, Junjue Wang, and Naoto Yokoya. Seeing is believing, but how much? a comprehensive analysis of verbalized calibration in vision- language models. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng (eds.),Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processin...
work page 2025
-
[27]
Association for Computational Linguistics. ISBN 979-8-89176-332-6. doi: 10.18653/v1/2025.emnlp-main
-
[28]
Yasin Abbasi Yadkori, Ilja Kuzborskij, Andr´as Gy¨orgy, and Csaba Szepesv´ari
URLhttps://aclanthology.org/2025.emnlp-main.74/. Yasin Abbasi Yadkori, Ilja Kuzborskij, Andr´as Gy¨orgy, and Csaba Szepesv´ari. To believe or not to believe your llm.arXiv preprint arXiv:2406.02543,
-
[29]
Obtaining calibrated probability estimates from decision trees and naive bayesian classifiers
Bianca Zadrozny and Charles Elkan. Obtaining calibrated probability estimates from decision trees and naive bayesian classifiers. InIcml, volume 1, pp. 2001,
work page 2001
-
[30]
Serena Zhang, Sraavya Sambara, Oishi Banerjee, Julian Acosta, L John Fahrner, and Pranav Rajpurkar. Radflag: A black-box hallucination detection method for medical vision language models.arXiv preprint arXiv:2411.00299, 2024a. Sheng Zhang, Yanbo Xu, Naoto Usuyama, Hanwen Xu, Jaspreet Bagga, Robert Tinn, Sam Preston, Rajesh Rao, Mu Wei, Naveen Valluri, et ...
-
[31]
15 Preprint. Under review. A Further Related Work: Calibration in Deep Learning and Generative Models. Modern deep neural networks are often observed to be miscalibrated: while achieving high accuracy, they tend to produce overconfident predictions. Guo et al. (2017) provided the characterization of this phenomenon and introducedtemperature scalingas a po...
work page 2017
-
[32]
Which organ is abnormal, heart or lung?
Note that the SLAKE dataset provides its own CLOSED/OPEN labels, where CLOSED includes not only yes/no questions but alsoclosed-choicequestions such as “Which organ is abnormal, heart or lung?” Similarly, VQA-Med-2019 contains comparable closed-choice questions (e.g., “Is this image modality T1, T2, or FLAIR?”) without explicitly providing such labels. Me...
work page 2019
-
[33]
to perform semantic clustering, its NLI-based training on general-domain corpora may not generalize well to domain-specific equivalences; we instead use Qwen/Qwen3-4B-Instruct-2507, which demonstrates competitive performance on medical benchmarks (Team, 2025). Verbalized confidence.We evaluate six variants of verbalized confidence prompting strategy, each...
work page 2025
-
[34]
Term Probability Almost certain 0.95 Highly likely 0.90 Very good chance 0.85 Probable 0.75 Likely 0.70 Better than even 0.60 About even 0.50 Unlikely 0.30 Improbable 0.20 Very good chance not 0.15 Highly unlikely 0.10 Almost certainly not 0.05 Table 6: Mapping from linguistic confidence terms to numerical probabilities. C.1.3 LLM-as-a-Judge Prompt We use...
work page 2025
-
[35]
E.1 Calibration across Model Families and Varying Scales Tables 8–10 present the full results. We consistently observed systematic overconfidence across model families and datasets; scaling did not mitigate the overconfidence or miscali- bration. While accuracy generally increased with larger models, reliability metrics such as ECE, ACE, and AUROC did not...
-
[36]
For open-ended ques- tions, we reconfirmed that HAC consistently improved AUROC
F.1 Predictive Discrimination Gains Table 12 extends Table 2 to per-dataset and per-model breakdowns. For open-ended ques- tions, we reconfirmed that HAC consistently improved AUROC. For closed-ended questions, performance varied across datasets, with the largest gain on VQA-Med. Exploring a more robust HAC formulation that generalizes across question typ...
work page 1900
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.