Recognition: no theorem link
ExploreVLA: Dense World Modeling and Exploration for End-to-End Autonomous Driving
Pith reviewed 2026-05-13 20:49 UTC · model grok-4.3
The pith
Augmenting VLA driving models with future image prediction supplies both dense supervision and an uncertainty signal for safe policy exploration.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
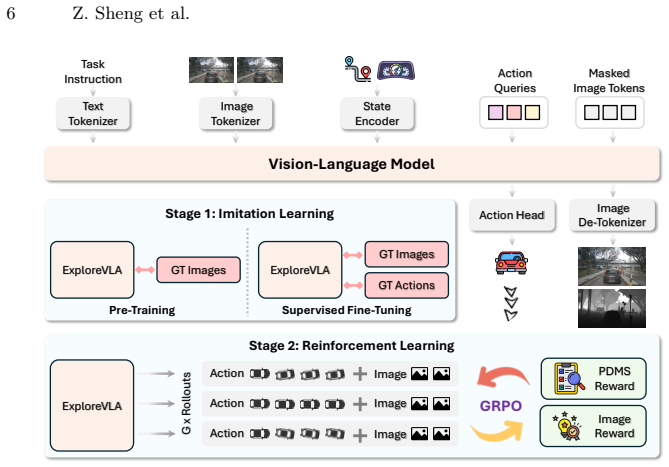
The central claim is that a unified understanding-and-generation framework, where the VLA model augments trajectory prediction with future RGB and depth image generation, creates dense world modeling objectives that both enrich representations for planning and generate an uncertainty-based intrinsic reward for exploration, which when safety-gated enables Group Relative Policy Optimization to produce more robust driving policies.
What carries the argument
The dense world model for generating future RGB and depth images, whose prediction uncertainty measures a trajectory's novelty relative to the training distribution to supply the intrinsic reward.
Load-bearing premise
The world model's image prediction uncertainty reliably indicates both novelty and safety, allowing the safety-gated reward to produce valuable exploration without unsafe behaviors or training instability.
What would settle it
If removing the uncertainty-based exploration reward causes no drop in performance on out-of-distribution test scenarios compared to pure imitation learning, the claim that uncertainty supplies useful exploration signals would be falsified.
Figures





read the original abstract
End-to-end autonomous driving models based on Vision-Language-Action (VLA) architectures have shown promising results by learning driving policies through behavior cloning on expert demonstrations. However, imitation learning inherently limits the model to replicating observed behaviors without exploring diverse driving strategies, leaving it brittle in novel or out-of-distribution scenarios. Reinforcement learning (RL) offers a natural remedy by enabling policy exploration beyond the expert distribution. Yet VLA models, typically trained on offline datasets, lack directly observable state transitions, necessitating a learned world model to anticipate action consequences. In this work, we propose a unified understanding-and-generation framework that leverages world modeling to simultaneously enable meaningful exploration and provide dense supervision. Specifically, we augment trajectory prediction with future RGB and depth image generation as dense world modeling objectives, requiring the model to learn fine-grained visual and geometric representations that substantially enrich the planning backbone. Beyond serving as a supervisory signal, the world model further acts as a source of intrinsic reward for policy exploration: its image prediction uncertainty naturally measures a trajectory's novelty relative to the training distribution, where high uncertainty indicates out-of-distribution scenarios that, if safe, represent valuable learning opportunities. We incorporate this exploration signal into a safety-gated reward and optimize the policy via Group Relative Policy Optimization (GRPO). Experiments on the NAVSIM and nuScenes benchmarks demonstrate the effectiveness of our approach, achieving a state-of-the-art PDMS score of 93.7 and an EPDMS of 88.8 on NAVSIM. The code and demo will be publicly available at https://zihaosheng.github.io/ExploreVLA/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ExploreVLA, a unified VLA framework for end-to-end autonomous driving that augments trajectory prediction with future RGB and depth image generation as dense world-modeling objectives. These objectives supply both enriched supervision for the planning backbone and an intrinsic reward signal based on the model's own image-prediction uncertainty, which is combined with a safety gate and optimized via Group Relative Policy Optimization (GRPO). Experiments are reported on NAVSIM and nuScenes, with state-of-the-art PDMS of 93.7 and EPDMS of 88.8 claimed on NAVSIM.
Significance. If the uncertainty-based exploration mechanism can be shown to identify safe novelty without reinforcing unsafe behaviors, the work would meaningfully advance RL-augmented VLA driving by addressing the distribution-shift brittleness of pure imitation learning. The dual use of dense prediction for both representation learning and intrinsic reward is a conceptually clean contribution.
major comments (2)
- [Abstract] Abstract: The central claim that image-prediction uncertainty serves as a reliable, safety-gated intrinsic reward for valuable exploration is load-bearing yet unsupported; no correlation analysis between uncertainty and out-of-distribution but drivable states, no ablation of the safety gate, and no failure-case inspection are provided, leaving open the possibility that high uncertainty simply flags imminent collisions or rule violations.
- [Abstract] Abstract / Experiments: The reported SOTA PDMS 93.7 and EPDMS 88.8 scores are presented without ablations, baseline comparisons, error bars, or details on how the safety gate was implemented, making it impossible to determine whether the gains derive from the proposed exploration signal or from post-hoc tuning.
minor comments (1)
- [Abstract] The manuscript states that code and a demo will be released but supplies insufficient methodological detail (e.g., exact form of the uncertainty reward, GRPO hyperparameters, or safety-gate threshold) for independent verification in the current version.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that the central claims require stronger empirical support and have revised the manuscript to include the requested analyses, ablations, and implementation details.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that image-prediction uncertainty serves as a reliable, safety-gated intrinsic reward for valuable exploration is load-bearing yet unsupported; no correlation analysis between uncertainty and out-of-distribution but drivable states, no ablation of the safety gate, and no failure-case inspection are provided, leaving open the possibility that high uncertainty simply flags imminent collisions or rule violations.
Authors: We acknowledge the need for direct validation of the uncertainty signal. In the revised version we add a correlation analysis between image-prediction uncertainty and out-of-distribution yet drivable states, an ablation that removes the safety gate, and qualitative inspection of failure cases demonstrating that high-uncertainty trajectories correspond to safe novel scenarios rather than imminent collisions. revision: yes
-
Referee: [Abstract] Abstract / Experiments: The reported SOTA PDMS 93.7 and EPDMS 88.8 scores are presented without ablations, baseline comparisons, error bars, or details on how the safety gate was implemented, making it impossible to determine whether the gains derive from the proposed exploration signal or from post-hoc tuning.
Authors: We agree that the experimental presentation must be strengthened. The revised manuscript includes component-wise ablations (world-modeling loss, uncertainty reward, safety gate), additional baseline comparisons, error bars from multiple random seeds, and a precise description of the safety-gate logic and thresholds to isolate the contribution of the exploration signal. revision: yes
Circularity Check
Derivation chain is self-contained with no circular reductions
full rationale
The paper trains a unified VLA world model on dense RGB/depth prediction objectives to enrich the planning backbone, then deploys the same model's image-prediction uncertainty as an intrinsic reward inside a safety-gated GRPO loop. This construction follows the standard curiosity-driven exploration pattern and does not equate the final PDMS/EPDMS benchmark scores to the training reward by definition; the benchmarks are computed on independent held-out trajectories after policy optimization. No load-bearing self-citation, uniqueness theorem, or fitted-input-renamed-as-prediction step appears in the derivation. The central empirical claims therefore rest on external benchmark evaluation rather than internal definitional closure.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Caesar, H., Bankiti, V., Lang, A.H., Vora, S., Liong, V.E., Xu, Q., Krishnan, A., Pan, Y., Baldan, G., Beijbom, O.: nuscenes: A multimodal dataset for autonomous driving. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 11621–11631 (2020)
work page 2020
-
[2]
Pseudo-simulation for autonomous driving.arXiv preprint arXiv:2506.04218,
Cao, W., Hallgarten, M., Li, T., Dauner, D., Gu, X., Wang, C., Miron, Y., Aiello, M., Li, H., Gilitschenski, I., et al.: Pseudo-simulation for autonomous driving. arXiv preprint arXiv:2506.04218 (2025)
-
[3]
Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling
Chen, X., Wu, Z., Liu, X., Pan, Z., Liu, W., Xie, Z., Yu, X., Ruan, C.: Janus-pro: Unified multimodal understanding and generation with data and model scaling. arXiv preprint arXiv:2501.17811 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Chen, Y., Wang, Y., Zhang, Z.: Drivinggpt: Unifying driving world modeling and planning with multi-modal autoregressive transformers. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 26890–26900 (2025)
work page 2025
-
[5]
IEEE Transactions on Pattern Analysis and Machine Intelligence45(11), 12878–12895 (2022)
Chitta, K., Prakash, A., Jaeger, B., Yu, Z., Renz, K., Geiger, A.: Transfuser: Imitation with transformer-based sensor fusion for autonomous driving. IEEE Transactions on Pattern Analysis and Machine Intelligence45(11), 12878–12895 (2022)
work page 2022
-
[6]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Codevilla, F., Santana, E., López, A.M., Gaidon, A.: Exploring the limitations of behavior cloning for autonomous driving. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 9329–9338 (2019)
work page 2019
-
[7]
Advances in Neural Information Processing Systems37, 28706–28719 (2024)
Dauner, D., Hallgarten, M., Li, T., Weng, X., Huang, Z., Yang, Z., Li, H., Gilitschen- ski, I., Ivanovic, B., Pavone, M., et al.: Navsim: Data-driven non-reactive au- tonomous vehicle simulation and benchmarking. Advances in Neural Information Processing Systems37, 28706–28719 (2024)
work page 2024
-
[8]
ACM Computing Surveys58(3), 1–38 (2025)
Ding, J., Zhang, Y., Shang, Y., Zhang, Y., Zong, Z., Feng, J., Yuan, Y., Su, H., Li, N., Sukiennik, N., et al.: Understanding world or predicting future? a comprehensive survey of world models. ACM Computing Surveys58(3), 1–38 (2025)
work page 2025
-
[9]
IEEE Robotics and Automation Letters11(1), 226–233 (2025)
Feng, R., Xi, N., Chu, D., Wang, R., Deng, Z., Wang, A., Lu, L., Wang, J., Huang, Y.: Artemis: Autoregressive end-to-end trajectory planning with mixture of experts for autonomous driving. IEEE Robotics and Automation Letters11(1), 226–233 (2025)
work page 2025
-
[10]
A survey of world models for autonomous driving.arXiv preprint arXiv:2501.11260, 2025
Feng, T., Wang, W., Yang, Y.: A survey of world models for autonomous driving. arXiv preprint arXiv:2501.11260 (2025)
-
[11]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Fu, H., Zhang, D., Zhao, Z., Cui, J., Liang, D., Zhang, C., Zhang, D., Xie, H., Wang, B., Bai, X.: Orion: A holistic end-to-end autonomous driving framework by vision-language instructed action generation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 24823–24834 (2025)
work page 2025
-
[12]
Advances in Neural Information Processing Systems37, 91560–91596 (2024)
Gao, S., Yang, J., Chen, L., Chitta, K., Qiu, Y., Geiger, A., Zhang, J., Li, H.: Vista: A generalizable driving world model with high fidelity and versatile controllability. Advances in Neural Information Processing Systems37, 91560–91596 (2024)
work page 2024
-
[13]
IEEE Transactions on Intelligent Vehicles (2024)
Guan, Y., Liao, H., Li, Z., Hu, J., Yuan, R., Zhang, G., Xu, C.: World models for autonomous driving: An initial survey. IEEE Transactions on Intelligent Vehicles (2024)
work page 2024
-
[14]
In: 2025 IEEE International Conference on Robotics and Automation (ICRA)
Guo, Y., Zhang, J., Chen, X., Ji, X., Wang, Y.J., Hu, Y., Chen, J.: Improving vision-language-action model with online reinforcement learning. In: 2025 IEEE International Conference on Robotics and Automation (ICRA). pp. 15665–15672. IEEE (2025) 16 Z. Sheng et al
work page 2025
-
[15]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Hassan, M., Stapf, S., Rahimi, A., Rezende, P., Haghighi, Y., Brüggemann, D., Katircioglu, I., Zhang, L., Chen, X., Saha, S., et al.: Gem: A generalizable ego-vision multimodal world model for fine-grained ego-motion, object dynamics, and scene composition control. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. ...
work page 2025
-
[16]
GAIA-1: A Generative World Model for Autonomous Driving
Hu, A., Russell, L., Yeo, H., Murez, Z., Fedoseev, G., Kendall, A., Shotton, J., Corrado, G.: Gaia-1: A generative world model for autonomous driving. arXiv preprint arXiv:2309.17080 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[17]
Hu, E.J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W., et al.: Lora: Low-rank adaptation of large language models. Iclr1(2), 3 (2022)
work page 2022
-
[18]
In: European Conference on Computer Vision
Hu, S., Chen, L., Wu, P., Li, H., Yan, J., Tao, D.: St-p3: End-to-end vision-based autonomous driving via spatial-temporal feature learning. In: European Conference on Computer Vision. pp. 533–549. Springer (2022)
work page 2022
-
[19]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Hu, Y., Yang, J., Chen, L., Li, K., Sima, C., Zhu, X., Chai, S., Du, S., Lin, T., Wang, W., et al.: Planning-oriented autonomous driving. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 17853–17862 (2023)
work page 2023
-
[20]
EMMA: End-to-End Multimodal Model for Autonomous Driving
Hwang, J.J., Xu, R., Lin, H., Hung, W.C., Ji, J., Choi, K., Huang, D., He, T., Cov- ington, P., Sapp, B., et al.: Emma: End-to-end multimodal model for autonomous driving. arXiv preprint arXiv:2410.23262 (2024)
work page internal anchor Pith review arXiv 2024
-
[21]
Diffvla: Vision-language guided diffusion planning for autonomous driving,
Jiang, A., Gao, Y., Sun, Z., Wang, Y., Wang, J., Chai, J., Cao, Q., Heng, Y., Jiang, H., Dong, Y., et al.: Diffvla: Vision-language guided diffusion planning for autonomous driving. arXiv preprint arXiv:2505.19381 (2025)
-
[22]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Jiang, B., Chen, S., Xu, Q., Liao, B., Chen, J., Zhou, H., Zhang, Q., Liu, W., Huang, C., Wang, X.: Vad: Vectorized scene representation for efficient autonomous driving. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 8340–8350 (2023)
work page 2023
-
[23]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Jiang, S., Huang, Z., Qian, K., Luo, Z., Zhu, T., Zhong, Y., Tang, Y., Kong, M., Wang, Y., Jiao, S., et al.: A survey on vision-language-action models for autonomous driving. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 4524–4536 (2025)
work page 2025
-
[24]
In: Proceedings of the computer vision and pattern recognition conference
Li, B., Guo, J., Liu, H., Zou, Y., Ding, Y., Chen, X., Zhu, H., Tan, F., Zhang, C., Wang, T., et al.: Uniscene: Unified occupancy-centric driving scene generation. In: Proceedings of the computer vision and pattern recognition conference. pp. 11971–11981 (2025)
work page 2025
-
[25]
arXiv preprint arXiv:2510.18313 (2025)
Li, B., Ma, Z., Du, D., Peng, B., Liang, Z., Liu, Z., Ma, C., Jin, Y., Zhao, H., Zeng, W., et al.: Omninwm: Omniscient driving navigation world models. arXiv preprint arXiv:2510.18313 (2025)
-
[26]
Hydra-mdp++: Advancing end-to-end driving via expert- guided hydra-distillation,
Li, K., Li, Z., Lan, S., Xie, Y., Zhang, Z., Liu, J., Wu, Z., Yu, Z., Alvarez, J.M.: Hydra-mdp++: Advancing end-to-end driving via expert-guided hydra-distillation. arXiv preprint arXiv:2503.12820 (2025)
-
[27]
Li, Y., Shang, S., Liu, W., Zhan, B., Wang, H., Wang, Y., Chen, Y., Wang, X., An, Y., Tang, C., et al.: Drivevla-w0: World models amplify data scaling law in autonomous driving. arXiv preprint arXiv:2510.12796 (2025)
-
[28]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Li, Y., Wang, Y., Liu, Y., He, J., Fan, L., Zhang, Z.: End-to-end driving with online trajectory evaluation via bev world model. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 27137–27146 (2025)
work page 2025
-
[29]
ReCogDrive: A Reinforced Cognitive Framework for End-to-End Autonomous Driving
Li, Y., Xiong, K., Guo, X., Li, F., Yan, S., Xu, G., Zhou, L., Chen, L., Sun, H., Wang, B., et al.: Recogdrive: A reinforced cognitive framework for end-to-end autonomous driving. arXiv preprint arXiv:2506.08052 (2025)
work page internal anchor Pith review arXiv 2025
-
[30]
Textbooks Are All You Need II: phi-1.5 technical report
Li, Y., Bubeck, S., Eldan, R., Del Giorno, A., Gunasekar, S., Lee, Y.T.: Textbooks are all you need ii: phi-1.5 technical report. arXiv preprint arXiv:2309.05463 (2023) ExploreVLA 17
work page internal anchor Pith review arXiv 2023
-
[31]
Hydra-MDP: End-to-end Multimodal Planning with Multi-target Hydra-Distillation
Li, Z., Li, K., Wang, S., Lan, S., Yu, Z., Ji, Y., Li, Z., Zhu, Z., Kautz, J., Wu, Z., et al.: Hydra-mdp: End-to-end multimodal planning with multi-target hydra-distillation. arXiv preprint arXiv:2406.06978 (2024)
work page internal anchor Pith review arXiv 2024
-
[32]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Liao, B., Chen, S., Yin, H., Jiang, B., Wang, C., Yan, S., Zhang, X., Li, X., Zhang, Y., Zhang, Q., et al.: Diffusiondrive: Truncated diffusion model for end- to-end autonomous driving. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 12037–12047 (2025)
work page 2025
-
[33]
arXiv preprint arXiv:2308.07234 (2023)
Min, C., Zhao, D., Xiao, L., Nie, Y., Dai, B.: Uniworld: Autonomous driving pre-training via world models. arXiv preprint arXiv:2308.07234 (2023)
-
[34]
Ross, S., Gordon, G., Bagnell, D.: A reduction of imitation learning and structured prediction to no-regret online learning. In: Proceedings of the Fourteenth Inter- national Conference on Artificial Intelligence and Statistics. vol. 15, pp. 627–635. PMLR (2011)
work page 2011
-
[35]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y., Wu, Y., et al.: Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
Sima, C., Chitta, K., Yu, Z., Lan, S., Luo, P., Geiger, A., Li, H., Alvarez, J.M.: Centaur: Robust end-to-end autonomous driving with test-time training. arXiv preprint arXiv:2503.11650 (2025)
-
[37]
In: European conference on computer vision
Wang, X., Zhu, Z., Huang, G., Chen, X., Zhu, J., Lu, J.: Drivedreamer: Towards real-world-drive world models for autonomous driving. In: European conference on computer vision. pp. 55–72. Springer (2024)
work page 2024
- [38]
-
[39]
Wang, Y., Luo, W., Bai, J., Cao, Y., Che, T., Chen, K., Chen, Y., Diamond, J., Ding, Y., Ding, W., et al.: Alpamayo-r1: Bridging reasoning and action prediction for generalizable autonomous driving in the long tail. arXiv preprint arXiv:2511.00088 (2025)
-
[40]
Show-o: One Single Transformer to Unify Multimodal Understanding and Generation
Xie, J., Mao, W., Bai, Z., Zhang, D.J., Wang, W., Lin, K.Q., Gu, Y., Chen, Z., Yang, Z., Shou, M.Z.: Show-o: One single transformer to unify multimodal understanding and generation. arXiv preprint arXiv:2408.12528 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[41]
In: Proceedings of the Winter Conference on Applications of Computer Vision
Xing, S., Qian, C., Wang, Y., Hua, H., Tian, K., Zhou, Y., Tu, Z.: Openemma: Open-source multimodal model for end-to-end autonomous driving. In: Proceedings of the Winter Conference on Applications of Computer Vision. pp. 1001–1009 (2025)
work page 2025
-
[42]
arXiv preprint arXiv:2601.04453 (2026)
Xiong, Z., Ye, X., Yaman, B., Cheng, S., Lu, Y., Luo, J., Jacobs, N., Ren, L.: Unidrive-wm: Unified understanding, planning and generation world model for autonomous driving. arXiv preprint arXiv:2601.04453 (2026)
-
[43]
IEEE Robotics and Automation Letters9(10), 8186–8193 (2024)
Xu, Z., Zhang, Y., Xie, E., Zhao, Z., Guo, Y., Wong, K.Y.K., Li, Z., Zhao, H.: Drivegpt4: Interpretable end-to-end autonomous driving via large language model. IEEE Robotics and Automation Letters9(10), 8186–8193 (2024)
work page 2024
-
[44]
arXiv preprint arXiv:2511.20325 (2025) 4 18 X
Yan, T., Tang, T., Gui, X., Li, Y., Zhesng, J., Huang, W., Kong, L., Han, W., Zhou, X., Zhang, X., et al.: Ad-r1: Closed-loop reinforcement learning for end-to-end autonomous driving with impartial world models. arXiv preprint arXiv:2511.20325 (2025)
-
[45]
ReSim: Reliable World Simulation for Autonomous Driving
Yang, J., Chitta, K., Gao, S., Chen, L., Shao, Y., Jia, X., Li, H., Geiger, A., Yue, X., Chen, L.: Resim: Reliable world simulation for autonomous driving. arXiv preprint arXiv:2506.09981 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
Yang, J., Gao, S., Qiu, Y., Chen, L., Li, T., Dai, B., Chitta, K., Wu, P., Zeng, J., Luo, P., et al.: Generalized predictive model for autonomous driving. In: Proceedings 18 Z. Sheng et al. of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 14662–14672 (2024)
work page 2024
-
[47]
arXiv preprint arXiv:2506.06659 (2025)
Yao, W., Li, Z., Lan, S., Wang, Z., Sun, X., Alvarez, J.M., Wu, Z.: Drivesuprim: Towards precise trajectory selection for end-to-end planning. arXiv preprint arXiv:2506.06659 (2025)
-
[48]
In: Proceed- ings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Yin, W., Zhang, C., Chen, H., Cai, Z., Yu, G., Wang, K., Chen, X., Shen, C.: Metric3d: Towards zero-shot metric 3d prediction from a single image. In: Proceed- ings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 9043–9053 (2023)
work page 2023
-
[49]
Language Model Beats Diffusion -- Tokenizer is Key to Visual Generation
Yu, L., Lezama, J., Gundavarapu, N.B., Versari, L., Sohn, K., Minnen, D., Cheng, Y., Birodkar, V., Gupta, A., Gu, X., et al.: Language model beats diffusion–tokenizer is key to visual generation. arXiv preprint arXiv:2310.05737 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[50]
arXiv preprint arXiv:2408.03601 (2024) 13
Yuan, C., Zhang, Z., Sun, J., Sun, S., Huang, Z., Lee, C.D.W., Li, D., Han, Y., Wong, A., Tee, K.P., et al.: Drama: An efficient end-to-end motion planner for autonomous driving with mamba. arXiv preprint arXiv:2408.03601 (2024)
-
[51]
arXiv preprint arXiv:2402.10828 (2024)
Yuan, J., Sun, S., Omeiza, D., Zhao, B., Newman, P., Kunze, L., Gadd, M.: Rag- driver: Generalisable driving explanations with retrieval-augmented in-context learning in multi-modal large language model. arXiv preprint arXiv:2402.10828 (2024)
-
[52]
Advances in Neural Information Processing Systems (2025)
Zeng, S., Chang, X., Xie, M., Liu, X., Bai, Y., Pan, Z., Xu, M., Wei, X., Guo, N.: Futuresightdrive: Thinking visually with spatio-temporal cot for autonomous driving. Advances in Neural Information Processing Systems (2025)
work page 2025
-
[53]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Zhang, K., Tang, Z., Hu, X., Pan, X., Guo, X., Liu, Y., Huang, J., Yuan, L., Zhang, Q., Long, X.X., et al.: Epona: Autoregressive diffusion world model for autonomous driving. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 27220–27230 (2025)
work page 2025
-
[54]
In: Advances in Neural Information Processing Systems (2025)
Zhao, Z., Fu, T., Wang, Y., Wang, L., Lu, H.: From forecasting to planning: Policy world model for collaborative state-action prediction. In: Advances in Neural Information Processing Systems (2025)
work page 2025
-
[55]
In: European conference on computer vision
Zheng, W., Chen, W., Huang, Y., Zhang, B., Duan, Y., Lu, J.: Occworld: Learning a 3d occupancy world model for autonomous driving. In: European conference on computer vision. pp. 55–72. Springer (2024)
work page 2024
-
[56]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Zheng, Y., Yang, P., Xing, Z., Zhang, Q., Zheng, Y., Gao, Y., Li, P., Zhang, T., Xia, Z., Jia, P., et al.: World4drive: End-to-end autonomous driving via intention- aware physical latent world model. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 28632–28642 (2025)
work page 2025
-
[57]
arXiv preprint arXiv:2503.23463 (2025) 4
Zhou, X., Han, X., Yang, F., Ma, Y., Knoll, A.C.: Opendrivevla: Towards end-to- end autonomous driving with large vision language action model. arXiv preprint arXiv:2503.23463 (2025)
-
[58]
Advances in Neural Information Processing Systems (2025)
Zhou, Z., Cai, T., Zhao, S.Z., Zhang, Y., Huang, Z., Zhou, B., Ma, J.: Autovla: A vision-language-action model for end-to-end autonomous driving with adaptive reasoning and reinforcement fine-tuning. Advances in Neural Information Processing Systems (2025)
work page 2025
-
[59]
Zou, J., Chen, S., Liao, B., Zheng, Z., Song, Y., Zhang, L., Zhang, Q., Liu, W., Wang, X.: Diffusiondrivev2: Reinforcement learning-constrained truncated diffusion modeling in end-to-end autonomous driving. arXiv preprint arXiv:2512.07745 (2025) ExploreVLA 19 A More Implementation Details Our model is built upon Show-o [40], which employs Phi-1.5 [30] as ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.