Recognition: 2 theorem links
· Lean TheoremRubrics to Tokens: Bridging Response-level Rubrics and Token-level Rewards in Instruction Following Tasks
Pith reviewed 2026-05-13 20:20 UTC · model grok-4.3
The pith
RTT turns response-level rubric scores into token-level rewards to reduce sparsity in LLM instruction training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
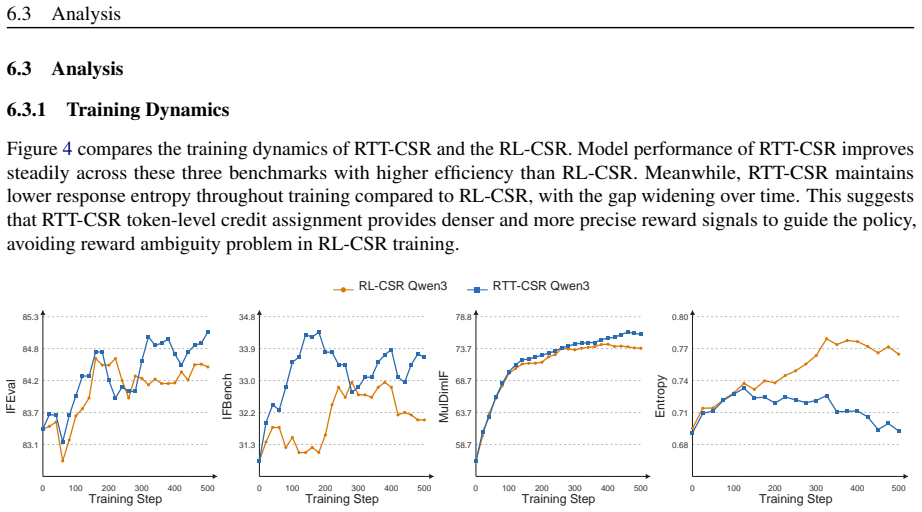
RTT bridges coarse response-level rubric scores and fine-grained token-level credit assignment by training a discriminator to identify responsible tokens for each constraint and optimizing via RTT-GRPO, which unifies response and token advantages while applying Intra-sample Token Group Normalization to manage the shift to multi-dimensional rewards.
What carries the argument
Token-Level Relevance Discriminator that predicts which tokens satisfy specific rubric constraints, integrated into RTT-GRPO optimization with Intra-sample Token Group Normalization for multi-dimensional rewards.
If this is right
- RTT reduces reward sparsity by providing token-level advantages instead of sparse response-level signals.
- The method improves both instruction-following accuracy and rubric-level constraint satisfaction across models.
- Intra-sample Token Group Normalization enables stable training when rewards move from one dimension to three.
- RTT-GRPO unifies response-level and token-level signals in a single optimization step.
Where Pith is reading between the lines
- The approach could lower annotation costs by deriving token labels automatically from existing response rubrics.
- Similar token-level bridging might apply to other sparse-reward settings such as multi-step reasoning or tool use.
- Testing whether the discriminator generalizes to longer or more complex instructions would reveal scaling limits.
Load-bearing premise
The Token-Level Relevance Discriminator accurately identifies tokens responsible for each constraint without systematic bias or needing extra labeled data.
What would settle it
Human raters judging that the discriminator frequently assigns high relevance scores to tokens that do not actually help satisfy the rubric constraints on held-out responses would falsify the central claim.
Figures




read the original abstract
Rubric-based Reinforcement Learning (RL) has emerged as a promising approach for aligning Large Language Models (LLMs) with complex, open-domain instruction following tasks. However, existing methods predominantly rely on response-level rewards, introducing severe reward sparsity and reward ambiguity problems. To address these issues, we propose Rubrics to Tokens (RTT), a novel rubric-based RL framework that bridges coarse response-level scores and fine-grained token-level credit assignment. RTT introduces a Token-Level Relevance Discriminator to predict which tokens in the response are responsible for a specific constraint, and optimizes the policy model via RTT-GRPO, which integrates response-level and token-level advantages within a unified framework. Furthermore, when transitioning from one-dimensional, outcome-level reward to three-dimensional reward space in the token-level rubric-based RL, we propose a novel group normalization method, called Intra-sample Token Group Normalization, to accommodate this shift. Extensive experiments and benchmarks demonstrate that RTT consistently outperforms other baselines in both instruction- and rubric-level accuracy across different models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Rubrics to Tokens (RTT), a rubric-based RL framework for aligning LLMs with complex instruction-following tasks. It introduces a Token-Level Relevance Discriminator that predicts which tokens in a response are responsible for satisfying individual constraints from response-level rubric scores, then optimizes the policy with RTT-GRPO (which combines response-level and token-level advantages) and Intra-sample Token Group Normalization to handle the shift to a three-dimensional token-level reward space. The central claim is that RTT consistently outperforms baselines on both instruction-level and rubric-level accuracy across models.
Significance. If the empirical claims hold and the discriminator provides unbiased token-level credit assignment, RTT would address a key limitation of response-level RL (reward sparsity and ambiguity) by enabling finer-grained optimization. The Intra-sample Token Group Normalization for multi-dimensional rewards is a potentially useful technical contribution for rubric-based methods. The work could influence future alignment techniques that combine coarse human feedback with token-level signals, provided the discriminator's reliability is demonstrated.
major comments (3)
- [§4.2] §4.2 (Token-Level Relevance Discriminator): The manuscript provides no validation of the discriminator's accuracy (e.g., precision/recall against human token-level annotations or an ablation that replaces discriminator outputs with uniform or random masks). This is load-bearing for the central claim, because any reported gains on instruction- and rubric-level accuracy could arise from the group normalization or advantage combination rather than accurate credit assignment.
- [§5] §5 (Experiments): The results tables report consistent outperformance but supply no statistical significance tests, confidence intervals, or detailed baseline descriptions (hyperparameters, training steps, reward model sizes). Without these, it is impossible to determine whether the observed improvements are robust or attributable to the proposed components.
- [§4.3] §4.3 (RTT-GRPO): The integration of response-level and token-level advantages is described at a high level; the exact weighting or scheduling between the two advantage terms is not specified, leaving open whether the method reduces to standard GRPO under certain conditions.
minor comments (3)
- [Abstract] Abstract: The phrase 'three-dimensional reward space' is introduced without defining the three dimensions; this should be clarified in the first paragraph of §3 or §4.
- [Figure 2] Figure 2: The diagram of the Token-Level Relevance Discriminator lacks axis labels and a legend for the relevance scores; this reduces readability.
- [§6] §6 (Related Work): The discussion of prior rubric-based RL methods omits recent token-level reward papers that use similar discriminators; adding 2–3 citations would strengthen context.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We have addressed each major comment point by point below. Where revisions are needed to strengthen validation and clarity, we have incorporated them in the revised manuscript.
read point-by-point responses
-
Referee: [§4.2] §4.2 (Token-Level Relevance Discriminator): The manuscript provides no validation of the discriminator's accuracy (e.g., precision/recall against human token-level annotations or an ablation that replaces discriminator outputs with uniform or random masks). This is load-bearing for the central claim, because any reported gains on instruction- and rubric-level accuracy could arise from the group normalization or advantage combination rather than accurate credit assignment.
Authors: We agree that direct validation of the Token-Level Relevance Discriminator is essential to substantiate the credit assignment mechanism. In the revised manuscript, we have added an ablation study replacing discriminator outputs with random and uniform masks, demonstrating performance degradation. We have also included precision and recall metrics computed against a small set of human-annotated token-level labels on a held-out subset of the data. These results support that the observed gains stem from meaningful token-level signals rather than solely from normalization or advantage combination. revision: yes
-
Referee: [§5] §5 (Experiments): The results tables report consistent outperformance but supply no statistical significance tests, confidence intervals, or detailed baseline descriptions (hyperparameters, training steps, reward model sizes). Without these, it is impossible to determine whether the observed improvements are robust or attributable to the proposed components.
Authors: We acknowledge the need for greater statistical rigor and transparency in the experimental section. The revised manuscript now reports statistical significance via paired t-tests with p-values, includes 95% confidence intervals on all performance metrics in the tables, and adds a comprehensive appendix detailing hyperparameters, training steps, reward model sizes, and implementation specifics for all baselines. These changes allow readers to better assess the robustness and attribution of the improvements. revision: yes
-
Referee: [§4.3] §4.3 (RTT-GRPO): The integration of response-level and token-level advantages is described at a high level; the exact weighting or scheduling between the two advantage terms is not specified, leaving open whether the method reduces to standard GRPO under certain conditions.
Authors: We thank the referee for noting the need for precise specification. In the updated Section 4.3, we now provide the exact formulation: the combined advantage is computed as A = A_response + λ · A_token, where λ is a scheduling hyperparameter that increases linearly from 0.1 to 1.0 over training epochs. We include the full pseudocode and a brief analysis demonstrating that the method does not reduce to standard GRPO, as the token-level term supplies an ongoing fine-grained signal throughout optimization. revision: yes
Circularity Check
No significant circularity; claims rest on empirical results rather than definitional reduction
full rationale
The paper introduces RTT via a Token-Level Relevance Discriminator and RTT-GRPO with Intra-sample Token Group Normalization, building on standard RL components. No equations or derivations are shown that reduce claimed accuracy gains to a fitted parameter or self-defined quantity by construction. No self-citation load-bearing steps, uniqueness theorems, or ansatz smuggling appear in the provided abstract and context. The central claim of outperformance is presented as empirical, not tautological, yielding only minor self-citation risk at most.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Token-Level Relevance Discriminator
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
RTT introduces a Token-Level Relevance Discriminator to predict which tokens... and optimizes the policy model via RTT-GRPO, which integrates response-level and token-level advantages... Intra-sample Token Group Normalization
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We identify the Group Partitioning Problem when transitioning from one-dimensional, outcome-level reward to three-dimensional reward space
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Wenhao Liu, Zhengkang Guo, Mingchen Xie, Jingwen Xu, Zisu Huang, Muzhao Tian, Jianhan Xu, Muling Wu, Xiaohua Wang, Changze Lv, et al. 2025. Recast: Strengthening llms’ complex instruction following with constraint-verifiable data.arXiv e-prints, pages arXiv–2505
work page 2025
- [2]
-
[3]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. 2022. Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744
work page 2022
-
[4]
Hao Peng, Yunjia Qi, Xiaozhi Wang, Bin Xu, Lei Hou, and Juanzi Li. 2025. Verif: Verification engineering for reinforcement learning in instruction following. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 30312–30327
work page 2025
- [5]
- [6]
-
[7]
Yiwei Qin, Kaiqiang Song, Yebowen Hu, Wenlin Yao, Sangwoo Cho, Xiaoyang Wang, Xuansheng Wu, Fei Liu, Pengfei Liu, and Dong Yu. 2024. Infobench: Evaluating instruction following ability in large language models
work page 2024
-
[8]
Qwen, :, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, et al. 2025. Qwen2.5 technical report
work page 2025
-
[9]
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn
-
[10]
Direct preference optimization: Your language model is secretly a reward model.Advances in neural information processing systems, 36:53728–53741
-
[11]
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R Bowman. 2024. Gpqa: A graduate-level google-proof q&a benchmark.arXiv preprint arXiv:2311.12022
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. 2024. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [13]
- [14]
- [15]
- [16]
-
[17]
Peiyi Wang, Lei Li, Zhihong Shao, Runxin Xu, Damai Dai, Yifei Li, Deli Chen, Yu Wu, and Zhifang Sui. 2024a. Math-shepherd: Verify and reinforce llms step-by-step without human annotations. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 9426–9439
- [18]
-
[19]
Yinjie Wang, Xuyang Chen, Xiaolong Jin, Mengdi Wang, and Ling Yang. 2026. Openclaw-rl: Train any agent simply by talking
work page 2026
-
[20]
Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Ziyan Jiang, et al. 2024b. Mmlu-pro: A more robust and challenging multi-task language understanding benchmark.arXiv preprint arXiv:2406.01574. 13
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Bosi Wen, Pei Ke, Xiaotao Gu, Lindong Wu, Hao Huang, Jinfeng Zhou, Wenchuang Li, Binxin Hu, Wendy Gao, Jiaxing Xu, et al. 2024. Benchmarking complex instruction-following with multiple constraints composition. Advances in Neural Information Processing Systems, 37:137610–137645
work page 2024
-
[22]
Yuxin Wu and Kaiming He. 2018. Group normalization. InProceedings of the European conference on computer vision (ECCV), pages 3–19
work page 2018
-
[23]
Can Xu, Qingfeng Sun, Kai Zheng, Xiubo Geng, Pu Zhao, Jiazhan Feng, Chongyang Tao, and Daxin Jiang. 2023. Wizardlm: Empowering large language models to follow complex instructions.arXiv preprint arXiv:2304.12244
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. 2025. Qwen3 technical report.arXiv preprint arXiv:2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Junjie Ye, Caishuang Huang, Zhuohan Chen, Wenjie Fu, Chenyuan Yang, Leyi Yang, Yilong Wu, Peng Wang, Meng Zhou, Xiaolong Yang, et al. 2025. A multi-dimensional constraint framework for evaluating and improving instruction following in large language models.arXiv preprint arXiv:2505.07591
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Eunseop Yoon, Hee Suk Yoon, SooHwan Eom, Gunsoo Han, Daniel Nam, Daejin Jo, Kyoung-Woon On, Mark Hasegawa-Johnson, Sungwoong Kim, and Chang Yoo. 2024. Tlcr: Token-level continuous reward for fine-grained reinforcement learning from human feedback. InFindings of the Association for Computational Linguistics: ACL 2024, pages 14969–14981
work page 2024
-
[27]
Siliang Zeng, Quan Wei, William Brown, Oana Frunza, Yuriy Nevmyvaka, Yang Katie Zhao, and Mingyi Hong
-
[28]
InICML 2025 Workshop on Computer Use Agents
Reinforcing multi-turn reasoning in llm agents via turn-level credit assignment. InICML 2025 Workshop on Computer Use Agents
work page 2025
- [29]
-
[30]
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. 2023. Judging llm-as-a-judge with mt-bench and chatbot arena. Advances in neural information processing systems, 36:46595–46623
work page 2023
-
[31]
Yaowei Zheng, Ruqing Zhang, Wenhua Zhang, Yong Ye, Yuan Luo, Zihan Yan, Yujiong Zhang, Yuxuan Yang, and Jing Huang. 2024. Llamafactory: Unified efficient fine-tuning of 100+ language models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics: System Demonstrations
work page 2024
-
[32]
Chunting Zhou, Pengfei Liu, Puxin Xu, Srinivasan Iyer, Jiao Sun, Yuning Mao, Xuezhe Ma, Avia Efrat, Ping Yu, Lili Yu, et al. 2023a. Lima: Less is more for alignment.Advances in Neural Information Processing Systems, 36:55006–55021
- [33]
-
[34]
Jeffrey Zhou, Tianjian Lu, Swaroop Mishra, Siddhartha Brahma, Sujoy Basu, Yi Luan, Denny Zhou, and Le Hou. 2023b. Instruction-following evaluation for large language models.arXiv preprint arXiv:2311.07911
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
Each sentence in the generated text uses a second person
Yang Zhou, Sunzhu Li, Shunyu Liu, Wenkai Fang, Kongcheng Zhang, Jiale Zhao, Jingwen Yang, Yihe Zhou, Jianwei Lv, Tongya Zheng, et al. 2025. Breaking the exploration bottleneck: Rubric-scaffolded reinforcement learning for general llm reasoning.arXiv preprint arXiv:2508.16949. A Limitations and Future Work A.1 Limitations While we identify the Group Partit...
-
[36]
Instead, provide a thorough narrative that explains the ”how” and ”why” alongside the final result
Integration:Do not separate the reasoning from the answer. Instead, provide a thorough narrative that explains the ”how” and ”why” alongside the final result
-
[37]
Rubric Fulfillment:Every constraint listed in the Rubrics must be strictly followed within the flow of your detailed response
-
[38]
Depth:Avoid brief or ”final-answer-only” responses. Elaborate on the logic and steps required to reach the conclusion. Output:{OUTPUT} For the minimal modification strategy, we use the following prompt to generated negative response that violates the specific constraint. Prompt for Minimal modification You are given a question, an original response that f...
-
[42]
Ensure the JSON format is correct and can be directly parsed. Greedy baseline prompt You are a professional text analysis assistant. Your task is to extract text segments from the Response that are relevant to the given Criteria. Criteria:{criteria} Response:{response} Please carefully analyze the Response and extract the text segments that address or rel...
-
[43]
If the entire response is relevant to the Criteria, output:{”type”: ”all relevant”}
-
[44]
If the entire response is irrelevant to the Criteria, output:{”type”: ”all irrelevant”}
-
[45]
If partially relevant, output: {”type”: ”partial relevant”, ”relevant texts”: [”relevant text segment 1”, ”relevant text segment 2”, ...]} Important Notes: 19
-
[46]
The text segments in relevant texts must be exact original text from the Response (exact match, including punctuation and spaces)
-
[47]
Each text segment should be a continuous, complete sentence or phrase
-
[48]
Output only JSON format, without any markdown code block markers or other text
-
[49]
Ensure the JSON format is correct and can be directly parsed. D Inter-Sample Token Group Normalization We first provide a formal definition ofInter-Sample Token Group Normalization, the baseline strategy discussed in Section 3.2. Then we give an elaborate analysis of length-bias problem to formally demonstrate why this group normalization method systemati...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.