Recognition: 2 theorem links
· Lean TheoremNeural Global Optimization via Iterative Refinement from Noisy Samples
Pith reviewed 2026-05-13 18:55 UTC · model grok-4.3
The pith
A neural network learns to iteratively refine noisy samples and spline fits into accurate global minima for black-box functions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a neural network trained solely on synthetic multi-modal functions can learn to locate global minima by iteratively refining an initial position estimate derived from noisy samples and their spline representation. The model encodes multiple modalities of the input and performs repeated position updates, yielding an 8.05 percent mean error on held-out test functions versus 36.24 percent for the spline baseline and succeeding with low error in 72 percent of trials.
What carries the argument
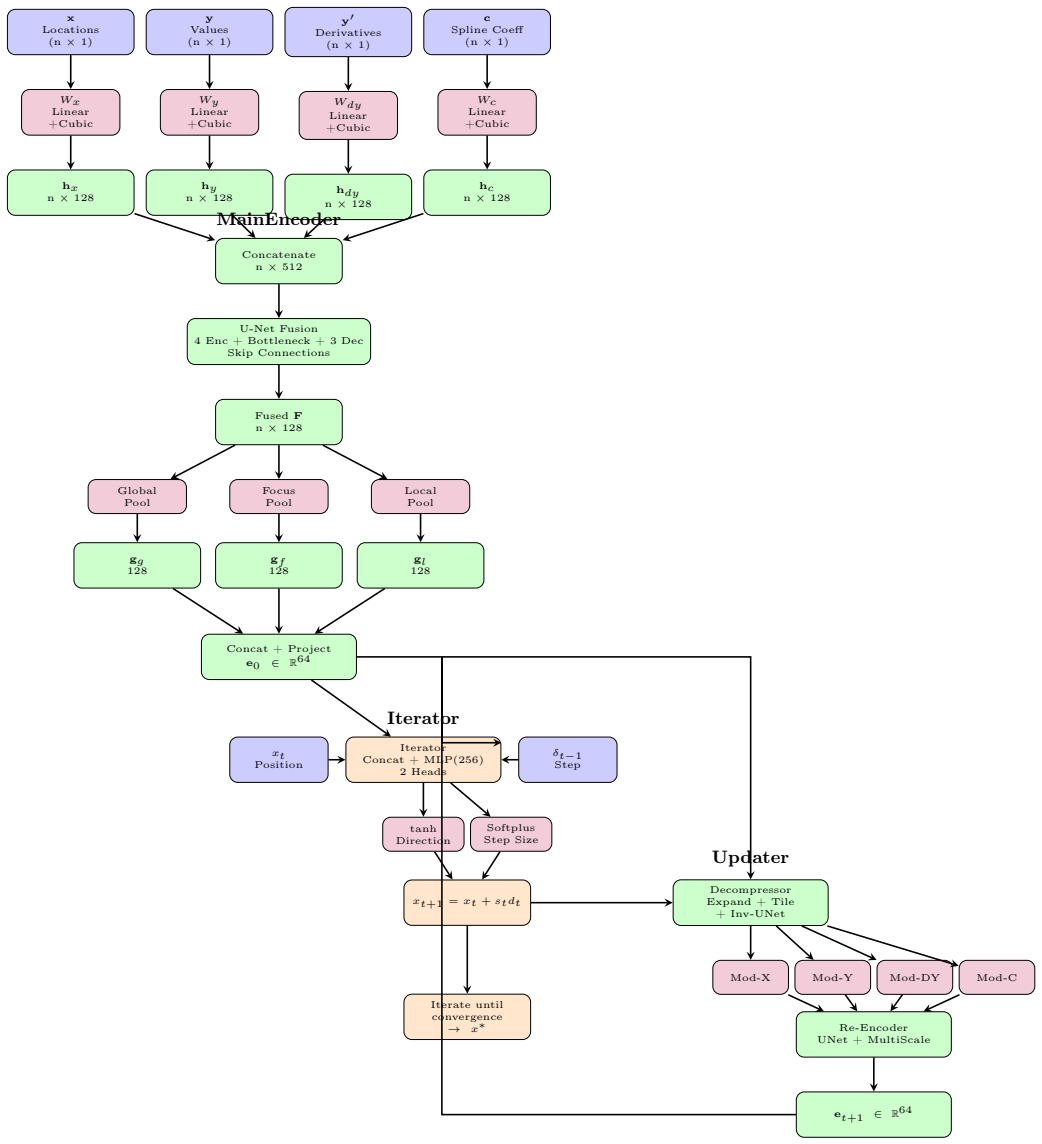
An iterative refinement network that encodes function values, derivatives, and spline coefficients to drive successive position updates toward the global minimum.
If this is right
- Global optimization becomes possible without derivative information or multiple random restarts.
- Performance gains over simple spline initialization hold across a range of multi-modal landscapes.
- The learned refinement step transfers from synthetic training functions to unseen test functions.
- The approach reduces the number of function evaluations needed to reach low-error minima.
Where Pith is reading between the lines
- The same refinement network could be applied to higher-dimensional problems where exhaustive search for ground truth is impossible.
- Combining the iterative updates with uncertainty estimates from Bayesian optimization might further improve sample efficiency.
- Varying the noise distribution during training could make the model robust to real sensor or simulation noise levels.
Load-bearing premise
Training exclusively on randomly generated synthetic functions with exhaustive-search ground truth produces a model that generalizes to real-world black-box functions with different noise statistics and modality structures.
What would settle it
Running the trained model on a real-world black-box task such as neural-network hyperparameter tuning and measuring whether the final error stays above 20 percent despite adequate noisy samples.
Figures



read the original abstract
Global optimization of black-box functions from noisy samples is a fundamental challenge in machine learning and scientific computing. Traditional methods such as Bayesian Optimization often converge to local minima on multi-modal functions, while gradient-free methods require many function evaluations. We present a novel neural approach that learns to find global minima through iterative refinement. Our model takes noisy function samples and their fitted spline representation as input, then iteratively refines an initial guess toward the true global minimum. Trained on randomly generated functions with ground truth global minima obtained via exhaustive search, our method achieves a mean error of 8.05 percent on challenging multi-modal test functions, compared to 36.24 percent for the spline initialization, a 28.18 percent improvement. The model successfully finds global minima in 72 percent of test cases with error below 10 percent, demonstrating learned optimization principles rather than mere curve fitting. Our architecture combines encoding of multiple modalities including function values, derivatives, and spline coefficients with iterative position updates, enabling robust global optimization without requiring derivative information or multiple restarts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a neural model for global optimization of black-box functions from noisy samples. It takes noisy function values and a spline fit as input, then iteratively refines an initial guess toward the global minimum. The model is trained exclusively on randomly generated synthetic functions whose ground-truth minima are obtained by exhaustive search. On challenging multi-modal test functions it reports a mean error of 8.05% (versus 36.24% for the spline initialization) and succeeds with error below 10% in 72% of cases, which the authors interpret as evidence of learned optimization principles rather than curve fitting.
Significance. If the reported improvement generalizes beyond the synthetic training distribution, the approach could offer a useful learned initializer or refiner for black-box optimization tasks that currently rely on Bayesian optimization or multi-start gradient-free methods. The absence of architecture diagrams, training protocols, statistical significance tests, ablation studies, or explicit distribution-shift controls, however, leaves the central performance claims unverifiable and the generalization claim unsupported.
major comments (3)
- Abstract: the claim that the model 'demonstrates learned optimization principles rather than mere curve fitting' is load-bearing for the paper's contribution, yet no statement confirms that the test functions are sampled from a generative process, noise model, or modality structure distinct from the training distribution. Without this control, the 28.18% error reduction could arise from distribution matching rather than transferable optimization behavior.
- Abstract: the reported mean error of 8.05% and 72% success rate are presented without any mention of the number of test functions, variance across runs, statistical tests, or ablation studies that isolate the contribution of the iterative refinement component versus the spline initialization.
- Abstract: the architecture is described only at a high level ('encoding of multiple modalities including function values, derivatives, and spline coefficients with iterative position updates'), with no diagram, layer counts, loss function, or training hyper-parameters supplied, rendering the method non-reproducible from the manuscript.
minor comments (2)
- Abstract: the phrase 'without requiring derivative information' is inconsistent with the earlier mention of encoding derivatives; clarify whether derivatives are computed from the spline or supplied as input.
- Abstract: the improvement is stated as '28.18 percent' but the arithmetic (36.24 - 8.05) yields 28.19; correct the rounding.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below and describe the revisions we will implement to improve clarity, reproducibility, and the support for our claims.
read point-by-point responses
-
Referee: Abstract: the claim that the model 'demonstrates learned optimization principles rather than mere curve fitting' is load-bearing for the paper's contribution, yet no statement confirms that the test functions are sampled from a generative process, noise model, or modality structure distinct from the training distribution. Without this control, the 28.18% error reduction could arise from distribution matching rather than transferable optimization behavior.
Authors: We agree that the interpretation of learned optimization principles is strengthened by evidence of generalization. The test functions are drawn from the same family of randomly generated multi-modal functions but form a disjoint set created with independent random seeds and parameter ranges. In the revision we will add an explicit description of the data generation procedure and test-set construction in the Experiments section. We will also moderate the abstract claim to 'suggesting that the model has learned effective iterative refinement strategies' to avoid overstatement while preserving the performance comparison to the spline baseline. revision: partial
-
Referee: Abstract: the reported mean error of 8.05% and 72% success rate are presented without any mention of the number of test functions, variance across runs, statistical tests, or ablation studies that isolate the contribution of the iterative refinement component versus the spline initialization.
Authors: We acknowledge that these statistical and ablation details are necessary for verifiability. In the revised manuscript we will report the number of test functions, include variance or standard deviation across runs, add statistical significance tests against the baseline, and incorporate ablation experiments that isolate the iterative refinement module. These elements will be added to the main text and summarized concisely in the abstract. revision: yes
-
Referee: Abstract: the architecture is described only at a high level ('encoding of multiple modalities including function values, derivatives, and spline coefficients with iterative position updates'), with no diagram, layer counts, loss function, or training hyper-parameters supplied, rendering the method non-reproducible from the manuscript.
Authors: We agree that the current description is insufficient for reproducibility. The revised paper will include a dedicated architecture diagram, specify layer counts and dimensions for the multi-modal encoder and refinement modules, state the loss function used for training, and provide the complete set of training hyperparameters. These details will appear in a new Implementation Details section. revision: yes
Circularity Check
No significant circularity: independent exhaustive-search ground truth
full rationale
The paper trains a neural model on synthetic functions whose global minima are located by exhaustive search, an external procedure independent of the network. Reported metrics (8.05% mean error, 72% success rate) are direct comparisons of model outputs against these independent ground-truth locations on held-out test functions. No equations reduce the error metric to a quantity defined by the model's own fitted parameters, no self-citation supplies a load-bearing uniqueness theorem, and the spline initialization serves only as a baseline input rather than a definitional tautology. The derivation chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Randomly generated functions with exhaustive-search minima are representative of real black-box optimization problems
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Our architecture combines encoding of multiple modalities (function values, derivatives, spline coefficients) with iterative position updates
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Trained on randomly generated functions with ground truth global minima obtained via exhaustive search
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
J. Bergstra and Y. Bengio. Random search for hyper-parameter optimization.Journal of Ma- chine Learning Research, 13:281–305, 2012
work page 2012
- [2]
-
[3]
J. Gómez-Bombarelli et al. Automatic chemi- cal design using a data-driven continuous rep- resentation of molecules.ACS Central Science, 4(2):268–276, 2018
work page 2018
-
[4]
B. Shahriari, K. Swersky, Z. Wang, R. P. Adams, and N. De Freitas. Taking the human out of the loop: A review of Bayesian optimization.Pro- ceedings of the IEEE, 104(1):148–175, 2015
work page 2015
- [5]
-
[6]
D. R. Jones, M. Schonlau, and W. J. Welch. Efficient global optimization of expensive black- box functions.Journal of Global Optimization, 13(4):455–492, 1998
work page 1998
-
[7]
N. Hansen and A. Ostermeier. Completely de- randomized self-adaptation in evolution strate- gies.Evolutionary Computation, 9(2):159–195, 2001
work page 2001
-
[8]
E. Brochu, V. M. Cora, and N. De Freitas. A tutorial on Bayesian optimization of expensive cost functions.arXiv preprint arXiv:1012.2599, 2010
work page Pith review arXiv 2010
-
[9]
N. Srinivas, A. Krause, S. M. Kakade, and M. Seeger. Gaussian process optimization in the bandit setting: No regret and experimental de- sign. InInternational Conference on Machine Learning, 2009
work page 2009
-
[10]
P. I. Frazier, W. B. Powell, and S. Dayanik. A knowledge-gradient policy for sequential infor- mation collection.SIAM Journal on Control and Optimization, 47(5):2410–2439, 2008
work page 2008
- [11]
-
[12]
S. Kirkpatrick, C. D. Gelatt, and M. P. Vecchi. Optimization by simulated annealing.Science, 220(4598):671–680, 1983
work page 1983
-
[13]
Y. Chen, M. W. Hoffman, S. G. Colmenarejo, M.Denil, T.P.Lillicrap, M.Botvinick, andN.de Freitas. Learning to learn without gradient de- scent by gradient descent. InInternational Con- ference on Machine Learning, 2017
work page 2017
-
[14]
Neural Combinatorial Optimization with Reinforcement Learning
I. Bello, H. Pham, Q. V. Le, M. Norouzi, and S. Bengio. Neural combinatorial optimization with reinforcement learning.arXiv preprint arXiv:1611.09940, 2016. Algorithm 1Neural Global Optimization - Forward Pass Require:Samplesx,y; fitted spline derivativesy ′, coefficientsc; initial positionx 0 Ensure:Predicted global minimumx ∗ 1://Stage 1: MainEncoder 2:...
work page Pith review arXiv 2016
-
[15]
n 35:M (i) y ←ϕ cubic(W y mod[R(i) ||x t+1 ||δ t])fori=
-
[16]
n 36:M (i) dy ←ϕ cubic(W dy mod[R(i) ||x t+1 ||δ t])fori=
-
[17]
n 37:M (i) c ←ϕ cubic(W c mod[R(i) ||x t+1 ||δ t])fori=
-
[18]
n 38://Updater - Re-Encoder 39:M (i) cat ←[M (i) x ||M (i) y ||M (i) dy ||M (i) c ] 40:F ′ ←UNet(M cat) 41:g ′ global ←ϕ cubic(W ′ global ·mean(F ′) +b ′ global) 42:g ′ focus ←ϕ cubic(W ′ focus ·mean(F ′) +b ′ focus) 43:g ′ local ←ϕ cubic(W ′ local ·mean(F ′) +b ′ local) 44:e t+1 ←W ′ edv[g′ global ||g ′ focus ||g ′ local] +b ′ edv 45:t←t+ 1 46:end while ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.