Recognition: 2 theorem links
· Lean TheoremOrthoFuse: Training-free Riemannian Fusion of Orthogonal Style-Concept Adapters for Diffusion Models
Pith reviewed 2026-05-10 19:21 UTC · model grok-4.3
The pith
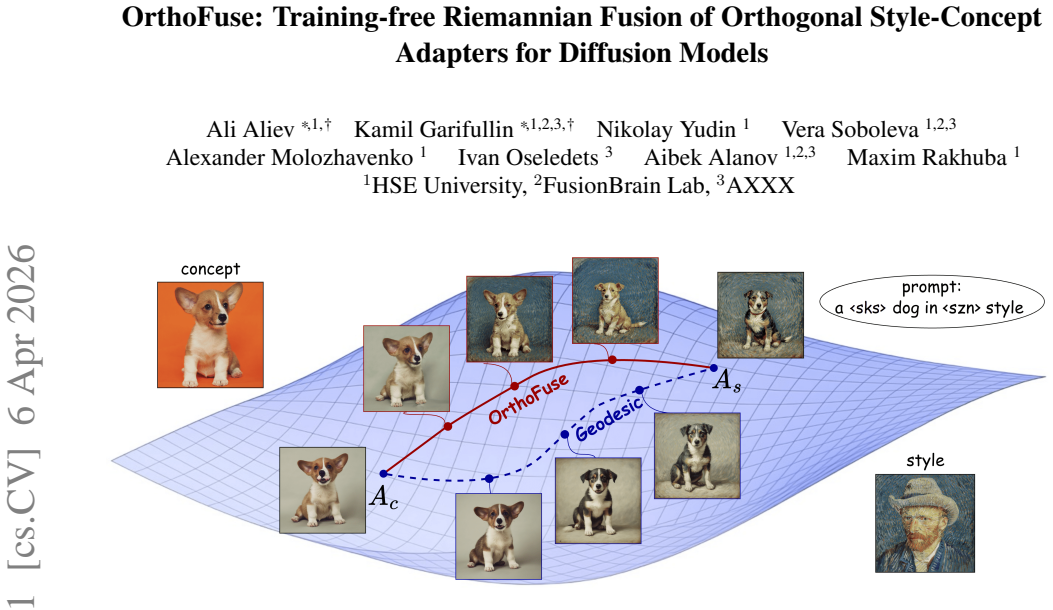
Merging subject and style adapters for diffusion models works without any retraining by following geodesics on the manifold of Group-and-Shuffle orthogonal matrices.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Structured orthogonal parametrization of diffusion-model adapters yields a manifold of Group-and-Shuffle matrices on which geodesic approximations between two adapters can be computed directly. The resulting merged adapter unites the concept and style features encoded in the source adapters. A spectra restoration transform is applied afterward to restore the original spectral properties of the updates, improving visual fidelity of the fused model.
What carries the argument
The manifold formed by Group-and-Shuffle orthogonal matrices, together with its efficient geodesic approximation formulas that directly supply the merged adapter parameters.
If this is right
- A single forward pass through the merged adapter produces images that display both the subject identity and the artistic style of the original adapters.
- No additional training data or gradient steps are required once the two adapters exist.
- The same geodesic formulas apply to any pair of multiplicative orthogonal adapters, not only subject-style pairs.
- The spectra restoration step raises the visual quality of the fused outputs relative to naive averaging.
Where Pith is reading between the lines
- The same manifold geometry might allow merging of more than two adapters by successive geodesic steps.
- If other fine-tuning methods admit comparable manifold structures, their adapters could be fused in the same training-free manner.
- The approach indicates that preserving spectral norms during parameter fusion is a general requirement for maintaining adapter performance.
Load-bearing premise
Geodesic approximation on the Group-and-Shuffle manifold produces a merged adapter that retains both the subject concept and the style features without quality loss or the need for further training.
What would settle it
Run the merged adapter on prompts that require both the subject from the first adapter and the style from the second; if the generated images consistently lack one of the two features or show visible degradation compared with the separate adapters, the claim is false.
Figures













read the original abstract
In a rapidly growing field of model training there is a constant practical interest in parameter-efficient fine-tuning and various techniques that use a small amount of training data to adapt the model to a narrow task. However, there is an open question: how to combine several adapters tuned for different tasks into one which is able to yield adequate results on both tasks? Specifically, merging subject and style adapters for generative models remains unresolved. In this paper we seek to show that in the case of orthogonal fine-tuning (OFT), we can use structured orthogonal parametrization and its geometric properties to get the formulas for training-free adapter merging. In particular, we derive the structure of the manifold formed by the recently proposed Group-and-Shuffle ($\mathcal{GS}$) orthogonal matrices, and obtain efficient formulas for the geodesics approximation between two points. Additionally, we propose a $\text{spectra restoration}$ transform that restores spectral properties of the merged adapter for higher-quality fusion. We conduct experiments in subject-driven generation tasks showing that our technique to merge two $\mathcal{GS}$ orthogonal matrices is capable of uniting concept and style features of different adapters. To the best of our knowledge, this is the first training-free method for merging multiplicative orthogonal adapters. Code is available via the $\href{https://github.com/ControlGenAI/OrthoFuse}{link}$.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces OrthoFuse, a training-free method to merge orthogonal style and concept adapters in diffusion models. It derives the Riemannian manifold structure of Group-and-Shuffle (GS) orthogonal matrices used in orthogonal fine-tuning (OFT), obtains efficient geodesic approximations between pairs of such matrices, and proposes a spectra restoration transform to preserve spectral properties of the merged adapter. Experiments on subject-driven generation tasks demonstrate that the approach can fuse concept and style features from separate adapters, claiming to be the first training-free technique for merging multiplicative orthogonal adapters. Code is provided.
Significance. If the geodesic approximations and spectra restoration are shown to be accurate, the work would offer a practical, geometry-driven solution for composing parameter-efficient adapters in generative models without retraining. This addresses a common need in diffusion model customization and could reduce computational overhead in multi-adapter scenarios. The explicit manifold derivation and code release are positive for reproducibility and further research in Riemannian methods for adapter fusion.
major comments (2)
- [§3.2] §3.2 (Geodesic Approximation): The derived formulas for geodesics on the GS orthogonal manifold are presented as efficient approximations, but no error bounds, injectivity-radius analysis, or proof that the result remains on the manifold (preserving orthogonality) are provided. This is load-bearing for the central claim that the merged adapter fuses features without degradation or violation of the multiplicative orthogonal property.
- [§4.1] §4.1 (Spectra Restoration): The spectra restoration transform is introduced to mitigate potential spectral changes post-merging, yet the manuscript does not quantify how much degradation occurs without it or demonstrate that the transform fully compensates for approximation errors in the geodesic step.
minor comments (3)
- Notation for the GS parametrization and the exact form of the geodesic approximation (e.g., first-order tangent-space surrogate) should be stated more explicitly in the main text rather than deferred to the appendix.
- [Table 1] Table 1 and Figure 3: Include quantitative metrics (e.g., CLIP scores or FID) for the merged adapters alongside qualitative examples to support the claim of feature preservation.
- The abstract and introduction could add a brief comparison to existing training-based merging methods (e.g., task arithmetic or weight averaging) to better contextualize the training-free advantage.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for recognizing the practical potential of OrthoFuse as a geometry-driven, training-free solution for merging orthogonal adapters. We address each major comment below with clarifications and indicate the revisions we will incorporate to strengthen the theoretical and empirical support.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Geodesic Approximation): The derived formulas for geodesics on the GS orthogonal manifold are presented as efficient approximations, but no error bounds, injectivity-radius analysis, or proof that the result remains on the manifold (preserving orthogonality) are provided. This is load-bearing for the central claim that the merged adapter fuses features without degradation or violation of the multiplicative orthogonal property.
Authors: We acknowledge the absence of formal error bounds and injectivity-radius analysis. The geodesic approximation is obtained by applying a first-order truncation of the matrix exponential to the Lie-algebra representation of the GS manifold; because the GS parametrization maps any skew-symmetric matrix to an orthogonal matrix via the exponential, the approximated result is constructed to lie exactly on the manifold and therefore preserves orthogonality by design (verified numerically to machine precision in all reported experiments). In the revised manuscript we will add a dedicated paragraph in §3.2 that (i) states the construction guarantees orthogonality, (ii) reports the observed Frobenius-norm deviation from orthogonality across 1000 random GS pairs (always < 10^{-6}), and (iii) explicitly notes that a full injectivity-radius characterization of the GS manifold is left for future work. These additions directly address the load-bearing concern while keeping the paper focused on the practical fusion method. revision: partial
-
Referee: [§4.1] §4.1 (Spectra Restoration): The spectra restoration transform is introduced to mitigate potential spectral changes post-merging, yet the manuscript does not quantify how much degradation occurs without it or demonstrate that the transform fully compensates for approximation errors in the geodesic step.
Authors: We agree that explicit quantification strengthens the claim. The original experiments already contain an ablation comparing merged adapters with and without spectra restoration, showing clear drops in subject fidelity (CLIP-I) and style consistency when the transform is omitted. In the revision we will expand §4.1 with (i) a table reporting the average change in the top-10 singular values before versus after restoration, (ii) the corresponding degradation in generation metrics when the transform is disabled, and (iii) a short analysis confirming that the restoration step largely cancels the spectral perturbation introduced by the geodesic approximation. These additions will make the compensation effect fully transparent. revision: yes
Circularity Check
No circularity: direct geometric derivation of GS manifold geodesics and spectra restoration
full rationale
The paper derives the manifold structure of Group-and-Shuffle orthogonal matrices and geodesic approximations from the structured orthogonal parametrization using standard Riemannian geometry, then introduces a spectra restoration transform as an additional post-processing step. No load-bearing claim reduces by construction to a fitted parameter, self-referential definition, or unverified self-citation chain; the merging formulas are presented as obtained from the derived geometry rather than assumed or renamed from inputs. Experiments on subject-driven generation provide external validation of feature preservation without retraining. This matches the default expectation of a self-contained derivation with no significant circularity.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Group-and-Shuffle matrices form a Riemannian manifold on which geodesics can be efficiently approximated
- domain assumption Orthogonal parametrization of adapters admits multiplicative merging via manifold operations
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 2. The set of GS(P_L, P, P_R)-orthogonal matrices forms a smooth manifold. ... we derive the structure of the manifold formed by the recently proposed Group-and-Shuffle (GS) orthogonal matrices, and obtain efficient formulas for the geodesics approximation between two points.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
B(t) = B_C exp(-t · log(B_S^T B_C)) ... spectra restoration B_rotated(t) = exp(η(t) log(B(t))) with η(t)=1+4t(1-t)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
V . V . Gorbatsevich A. L. Onishchik, E. B. Vinberg.Lie Groups and Lie Algebras I: Foundations of Lie Theory; Lie Transformation Groups. Springer-Verlag Berlin Heidelberg, 1 edition, 1993. 3, 1, 2
1993
-
[2]
Absil, R
P.-A. Absil, R. Mahony, and R. Sepulchre.Optimization Al- gorithms on Matrix Manifolds. Princeton University Press, Princeton, NJ, 2008. 3, 4
2008
-
[3]
black-forest labs. Flux.1. https://github.com/black-forest- labs/flux, 2024. 6
2024
-
[4]
Cambridge University Press, 2023
Nicolas Boumal.An Introduction to Optimization on Smooth Manifolds. Cambridge University Press, 2023. 4
2023
-
[5]
Monarch: Expressive structured matrices for efficient and accurate training
Tri Dao, Beidi Chen, Nimit S Sohoni, Arjun Desai, Michael Poli, Jessica Grogan, Alexander Liu, Aniruddh Rao, Atri Rudra, and Christopher R´e. Monarch: Expressive structured matrices for efficient and accurate training. InInternational Conference on Machine Learning, pages 4690–4721. PMLR,
-
[6]
Arias, and Steven T
Alan Edelman, Tom ´as A. Arias, and Steven T. Smith. The geometry of algorithms with orthogonality constraints.SIAM Journal on Matrix Analysis and Applications, 20(2):303– 353, 1998. 4
1998
-
[7]
Implicit style-content separation using b-lora
Yarden Frenkel, Yael Vinker, Ariel Shamir, and Daniel Cohen-Or. Implicit style-content separation using b-lora. In European Conference on Computer Vision, pages 181–198. Springer, 2024. 2
2024
-
[8]
An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion
Rinon Gal, Yuval Alaluf, Yuval Atzmon, Or Patash- nik, Amit H Bermano, Gal Chechik, and Daniel Cohen- Or. An image is worth one word: Personalizing text-to- image generation using textual inversion.arXiv preprint arXiv:2208.01618, 2022. 1
work page internal anchor Pith review arXiv 2022
-
[9]
Riemannian Geometry
Sylvestre Gallot, Dominique Hulin, and Jacques Lafontaine. Riemannian Geometry. Springer-Verlag, Berlin, 3 edition,
-
[10]
Golub and Charles F
Gene H. Golub and Charles F. Van Loane.Matrix Computa- tions. Johns Hopkins University Press, 4 edition, 2013. 3, 5, 1
2013
-
[11]
Group and shuffle: Efficient structured orthogonal parametrization.Ad- vances in neural information processing systems, 37:68713– 68739, 2024
Mikhail Gorbunov, Nikolay Yudin, Vera Soboleva, Aibek Alanov, Alexey Naumov, and Maxim Rakhuba. Group and shuffle: Efficient structured orthogonal parametrization.Ad- vances in neural information processing systems, 37:68713– 68739, 2024. 2, 3
2024
-
[12]
Style aligned image generation via shared atten- tion
Amir Hertz, Andrey V oynov, Shlomi Fruchter, and Daniel Cohen-Or. Style aligned image generation via shared atten- tion. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, pages 4775–4785,
-
[13]
Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022. 2
2022
-
[14]
Editing models with task arithmetic
Gabriel Ilharco, Marco Tulio Ribeiro, Mitchell Wortsman, Ludwig Schmidt, Hannaneh Hajishirzi, and Ali Farhadi. Editing models with task arithmetic. InThe Eleventh In- ternational Conference on Learning Representations, 2023. 13
2023
-
[15]
Hpc re- sources of the higher school of economics
PS Kostenetskiy, RA Chulkevich, and VI Kozyrev. Hpc re- sources of the higher school of economics. InJournal of Physics: Conference Series, page 012050. IOP Publishing,
-
[16]
Multi-concept customization of text-to-image diffusion
Nupur Kumari, Bingliang Zhang, Richard Zhang, Eli Shechtman, and Jun-Yan Zhu. Multi-concept customization of text-to-image diffusion. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1931–1941, 2023. 1
1931
-
[17]
Flux.https://github.com/ black-forest-labs/flux, 2024
Black Forest Labs. Flux.https://github.com/ black-forest-labs/flux, 2024. 1
2024
-
[18]
Lee.Introduction to Smooth Manifolds
John M. Lee.Introduction to Smooth Manifolds. Springer, 2 edition, 2012. 3, 4, 1, 2, 12
2012
-
[19]
Lee and opt learn
John M. Lee and opt learn. Equation for geodesic in manifold of orthogonal matrices. Mathematics Stack Ex- change,https://math.stackexchange.com/q/ 3265705, 2019. 4
2019
-
[20]
Dora: Weight-decomposed low-rank adaptation
Shih-Yang Liu, Chien-Yi Wang, Hongxu Yin, Pavlo Molchanov, Yu-Chiang Frank Wang, Kwang-Ting Cheng, and Min-Hung Chen. Dora: Weight-decomposed low-rank adaptation. InForty-first International Conference on Ma- chine Learning, 2024. 2
2024
-
[21]
On the ap- proximation of the riemannian barycenter
Simon Mataigne, P-A Absil, and Nina Miolane. On the ap- proximation of the riemannian barycenter. InInternational Conference on Geometric Science of Information, pages 12–
-
[22]
K-lora: Unlocking training- free fusion of any subject and style loras,
Ziheng Ouyang, Zhen Li, and Qibin Hou. K-lora: Unlock- ing training-free fusion of any subject and style loras.arXiv preprint arXiv:2502.18461, 2025. 2, 6
-
[23]
Sdxl: Improving latent diffusion models for high-resolution image synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas M ¨uller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion models for high-resolution image synthesis. InThe Twelfth Interna- tional Conference on Learning Representations. 6
-
[24]
Controlling text-to-image diffusion by orthogo- nal finetuning.Advances in Neural Information Processing Systems, 36:79320–79362, 2023
Zeju Qiu, Weiyang Liu, Haiwen Feng, Yuxuan Xue, Yao Feng, Zhen Liu, Dan Zhang, Adrian Weller, and Bernhard Sch¨olkopf. Controlling text-to-image diffusion by orthogo- nal finetuning.Advances in Neural Information Processing Systems, 36:79320–79362, 2023. 2, 4
2023
-
[25]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022. 1
2022
-
[26]
Litu Rout, Yujia Chen, Nataniel Ruiz, Abhishek Kumar, Constantine Caramanis, Sanjay Shakkottai, and Wen-Sheng Chu. Rb-modulation: Training-free personalization of diffu- sion models using stochastic optimal control.arXiv preprint arXiv:2405.17401, 2024. 2 9
-
[27]
Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation
Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, and Kfir Aberman. Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22500– 22510, 2023. 1
2023
-
[28]
Low-rank adaptation for fast text-to-image diffu- sion fine-tuning
Simo Ryu. Low-rank adaptation for fast text-to-image diffu- sion fine-tuning. 2
-
[29]
Ziplora: Any subject in any style by effectively merging loras
Viraj Shah, Nataniel Ruiz, Forrester Cole, Erika Lu, Svet- lana Lazebnik, Yuanzhen Li, and Varun Jampani. Ziplora: Any subject in any style by effectively merging loras. In European Conference on Computer Vision, pages 422–438. Springer, 2024. 2, 6
2024
-
[30]
Vera Soboleva, Aibek Alanov, Andrey Kuznetsov, and Konstantin Sobolev. T-lora: Single image diffusion model customization without overfitting.arXiv preprint arXiv:2507.05964, 2025. 2
-
[31]
Styledrop: Text-to-image synthesis of any style.Advances in Neural Information Pro- cessing Systems, 36:66860–66889, 2023
Kihyuk Sohn, Lu Jiang, Jarred Barber, Kimin Lee, Nataniel Ruiz, Dilip Krishnan, Huiwen Chang, Yuanzhen Li, Irfan Essa, Michael Rubinstein, et al. Styledrop: Text-to-image synthesis of any style.Advances in Neural Information Pro- cessing Systems, 36:66860–66889, 2023. 1, 6
2023
-
[32]
Styledrop: Text-to-image generation in any style.arXiv preprint arXiv:2306.00983,
Kihyuk Sohn, Nataniel Ruiz, Kimin Lee, Daniel Castro Chin, Irina Blok, Huiwen Chang, Jarred Barber, Lu Jiang, Glenn Entis, Yuanzhen Li, et al. Styledrop: Text-to-image generation in any style.arXiv preprint arXiv:2306.00983,
-
[33]
Xun Wu, Shaohan Huang, and Furu Wei. Mixture of lora experts.arXiv preprint arXiv:2404.13628, 2024. 2 10 OrthoFuse: Training-free Riemannian Fusion of Orthogonal Style-Concept Adapters for Diffusion Models Supplementary Material A. Smoothness In this section, we prove that the set ofGSorthogonal ma- trices form a smooth manifold using a slightly different...
-
[34]
A<concept> <superclass>in jungle in<style>style
=A 1ΩA⊤ 1 =A 1 log(A⊤ 1A2)A⊤ 1. Finally, we obtain: γA⊤ 1 ,A⊤ 2 (t) = exp tlog(A 2A⊤ 1) A1 = = exp tA1 log(A⊤ 1A2)A⊤ 1 A1 = =A1 exp tlog(A⊤ 1A2) A⊤ 1A1 = =A1 exp tlog(A⊤ 1A2) =γ A1 ,A2 (t). (21) C. Proof of Proposition 1 Proof.Utilizing eigendecomposition ofB(t) B(t) =UΛU ∗,Λ = diag(x 1+iy1, . . . , xn+iyn),(22) 4 satisfying|x i|2 +|y i|2 = 1. Since the e...
-
[35]
Conversion to skew-symmetric generators using the Cayley parameterization
-
[36]
Spectral decomposition ofB ⊤ S BC
-
[37]
Logarithmic interpolation in the Lie algebra
-
[38]
Algorithm 1OrthoFuse merging Require:D C, DS
Exponential map back to the orthogonal group The corresponding pseudocode for a single block is shown below. Algorithm 1OrthoFuse merging Require:D C, DS. 1:K C = DC −D⊤ C 2 ;K S = DS −D⊤ S 2 ; 2:B C =torch.linalg.solve((I−K C)(I+K C)); BS =torch.linalg.solve((I−K S)(I+K S)); 3:Λ, U=torch.linalg.eig(B ⊤ S BC); 4:Λ log = log(Λ).imag·i; 5:B t =B Ctorch.lina...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.