Recognition: 2 theorem links
· Lean TheoremETR: Entropy Trend Reward for Efficient Chain-of-Thought Reasoning
Pith reviewed 2026-05-10 19:49 UTC · model grok-4.3
The pith
Rewarding downward trends in uncertainty during reasoning produces shorter chain-of-thought traces with higher accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
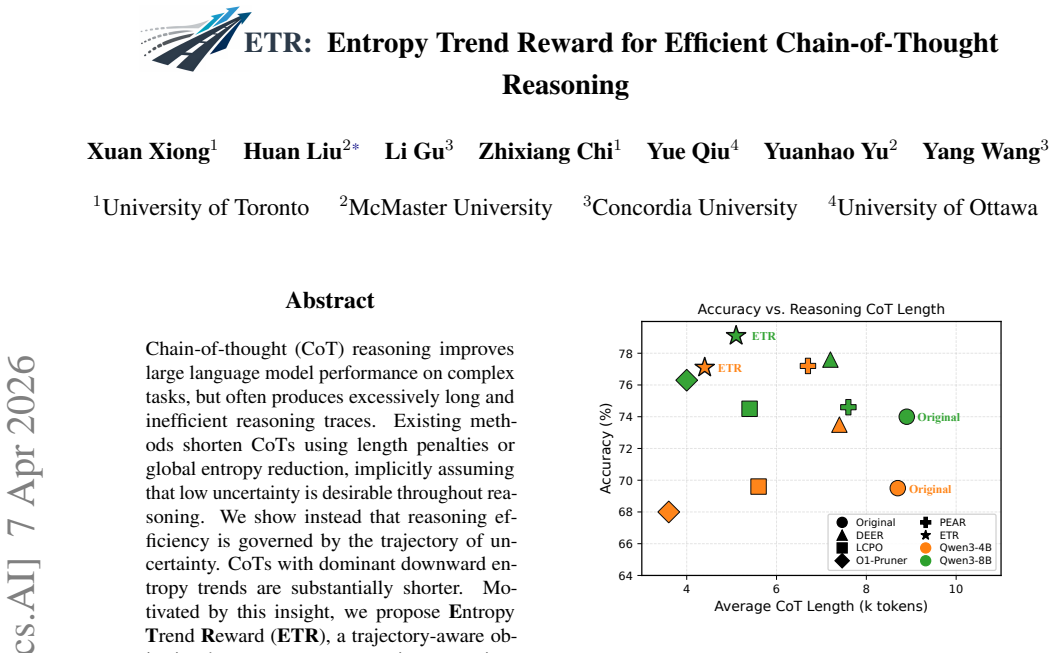
CoTs with dominant downward entropy trends are substantially shorter. Motivated by this observation, Entropy Trend Reward (ETR) is introduced as a trajectory-aware objective that encourages progressive uncertainty reduction while allowing limited local exploration; when integrated into GRPO, ETR produces a superior accuracy-efficiency tradeoff, improving DeepSeek-R1-Distill-7B by 9.9% accuracy while cutting CoT length by 67% across four benchmarks.
What carries the argument
Entropy Trend Reward (ETR), a scalar added to the policy gradient that scores each reasoning sequence according to the net direction and consistency of its entropy trajectory rather than the absolute entropy at any step.
Load-bearing premise
The observed correlation between dominant downward entropy trends and shorter CoTs is causal, and the ETR formulation can be stably optimized inside GRPO without producing unmeasured side effects on other model behaviors.
What would settle it
Train a model with ETR, then evaluate on a fresh benchmark set never used in optimization and check whether the length reduction and accuracy gain both disappear.
Figures






read the original abstract
Chain-of-thought (CoT) reasoning improves large language model performance on complex tasks, but often produces excessively long and inefficient reasoning traces. Existing methods shorten CoTs using length penalties or global entropy reduction, implicitly assuming that low uncertainty is desirable throughout reasoning. We show instead that reasoning efficiency is governed by the trajectory of uncertainty. CoTs with dominant downward entropy trends are substantially shorter. Motivated by this insight, we propose Entropy Trend Reward (ETR), a trajectory-aware objective that encourages progressive uncertainty reduction while allowing limited local exploration. We integrate ETR into Group Relative Policy Optimization (GRPO) and evaluate it across multiple reasoning models and challenging benchmarks. ETR consistently achieves a superior accuracy-efficiency tradeoff, improving DeepSeek-R1-Distill-7B by 9.9% in accuracy while reducing CoT length by 67% across four benchmarks. Code is available at https://github.com/Xuan1030/ETR
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that chain-of-thought (CoT) reasoning efficiency is governed by the trajectory of uncertainty rather than global low entropy or length penalties. It observes that CoTs exhibiting dominant downward entropy trends are substantially shorter, proposes the Entropy Trend Reward (ETR) as a trajectory-aware objective that encourages progressive uncertainty reduction while permitting limited local exploration, integrates ETR into Group Relative Policy Optimization (GRPO), and reports that this yields a superior accuracy-efficiency tradeoff, including a 9.9% accuracy gain and 67% CoT length reduction for DeepSeek-R1-Distill-7B across four benchmarks.
Significance. If the core observational insight holds and the reported gains can be causally attributed to the entropy-trend mechanism rather than unmeasured GRPO factors, the work would provide a principled alternative to existing length-penalty or global-entropy methods for training efficient reasoning models. The public code release supports reproducibility and allows direct testing of the claimed tradeoff.
major comments (2)
- [Abstract] Abstract: The central claim that 'CoTs with dominant downward entropy trends are substantially shorter' motivates the entire ETR objective, yet the abstract supplies no definition of entropy computation, no quantification of 'dominant downward trends,' and no controls for confounders such as task difficulty or token-level calibration. Without these, the correlation cannot be assessed as causal, undermining attribution of the 9.9% accuracy and 67% length gains specifically to ETR.
- [Experiments] Experiments section: The reported improvements on DeepSeek-R1-Distill-7B and other models lack ablations that isolate the trend component of ETR from baseline GRPO hyperparameters, length penalties, or global entropy terms. This omission makes it impossible to determine whether the accuracy-efficiency tradeoff arises from the proposed trajectory-aware reward or from other unmeasured training dynamics.
minor comments (1)
- [Abstract] The abstract states that code is available at a GitHub link, but the manuscript does not include a reproducibility checklist or details on random seeds, hyperparameter ranges, or exact entropy-estimation procedure used in the reported runs.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, providing clarifications and committing to specific revisions that will strengthen the presentation of the entropy trend insight and the attribution of results to ETR.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'CoTs with dominant downward entropy trends are substantially shorter' motivates the entire ETR objective, yet the abstract supplies no definition of entropy computation, no quantification of 'dominant downward trends,' and no controls for confounders such as task difficulty or token-level calibration. Without these, the correlation cannot be assessed as causal, undermining attribution of the 9.9% accuracy and 67% length gains specifically to ETR.
Authors: We agree that the abstract, as a high-level summary, omits technical specifics that would aid immediate assessment of the claim. Entropy is computed as the mean per-token entropy obtained from the model's softmax probabilities at each generation step. A dominant downward trend is quantified as a trajectory whose entropy sequence has a negative linear-regression slope and in which more than 50% of consecutive step pairs exhibit entropy reduction. Task difficulty is controlled by evaluating on four benchmarks that span a range of complexities under identical prompting and decoding settings; token-level calibration effects are mitigated by reporting results across multiple model families. We will revise the abstract to incorporate concise definitions and a brief statement on controls, while moving fuller methodological detail to Section 3. This change directly addresses the concern about causal attribution. revision: yes
-
Referee: [Experiments] Experiments section: The reported improvements on DeepSeek-R1-Distill-7B and other models lack ablations that isolate the trend component of ETR from baseline GRPO hyperparameters, length penalties, or global entropy terms. This omission makes it impossible to determine whether the accuracy-efficiency tradeoff arises from the proposed trajectory-aware reward or from other unmeasured training dynamics.
Authors: This observation is correct and highlights a genuine gap in the current experimental design. While the manuscript compares ETR-augmented GRPO against vanilla GRPO, it does not include explicit variants that apply only length penalties or global entropy minimization inside the same GRPO framework. We will add these ablations in the revised experiments section: (i) GRPO with a standard length penalty, (ii) GRPO with a global entropy term, and (iii) a non-trend ETR variant that rewards only average entropy. The new results will quantify the incremental benefit of the trajectory-aware component and thereby strengthen the causal link between the entropy-trend mechanism and the reported accuracy-efficiency gains. revision: yes
Circularity Check
No circularity; ETR is an empirically motivated reward whose gains are measured outcomes, not definitional
full rationale
The paper first reports an empirical correlation (downward entropy trends coincide with shorter CoTs) from existing model outputs, then defines ETR to encourage that trajectory inside GRPO, and finally measures accuracy and length on held-out benchmarks. None of these steps reduces to a self-definition, a fitted parameter renamed as a prediction, or a self-citation chain; the accuracy lift and length reduction are downstream empirical results rather than tautological consequences of the reward equation itself.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Reasoning efficiency is governed by the trajectory of uncertainty rather than absolute uncertainty levels throughout the trace.
invented entities (1)
-
Entropy Trend Reward (ETR)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We define the step-wise entropy change as Δ_t = H_{t-1} − H_t ... S_t = γ S_{t-1} + Δ_t ... R_entropy(o) = sum_{t=2}^T S_t = sum α_t Δ_t with α_t = 1−γ^{T−t+1}/(1−γ)
-
IndisputableMonolith/Foundation/ArrowOfTime.leanz_monotone_absolute echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
reasoning efficiency is governed by the trajectory of uncertainty. CoTs with dominant downward entropy trends are substantially shorter
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Evaluating large language models trained on code. Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shi- rong Ma, Peiyi Wang, Xiao Bi, and 1 others. 2025. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948. Zhiwei He, Tian Liang, Jiahao Xu, Qiuzhi Liu, Xing...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
InThe Twelfth Inter- national Conference on Learning Representations
Let’s verify step by step. InThe Twelfth Inter- national Conference on Learning Representations. Tengxiao Liu, Qipeng Guo, Xiangkun Hu, Cheng Ji- ayang, Yue Zhang, Xipeng Qiu, and Zheng Zhang
-
[3]
O1-pruner: Length-harmonizing fine-tuning for o1-like reasoning pruning.ArXiv, abs/2501.12570, 2025
Can language models learn to skip steps?Ad- vances in Neural Information Processing Systems, 37:45359–45385. Haotian Luo, Li Shen, Haiying He, Yibo Wang, Shi- wei Liu, Wei Li, Naiqiang Tan, Xiaochun Cao, and Dacheng Tao. 2025. O1-pruner: Length- harmonizing fine-tuning for o1-like reasoning prun- ing.arXiv preprint arXiv:2501.12570. Wenjie Ma, Jingxuan He...
-
[4]
Stop Overthinking: A Survey on Efficient Reasoning for Large Language Models
Stop overthinking: A survey on efficient rea- soning for large language models.arXiv preprint arXiv:2503.16419. Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, and 1 others. 2022. Chain-of-thought prompting elic- its reasoning in large language models.Advances in neural information processing systems, 35:248...
work page internal anchor Pith review arXiv 2022
-
[5]
Since the digits can only be 0 or 2, the sum will be 2 times the number of 2s in the number
Then, for divisibility by 3, the sum of the digits has to be a multiple of 3. Since the digits can only be 0 or 2, the sum will be 2 times the number of 2s in the number. So the number of 2s has to be a multiple of 3. Therefore, the number must have 3, 6, 9, etc., number of 2s. But since we want the smallest such number, probably 3 twos. But also, the num...
2000
-
[6]
2200: sum is 2+2=4, no
2000: sum is 2, no. 2200: sum is 2+2=4, no. 2020: sum is 2+2=4, no. 2220: sum is 2+2+2=6, which is divisible by 3. So 2220 is the first one. Wait, but is there a smaller number? Like, maybe a number with fewer digits? 2220 is four digits. Is there a three-digit number? The three-digit numbers ending with 0 are 200, 220, 200. But their digit sums are 2, 4,...
2000
-
[7]
Therefore, the answer is 2220
So 2220 is the first. Therefore, the answer is 2220. Wait, but let me check if there’s a number with more digits but smaller in value. Wait, no, because 2220 is four digits. Any number with more digits would be larger. So I think 2220 is the answer. But let me confirm by dividing 2220 by 30. 30 times 74 is 2220. Yes. So I think that’s it. **Final Answer**...
-
[8]
The reaction is Ca2+ +EDTA 4− ⇌ Ca-EDTA complex
-
[9]
The formation constant Kf is given by Kf = [Ca-EDTA] [Ca2+][EDTA4−]
-
[10]
Since the complex is stochiometric, the concentra- tions of Ca2+ and EDTA4− are equal, denoted asc
-
[11]
The total concentration of the complex is 0.02 M, soK f = 0.02 c2
-
[12]
Solving forc 2:c 2 = 0.02 5×1010 = 4×10 −13
-
[13]
Thus, the concentration of calcium ions is 6.3×10 −7 M
Taking the square root: c= √ 4×10 −13 = 2×10 −6.5 ≈6.3×10 −7. Thus, the concentration of calcium ions is 6.3×10 −7 M. A 19
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.