Recognition: 2 theorem links
· Lean TheoremUnderstanding Performance Gap Between Parallel and Sequential Sampling in Large Reasoning Models
Pith reviewed 2026-05-10 18:31 UTC · model grok-4.3
The pith
The performance gap between parallel and sequential sampling in large reasoning models is primarily due to reduced exploration in sequential approaches.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
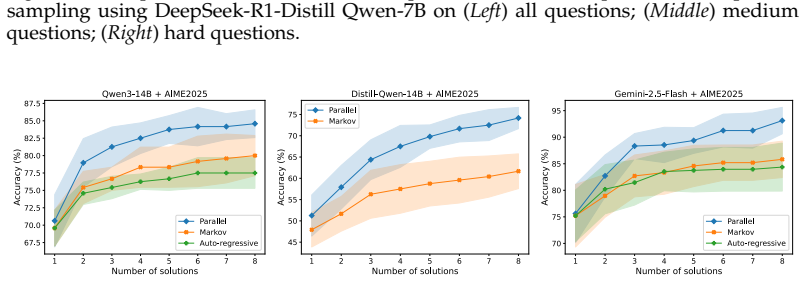
Parallel sampling outperforms sequential sampling in large reasoning models on math and coding tasks despite sequential sampling's greater power. Controlled experiments on Qwen3, DeepSeek-R1 distilled models, and Gemini 2.5 isolate the effects of the aggregator operator, context length, and conditioning on prior answers. The results indicate that aggregation and context length are not the main drivers, while conditioning leads to less exploration and accounts for most of the observed performance difference.
What carries the argument
The hypothesis that sequential sampling reduces exploration by conditioning each new sample on previous answers, isolated through targeted comparisons against aggregator and context-length effects.
If this is right
- Sequential sampling performance can be improved by introducing mechanisms that maintain answer diversity across steps.
- Parallel sampling remains the more reliable strategy for maximizing solution quality on challenging reasoning problems.
- The effective search space in sequential inference is narrower than the model's capacity would suggest because of conditioning.
- Inference pipelines for large reasoning models should prioritize independent sampling paths when exploration is the bottleneck.
Where Pith is reading between the lines
- This points to a possible need for training methods that encourage diverse reasoning trajectories usable in sequential chains.
- Hybrid sampling strategies that begin with parallel draws before chaining could combine the strengths of both approaches.
- The finding may extend to other multi-step reasoning settings where prior outputs risk narrowing the search space.
Load-bearing premise
The chosen empirical tests on Qwen3, DeepSeek-R1 distilled models, and Gemini 2.5 across math and coding domains sufficiently isolate lack of exploration from confounding factors such as prompt formatting or aggregation details.
What would settle it
An experiment that increases exploration in sequential sampling, for example by raising temperature or adding diversity penalties while holding context length and aggregator fixed, and measures whether the performance gap with parallel sampling closes.
Figures

































read the original abstract
Large Reasoning Models (LRMs) have shown remarkable performance on challenging questions, such as math and coding. However, to obtain a high quality solution, one may need to sample more than once. In principal, there are two sampling strategies that can be composed to form more complex processes: sequential sampling and parallel sampling. In this paper, we first compare these two approaches with rigor, and observe, aligned with previous works, that parallel sampling seems to outperform sequential sampling even though the latter should have more representation power. To understand the underline reasons, we make three hypothesis on the reason behind this behavior: (i) parallel sampling outperforms due to the aggregator operator; (ii) sequential sampling is harmed by needing to use longer contexts; (iii) sequential sampling leads to less exploration due to conditioning on previous answers. The empirical evidence on various model families and sizes (Qwen3, DeepSeek-R1 distilled models, Gemini 2.5) and question domains (math and coding) suggests that the aggregation and context length do not seem to be the main culprit behind the performance gap. In contrast, the lack of exploration seems to play a considerably larger role, and we argue that this is one main cause for the performance gap.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper compares parallel and sequential sampling in Large Reasoning Models (LRMs) on math and coding tasks. It observes that parallel sampling outperforms sequential sampling despite the latter's greater representational power. The authors test three hypotheses for the gap—(i) aggregator operator differences, (ii) harm from longer contexts in sequential sampling, and (iii) reduced exploration from conditioning on prior answers—via ablations on Qwen3, DeepSeek-R1 distilled models, and Gemini 2.5. They conclude that lack of exploration is the primary cause.
Significance. If the central claim holds, the work would offer useful guidance on inference strategies for LRMs by emphasizing the value of maintaining answer diversity. The multi-model and multi-domain empirical evaluation is a strength that broadens the applicability of the observations.
major comments (2)
- [Abstract] The isolation of lack of exploration as the main cause (hypothesis iii) rests on ablations showing that aggregator choice and context length do not close the gap. However, these ablations are described without quantitative details, error bars, or explicit metrics on performance differences, leaving the elimination argument weakly supported as noted in the abstract's summary of findings.
- [Empirical evidence sections] No direct, controlled measurement of exploration (e.g., entropy of answer distributions, fraction of unique correct solutions, or trajectory diversity) is reported while holding prompt template, temperature, and sample count fixed and disabling conditioning in the sequential arm. This makes the central claim rest on indirect evidence by elimination, allowing confounds such as compounding early errors to remain unruled out.
minor comments (2)
- [Abstract] The abstract refers to 'various model families and sizes' and 'question domains' but does not list the precise model sizes, number of questions per domain, or sampling parameters used in the comparisons.
- [Throughout] Consider including statistical significance tests or variance estimates alongside the reported performance gaps to allow readers to assess the reliability of the observed differences across models.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback on our manuscript. We address each major comment point by point below, providing clarifications and indicating revisions where they strengthen the presentation of our results without altering the core findings.
read point-by-point responses
-
Referee: [Abstract] The isolation of lack of exploration as the main cause (hypothesis iii) rests on ablations showing that aggregator choice and context length do not close the gap. However, these ablations are described without quantitative details, error bars, or explicit metrics on performance differences, leaving the elimination argument weakly supported as noted in the abstract's summary of findings.
Authors: We agree that the ablation results would be more convincing with explicit quantitative support. In the revised manuscript we have expanded the relevant sections and tables to report exact performance deltas (including means and standard deviations across repeated runs) for each hypothesis test on Qwen3, DeepSeek-R1, and Gemini 2.5. These additions make the elimination argument concrete and show that neither aggregator choice nor context length accounts for the observed gap. revision: yes
-
Referee: [Empirical evidence sections] No direct, controlled measurement of exploration (e.g., entropy of answer distributions, fraction of unique correct solutions, or trajectory diversity) is reported while holding prompt template, temperature, and sample count fixed and disabling conditioning in the sequential arm. This makes the central claim rest on indirect evidence by elimination, allowing confounds such as compounding early errors to remain unruled out.
Authors: We acknowledge the value of direct exploration metrics. Our experimental design already holds prompt template, temperature, and sample count fixed; the only systematic difference between arms is the conditioning step inherent to sequential sampling. In the revision we have added direct measurements of answer diversity (fraction of unique correct solutions) and entropy of the generated answer distributions under these controlled conditions. These metrics confirm substantially lower exploration in the sequential case. On the potential confound of compounding early errors, the context-length ablation already evaluates performance when long histories are supplied, and the gap remains; this indicates that reduced exploration, rather than error accumulation alone, is the dominant factor. revision: partial
Circularity Check
No significant circularity: purely empirical hypothesis testing
full rationale
The paper conducts an empirical study comparing parallel and sequential sampling in LRMs. It states three hypotheses about the performance gap (aggregator choice, context length, and reduced exploration) and evaluates them via experiments across Qwen3, DeepSeek-R1, and Gemini 2.5 on math/coding tasks. Conclusions are drawn from observed performance differences after ablating specific factors. No equations, derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the abstract or described content. The argument relies on direct experimental comparisons rather than any self-referential reduction, rendering the chain self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Performance differences between sampling strategies can be measured reliably via accuracy on math and coding benchmarks
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The empirical evidence ... suggests that the aggregation and context length do not seem to be the main culprit ... the lack of exploration seems to play a considerably larger role
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
induction heads ... pattern copying behavior
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Aime 2025.https://artofproblemsolving.com/wiki/index.php/AIME Problems and Solutions,
AoPS. Aime 2025.https://artofproblemsolving.com/wiki/index.php/AIME Problems and Solutions,
2025
-
[2]
Jiefeng Chen, Jie Ren, Xinyun Chen, Chengrun Yang, Ruoxi Sun, Jinsung Yoon, and Sercan¨O Arık. Sets: Leveraging self-verification and self-correction for improved test-time scaling. arXiv preprint arXiv:2501.19306,
-
[3]
Teaching Large Language Models to Self-Debug
Xinyun Chen, Maxwell Lin, Nathanael Sch¨arli, and Denny Zhou. Teaching large language models to self-debug.arXiv preprint arXiv:2304.05128,
work page internal anchor Pith review arXiv
-
[4]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Enhancing chat language models by scaling high-quality instructional conversations
Ning Ding, Yulin Chen, Bokai Xu, Yujia Qin, Zhi Zheng, Shengding Hu, Zhiyuan Liu, Maosong Sun, and Bowen Zhou. Enhancing chat language models by scaling high-quality instructional conversations.arXiv preprint arXiv:2305.14233,
-
[6]
Xidong Feng, Ziyu Wan, Muning Wen, Stephen Marcus McAleer, Ying Wen, Weinan Zhang, and Jun Wang. Alphazero-like tree-search can guide large language model decoding and training.arXiv preprint arXiv:2309.17179,
-
[7]
Inverse scaling in test-time compute.arXiv preprint arXiv:2507.14417, 2025
Aryo Pradipta Gema, Alexander H¨agele, Runjin Chen, Andy Arditi, Jacob Goldman-Wetzler, Kit Fraser-Taliente, Henry Sleight, Linda Petrini, Julian Michael, Beatrice Alex, et al. Inverse scaling in test-time compute.arXiv preprint arXiv:2507.14417,
-
[8]
Does thinking more always help? mirage of test-time scaling in reasoning models,
Soumya Suvra Ghosal, Souradip Chakraborty, Avinash Reddy, Yifu Lu, Mengdi Wang, Dinesh Manocha, Furong Huang, Mohammad Ghavamzadeh, and Amrit Singh Bedi. Does thinking more always help? understanding test-time scaling in reasoning models. arXiv preprint arXiv:2506.04210,
-
[9]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Jingcheng Hu, Yinmin Zhang, Shijie Shang, Xiaobo Yang, Yue Peng, Zhewei Huang, Hebin Zhou, Xin Wu, Jie Cheng, Fanqi Wan, et al. Pacore: Learning to scale test-time compute with parallel coordinated reasoning.arXiv preprint arXiv:2601.05593,
-
[11]
Large Language Models Cannot Self-Correct Reasoning Yet
Jie Huang, Xinyun Chen, Swaroop Mishra, Huaixiu Steven Zheng, Adams Wei Yu, Xinying Song, and Denny Zhou. Large language models cannot self-correct reasoning yet.arXiv preprint arXiv:2310.01798,
work page internal anchor Pith review arXiv
-
[12]
Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, et al. Openai o1 system card. arXiv preprint arXiv:2412.16720,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Ar- mando Solar-Lezama, Koushik Sen, and Ion Stoica. Livecodebench: Holistic and contami- nation free evaluation of large language models for code.arXiv preprint arXiv:2403.07974,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Gemini Embedding: Generalizable Embeddings from Gemini
10 Preprint. Under review. Jinhyuk Lee, Feiyang Chen, Sahil Dua, Daniel Cer, Madhuri Shanbhogue, Iftekhar Naim, Gustavo Hern´andez ´Abrego, Zhe Li, Kaifeng Chen, Henrique Schechter Vera, et al. Gemini embedding: Generalizable embeddings from gemini.arXiv preprint arXiv:2503.07891,
work page internal anchor Pith review arXiv
-
[15]
Dacheng Li, Shiyi Cao, Chengkun Cao, Xiuyu Li, Shangyin Tan, Kurt Keutzer, Jiarong Xing, Joseph E Gonzalez, and Ion Stoica. S*: Test time scaling for code generation.arXiv preprint arXiv:2502.14382, 1(2), 2025a. Raymond Li, Loubna Ben Allal, Yangtian Zi, Niklas Muennighoff, Denis Kocetkov, Cheng- hao Mou, Marc Marone, Christopher Akiki, Jia Li, Jenny Chim...
-
[16]
Zichong Li, Xinyu Feng, Yuheng Cai, Zixuan Zhang, Tianyi Liu, Chen Liang, Weizhu Chen, Haoyu Wang, and Tuo Zhao. Llms can generate a better answer by aggregating their own responses.arXiv preprint arXiv:2503.04104, 2025b. Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming...
-
[17]
s1: Simple test-time scaling
Niklas Muennighoff, Zitong Yang, Weijia Shi, Xiang Lisa Li, Li Fei-Fei, Hannaneh Hajishirzi, Luke Zettlemoyer, Percy Liang, Emmanuel Cand `es, and Tatsunori B Hashimoto. s1: Simple test-time scaling. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp. 20286–20332,
2025
-
[18]
AlphaEvolve: A coding agent for scientific and algorithmic discovery
Alexander Novikov, Ng ˆan V ˜u, Marvin Eisenberger, Emilien Dupont, Po-Sen Huang, Adam Zsolt Wagner, Sergey Shirobokov, Borislav Kozlovskii, Francisco JR Ruiz, Abbas Mehrabian, et al. Alphaevolve: A coding agent for scientific and algorithmic discovery. arXiv preprint arXiv:2506.13131,
work page internal anchor Pith review arXiv
-
[19]
https://transformer-circuits.pub/2022/in- context-learning-and-induction-heads/index.html. OpenAI. New embedding models and api updates.https://openai.com/index/new-embedding- models-and-api-updates/,
2022
-
[20]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathe- matical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Deepseekmath-v2: Towards self-verifiable mathematical reasoning,
Zhihong Shao, Yuxiang Luo, Chengda Lu, ZZ Ren, Jiewen Hu, Tian Ye, Zhibin Gou, Shirong Ma, and Xiaokang Zhang. Deepseekmath-v2: Towards self-verifiable mathematical reasoning.arXiv preprint arXiv:2511.22570,
-
[23]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling llm test-time compute opti- mally can be more effective than scaling model parameters.arXiv preprint arXiv:2408.03314,
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
11 Preprint. Under review. Xiaoyu Tian, Sitong Zhao, Haotian Wang, Shuaiting Chen, Yunjie Ji, Yiping Peng, Han Zhao, and Xiangang Li. Think twice: Enhancing llm reasoning by scaling multi-round test-time thinking.arXiv preprint arXiv:2503.19855,
-
[25]
Siddarth Venkatraman, Vineet Jain, Sarthak Mittal, Vedant Shah, Johan Obando-Ceron, Yoshua Bengio, Brian R Bartoldson, Bhavya Kailkhura, Guillaume Lajoie, Glen Berseth, et al. Recursive self-aggregation unlocks deep thinking in large language models.arXiv preprint arXiv:2509.26626,
-
[26]
Jian Wang, Boyan Zhu, Chak Tou Leong, Yongqi Li, and Wenjie Li. Scaling over scaling: Ex- ploring test-time scaling pareto in large reasoning models.arXiv preprint arXiv:2505.20522, 2025a. Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in la...
-
[27]
Yinjie Wang, Ling Yang, Ye Tian, Ke Shen, and Mengdi Wang. Co-evolving llm coder and unit tester via reinforcement learning.arXiv preprint arXiv:2506.03136, 2025b. Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models.Advances in neural i...
-
[28]
Hao Wen, Yifan Su, Feifei Zhang, Yunxin Liu, Yunhao Liu, Ya-Qin Zhang, and Yuanchun Li. Parathinker: Native parallel thinking as a new paradigm to scale llm test-time compute. arXiv preprint arXiv:2509.04475,
-
[29]
Huajian Xin, ZZ Ren, Junxiao Song, Zhihong Shao, Wanjia Zhao, Haocheng Wang, Bo Liu, Liyue Zhang, Xuan Lu, Qiushi Du, et al. Deepseek-prover-v1. 5: Harnessing proof assistant feedback for reinforcement learning and monte-carlo tree search.arXiv preprint arXiv:2408.08152,
-
[30]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
Wenting Zhao, Pranjal Aggarwal, Swarnadeep Saha, Asli Celikyilmaz, Jason Weston, and Ilia Kulikov. The majority is not always right: Rl training for solution aggregation.arXiv preprint arXiv:2509.06870,
-
[32]
Parallel-r1: Towards parallel thinking via reinforcement learning
Tong Zheng, Hongming Zhang, Wenhao Yu, Xiaoyang Wang, Runpeng Dai, Rui Liu, Huiwen Bao, Chengsong Huang, Heng Huang, and Dong Yu. Parallel-r1: Towards parallel thinking via reinforcement learning.arXiv preprint arXiv:2509.07980,
-
[33]
Under review
12 Preprint. Under review. A Related Work Our work is related to the field of inference test-time scaling in LLMs, especially for those Large Reasoning Models (LRMs). Sequential inference scaling.Sequential test-time scaling typically means that the later com- putations rely on earlier ones. With the success of reinforcement learning (Schulman et al., 201...
2017
-
[34]
parallel thinking
in LRMs, this refers to scaling the number of tokens in the reasoning traces, e.g., chains-of-thoughts (Wei et al., 2022). Jaech et al. (2024); Guo et al. (2025); Comanici et al. (2025); Muennighoff et al. (2025) showed that with increasing thinking token budget in the sequential reasoning trace, LRMs also demonstrate increasing perfor- mance gains during...
2022
-
[35]
Tunnel Vision
combines both parallel and sequential sampling to evolve the coding solutions for scientific and algorithmic discovery. Comparing parallel/sequential sampling.Huang et al. (2023) represents the early explo- ration by comparing sequential and parallel sampling in LLM reasoning. They claim that LLMs cannot self-correct their previous solutions in sequential...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.