Recognition: 2 theorem links
· Lean TheoremHumANDiff: Articulated Noise Diffusion for Motion-Consistent Human Video Generation
Pith reviewed 2026-05-10 20:18 UTC · model grok-4.3
The pith
Sampling noise on 3D human body surfaces lets diffusion models generate motion-consistent videos.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
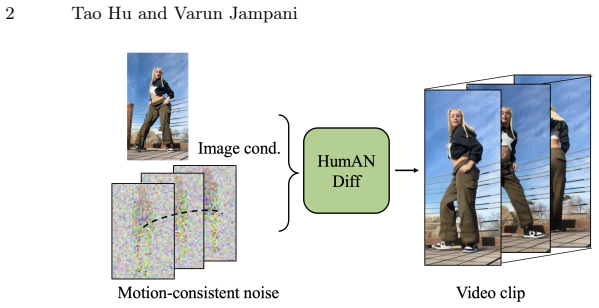
HumANDiff replaces random Gaussian noise with 3D articulated noise sampled on the dense surface manifold of a statistical human body template. This noise inherits body topology priors for spatially and temporally consistent sampling. The training objective is extended to jointly predict pixel appearances and physical motions from the noise, while a geometric motion consistency loss defined in the articulated noise space enforces physical consistency across frames. The resulting fine-tuned models support controllable human video generation, including image-to-video synthesis, without any changes to the underlying diffusion architecture.
What carries the argument
Articulated motion-consistent noise sampling on the dense surface manifold of a statistical human body template, which correlates spatiotemporal noise distributions and supplies body topology priors for consistent motion control.
If this is right
- Existing video diffusion models can be adapted for high-fidelity human video synthesis through fine-tuning alone.
- Image-to-video generation becomes possible inside one framework with built-in motion control and no extra modules.
- Motion-dependent effects such as clothing wrinkles arise directly from the joint appearance-motion objective.
- The approach remains model-agnostic and works with diverse clothing styles while preserving temporal consistency.
Where Pith is reading between the lines
- The same surface-manifold noise idea could be tested on other articulated objects such as animals or robots by swapping the body template.
- Adding explicit physics simulation on top of the noise sampling might further reduce implausible deformations that the current method still produces.
- Because the method needs no architecture changes, it could be combined with future advances in base video diffusion models to improve human results without re-engineering.
Load-bearing premise
That noise sampled on the surface of a statistical human body template will automatically encode the real dynamics and physics of human motion and clothing deformation.
What would settle it
Videos in which clothing fails to wrinkle or stretch in ways that match the body motion, or in which limbs and clothing exhibit temporal jitter or intersections absent from real footage.
Figures










read the original abstract
Despite tremendous recent progress in human video generation, generative video diffusion models still struggle to capture the dynamics and physics of human motions faithfully. In this paper, we propose a new framework for human video generation, HumANDiff, which enhances the human motion control with three key designs: 1) Articulated motion-consistent noise sampling that correlates the spatiotemporal distribution of latent noise and replaces the unstructured random Gaussian noise with 3D articulated noise sampled on the dense surface manifold of a statistical human body template. It inherits body topology priors for spatially and temporally consistent noise sampling. 2) Joint appearance-motion learning that enhances the standard training objective of video diffusion models by jointly predicting pixel appearances and corresponding physical motions from the articulated noises. It enables high-fidelity human video synthesis, e.g., capturing motion-dependent clothing wrinkles. 3) Geometric motion consistency learning that enforces physical motion consistency across frames via a novel geometric motion consistency loss defined in the articulated noise space. HumANDiff enables scalable controllable human video generation by fine-tuning video diffusion models with articulated noise sampling. Consequently, our method is agnostic to diffusion model design, and requires no modifications to the model architecture. During inference, HumANDiff enables image-to-video generation within a single framework, achieving intrinsic motion control without requiring additional motion modules. Extensive experiments demonstrate that our method achieves state-of-the-art performance in rendering motion-consistent, high-fidelity humans with diverse clothing styles. Project page: https://taohuumd.github.io/projects/HumANDiff/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces HumANDiff, a framework for human video generation via fine-tuning of video diffusion models. It proposes three components: (1) articulated motion-consistent noise sampling that replaces unstructured Gaussian noise with 3D noise sampled on the dense surface manifold of a statistical human body template to inherit topology priors for spatiotemporal consistency; (2) joint appearance-motion learning that augments the diffusion training objective to predict both pixel appearances and physical motions; and (3) a geometric motion consistency loss defined in the articulated noise space to enforce cross-frame physical consistency. The method is architecture-agnostic, supports image-to-video generation intrinsically, and claims state-of-the-art performance in producing motion-consistent, high-fidelity human videos with diverse clothing styles.
Significance. If the empirical claims hold, the work would be significant for controllable video generation by showing how to inject 3D body topology priors directly into the noise process of existing diffusion models without architectural modifications or external motion modules. This could improve scalability and motion fidelity in human synthesis tasks, addressing a recognized limitation in current generative video models regarding faithful dynamics and clothing deformation.
major comments (3)
- [§3.1] §3.1: The articulated noise sampling is defined on the dense surface manifold of a statistical body template and claimed to capture spatiotemporal distributions for motion consistency. However, the construction supplies only topology priors; no derivation shows how this sampling encodes real motion dynamics or clothing physics (e.g., wrinkles, forces) without physics simulation or per-sequence fitting, which is load-bearing for the central claim of faithful dynamics.
- [§4] §4 (Experiments): The abstract and method claim SOTA results in motion consistency and high-fidelity rendering, but the provided description lacks explicit quantitative metrics (e.g., FVD, motion accuracy scores), ablation tables isolating each of the three components, or error analysis on unseen motions/complex clothing. Without these, the attribution of improvements to the articulated noise and geometric loss cannot be verified.
- [§3.3] §3.3: The geometric motion consistency loss is defined in the same articulated noise space as the sampling. This risks circularity: the loss operates on quantities constructed by the method itself rather than on independent physical quantities, so it is unclear whether it enforces true physical consistency or merely geometric self-consistency.
minor comments (2)
- [Abstract] The abstract states the method is 'agnostic to diffusion model design' and requires 'no modifications to the model architecture'; this strength should be highlighted with a concrete example of the base model used in experiments.
- [§3] Notation for the articulated noise (e.g., how the manifold sampling is parameterized) should be introduced earlier and used consistently in the loss definitions.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on HumANDiff. We address each major comment below, providing clarifications and indicating revisions to the manuscript where the points strengthen the presentation or evidence.
read point-by-point responses
-
Referee: [§3.1] The articulated noise sampling is defined on the dense surface manifold of a statistical body template and claimed to capture spatiotemporal distributions for motion consistency. However, the construction supplies only topology priors; no derivation shows how this sampling encodes real motion dynamics or clothing physics (e.g., wrinkles, forces) without physics simulation or per-sequence fitting, which is load-bearing for the central claim of faithful dynamics.
Authors: We appreciate this point. The articulated noise sampling is intended to replace unstructured Gaussian noise with a structured distribution that respects the fixed topology and articulation of the SMPL body template, thereby inducing correlated spatiotemporal noise patterns that aid the diffusion process in producing consistent motion. It does not claim to directly encode clothing physics or forces; those emerge from the combination of joint appearance-motion prediction (which learns motion-dependent appearance changes such as wrinkles) and the geometric consistency loss. We have revised §3.1 to explicitly state that the sampling supplies topological priors for consistency rather than a physics derivation, and we reference how the other two components enable the capture of dynamic effects during fine-tuning. revision: partial
-
Referee: [§4] The abstract and method claim SOTA results in motion consistency and high-fidelity rendering, but the provided description lacks explicit quantitative metrics (e.g., FVD, motion accuracy scores), ablation tables isolating each of the three components, or error analysis on unseen motions/complex clothing. Without these, the attribution of improvements to the articulated noise and geometric loss cannot be verified.
Authors: We agree that clear quantitative support and component-wise ablations are necessary to substantiate the claims. The full manuscript contains FVD, motion consistency, and user-study metrics in §4 along with some ablations, but we acknowledge the presentation could be more explicit. In the revision we will add a dedicated ablation table isolating the contribution of each component (noise sampling, joint prediction, and geometric loss), include motion accuracy scores on held-out sequences, and provide error analysis for complex clothing and unseen motions. These additions will directly address attribution. revision: yes
-
Referee: [§3.3] The geometric motion consistency loss is defined in the same articulated noise space as the sampling. This risks circularity: the loss operates on quantities constructed by the method itself rather than on independent physical quantities, so it is unclear whether it enforces true physical consistency or merely geometric self-consistency.
Authors: The loss is computed by comparing the predicted motion fields (derived from the diffusion model's output) projected back onto the fixed articulated template across frames. Because the template articulation is independent of the generated video content and the noise field is sampled once per sequence, the loss penalizes temporal inconsistencies in the body manifold coordinates. This is not purely self-referential; it enforces agreement with the physical joint structure encoded in the template. We have expanded §3.3 with a short derivation showing the correspondence between noise-space differences and 3D joint displacements, and we note that the loss is applied only during training to regularize the learned dynamics. revision: partial
Circularity Check
No significant circularity; method introduces independent sampling and loss designs
full rationale
The paper proposes three explicit new components—articulated noise sampling on a body template manifold, joint appearance-motion prediction, and a geometric consistency loss in noise space—for fine-tuning existing video diffusion models. No equations, derivations, or claims reduce the motion-consistency or fidelity improvements to quantities defined by the inputs themselves, nor do they rely on load-bearing self-citations or fitted parameters renamed as predictions. The SOTA performance is presented as an empirical outcome of the new designs rather than a tautological re-expression of prior quantities.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Video diffusion models can be fine-tuned by replacing unstructured Gaussian noise with structured noise sampled on a human body surface manifold without architectural changes.
- domain assumption Jointly predicting pixel appearance and physical motion from the same articulated noise improves fidelity of motion-dependent effects such as clothing wrinkles.
invented entities (1)
-
Articulated motion-consistent noise
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
replaces the unstructured random Gaussian noise with 3D articulated noise sampled on the dense surface manifold of a statistical human body template... geometric motion consistency loss defined in the articulated noise space
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
jointly predicting pixel appearances and corresponding physical motions from the articulated noises
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Github (2021),https://github
Easymocap - make human motion capture easier. Github (2021),https://github. com/zju3dv/EasyMocap6, 9
2021
-
[2]
Computer Graphics Forum38(2019) 4
Aberman, K., Shi, M., Liao, J., Lischinski, D., Chen, B., Cohen-Or, D.: Deep video-based performance cloning. Computer Graphics Forum38(2019) 4
2019
-
[3]
2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp
Bhunia, A.K., Khan, S.H., Cholakkal, H., Anwer, R.M., Laaksonen, J., Shah, M., Khan, F.S.: Person image synthesis via denoising diffusion model. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp. 5968–5976 (2022),https://api.semanticscholar.org/CorpusID:25376129110, 11
2023
-
[5]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Blattmann, A., Dockhorn, T., Kulal, S., Mendelevitch, D., Kilian, M., Lorenz, D., Levi, Y., English, Z., Voleti, V., Letts, A., et al.: Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets. arXiv preprint arXiv:2311.15127 (2023) 4
work page internal anchor Pith review arXiv 2023
-
[6]
Burgert, R., Xu, Y., Xian, W., Pilarski, O., Clausen, P., He, M., Ma, L., Deng, Y., Li, L., Mousavi, M., Ryoo, M., Debevec, P., Yu, N.: Go-with-the-flow: Motion- controllable video diffusion models using real-time warped noise. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2025),https://arxiv.org/abs/2501.08...
-
[7]
IEEE Transactions on Pat- tern Analysis and Machine Intelligence43(1), 172–186 (2019) 4
Cao, Z., Hidalgo, G., Simon, T., Wei, S.E., Sheikh, Y.: OpenPose: Realtime Multi- Person 2D Pose Estimation using Part Affinity Fields. IEEE Transactions on Pat- tern Analysis and Machine Intelligence43(1), 172–186 (2019) 4
2019
-
[8]
Chan, C., Ginosar, S., Zhou, T., Efros, A.A.: Everybody dance now. ICCV pp. 5932–5941 (2019) 4
2019
-
[9]
Chan, E., Lin, C.Z., Chan, M.A., Nagano, K., Pan, B., Mello, S.D., Gallo, O., Guibas, L.J., Tremblay, J., Khamis, S., Karras, T., Wetzstein, G.: Effi- cient geometry-aware 3d generative adversarial networks. ArXivabs/2112.07945 (2021) 4
-
[10]
ArXivabs/2504.03072 (2025),https://api.semanticscholar.org/CorpusID:2709646892, 5
Chang, P., Tang, J., Gross, M., Azevedo, V.C.: How i warped your noise: a temporally-correlated noise prior for diffusion models. ArXivabs/2504.03072 (2025),https://api.semanticscholar.org/CorpusID:2709646892, 5
-
[11]
Chefer, H., Singer, U., Zohar, A., Kirstain, Y., Polyak, A., Taigman, Y., Wolf, L., Sheynin, S.: Videojam: Joint appearance-motion representations for enhanced motion generation in video models. ArXivabs/2502.02492(2025),https://api. semanticscholar.org/CorpusID:2761076103, 7, 8
-
[12]
Chen,J.,Zhang,Y.,Kang,D.,Zhe,X.,Bao,L.,Lu,H.:Animatableneuralradiance fields from monocular rgb video. ArXivabs/2106.13629(2021) 4
-
[13]
Grigor’ev, A.K., Sevastopolsky, A., Vakhitov, A., Lempitsky, V.S.: Coordinate- based texture inpainting for pose-guided human image generation. CVPR pp. 12127–12136 (2019) 4
2019
-
[14]
Gu, J., Liu, L., Wang, P., Theobalt, C.: Stylenerf: A style-based 3d-aware generator for high-resolution image synthesis. ArXivabs/2110.08985(2021) 4 20 Tao Hu and Varun Jampani
-
[15]
AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning
Guo, Y., Yang, C., Rao, A., Liang, Z., Wang, Y., Qiao, Y., Agrawala, M., Lin, D., Dai, B.: AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning. arXiv preprint arXiv:2307.04725 (2023) 4
work page internal anchor Pith review arXiv 2023
-
[16]
In: CVPR
Güler, R.A., Neverova, N., Kokkinos, I.: Densepose: Dense human pose estimation in the wild. In: CVPR. pp. 7297–7306 (2018) 6
2018
-
[17]
In: NIPS (2017) 10
Heusel,M.,Ramsauer,H.,Unterthiner,T.,Nessler,B.,Hochreiter,S.:Ganstrained by a two time-scale update rule converge to a local nash equilibrium. In: NIPS (2017) 10
2017
-
[18]
Advances in Neural Information Processing Systems33(2020) 4
Ho, J., Jain, A., Abbeel, P.: Denoising Diffusion Probabilistic Models. Advances in Neural Information Processing Systems33(2020) 4
2020
-
[19]
Headnerf: A real-time nerf-based parametric head model.CoRR, abs/2112.05637, 2021
Hong, Y., Peng, B., Xiao, H., Liu, L., Zhang, J.: Headnerf: A real-time nerf-based parametric head model. ArXivabs/2112.05637(2021) 4
-
[20]
LoRA: Low-Rank Adaptation of Large Language Models
Hu, J.E., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Chen, W.: Lora: Low-rank adaptation of large language models. ArXivabs/2106.09685(2021), https://api.semanticscholar.org/CorpusID:23545800917
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[21]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2024) 2, 4, 11, 12
Hu, L., Gao, X., Zhang, P., Sun, K., Zhang, B., Bo, L.: Animate Anyone: Con- sistent and Controllable Image-to-Video Synthesis for Character Animation. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2024) 2, 4, 11, 12
2024
-
[22]
Animate anyone 2: High-fidelity character image animation with environment affordance,
Hu, L., Wang, G., Shen, Z., Gao, X., Meng, D., Zhuo, L., Zhang, P., Zhang, B., Bo, L.: Animate Anyone 2: High-Fidelity Character Image Animation with Envi- ronment Affordance. arXiv preprint arXiv:2502.06145 (2025) 4
-
[23]
3DV (2022) 4
Hu,T.,Yu,T.,Zheng,Z.,Zhang,H.,Liu,Y.,Zwicker,M.:Hvtr:Hybridvolumetric- textural rendering for human avatars. 3DV (2022) 4
2022
-
[24]
2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp
Hu, T., Hong, F., Liu, Z.: Surmo: Surface-based 4d motion modeling for dynamic human rendering. 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp. 6550–6560 (2024),https://api.semanticscholar.org/ CorpusID:2688194933, 7, 8
2024
-
[25]
In: ICCV (2021) 4
Hu, T., Sarkar, K., Liu, L., Zwicker, M., Theobalt, C.: Egorenderer: Rendering human avatars from egocentric camera images. In: ICCV (2021) 4
2021
-
[26]
IEEE Transactions on Visualization and Computer Graphics pp
Hu, T., Xu, H., Luo, L., Yu, T., Zheng, Z., Zhang, H., Liu, Y., Zwicker, M.: Hvtr++: Image and pose driven human avatars using hybrid volumetric-textural rendering. IEEE Transactions on Visualization and Computer Graphics pp. 1–15 (2023).https://doi.org/10.1109/TVCG.2023.32977214
-
[27]
ACM Transactions on Graphics42(4), 1–12 (2023) 4
Işık, M., Rünz, M., Georgopoulos, M., Khakhulin, T., Starck, J., Agapito, L., Nießner, M.: HumanRF: High-Fidelity Neural Radiance Fields for Humans in Mo- tion. ACM Transactions on Graphics42(4), 1–12 (2023) 4
2023
-
[28]
2023 IEEE/CVF Interna- tional Conference on Computer Vision (ICCV) pp
Karras, J., Holynski, A., Wang, T.C., Kemelmacher-Shlizerman, I.: Dreampose: Fashion image-to-video synthesis via stable diffusion. 2023 IEEE/CVF Interna- tional Conference on Computer Vision (ICCV) pp. 22623–22633 (2023),https: //api.semanticscholar.org/CorpusID:2580788929, 10, 11, 19
2023
-
[29]
Kratzwald, B., Huang, Z., Paudel, D.P., Van Gool, L.: Towards an understanding of our world by GANing videos in the wild (2017),https://arxiv.org/abs/1711. 11453, arXiv:1711.11453 4
-
[30]
A comprehensive survey on human video generation: Challenges, methods, and insights,
Lei, W., Wang, J., Ma, F., Huang, G., Liu, L.: A Comprehensive Survey on Human Video Generation: Challenges, Methods, and Insights. arXiv preprint arXiv:2407.08428 (2024) 4
-
[31]
Liu, C., Vahdat, A.: On equivariance and fast sampling in video diffusion models trained with warped noise (2025),https://api.semanticscholar.org/CorpusID: 2777810882, 5, 7 HumANDiff: Articulated Noise Diffusion 21
2025
-
[32]
TOG40(2021) 4, 10, 15
Liu,L.,Habermann,M.,Rudnev,V.,Sarkar,K.,Gu,J.,Theobalt,C.:Neuralactor: Neural free-view synthesis of human actors with pose control. TOG40(2021) 4, 10, 15
2021
-
[33]
Liu, L., Xu, W., Habermann, M., Zollhöfer, M., Bernard, F., Kim, H., Wang, W., Theobalt, C.: Neural human video rendering by learning dynamic textures and rendering-to-video translation. IEEE Transactions on Visualization and Computer Graphics (05 2020).https://doi.org/10.1109/TVCG.2020.29965944
-
[34]
ACM Transactions on Graphics (TOG) (2019) 4
Liu, L., Xu, W., Zollhoefer, M., Kim, H., Bernard, F., Habermann, M., Wang, W., Theobalt, C.: Neural rendering and reenactment of human actor videos. ACM Transactions on Graphics (TOG) (2019) 4
2019
-
[35]
In: CVPR
Liu, Z., Luo, P., Qiu, S., Wang, X., Tang, X.: Deepfashion: Powering robust clothes recognition and retrieval with rich annotations. In: CVPR. pp. 1096–1104 (2016) 13
2016
-
[36]
ACM Trans
Loper, M., Mahmood, N., Romero, J., Pons-Moll, G., Black, M.J.: Smpl: a skinned multi-person linear model. ACM Trans. Graph.34, 248:1–16 (2015) 2, 3, 4, 6
2015
-
[37]
In: NeurIPS
Ma, L., Jia, X., Sun, Q., Schiele, B., Tuytelaars, T., Van Gool, L.: Pose guided person image generation. In: NeurIPS. pp. 405–415 (2017) 4
2017
-
[38]
CVPR (2018) 4
Ma, L., Sun, Q., Georgoulis, S., van Gool, L., Schiele, B., Fritz, M.: Disentangled person image generation. CVPR (2018) 4
2018
-
[39]
ECCV (2018) 4
Neverova, N., Güler, R.A., Kokkinos, I.: Dense pose transfer. ECCV (2018) 4
2018
-
[40]
Niemeyer, M., Geiger, A.: Giraffe: Representing scenes as compositional generative neural feature fields. CVPR pp. 11448–11459 (2021) 4
2021
-
[41]
In: IEEE/CVF ICCV (2021) 4
Noguchi, A., Sun, X., Lin, S., Harada, T.: Neural articulated radiance field. In: IEEE/CVF ICCV (2021) 4
2021
-
[42]
Or-El, R., Luo, X., Shan, M., Shechtman, E., Park, J.J., Kemelmacher-Shlizerman, I.: Stylesdf: High-resolution 3d-consistent image and geometry generation. ArXiv abs/2112.11427(2021) 4
-
[43]
In: ICCV (2021) 4
Peng, S., Dong, J., Wang, Q., Zhang, S., Shuai, Q., Zhou, X., Bao, H.: Animatable neural radiance fields for modeling dynamic human bodies. In: ICCV (2021) 4
2021
-
[44]
CVPR (2021) 4
Peng, S., Zhang, Y., Xu, Y., Wang, Q., Shuai, Q., Bao, H., Zhou, X.: Neural body: Implicit neural representations with structured latent codes for novel view synthesis of dynamic humans. CVPR (2021) 4
2021
-
[45]
WACV (2021) 4
Prokudin, S., Black, M.J., Romero, J.: Smplpix: Neural avatars from 3d human models. WACV (2021) 4
2021
-
[46]
In: CVPR (June 2018) 4
Pumarola, A., Agudo, A., Sanfeliu, A., Moreno-Noguer, F.: Unsupervised person image synthesis in arbitrary poses. In: CVPR (June 2018) 4
2018
-
[47]
LHM: large animatable human reconstruction model from a single image in seconds
Qiu, L., Gu, X., Li, P., Zuo, Q., Shen, W., Zhang, J., Qiu, K., Yuan, W., Chen, G., Dong, Z., et al.: Lhm: Large animatable human reconstruction model from a single image in seconds. arXiv preprint arXiv:2503.10625 (2025) 4
-
[48]
arXiv preprint arXiv:2412.02684 (2024) 4
Qiu, L., Zhu, S., Zuo, Q., Gu, X., Dong, Y., Zhang, J., Xu, C., Li, Z., Yuan, W., Bo, L., et al.: Anigs: Animatable gaussian avatar from a single image with inconsistent gaussian reconstruction. arXiv preprint arXiv:2412.02684 (2024) 4
-
[49]
Raj, A., Tanke, J., Hays, J., Vo, M., Stoll, C., Lassner, C.: Anr: Articulated neural rendering for virtual avatars. CVPR pp. 3721–3730 (2021) 4
2021
-
[50]
In: IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR) (2022) 4
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-Resolution Image Synthesis with Latent Diffusion Models. In: IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR) (2022) 4
2022
-
[51]
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models (2021) 1, 2, 4, 11
2021
-
[52]
In: ECCV (2020) 4 22 Tao Hu and Varun Jampani
Sarkar, K., Mehta, D., Xu, W., Golyanik, V., Theobalt, C.: Neural re-rendering of humans from a single image. In: ECCV (2020) 4 22 Tao Hu and Varun Jampani
2020
-
[53]
ACM Transactions on Graphics 43(6), 1–13 (2024) 2, 4, 5
Shao, R., Pang, Y., Zheng, Z., Sun, J., Liu, Y.: Human4DiT: 360-Degree Human Video Generation with 4D Diffusion Transformer. ACM Transactions on Graphics 43(6), 1–13 (2024) 2, 4, 5
2024
-
[54]
ACM Transactions on Graphics (TOG) (2025) 2, 4
Shao, R., Xu, Y., Shen, Y., Yang, C., Zheng, Y., Chen, C., Liu, Y., Wetzstein, G.: Isa4d: Interspatial attention for efficient 4d human video generation. ACM Transactions on Graphics (TOG) (2025) 2, 4
2025
-
[55]
In: CVPR (2018) 4
Siarohin, A., Sangineto, E., Lathuiliere, S., Sebe, N.: Deformable GANs for pose- based human image generation. In: CVPR (2018) 4
2018
-
[56]
2021 IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition (CVPR) pp
Siarohin, A., Woodford, O.J., Ren, J., Chai, M., Tulyakov, S.: Motion represen- tations for articulated animation. 2021 IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition (CVPR) pp. 13648–13657 (2021),https://api. semanticscholar.org/CorpusID:23338803210
2021
-
[57]
Make-A-Video: Text-to-Video Generation without Text-Video Data
Singer, U., Polyak, A., Hayes, T., Yin, X., An, J., Zhang, S., Hu, Q., Yang, H., Ashual, O., Gafni, O., et al.: Make-A-Video: Text-to-Video Generation without Text-Video Data. arXiv preprint arXiv:2209.14792 (2022) 4
work page internal anchor Pith review arXiv 2022
-
[58]
Score-Based Generative Modeling through Stochastic Differential Equations
Song, Y., Sohl-Dickstein, J., Kingma, D.P., Kumar, A., Ermon, S., Poole, B.: Score-Based Generative Modeling through Stochastic Differential Equations. arXiv preprint arXiv:2011.13456 (2020) 4
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[59]
In: NeurIPS (2021) 4
Su, S.Y., Yu, F., Zollhoefer, M., Rhodin, H.: A-nerf: Articulated neural radiance fields for learning human shape, appearance, and pose. In: NeurIPS (2021) 4
2021
-
[60]
ACM Transactions on Graphics (TOG)38(2019) 4
Thies, J., Zollhöfer, M., Nießner, M.: Deferred neural rendering: image synthesis using neural textures. ACM Transactions on Graphics (TOG)38(2019) 4
2019
-
[61]
Towards Accurate Generative Models of Video: A New Metric & Challenges
Unterthiner, T., van Steenkiste, S., Kurach, K., Roth, K., Hulsc, A., Riedmiller, M., Bousquet, O.: Towards accurate generative models of video: The fvd score. arXiv preprint arXiv:1812.01717 (2018) 10
work page internal anchor Pith review arXiv 2018
-
[62]
arXiv preprint arXiv:1907.06578 (2019) 10
Unterthiner, T., et al.: Fvd: A new metric for video generation. arXiv preprint arXiv:1907.06578 (2019) 10
-
[63]
Wan: Open and Advanced Large-Scale Video Generative Models
Wan, T., Wang, A., Ai, B., Wen, B., Mao, C., Xie, C.W., Chen, D., Yu, F., Zhao, H., Yang, J., Zeng, J., Wang, J., Zhang, J., Zhou, J., Wang, J., Chen, J., Zhu, K., Zhao, K., Yan, K., Huang, L., Feng, M., Zhang, N., Li, P., Wu, P., Chu, R., Feng, R., Zhang, S., Sun, S., Fang, T., Wang, T., Gui, T., Weng, T., Shen, T., Lin, W., Wang, W., Wang, W., Zhou, W.,...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[64]
Instantid: Zero-shot identity-preserving generation in seconds.arXiv preprint arXiv:2401.07519, 2024
Wang, Q., Bai, X., Wang, H., Qin, Z., Chen, A., Li, H., Tang, X., Hu, Y.: InstantID: Zero-shot Identity-Preserving Generation in Seconds. arXiv preprint arXiv:2401.07519 (2024) 4
-
[65]
In: IEEE/CVF Con- ference on Computer Vision and Pattern Recognition (CVPR) (2024) 4, 5
Wang, T., Li, L., Lin, K., Lin, C.C., Yang, Z., Zhang, H., Liu, Z., Wang, L.: DisCo: Disentangled Control for Realistic Human Dance Generation. In: IEEE/CVF Con- ference on Computer Vision and Pattern Recognition (CVPR) (2024) 4, 5
2024
-
[66]
In: NeurIPS (2018) 4
Wang, T.C., Liu, M.Y., Zhu, J.Y., Liu, G., Tao, A., Kautz, J., Catanzaro, B.: Video-to-video synthesis. In: NeurIPS (2018) 4
2018
-
[67]
In: CVPR (2018) 17
Wang, T.C., Liu, M.Y., Zhu, J.Y., Tao, A., Kautz, J., Catanzaro, B.: High- resolution image synthesis and semantic manipulation with conditional gans. In: CVPR (2018) 17
2018
-
[68]
Magicvideo-v2: Multi-stage high- aesthetic video generation,
Wang,W.,Liu,J.,Lin,Z.,Yan,J.,Chen,S.,Low,C.,Hoang,T.,Wu,J.,Liew,J.H., Yan, H., et al.: MagicVideo-V2: Multi-Stage High-Aesthetic Video Generation. arXiv preprint arXiv:2401.04468 (2024) 4 HumANDiff: Articulated Noise Diffusion 23
-
[69]
Science China Information Sciences (2025) 11, 12
Wang, X., Zhang, S., Gao, C., Wang, J., Zhou, X., Zhang, Y., Yan, L., Sang, N.: Unianimate: Taming unified video diffusion models for consistent human image animation. Science China Information Sciences (2025) 11, 12
2025
-
[70]
IEEE Transactions on Image Process- ing13(4), 600–612 (2004) 10
Wang, Z., Bovik, A.C., Sheikh, H.R., Simoncelli, E.P.: Image quality assessment: from error visibility to structural similarity. IEEE Transactions on Image Process- ing13(4), 600–612 (2004) 10
2004
-
[71]
In: International Conference on Computer Vision (ICCV) (2023) 4
Wu, J.Z., Ge, Y., Wang, X., Lei, S.W., Gu, Y., Shi, Y., Hsu, W., Shan, Y., Qie, X., Shou, M.Z.: Tune-A-Video: One-Shot Tuning of Image Diffusion Models for Text- to-Video Generation. In: International Conference on Computer Vision (ICCV) (2023) 4
2023
-
[72]
In: IEEE/CVF Conference on Computer Vision and Pattern Recog- nition (CVPR) (2024) 4
Xu, Z., Zhang, J., Liew, J.H., Yan, H., Liu, J.W., Zhang, C., Feng, J., Shou, M.Z.: MagicAnimate: Temporally Consistent Human Image Animation using Dif- fusion Model. In: IEEE/CVF Conference on Computer Vision and Pattern Recog- nition (CVPR) (2024) 4
2024
-
[73]
VideoGPT: Video Generation using VQ-VAE and Transformers
Yan, W., Zhang, Y., Abbeel, P., Srinivas, A.: VideoGPT: Video Generation using VQ-VAE and Transformers. arXiv preprint arXiv:2104.10157 (2021) 4
work page internal anchor Pith review arXiv 2021
-
[74]
In: International Conference on Computer Vision (ICCV) (2023) 4
Yang, Z., Zeng, A., Yuan, C., Li, Y.: Effective Whole-body Pose Estimation with Two-stages Distillation. In: International Conference on Computer Vision (ICCV) (2023) 4
2023
-
[75]
arXiv (2024) 1, 2, 4, 5, 7, 9, 10, 11, 15, 16, 17
Yang, Z., Teng, J., Zheng, W., Ding, M., Huang, S., Xu, J., Yang, Y., Hong, W., Zhang, X., Feng, G., Yin, D., Zhang, Y., Wang, W., Cheng, Y., Xu, B., Gu, X., Dong, Y., Tang, J.: Cogvideox: Text-to-video diffusion models with an expert transformer. arXiv (2024) 1, 2, 4, 5, 7, 9, 10, 11, 15, 16, 17
2024
-
[76]
In: IEEE/CVF Conference on Computer Vision and Pattern Recog- nition (CVPR) (2023) 4
Yu, L., Cheng, Y., Sohn, K., Lezama, J., Zhang, H., Chang, H., Hauptmann, A.G., Yang, M.H., Hao, Y., Essa, I., et al.: MAGVIT: Masked Generative Video Transformer. In: IEEE/CVF Conference on Computer Vision and Pattern Recog- nition (CVPR) (2023) 4
2023
-
[77]
2023 IEEE/CVF International Conference on Computer Vision (ICCV) pp
Yu, W.Y., Po, L.M., Cheung, R.C.C., Zhao, Y., Xue, Y.Z., Li, K.: Bidirection- ally deformable motion modulation for video-based human pose transfer. 2023 IEEE/CVF International Conference on Computer Vision (ICCV) pp. 7468–7478 (2023),https://api.semanticscholar.org/CorpusID:25993785010, 11
2023
-
[78]
In: British Machine Vision Conference (BMVC) (2019) 9
Zablotskaia, P., Siarohin, A., Sigal, L., Zhao, B.: Dwnet: Dense warp-based network for pose-guided human video generation. In: British Machine Vision Conference (BMVC) (2019) 9
2019
-
[79]
Advances in Neural Information Processing Systems37(2025) 4
Zhang, H., Chen, X., Wang, Y., Liu, X., Wang, Y., Qiao, Y.: 4Diffusion: Multi- view Video Diffusion Model for 4D Generation. Advances in Neural Information Processing Systems37(2025) 4
2025
-
[80]
In: International Conference on Computer Vision (ICCV) (2023) 4
Zhang, L., Rao, A., Agrawala, M.: Adding Conditional Control to Text-to-Image Diffusion Models. In: International Conference on Computer Vision (ICCV) (2023) 4
2023
-
[81]
In: CVPR (2018) 10
Zhang, R., Isola, P., Efros, A.A., Shechtman, E., Wang, O.: The unreasonable effectiveness of deep features as a perceptual metric. In: CVPR (2018) 10
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.