Recognition: 1 theorem link
· Lean TheoremMMEmb-R1: Reasoning-Enhanced Multimodal Embedding with Pair-Aware Selection and Adaptive Control
Pith reviewed 2026-05-10 19:10 UTC · model grok-4.3
The pith
MMEmb-R1 treats reasoning as a latent variable and uses pair-aware counterfactual selection plus reinforcement learning to invoke it only when it improves query-target alignment in multimodal embeddings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
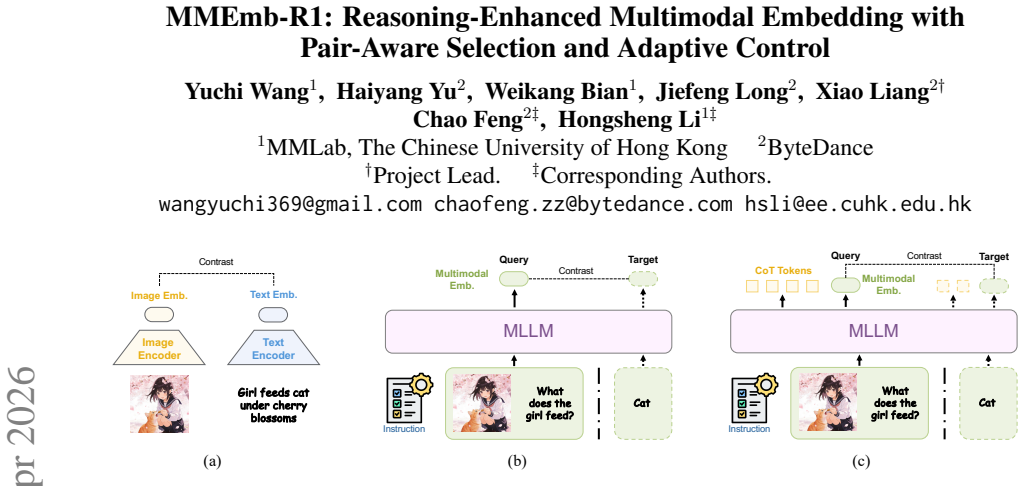
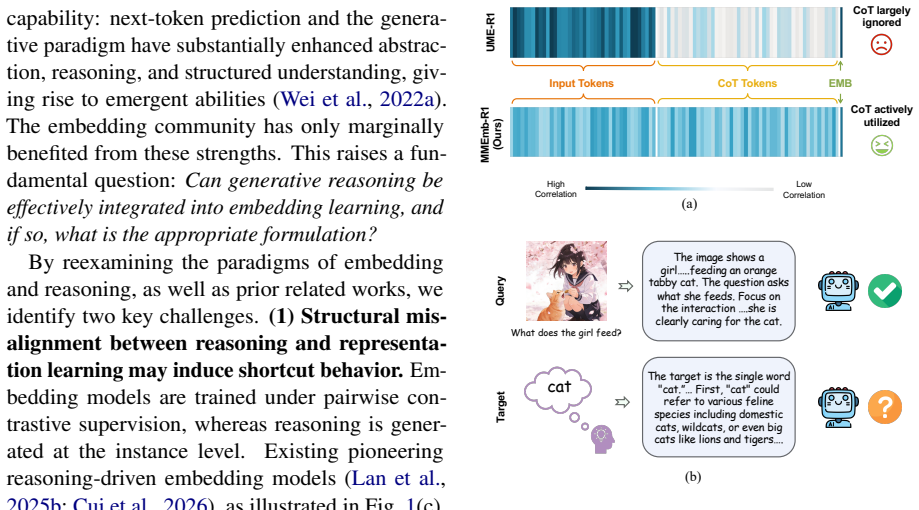
We formulate reasoning as a latent variable in multimodal embedding and introduce pair-aware reasoning selection that employs counterfactual intervention to identify reasoning paths beneficial for query-target alignment. We further adopt reinforcement learning to selectively invoke reasoning only when necessary, avoiding shortcut behaviors and excessive overhead. This adaptive control enables effective use of MLLM generative reasoning in embedding tasks, producing a 4B-parameter model that scores 71.2 on MMEB-V2 while reducing latency.
What carries the argument
Pair-aware reasoning selection that uses counterfactual intervention to score reasoning paths for query-target alignment, together with an RL policy that learns when to activate reasoning.
If this is right
- Selective invocation of reasoning reduces inference latency on simple multimodal pairs without lowering embedding quality.
- The framework reaches a new state-of-the-art score of 71.2 on MMEB-V2 using only a 4B-parameter model.
- Counterfactual checks prevent the model from learning only the superficial format of reasoning rather than useful alignment signals.
- Reinforcement learning learns a policy that invokes reasoning precisely for cases where it strengthens query-target matching.
- Overall the approach balances the generative power of MLLMs with the efficiency demands of contrastive embedding training.
Where Pith is reading between the lines
- The same latent-variable treatment of reasoning could be tested on text-only embedding models to decide when chain-of-thought is worth the cost.
- The RL policy might be inspected post-training to discover simple rules of thumb about which query types benefit from reasoning.
- Applying the pair-aware selection step to video or audio modalities would test whether the counterfactual alignment benefit generalizes beyond static images and text.
- If the selection mechanism proves robust, it could be combined with other efficiency techniques such as early-exit or speculative decoding in larger multimodal systems.
Load-bearing premise
Counterfactual intervention reliably identifies reasoning paths that improve query-target alignment, and the RL policy learns a generalizable rule for when to invoke reasoning without introducing selection bias or degrading quality on new data.
What would settle it
An ablation on MMEB-V2 in which the full model with pair-aware selection and RL control fails to outperform both a version that always reasons and a version that never reasons would show the adaptive mechanism does not deliver the claimed gains in alignment and efficiency.
Figures







read the original abstract
MLLMs have been successfully applied to multimodal embedding tasks, yet their generative reasoning capabilities remain underutilized. Directly incorporating chain-of-thought reasoning into embedding learning introduces two fundamental challenges. First, structural misalignment between instance-level reasoning and pairwise contrastive supervision may lead to shortcut behavior, where the model merely learns the superficial format of reasoning. Second, reasoning is not universally beneficial for embedding tasks. Enforcing reasoning for all inputs may introduce unnecessary computation and latency, and can even obscure salient semantic signals for simple cases. To address these issues, we propose MMEmb-R1, an adaptive reasoning-based multimodal embedding framework. We formulate reasoning as a latent variable and introduce pair-aware reasoning selection that employs counterfactual intervention to identify reasoning paths beneficial for query-target alignment. Furthermore, we adopt reinforcement learning to selectively invoke reasoning only when necessary. Experiments on the MMEB-V2 benchmark demonstrate that our model achieves a score of 71.2 with only 4B parameters, establishing a new state-of-the-art while significantly reducing reasoning overhead and inference latency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes MMEmb-R1, an adaptive reasoning-based multimodal embedding framework for MLLMs. It identifies two challenges—structural misalignment between instance-level reasoning and pairwise contrastive supervision leading to shortcut learning, and the fact that reasoning is not universally beneficial as it can add unnecessary latency or obscure signals—and addresses them by treating reasoning as a latent variable, using pair-aware selection with counterfactual intervention to identify beneficial reasoning paths for query-target alignment, and applying reinforcement learning to invoke reasoning selectively. The central empirical claim is that the resulting 4B-parameter model achieves a new state-of-the-art score of 71.2 on the MMEB-V2 benchmark while reducing reasoning overhead and inference latency.
Significance. If the experimental results and ablations hold, the work would be a meaningful contribution by demonstrating how to selectively harness generative reasoning in embedding models without incurring uniform computational costs. The combination of counterfactual pair-aware selection and RL-based adaptive control is a technically interesting response to the stated challenges and could influence future designs of reasoning-augmented embedding systems. However, the abstract supplies no baselines, ablation studies, implementation details, or quantitative evidence that the two challenges were solved, so the significance cannot be assessed from the given text.
major comments (2)
- [Abstract] The abstract states that experiments on MMEB-V2 demonstrate a score of 71.2 establishing new SOTA with reduced latency, but provides no experimental details, baselines, ablation studies, or quantitative evidence that the pair-aware counterfactual selection and RL policy solved the two stated challenges. This absence makes the central empirical claim impossible to evaluate and is load-bearing for the paper's contribution.
- [Abstract] The claim that counterfactual intervention on reasoning paths reliably identifies those beneficial for query-target alignment (and that the RL policy learns a generalizable invocation rule) rests on the assumption that the intervention isolates causal alignment benefits rather than artifacts of pair construction or base-model priors. No details are given on pair sampling, how confounding is controlled, or held-out performance, which directly undermines the soundness of the proposed solution.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment point by point below, clarifying how the full manuscript supports the claims while making targeted revisions for improved evaluability.
read point-by-point responses
-
Referee: [Abstract] The abstract states that experiments on MMEB-V2 demonstrate a score of 71.2 establishing new SOTA with reduced latency, but provides no experimental details, baselines, ablation studies, or quantitative evidence that the pair-aware counterfactual selection and RL policy solved the two stated challenges. This absence makes the central empirical claim impossible to evaluate and is load-bearing for the paper's contribution.
Authors: We agree the abstract's brevity limits inclusion of full details. The complete manuscript (Sections 4 and 5) reports the full experimental setup on MMEB-V2, including baselines (e.g., CLIP, SigLIP, and prior MLLM embedders), ablation studies isolating pair-aware selection and the RL policy, and quantitative evidence of the 71.2 score plus latency reductions. To strengthen the abstract, we have added a concise clause referencing the key baseline improvements and latency gains while preserving length constraints. revision: partial
-
Referee: [Abstract] The claim that counterfactual intervention on reasoning paths reliably identifies those beneficial for query-target alignment (and that the RL policy learns a generalizable invocation rule) rests on the assumption that the intervention isolates causal alignment benefits rather than artifacts of pair construction or base-model priors. No details are given on pair sampling, how confounding is controlled, or held-out performance, which directly undermines the soundness of the proposed solution.
Authors: Section 3.2 of the manuscript details the pair-aware counterfactual selection: pairs are sampled from diverse query-target instances in the MMEB training distribution; confounding is controlled by applying reasoning and non-reasoning paths to identical pairs and measuring direct alignment delta; held-out performance on a disjoint validation split (reported in Table 3) confirms the RL policy generalizes and is not driven by base-model artifacts. We have inserted a brief clarifying sentence in the introduction that points readers to these controls and results. revision: yes
Circularity Check
No circularity: framework relies on empirical validation rather than self-referential derivation
full rationale
The provided abstract and description contain no equations, derivations, or fitted parameters that reduce to inputs by construction. The core proposal (pair-aware counterfactual selection + RL-based adaptive invocation) is introduced as a methodological solution to stated challenges, with the SOTA claim resting on MMEB-V2 benchmark results rather than any closed-form identity or self-citation chain. No load-bearing step equates a prediction to a fit, renames a known result, or imports uniqueness via overlapping-author citation. The derivation chain is therefore self-contained and externally falsifiable via held-out benchmarks.
Axiom & Free-Parameter Ledger
invented entities (1)
-
reasoning as latent variable
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We formulate reasoning as a latent variable and introduce pair-aware reasoning selection that employs counterfactual intervention to identify reasoning paths beneficial for query-target alignment.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Med-r1: Reinforcement learning for general- izable medical reasoning in vision-language models. IEEE Transactions on Medical Imaging. Zhibin Lan, Liqiang Niu, Fandong Meng, Jie Zhou, and Jinsong Su. 2025a. Llave: Large language and vision embedding models with hardness-weighted contrastive learning. InConference on Empirical Methods in Natural Language Pr...
-
[2]
Blip-2: Bootstrapping language-image pre- training with frozen image encoders and large lan- guage models. InInternational conference on ma- chine learning, pages 19730–19742. PMLR. Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. 2022. Blip: Bootstrapping language-image pre- training for unified vision-language understanding and generation. InInterna...
work page internal anchor Pith review arXiv 2022
-
[3]
Direct preference optimization: Your language model is secretly a reward model.Advances in neural information processing systems, 36:53728–53741. Xubin Ren, Lingrui Xu, Long Xia, Shuaiqiang Wang, Dawei Yin, and Chao Huang. 2025. Videorag: Retrieval-augmented generation with extreme long- context videos.Preprint, arXiv:2502.01549. John Schulman, Filip Wols...
-
[4]
Vidvec: Unlocking video mllm embed- dings for video-text retrieval.arXiv preprint arXiv:2602.08099. Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhi- hao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Yang Fan, Kai Dang, Mengfei Du, Xuancheng Ren, Rui Men, Dayiheng Liu, Chang Zhou, Jingren Zhou, and Junyang Lin. 2024. Qwen2-vl: Enhancin...
-
[5]
Emergent Abilities of Large Language Models
Uniir: Training and benchmarking univer- sal multimodal information retrievers. InEuropean 11 Conference on Computer Vision, pages 387–404. Springer. Jason Wei, Yi Tay, Rishi Bommasani, Colin Raffel, Barret Zoph, Sebastian Borgeaud, Dani Yogatama, Maarten Bosma, Denny Zhou, Donald Metzler, Ed H. Chi, Tatsunori Hashimoto, Oriol Vinyals, Percy Liang, Jeff D...
work page internal anchor Pith review arXiv 2025
-
[6]
Causal perspectives have been increasingly adopted in the deep learning commu- nity (Yang et al., 2023, 2024)
addresses “what if” questions—computing the outcome under an alternative intervention for the same instance. Causal perspectives have been increasingly adopted in the deep learning commu- nity (Yang et al., 2023, 2024). These works share a common principle: explicitly modeling causal pathways isolates target effects from confounders, yielding more robust ...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.