Recognition: 2 theorem links
· Lean TheoremThe Character Error Vector: Decomposable errors for page-level OCR evaluation
Pith reviewed 2026-05-10 19:05 UTC · model grok-4.3
The pith
The Character Error Vector evaluates page-level OCR by decomposing errors into parsing, OCR, and interaction components.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We introduce the Character Error Vector, a bag-of-characters evaluator for OCR that remains defined under page-parsing errors. The CEV decomposes into parsing error, OCR error, and interaction error components using methods such as SpACER or Jensen-Shannon character distribution distance. This allows direct measurement of page-level OCR quality and triage of which pipeline stage needs attention, as demonstrated by superior performance of traditional methods over end-to-end models on complex archival data.
What carries the argument
The Character Error Vector, a bag-of-characters representation of OCR output that is decomposed into additive parsing error, OCR error, and interaction error terms.
If this is right
- Practitioners can identify whether parsing or OCR is the main bottleneck in a text extraction pipeline.
- Simple thresholding on available values predicts the dominant error source with an F1 of 0.91.
- Traditional pipeline approaches outperform state-of-the-art end-to-end models on degraded archival newspapers with complex layouts.
- The CEV acts as a bridge connecting page-level parsing quality measures to local character accuracy metrics like CER.
Where Pith is reading between the lines
- The same decomposition approach could be tested on handwritten or multilingual documents to check whether interaction terms behave similarly.
- Reporting the three CEV components alongside any single score would give clearer diagnostics across different document collections.
- Future pipelines might optimize parsing and recognition stages separately once the error contributions are routinely measured.
Load-bearing premise
The decomposition accurately separates the error sources without the specific implementations of SpACER or Jensen-Shannon distance introducing confounding effects.
What would settle it
A set of pages where the CEV attributes most error to one component, such as parsing, but manual inspection of the same pages shows that the dominant source is actually OCR recognition mistakes.
Figures

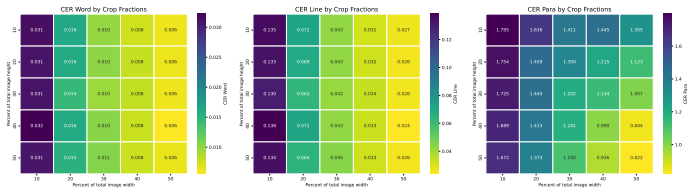



read the original abstract
The Character Error Rate (CER) is a key metric for evaluating the quality of Optical Character Recognition (OCR). However, this metric assumes that text has been perfectly parsed, which is often not the case. Under page-parsing errors, CER becomes undefined, limiting its use as a metric and making evaluating page-level OCR challenging, particularly when using data that do not share a labelling schema. We introduce the Character Error Vector (CEV), a bag-of-characters evaluator for OCR. The CEV can be decomposed into parsing and OCR, and interaction error components. This decomposability allows practitioners to focus on the part of the Document Understanding pipeline that will have the greatest impact on overall text extraction quality. The CEV can be implemented using a variety of methods, of which we demonstrate SpACER (Spatially Aware Character Error Rate) and a Character distribution method using the Jensen-Shannon Distance. We validate the CEV's performance against other metrics: first, the relationship with CER; then, parse quality; and finally, as a direct measure of page-level OCR quality. The validation process shows that the CEV is a valuable bridge between parsing metrics and local metrics like CER. We analyse a dataset of archival newspapers made of degraded images with complex layouts and find that state-of-the-art end-to-end models are outperformed by more traditional pipeline approaches. Whilst the CEV requires character-level positioning for optimal triage, thresholding on easily available values can predict the main error source with an F1 of 0.91. We provide the CEV as part of a Python library to support Document understanding research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Character Error Vector (CEV), a bag-of-characters evaluator for page-level OCR that remains defined under parsing errors (unlike CER). It claims the CEV decomposes into parsing, OCR, and interaction error components, demonstrated with SpACER (spatially aware) and Jensen-Shannon character distribution methods. Validation shows relationships to CER and parse quality, direct page-level quality assessment, and F1=0.91 for predicting main error source via thresholding on available values. Analysis of degraded archival newspapers finds traditional pipelines outperform end-to-end models; a Python library is provided.
Significance. If the decomposition is robust, the CEV provides a practical bridge between parsing metrics and local metrics like CER, enabling targeted improvements in document understanding pipelines by identifying whether parsing or OCR is the dominant error source. The library release and empirical results on complex archival data strengthen utility and reproducibility.
major comments (2)
- [Validation and method sections (decomposition and error-source prediction)] The central claim of clean decomposability into parsing/OCR/interaction components (abstract and validation description) requires that component ratios remain stable under alternative character alignments; the paper demonstrates SpACER and Jensen-Shannon but does not report tests with standard Levenshtein or optimal transport, leaving open whether attribution is confounded by the specific matching procedure.
- [Validation process (page-level OCR quality and error-source prediction)] The reported F1=0.91 for main-error-source prediction via thresholding lacks details on threshold selection, cross-validation procedure, or sensitivity analysis; without these, it is unclear whether the triage guidance generalizes beyond the specific dataset and implementations.
minor comments (2)
- The abstract states the CEV is provided as part of a Python library; the manuscript should include an explicit link, GitHub reference, or installation instructions to support reproducibility.
- Consider reporting confidence intervals or error bars on the F1 score and other quantitative validation results (e.g., relationships with CER) to better convey uncertainty.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help clarify the robustness and reproducibility of our proposed Character Error Vector (CEV). We address each major comment point by point below and will revise the manuscript accordingly to strengthen the validation sections.
read point-by-point responses
-
Referee: [Validation and method sections (decomposition and error-source prediction)] The central claim of clean decomposability into parsing/OCR/interaction components (abstract and validation description) requires that component ratios remain stable under alternative character alignments; the paper demonstrates SpACER and Jensen-Shannon but does not report tests with standard Levenshtein or optimal transport, leaving open whether attribution is confounded by the specific matching procedure.
Authors: We appreciate the referee's emphasis on verifying the stability of the decomposition. The CEV is defined as a bag-of-characters vector difference between predicted and ground-truth counts, with the decomposition into parsing, OCR, and interaction terms derived directly from this vector (independent of any particular alignment). SpACER and Jensen-Shannon were chosen as representative methods because they explicitly handle spatial and distributional mismatches common in page-level OCR. However, we acknowledge that reporting results under standard Levenshtein alignment and optimal transport would provide stronger evidence that component ratios are not artifacts of the chosen matching procedure. In the revised manuscript, we will add a new subsection in the validation experiments that recomputes the CEV decomposition using Levenshtein-based alignment on the same archival newspaper dataset and reports the resulting component ratios and error-source predictions for comparison. revision: yes
-
Referee: [Validation process (page-level OCR quality and error-source prediction)] The reported F1=0.91 for main-error-source prediction via thresholding lacks details on threshold selection, cross-validation procedure, or sensitivity analysis; without these, it is unclear whether the triage guidance generalizes beyond the specific dataset and implementations.
Authors: We agree that the current description of the F1=0.91 result is insufficiently detailed for full reproducibility and assessment of generalizability. The reported score was obtained by thresholding on easily computable page-level statistics (parse quality proxy and aggregate error magnitude) to classify the dominant error source. In the revised manuscript, we will expand the relevant validation subsection to specify: the exact threshold values and selection method (grid search over a held-out validation split of the archival dataset), the cross-validation procedure used to compute the F1, and a sensitivity analysis plotting F1 as a function of small perturbations around the chosen thresholds. These additions will clarify the scope of the triage guidance while preserving the original claim that thresholding on readily available values can achieve high predictive performance. revision: yes
Circularity Check
No load-bearing circularity; CEV decomposition defined independently and validated externally
full rationale
The paper introduces the CEV as a bag-of-characters evaluator for page-level OCR that handles parsing errors where CER is undefined. It defines a decomposition into parsing, OCR, and interaction components, then demonstrates two implementations (SpACER and Jensen-Shannon character distribution) and validates the metric against independent external quantities: relationship to CER, parse quality, and direct page-level OCR quality. Thresholding on available values predicts error source with reported F1 0.91. No equations or claims reduce the decomposition to a fitted parameter renamed as prediction, no self-definitional loops appear, and no uniqueness theorems or ansatzes are imported via self-citation as load-bearing premises. The central claim remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Jensen-Shannon distance is a suitable measure for comparing character distributions in OCR output
invented entities (1)
-
Character Error Vector (CEV)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The CEV can be decomposed into parsing and OCR, and interaction error components... SpACER... Jensen-Shannon Distance
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce the Character Error Vector (CEV), a bag-of-characters evaluator for OCR
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Shuai Bai et al.Qwen2.5-VL Technical Report. arXiv:2502.13923 [cs]. Feb. 2025.doi:10.48550/arXiv.2502.13923.url:http://arxiv.org/abs/ 2502.13923(visited on 04/04/2026). 22
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2502.13923.url:http://arxiv.org/abs/ 2025
-
[2]
Jonathan Bourne. “Reading the unreadable: creating a dataset of 19th century English newspapers using image-to-text language models”. In: Digital Scholarship in the Humanities(Dec. 2025), fqaf151.issn: 2055- 7671.doi:10.1093/llc/fqaf151.url:https://doi.org/10.1093/ llc/fqaf151(visited on 02/04/2026)
work page doi:10.1093/llc/fqaf151.url:https://doi.org/10.1093/ 2025
-
[3]
Scrambled text: fine-tuning language models for OCR error correction using synthetic data
Jonathan Bourne. “Scrambled text: fine-tuning language models for OCR error correction using synthetic data”. en. In:International Journal on Document Analysis and Recognition (IJDAR)28.4 (Dec. 2025), pp. 741– 755.issn: 1433-2825.doi:10.1007/s10032-025-00522-0.url:https: //doi.org/10.1007/s10032-025-00522-0(visited on 02/06/2026)
-
[4]
Jonathan Bourne, Mwiza Simbeye, and Ishtar Govia.The COTe score: A decomposable framework for evaluating Document Layout Analysis models. arXiv:2603.12718 [cs]. Mar. 2026.doi:10 . 48550 / arXiv . 2603 . 12718. url:http://arxiv.org/abs/2603.12718(visited on 03/16/2026)
-
[5]
Flexible character accuracy measure for reading-order-independent eval- uation
Christian Clausner, Stefan Pletschacher, and Apostolos Antonacopoulos. “Flexible character accuracy measure for reading-order-independent eval- uation”. In:Pattern Recognition Letters131 (Mar. 2020), pp. 390–397. issn: 0167-8655.doi:10.1016/j.patrec.2020.02.003.url:https:// www.sciencedirect.com/science/article/pii/S0167865520300416 (visited on 04/04/2026)
work page doi:10.1016/j.patrec.2020.02.003.url:https:// 2020
-
[6]
Ryan Cordell. ““Q i-jtb the Raven”: Taking Dirty OCR Seriously”. In: Book History20 (2017), pp. 188–225.issn: 1098-7371.url:https : / / www.jstor.org/stable/48554671(visited on 04/07/2026)
-
[7]
PaddleOCR 3.0 Technical Report
Cheng Cui et al.PaddleOCR 3.0 Technical Report. arXiv:2507.05595 [cs]. July 2025.doi:10.48550/arXiv.2507.05595.url:http://arxiv.org/ abs/2507.05595(visited on 04/04/2026)
work page internal anchor Pith review doi:10.48550/arxiv.2507.05595.url:http://arxiv.org/ 2025
-
[8]
Cheng Cui et al.PP-OCRv5: A Specialized 5M-Parameter Model Rivaling Billion-Parameter Vision-Language Models on OCR Tasks. arXiv:2603.24373 [cs]. Mar. 2026.doi:10.48550/arXiv.2603.24373.url:http://arxiv. org/abs/2603.24373(visited on 04/03/2026)
work page doi:10.48550/arxiv.2603.24373.url:http://arxiv 2026
-
[9]
Shuaiqi Duan et al.GLM-OCR Technical Report. en. arXiv:2603.10910 [cs]. Mar. 2026.doi:10.48550/arXiv.2603.10910.url:http://arxiv. org/abs/2603.10910(visited on 04/04/2026)
work page doi:10.48550/arxiv.2603.10910.url:http://arxiv 2026
-
[10]
A genetic sparse distributed mem- ory approach to the application of handwritten character recognition
Kuo-Chin Fan and Yuan-Kai Wang. “A genetic sparse distributed mem- ory approach to the application of handwritten character recognition”. In:Pattern Recognition30.12 (Dec. 1997), pp. 2015–2022.issn: 0031- 3203.doi:10 . 1016 / S0031 - 3203(97 ) 00017 - 4.url:https : / / www . sciencedirect.com/science/article/pii/S0031320397000174(vis- ited on 03/26/2026)
1997
-
[11]
Drew Hemment and Cory Kommers.Doing AI differently: rethinking the foundations of AI via the humanities. Ed. by Ruth Ahnert et al. London: The Alan Turing Institute, July 2025.doi:10.5281/zenodo.1642129. 23
-
[12]
Inbum Heo et al.LED Benchmark: Diagnosing Structural Layout Errors for Document Layout Analysis. arXiv:2507.23295 [cs]. July 2025.doi:10. 48550/arXiv.2507.23295.url:http://arxiv.org/abs/2507.23295 (visited on 12/13/2025)
-
[13]
Henrik Hermansson and James P. Cross.Tracking Amendments to Leg- islation and Other Political Texts with a Novel Minimum-Edit-Distance Algorithm: DocuToads. arXiv:1608.06459 [cs] version: 1. Aug. 2016.doi: 10 . 48550 / arXiv . 1608 . 06459.url:http : / / arxiv . org / abs / 1608 . 06459(visited on 04/04/2026)
-
[15]
July 2025.url:https://huggingface
IBM.Granite Docling Model Card. July 2025.url:https://huggingface. co/ibm-granite/granite-docling-258M(visited on 03/27/2026)
2025
-
[16]
original-date: 2020-03-14T11:46:39Z
JaidedAI.EasyOCR. original-date: 2020-03-14T11:46:39Z. Mar. 2026.url: https://github.com/JaidedAI/EasyOCR(visited on 03/27/2026)
2020
-
[17]
Transkribus - A Service Platform for Transcription, Recognition and Retrieval of Historical Documents
Philip Kahle et al. “Transkribus - A Service Platform for Transcription, Recognition and Retrieval of Historical Documents”. In:2017 14th IAPR International Conference on Document Analysis and Recognition (IC- DAR). Vol. 04. ISSN: 2379-2140. Nov. 2017, pp. 19–24.doi:10.1109/ ICDAR . 2017 . 307.url:https : / / ieeexplore . ieee . org / document / 8270253(v...
2017
-
[18]
eScriptorium: An Open Source Platform for Historical Document Analysis
Benjamin Kiessling et al. “eScriptorium: An Open Source Platform for Historical Document Analysis”. In:2019 International Conference on Doc- ument Analysis and Recognition Workshops (ICDARW). Vol. 2. Sept. 2019, pp. 19–19.doi:10 . 1109 / ICDARW . 2019 . 10032.url:https : / / ieeexplore . ieee . org / abstract / document / 8893029(visited on 04/03/2026)
2019
-
[19]
William Kilbride. “Saving the Bits”. en. In: (Nov. 2015). Book Title: A New Companion to Digital Humanities ISBN: 9781118680605, pp. 408– 419.doi:10.1002/9781118680605.ch28.url:https://onlinelibrary. wiley.com/doi/10.1002/9781118680605.ch28(visited on 04/07/2026)
work page doi:10.1002/9781118680605.ch28.url:https://onlinelibrary 2015
-
[20]
Loghi: An End-to-End Framework for Mak- ing Historical Documents Machine-Readable
Rutger van Koert et al. “Loghi: An End-to-End Framework for Mak- ing Historical Documents Machine-Readable”. en. In:Document Analysis and Recognition – ICDAR 2024 Workshops. Ed. by Harold Mouch` ere and Anna Zhu. Cham: Springer Nature Switzerland, 2024, pp. 73–88.isbn: 978-3-031-70645-5.doi:10.1007/978-3-031-70645-5_6
-
[21]
Document Language Models, Query Models, and Risk Minimization for Information Retrieval
John Lafferty and Chengxiang Zhai. “Document Language Models, Query Models, and Risk Minimization for Information Retrieval”. In:SIGIR Forum51.2 (Aug. 2017), pp. 251–259.issn: 0163-5840.doi:10 . 1145 / 3130348.3130375.url:https://dl.acm.org/doi/10.1145/3130348. 3130375(visited on 02/07/2026). 24
-
[22]
Binary codes capable of correcting deletions, in- sertions, and reversals
Vladimir Levenshtein. “Binary codes capable of correcting deletions, in- sertions, and reversals”. In:Soviet physics doklady10 (1966), pp. 707– 710
1966
-
[23]
Trocr: Transformer-based optical character recognition with pre-trained models, 2022
Minghao Li et al.TrOCR: Transformer-based Optical Character Recogni- tion with Pre-trained Models. arXiv:2109.10282 [cs]. Sept. 2022.doi:10. 48550/arXiv.2109.10282.url:http://arxiv.org/abs/2109.10282 (visited on 03/27/2026)
-
[24]
Yumeng Li et al.dots.ocr: Multilingual Document Layout Parsing in a Single Vision-Language Model. arXiv:2512.02498 [cs]. Dec. 2025.doi:10. 48550/arXiv.2512.02498.url:http://arxiv.org/abs/2512.02498 (visited on 03/27/2026)
-
[25]
Zhang Li et al.MonkeyOCR: Document Parsing with a Structure-Recognition- Relation Triplet Paradigm. arXiv:2506.05218 [cs]. Feb. 2026.doi:10 . 48550/arXiv.2506.05218.url:http://arxiv.org/abs/2506.05218 (visited on 04/04/2026)
-
[26]
Nikolaos Livathinos et al.Advanced Layout Analysis Models for Docling. arXiv:2509.11720 [cs]. Sept. 2025.doi:10 . 48550 / arXiv . 2509 . 11720. url:http://arxiv.org/abs/2509.11720(visited on 02/04/2026)
-
[27]
Diverging Diver- gences: Examining Variants of Jensen Shannon Divergence for Corpus Comparison Tasks
Jinghui Lu, Maeve Henchion, and Brian Mac Namee. “Diverging Diver- gences: Examining Variants of Jensen Shannon Divergence for Corpus Comparison Tasks”. eng. In:Proceedings of the Twelfth Language Re- sources and Evaluation Conference. Ed. by Nicoletta Calzolari et al. Mar- seille, France: European Language Resources Association, May 2020, pp. 6740– 6744....
2020
-
[28]
Application of artificial neural network model for optical character recognition
N. Mani and B. Srinivasan. “Application of artificial neural network model for optical character recognition”. In:Computational Cybernetics and Sim- ulation 1997 IEEE International Conference on Systems, Man, and Cy- bernetics. Vol. 3. ISSN: 1062-922X. Oct. 1997, 2517–2520 vol.3.doi:10. 1109 / ICSMC . 1997 . 635312.url:https : / / ieeexplore . ieee . org ...
1997
-
[29]
Word ranking in a single document by Jensen–Shannon divergence
Ali Mehri, Maryam Jamaati, and Hassan Mehri. “Word ranking in a single document by Jensen–Shannon divergence”. In:Physics Letters A 379.28 (Aug. 2015), pp. 1627–1632.issn: 0375-9601.doi:10 . 1016 / j . physleta . 2015 . 04 . 030.url:https : / / www . sciencedirect . com / science/article/pii/S0375960115003722(visited on 02/07/2026)
2015
-
[30]
NLS.The Spiritualist – Data Foundry. en-US. 2019.doi:https : / / doi. org/10.34812 /3b0g- 3j88.url:https:// data.nls. uk/data/ digitised-collections/spiritualist-newspapers/(visited on 04/07/2026)
2019
-
[31]
2026.url:https: //huggingface.co/datasets/NationalLibraryOfScotland/Spiritualist_ Newspaper(visited on 04/07/2026)
Joseph Nockels.Spiritualist Newspaper Transcription. 2026.url:https: //huggingface.co/datasets/NationalLibraryOfScotland/Spiritualist_ Newspaper(visited on 04/07/2026). 25
2026
-
[32]
2025.url:https://github.com/VikParuchuri/ surya
Vikas Paruchuri and Datalab Team.Surya: A lightweight document OCR and analysis toolkit. 2025.url:https://github.com/VikParuchuri/ surya
2025
-
[33]
MAUVE: Measuring the Gap Between Neural Text and Human Text using Divergence Frontiers
Krishna Pillutla et al. “MAUVE: Measuring the Gap Between Neural Text and Human Text using Divergence Frontiers”. en. In: ()
-
[34]
The PAGE (Page Analysis and Ground-Truth Elements) Format Framework
Stefan Pletschacher and Apostolos Antonacopoulos. “The PAGE (Page Analysis and Ground-Truth Elements) Format Framework”. In:2010 20th International Conference on Pattern Recognition. Aug. 2010, pp. 257–260. doi:10.1109/ICPR.2010.72.url:https://ieeexplore.ieee.org/ document/5597587(visited on 02/11/2026)
work page doi:10.1109/icpr.2010.72.url:https://ieeexplore.ieee.org/ 2010
-
[35]
Jake Poznanski et al.olmOCR: Unlocking Trillions of Tokens in PDFs with Vision Language Models. arXiv:2502.18443 [cs]. July 2025.doi:10. 48550/arXiv.2502.18443.url:http://arxiv.org/abs/2502.18443 (visited on 03/27/2026)
-
[36]
Andrew Prescott and Lorna Hughes.Why Do We Digitize? The Case for Slow Digitization - Archive Journal. en. 2018.url:http : / / www . archivejournal.net/?p=7962(visited on 03/26/2026)
2018
-
[37]
Reading order detection in visually-rich documents with multi-modal layout-aware relation prediction
Liang Qiao et al. “Reading order detection in visually-rich documents with multi-modal layout-aware relation prediction”. In:Pattern Recognition 150 (June 2024), p. 110314.issn: 0031-3203.doi:10.1016/j.patcog. 2024.110314.url:https://www.sciencedirect.com/science/article/ pii/S0031320324000657(visited on 04/04/2026)
-
[38]
Reading order detection on hand- written documents
Lorenzo Quir´ os and Enrique Vidal. “Reading order detection on hand- written documents”. en. In:Neural Computing and Applications34.12 (June 2022), pp. 9593–9611.issn: 1433-3058.doi:10.1007/s00521-022- 06948 - 5.url:https : / / doi . org / 10 . 1007 / s00521 - 022 - 06948 - 5 (visited on 04/04/2026)
-
[39]
Computer Vision Intelligence Test Modeling and Gener- ation: A Case Study on Smart OCR
Jing Shu et al. “Computer Vision Intelligence Test Modeling and Gener- ation: A Case Study on Smart OCR”. In:2024 IEEE International Con- ference on Artificial Intelligence Testing (AITest). arXiv:2410.03536 [cs]. July 2024, pp. 21–28.doi:10 . 1109 / AITest62860 . 2024 . 00011.url: http://arxiv.org/abs/2410.03536(visited on 04/04/2026)
-
[40]
An Overview of the Tesseract OCR Engine
R. Smith. “An Overview of the Tesseract OCR Engine”. In:Ninth Interna- tional Conference on Document Analysis and Recognition (ICDAR 2007). Vol. 2. Sept. 2007, pp. 629–633.doi:10 . 1109 / ICDAR . 2007 . 4376991. url:https : / / ieeexplore . ieee . org / document / 4376991(visited on 02/03/2025)
2007
-
[41]
METAe—Automated Encoding of Digitized Texts
Birgit Stehno, Alexander Egger, and Gregor Retti. “METAe—Automated Encoding of Digitized Texts”. In:Literary and Linguistic Computing18.1 (Apr. 2003), pp. 77–88.issn: 0268-1145.doi:10.1093/llc/18.1.77. url:https://doi.org/10.1093/llc/18.1.77(visited on 02/11/2026). 26
- [42]
-
[43]
Thai OCR: a neural network ap- plication
C. Tanprasert and T. Koanantakool. “Thai OCR: a neural network ap- plication”. In:Proceedings of Digital Processing Applications (TENCON ’96). Vol. 1. Nov. 1996, 90–95 vol.1.doi:10.1109/TENCON.1996.608717. url:https://ieeexplore.ieee.org/abstract/document/608717(vis- ited on 03/26/2026)
-
[44]
Interpreting textual artefacts: cognitive insights into expert practices
S. Tarte. “Interpreting textual artefacts: cognitive insights into expert practices”. English. In: (2012).url:https://ora.ox.ac.uk/objects/ uuid:c1c39da4-fa0d-4644-bc80-1672b89d1d95(visited on 03/26/2026)
2012
-
[45]
TEI.TEI: Guidelines for Electronic Text Encoding and Interchange. Apr. 2025.url:https://tei- c.org/release/doc/tei- p5- doc/en/html/ index.html
2025
-
[46]
Melissa Terras.Image to Interpretation: An Intelligent System to Aid His- torians in Reading the Vindolanda Texts. en. Google-Books-ID: wpREAAAQBAJ. OUP Oxford, Oct. 2006.isbn: 978-0-19-152544-5
2006
-
[47]
Zilong Wang et al. “LayoutReader: Pre-training of Text and Layout for Reading Order Detection”. In:Proceedings of the 2021 Conference on Em- pirical Methods in Natural Language Processing. Ed. by Marie-Francine Moens et al. Online and Punta Cana, Dominican Republic: Association for Computational Linguistics, Nov. 2021, pp. 4735–4744.doi:10.18653/v1/ 2021....
-
[48]
Reliable evaluation of adversarial robustness with an ensemble of diverse parameter-free attacks
Haoran Wei et al.General OCR Theory: Towards OCR-2.0 via a Unified End-to-end Model. arXiv:2409.01704. Sept. 2024.doi:10.48550/arXiv. 2409 . 01704.url:http : / / arxiv . org / abs / 2409 . 01704(visited on 10/14/2024)
work page internal anchor Pith review doi:10.48550/arxiv 2024
-
[49]
Zhiyuan Zhao et al.DocLayout-YOLO: Enhancing Document Layout Anal- ysis through Diverse Synthetic Data and Global-to-Local Adaptive Percep- tion. arXiv:2410.12628. Oct. 2024.doi:10.48550/arXiv.2410.12628. url:http://arxiv.org/abs/2410.12628(visited on 11/14/2024). 27
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.