Recognition: no theorem link
Evolution of Video Generative Foundations
Pith reviewed 2026-05-10 18:37 UTC · model grok-4.3
The pith
Video generation has evolved from early GAN methods through dominant diffusion models to emerging autoregressive and multimodal techniques.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
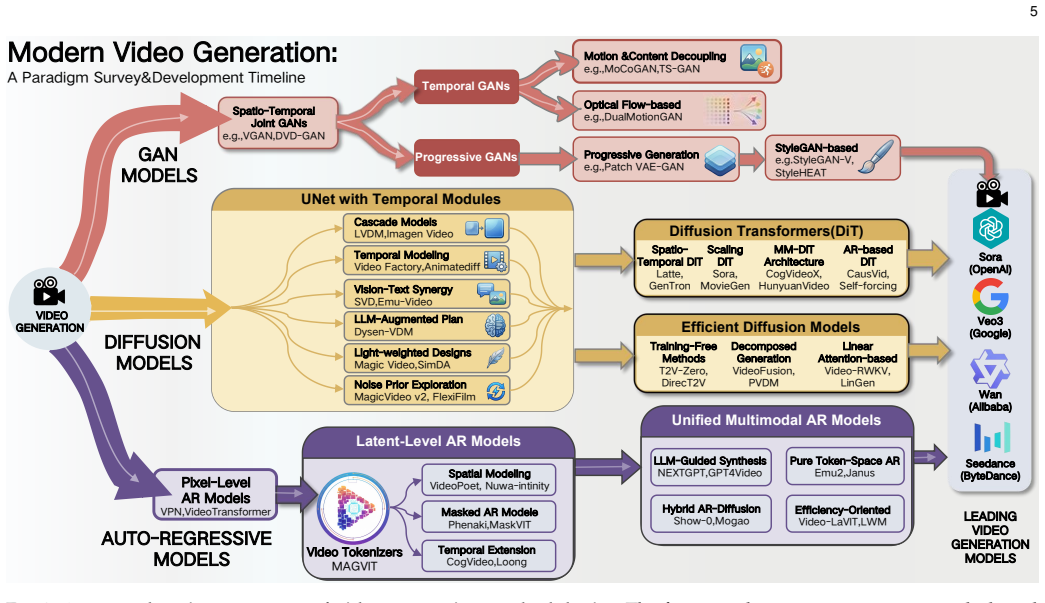
The paper states that video generation technology follows a traceable development sequence beginning with GAN-based systems, advancing to diffusion models as the prevailing method, and progressing toward autoregressive and multimodal frameworks. It delivers a detailed breakdown of the underlying mechanisms, major technical steps, and side-by-side evaluation of advantages versus shortcomings for each category. The survey then examines trends in combining diverse data sources to improve temporal consistency and semantic depth, ultimately linking these historical and present elements to steer upcoming work on applications such as world models and virtual environments.
What carries the argument
The evolutionary classification of video generative models, organized by core technique from GANs to diffusion to autoregressive and multimodal integration, which organizes the analysis of principles and trade-offs.
If this is right
- The progression supports creation of world models that can simulate physical dynamics more faithfully.
- Multimodal integration improves how well generated videos match surrounding context and meaning.
- The traced path informs development of tools for virtual and augmented reality, personalized learning, driving simulations, and entertainment.
- Comparative analysis of limitations in current methods highlights specific areas needing improvement for higher coherence over time.
Where Pith is reading between the lines
- This timeline suggests that combining autoregressive prediction with diffusion denoising could yield hybrids stronger than either alone in handling long sequences.
- Similar staged evolution may appear in related generative tasks such as audio or 3D scene creation, allowing cross-domain lessons.
- The survey's structure could serve as a template for evaluating whether new proprietary systems like Sora truly advance beyond prior categories or mainly optimize within them.
- Future experiments might test if the multimodal emphasis leads to measurable gains in semantic accuracy when models receive extra input modalities.
Load-bearing premise
The body of papers chosen for review fully represents the main advances and the comparisons of their strengths and limits are complete and even-handed.
What would settle it
A major new video generation method that cannot be placed in the GAN-diffusion-AR-multimodal sequence or that shows performance patterns contradicting the survey's listed advantages and drawbacks.
Figures






read the original abstract
The rapid advancement of Artificial Intelligence Generated Content (AIGC) has revolutionized video generation, enabling systems ranging from proprietary pioneers like OpenAI's Sora, Google's Veo3, and Bytedance's Seedance to powerful open-source contenders like Wan and HunyuanVideo to synthesize temporally coherent and semantically rich videos. These advancements pave the way for building "world models" that simulate real-world dynamics, with applications spanning entertainment, education, and virtual reality. However, existing reviews on video generation often focus on narrow technical fields, e.g., Generative Adversarial Networks (GAN) and diffusion models, or specific tasks (e. g., video editing), lacking a comprehensive perspective on the field's evolution, especially regarding Auto-Regressive (AR) models and integration of multimodal information. To address these gaps, this survey firstly provides a systematic review of the development of video generation technology, tracing its evolution from early GANs to dominant diffusion models, and further to emerging AR-based and multimodal techniques. We conduct an in-depth analysis of the foundational principles, key advancements, and comparative strengths/limitations. Then, we explore emerging trends in multimodal video generation, emphasizing the integration of diverse data types to enhance contextual awareness. Finally, by bridging historical developments and contemporary innovations, this survey offers insights to guide future research in video generation and its applications, including virtual/augmented reality, personalized education, autonomous driving simulations, digital entertainment, and advanced world models, in this rapidly evolving field. For more details, please refer to the project at https://github.com/sjtuplayer/Awesome-Video-Foundations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This survey traces the evolution of video generation technology from early GAN-based methods through dominant diffusion models to emerging autoregressive (AR) and multimodal approaches. It analyzes foundational principles, key advancements, and comparative strengths/limitations of each paradigm; explores trends in multimodal integration for enhanced contextual awareness; and offers forward-looking insights for applications including virtual/augmented reality, personalized education, autonomous driving simulations, digital entertainment, and world models. The work is supported by a linked GitHub repository (https://github.com/sjtuplayer/Awesome-Video-Foundations) containing an extended list of references.
Significance. If the literature coverage proves representative, the survey would fill a documented gap by moving beyond narrow prior reviews (GAN-only or diffusion-only) to connect historical foundations with contemporary AR and multimodal developments. The explicit discussion of strengths/limitations and the GitHub resource constitute concrete strengths that enhance utility and reproducibility for the community.
major comments (1)
- [Abstract] Abstract and opening sections: the claim of a 'systematic review' of the development from GANs to diffusion models to AR-based and multimodal techniques is not supported by any description of literature search protocol, databases, keywords, inclusion/exclusion criteria, or date range. This directly affects the central assertion that the selected body of work is representative and that the comparative strengths/limitations analysis is unbiased and comprehensive.
minor comments (1)
- [Abstract] Abstract: the sentence 'this survey firstly provides a systematic review...' reads awkwardly; a simpler phrasing such as 'this survey provides a systematic review...' would improve readability without changing meaning.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive assessment of the survey's scope and utility. We address the major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract and opening sections: the claim of a 'systematic review' of the development from GANs to diffusion models to AR-based and multimodal techniques is not supported by any description of literature search protocol, databases, keywords, inclusion/exclusion criteria, or date range. This directly affects the central assertion that the selected body of work is representative and that the comparative strengths/limitations analysis is unbiased and comprehensive.
Authors: We acknowledge that the manuscript asserts a 'systematic review' without providing an explicit literature search protocol, which is a valid observation. To resolve this, we will revise the abstract and introduction to include a dedicated 'Review Methodology' subsection. This addition will detail the databases consulted (arXiv, Google Scholar, IEEE Xplore, ACM Digital Library), search keywords (e.g., 'video generation GAN', 'diffusion models video synthesis', 'autoregressive video models', 'multimodal video generation'), date range (primarily 2014–2024 with key foundational works), inclusion criteria (peer-reviewed publications and high-impact preprints demonstrating technical novelty or empirical results), and exclusion criteria (non-English works, purely theoretical papers without empirical validation). We will also clarify how the comparative strengths/limitations analysis was derived from the collected literature. The existing GitHub repository already aggregates an extended reference list; we will update it to reflect the search process for transparency. These changes will directly support the representativeness claim. revision: yes
Circularity Check
No circularity: descriptive survey with no derivations or self-referential predictions
full rationale
This paper is a literature review tracing video generation history from GANs through diffusion models to AR and multimodal approaches. It contains no equations, no fitted parameters, no predictions derived from internal data or models, and no derivation chain that reduces to its own inputs by construction. Claims rest on narrative summaries of external cited works rather than any self-definitional or fitted-input structure. Absence of explicit search protocol is a methodological limitation but does not create circularity under the defined patterns, as no load-bearing mathematical or predictive step collapses to the paper's own outputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Denoising diffusion probabilistic models,
J. Ho, A. Jain, and P . Abbeel, “Denoising diffusion probabilistic models,”NeurIPS, 2020. 1, 2, 4
2020
-
[2]
High-resolution image synthesis with latent diffusion models,
R. Rombach, A. Blattmann, D. Lorenz, P . Esser, and B. Ommer, “High-resolution image synthesis with latent diffusion models,” inCVPR, 2022. 1, 2, 3, 4
2022
-
[3]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
A. Blattmann, T. Dockhorn, S. Kulal, D. Mendelevitch, M. Kilian, D. Lorenz, Y. Levi, Z. English, V . Voleti, A. Lettset al., “Stable video diffusion: Scaling latent video diffusion models to large datasets,”arXiv preprint arXiv:2311.15127, 2023. 1, 4, 7, 13
work page internal anchor Pith review arXiv 2023
-
[4]
Video generation models as world simulators,
T. Brooks, B. Peebles, C. Holmes, W. DePue, Y. Guo, L. Jing, D. Schnurr, J. Taylor, T. Luhman, E. Luhman, C. Ng, R. Wang, and A. Ramesh, “Video generation models as world simulators,” 2024. [Online]. Available: https://openai. com/research/video-generation-models-as-world-simulators 1, 13, 16
2024
-
[5]
Google, “Veo3,” https://deepmind.google/models/veo/, 2025. 1, 13
2025
-
[6]
Seedance 1.0: Exploring the Boundaries of Video Generation Models
Y. Gao, H. Guo, T. Hoang, and e. a. Weilin Huang, “Seedance 1.0: Exploring the boundaries of video generation models,”ArXiv, vol. abs/2506.09113, 2025. 1
work page internal anchor Pith review arXiv 2025
-
[7]
Wan: Open and advanced large-scale video generative models,
W. Team, “Wan: Open and advanced large-scale video generative models,” 2025. 1, 4, 7, 12, 13, 16
2025
-
[8]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
W. Kong, Q. Tian, Z. Zhang, R. Min, Z. Dai, J. Zhou, J. Xiong, X. Li, B. Wu, J. Zhanget al., “Hunyuanvideo: A systematic framework for large video generative models,”arXiv preprint arXiv:2412.03603, 2024. 1, 4, 8, 12, 13, 16
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
arXiv preprint arXiv:2403.16407 (2024)
C. Li, D. Huang, Z. Lu, Y. Xiao, Q. Pei, and L. Bai, “A survey on long video generation: Challenges, methods, and prospects,” arXiv preprint arXiv:2403.16407, 2024. 1, 2
-
[10]
A comprehensive survey on human video generation: Challenges, methods, and insights,
W. Lei, J. Wang, F. Ma, G. Huang, and L. Liu, “A comprehensive survey on human video generation: Challenges, methods, and insights,”arXiv preprint arXiv:2407.08428, 2024. 1
-
[11]
Video generative adversarial networks: a review,
N. Aldausari, A. Sowmya, N. Marcus, and G. Mohammadi, “Video generative adversarial networks: a review,”ACM Com- puting Surveys (CSUR), 2022. 1, 2
2022
-
[12]
A survey on video diffusion models,
Z. Xing, Q. Feng, H. Chen, Q. Dai, H. Hu, H. Xu, Z. Wu, and Y.- G. Jiang, “A survey on video diffusion models,”ACM Computing Surveys, 2024. 1, 2
2024
-
[13]
Video diffusion models: A survey.arXiv preprint arXiv:2405.03150,
A. Melnik, M. Ljubljanac, C. Lu, Q. Yan, W. Ren, and H. Ritter, “Video diffusion models: A survey,”arXiv preprint arXiv:2405.03150, 2024. 1, 2
-
[14]
Diffusion model-based video editing: A survey.arXiv preprint arXiv:2407.07111, 2024
W. Sun, R.-C. Tu, J. Liao, and D. Tao, “Diffusion model-based video editing: A survey,”arXiv preprint arXiv:2407.07111, 2024. 1, 2
-
[15]
Generative adver- sarial nets,
I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde- Farley, S. Ozair, A. Courville, and Y. Bengio, “Generative adver- sarial nets,” inNeurIPS, 2014. 1, 2
2014
-
[16]
A style-based generator architecture for generative adversarial networks,
T. Karras, S. Laine, and T. Aila, “A style-based generator architecture for generative adversarial networks,” inCVPR, 2019. 1, 3, 4, 6
2019
-
[17]
Videopoet: A large language model for zero- shot video generation,
D. Kondratyuk, L. Yu, X. Gu, J. Lezama, and e. a. Jonathan Huang, “Videopoet: A large language model for zero- shot video generation,” inICML, 2024. 1, 10
2024
-
[18]
Emu3: Next-Token Prediction is All You Need
X. Wang, X. Zhang, Z. Luo, Q. Sun, Y. Cui, J. Wang, F. Zhang, Y. Wang, Z. Li, Q. Yuet al., “Emu3: Next-token prediction is all you need,”arXiv preprint arXiv:2409.18869, 2024. 1
work page internal anchor Pith review arXiv 2024
-
[19]
Generating videos with scene dynamics,
C. Vondrick, H. Pirsiavash, and A. Torralba, “Generating videos with scene dynamics,” 2016. 2, 5
2016
-
[20]
Decomposing motion and content for natural video sequence prediction, 2018
R. Villegas, J. Yang, S. Hong, X. Lin, and H. Lee, “Decomposing motion and content for natural video sequence prediction,”arXiv preprint arXiv:1706.08033, 2017. 2, 5
-
[21]
Mocogan: Decomposing motion and content for video generation,
S. Tulyakov, M.-Y. Liu, X. Yang, and J. Kautz, “Mocogan: Decomposing motion and content for video generation,” in CVPR, 2018. 2, 4, 5
2018
-
[22]
T.-C. Wang, M.-Y. Liu, J.-Y. Zhu, G. Liu, A. Tao, J. Kautz, and B. Catanzaro, “Video-to-video synthesis,”arXiv preprint arXiv:1808.06601, 2018. 2
-
[23]
Pixel recurrent neural networks,
A. Van Den Oord, N. Kalchbrenner, and K. Kavukcuoglu, “Pixel recurrent neural networks,” inICML, 2016. 2, 3, 9
2016
-
[24]
Video pixel networks,
N. Kalchbrenner, A. van den Oord, K. Simonyan, I. Danihelka, O. Vinyals, A. Graves, and K. Kavukcuoglu, “Video pixel networks,” inICML, 2017. 2, 9
2017
-
[25]
Parallel multiscale autoregressive density estimation,
S. Reed, A. van den Oord, N. Kalchbrenner, S. G. Colmenarejo, Z. Wang, Y. Chen, D. Belov, and N. de Freitas, “Parallel multiscale autoregressive density estimation,” inICML, 2017. 2, 9
2017
-
[26]
Scaling autore- gressive video models,
D. Weissenborn, O. T ¨ackstr¨om, and J. Uszkoreit, “Scaling autore- gressive video models,” inICLR, 2020. 2, 9
2020
-
[27]
Videogpt: Video generation using vq-vae and transformers,
W. Yan, Y. Zhang, P . Abbeel, and A. Srinivas, “Videogpt: Video generation using vq-vae and transformers,” 2021. 3, 4
2021
-
[28]
Language model beats diffusion - tokenizer is key to visual generation,
L. Yu, J. Lezama, N. B. Gundavarapu, L. Versari, K. Sohn, D. Minnen, Y. Cheng, A. Gupta, X. Gu, A. G. Hauptmann, B. Gong, M.-H. Yang, I. Essa, D. A. Ross, and L. Jiang, “Language model beats diffusion - tokenizer is key to visual generation,” in ICLR, 2024. 3, 9
2024
-
[29]
Neural discrete representa- tion learning,
A. Van Den Oord, O. Vinyalset al., “Neural discrete representa- tion learning,”NeurIPS, 2017. 3, 4, 9
2017
-
[30]
Magvit: Masked generative video transformer,
L. Yu, Y. Cheng, K. Sohn, J. Lezama, H. Zhang, H. Chang, A. G. Hauptmann, M.-H. Yang, Y. Hao, I. Essa, and L. Jiang, “Magvit: Masked generative video transformer,” inCVPR, 2023. 4, 9, 10
2023
-
[31]
Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2,
I. Skorokhodov, S. Tulyakov, and M. Elhoseiny, “Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2,” inCVPR, 2022. 4, 6
2022
-
[32]
Videocrafter2: Overcoming data limitations for high- quality video diffusion models,
H. Chen, Y. Zhang, X. Cun, M. Xia, X. Wang, C. Weng, and Y. Shan, “Videocrafter2: Overcoming data limitations for high- quality video diffusion models,” inCVPR, 2024. 4, 7, 13
2024
-
[33]
Scalable diffusion models with transform- ers,
W. Peebles and S. Xie, “Scalable diffusion models with transform- ers,” inICCV, 2023. 4, 7
2023
-
[34]
Learning spatiotemporal features with 3d convolutional net- works,
D. Tran, L. Bourdev, R. Fergus, L. Torresani, and M. Paluri, “Learning spatiotemporal features with 3d convolutional net- works,” inICCV, 2015. 5
2015
-
[35]
A. Clark, J. Donahue, and K. Simonyan, “Adversarial video generation on complex datasets,”arXiv preprint arXiv:1907.06571,
-
[36]
Temporal generative adversarial nets with singular value clipping,
M. Saito, E. Matsumoto, and S. Saito, “Temporal generative adversarial nets with singular value clipping,” inICCV, 2017. 5
2017
-
[37]
Finding structure in time,
J. L. Elman, “Finding structure in time,”Cognitive ScienceV, 1990. 5
1990
-
[38]
Gradient-based learning applied to document recognition,
Y. LeCun, L. Bottou, Y. Bengio, and P . Haffner, “Gradient-based learning applied to document recognition,”Proceedings of the IEEE, 1998. 5
1998
-
[39]
arXiv preprint arXiv:2104.15069 , year=
Y. Tian, J. Ren, M. Chai, K. Olszewski, X. Peng, D. N. Metaxas, and S. Tulyakov, “A good image generator is what you need for high-resolution video synthesis,”arXiv preprint arXiv:2104.15069,
-
[40]
Temporal shift gan for large scale video generation,
A. Munoz, M. Zolfaghari, M. Argus, and T. Brox, “Temporal shift gan for large scale video generation,” inWACV, 2021. 5
2021
-
[41]
Dual motion gan for future-flow embedded video prediction,
X. Liang, L. Lee, W. Dai, and E. P . Xing, “Dual motion gan for future-flow embedded video prediction,” inICCV, 2017. 5 19
2017
-
[42]
Hierarchical video generation from orthogonal information: Optical flow and texture,
K. Ohnishi, S. Yamamoto, Y. Ushiku, and T. Harada, “Hierarchical video generation from orthogonal information: Optical flow and texture,” inAAAI, 2018. 6
2018
-
[43]
Fw- gan: Flow-navigated warping gan for video virtual try-on,
H. Dong, X. Liang, X. Shen, B. Wu, B.-C. Chen, and J. Yin, “Fw- gan: Flow-navigated warping gan for video virtual try-on,” in ICCV, 2019. 6
2019
-
[44]
Progressive Growing of GANs for Improved Quality, Stability, and Variation
T. Karras, T. Aila, S. Laine, and J. Lehtinen, “Progressive growing of gans for improved quality, stability, and variation,”arXiv preprint arXiv:1710.10196, 2017. 6
work page internal anchor Pith review arXiv 2017
-
[45]
D. Acharya, Z. Huang, D. P . Paudel, and L. Van Gool, “Towards high resolution video generation with progressive growing of sliced wasserstein gans,”arXiv preprint arXiv:1810.02419, 2018. 6
-
[46]
Swgan: A new algorithm of adhesive rice image segmentation based on improved generative adversarial networks,
S. Zeng, H. Zhang, Y. Chen, Z. Sheng, Z. Kang, and H. Li, “Swgan: A new algorithm of adhesive rice image segmentation based on improved generative adversarial networks,”Computers and Electronics in Agriculture. 6
-
[47]
Sliced wasserstein generative models,
J. Wu, Z. Huang, D. Acharya, W. Li, J. Thoma, D. P . Paudel, and L. V . Gool, “Sliced wasserstein generative models,” inCVPR,
-
[48]
Hierarchical patch vae-gan: Generating diverse videos from a single sample,
S. Gur, S. Benaim, and L. Wolf, “Hierarchical patch vae-gan: Generating diverse videos from a single sample,” inNeurIPS,
-
[49]
Stylevideogan: A temporal generative model using a pretrained stylegan,
G. Fox, A. Tewari, M. Elgharib, and C. Theobalt, “Stylevideogan: A temporal generative model using a pretrained stylegan,”arXiv preprint arXiv:2107.07224, 2021. 6
-
[50]
Stylefacev: Face video generation via decomposing and recomposing pretrained stylegan3,
H. Qiu, Y. Jiang, H. Zhou, W. Wu, and Z. Liu, “Stylefacev: Face video generation via decomposing and recomposing pretrained stylegan3,”arXiv preprint arXiv:2208.07862, 2022. 6
-
[51]
Styleheat: One-shot high-resolution editable talking face generation via pre-trained stylegan,
F. Yin, Y. Zhang, X. Cun, M. Cao, Y. Fan, X. Wang, Q. Bai, B. Wu, J. Wang, and Y. Yang, “Styleheat: One-shot high-resolution editable talking face generation via pre-trained stylegan,” in ECCV, 2022. 6
2022
-
[52]
Make-A-Video: Text-to-Video Generation without Text-Video Data
U. Singer, A. Polyak, T. Hayes, X. Yin, J. An, S. Zhang, Q. Hu, H. Yang, O. Ashual, O. Gafniet al., “Make-a-video: Text-to-video generation without text-video data,”arXiv preprint arXiv:2209.14792, 2022. 6
work page internal anchor Pith review arXiv 2022
-
[53]
Imagen video: High definition video generation with diffusion models,
J. Ho, W. Chan, C. Saharia, J. Whang, R. Gao, A. A. Gritsenko, D. P . Kingma, B. Poole, M. Norouzi, D. J. Fleet, and T. Salimans, “Imagen video: High definition video generation with diffusion models,”ArXiv, 2022. 6
2022
-
[54]
Lavie: High-quality video generation with cascaded latent diffusion models,
Y. Wang, X. Chen, X. Ma, S. Zhou, Z. Huang, Y. Wang, C. Yang, Y. He, J. Yu, P . Yanget al., “Lavie: High-quality video generation with cascaded latent diffusion models,”IJCV, 2024. 6
2024
-
[55]
Latent Video Diffusion Models for High-Fidelity Long Video Generation
Y. He, T. Yang, Y. Zhang, Y. Shan, and Q. Chen, “Latent video diffusion models for high-fidelity long video generation,”arXiv preprint arXiv:2211.13221, 2022. 6
work page internal anchor Pith review arXiv 2022
-
[56]
Align your latents: High-resolution video synthesis with latent diffusion models,
A. Blattmann, R. Rombach, H. Ling, T. Dockhorn, S. W. Kim, S. Fidler, and K. Kreis, “Align your latents: High-resolution video synthesis with latent diffusion models,” inCVPR, 2023. 6
2023
-
[57]
Show-1: Marrying pixel and latent diffusion models for text-to-video generation,
D. J. Zhang, J. Z. Wu, J.-W. Liu, R. Zhao, L. Ran, Y. Gu, D. Gao, and M. Z. Shou, “Show-1: Marrying pixel and latent diffusion models for text-to-video generation,”IJCV, 2024. 6
2024
-
[58]
Videofactory: Swap attention in spatiotemporal diffusions for text-to-video generation,
W. Wang, H. Yang, Z. Tuo, H. He, J. Zhu, J. Fu, and J. Liu, “Videofactory: Swap attention in spatiotemporal diffusions for text-to-video generation,” 2023. 7
2023
-
[59]
ModelScope Text-to-Video Technical Report
J. Wang, H. Yuan, D. Chen, Y. Zhang, X. Wang, and S. Zhang, “Modelscope text-to-video technical report,”arXiv preprint arXiv:2308.06571, 2023. 7
work page internal anchor Pith review arXiv 2023
-
[61]
Lora: Low-rank adaptation of large language models
E. J. Hu, Y. Shen, P . Wallis, Z. Allen-Zhu, Y. Li, S. Wang, L. Wang, W. Chenet al., “Lora: Low-rank adaptation of large language models.”ICLR, 2022. 7, 15
2022
-
[62]
Dynamicrafter: Animating open-domain images with video diffusion priors,
J. Xing, M. Xia, Y. Zhang, H. Chen, W. Yu, H. Liu, G. Liu, X. Wang, Y. Shan, and T.-T. Wong, “Dynamicrafter: Animating open-domain images with video diffusion priors,” inECCV, 2024. 7
2024
-
[63]
arXiv preprint arXiv:2311.10709 (2023)
R. Girdhar, M. Singh, A. Brown, Q. Duval, S. Azadi, S. Rambhatla, A. Shah, X. Yin, D. Parikh, and I. Misra, “Emu video: Factorizing text-to-video generation by explicit image conditioning (2023),” arXiv preprint arXiv:2311.10709. 7
-
[64]
Microcinema: A divide-and- conquer approach for text-to-video generation,
Y. Wang, J. Bao, W. Weng, R. Feng, D. Yin, T. Yang, J. Zhang, Q. Dai, Z. Zhao, C. Wanget al., “Microcinema: A divide-and- conquer approach for text-to-video generation,” inCVPR, 2024. 7
2024
-
[65]
Make pixels dance: High-dynamic video generation,
Y. Zeng, G. Wei, J. Zheng, J. Zou, Y. Wei, Y. Zhang, and H. Li, “Make pixels dance: High-dynamic video generation,” inCVPR,
-
[66]
Dysen-vdm: Empowering dynamics-aware text-to-video diffusion with llms,
H. Fei, S. Wu, W. Ji, H. Zhang, and T.-S. Chua, “Dysen-vdm: Empowering dynamics-aware text-to-video diffusion with llms,” inCVPR, 2024. 7
2024
-
[67]
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkat et al., “Gpt-4 technical report,”arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[68]
H. Lin, A. Zala, J. Cho, and M. Bansal, “Videodirectorgpt: Con- sistent multi-scene video generation via llm-guided planning,” arXiv preprint arXiv:2309.15091, 2023. 7
-
[69]
D. Zhou, W. Wang, H. Yan, W. Lv, Y. Zhu, and J. Feng, “Magicvideo: Efficient video generation with latent diffusion models,”arXiv preprint arXiv:2211.11018, 2022. 7
-
[70]
Simda: Simple diffusion adapter for efficient video generation,
Z. Xing, Q. Dai, H. Hu, Z. Wu, and Y.-G. Jiang, “Simda: Simple diffusion adapter for efficient video generation,” inCVPR, 2024. 7
2024
-
[71]
J. An, S. Zhang, H. Yang, S. Gupta, J.-B. Huang, J. Luo, and X. Yin, “Latent-shift: Latent diffusion with temporal shift for efficient text-to-video generation,”arXiv preprint arXiv:2304.08477, 2023. 7
-
[72]
Magicvideo-v2: Multi-stage high- aesthetic video generation,
W. Wang, J. Liu, Z. Lin, J. Yan, S. Chen, C. Low, T. Hoang, J. Wu, J. H. Liew, H. Yanet al., “Magicvideo-v2: Multi-stage high- aesthetic video generation,”arXiv preprint arXiv:2401.04468, 2024. 7
-
[73]
Preserve your own correlation: A noise prior for video diffusion models,
S. Ge, S. Nah, G. Liu, T. Poon, A. Tao, B. Catanzaro, D. Jacobs, J.-B. Huang, M.-Y. Liu, and Y. Balaji, “Preserve your own correlation: A noise prior for video diffusion models,” inICCV, 2023. 7
2023
-
[74]
Flexifilm: Long video gen- eration with flexible conditions,
Y. Ouyang, H. Zhao, G. Wanget al., “Flexifilm: Long video gen- eration with flexible conditions,”arXiv preprint arXiv:2404.18620,
-
[75]
Vdt: General-purpose video diffusion transformers via mask modeling,
H. Lu, G. Yang, N. Fei, Y. Huo, Z. Lu, P . Luo, and M. Ding, “Vdt: General-purpose video diffusion transformers via mask modeling,”arXiv preprint arXiv:2305.13311, 2023. 7
-
[76]
Latte: Latent Diffusion Transformer for Video Generation
X. Ma, Y. Wang, G. Jia, X. Chen, Z. Liu, Y.-F. Li, C. Chen, and Y. Qiao, “Latte: Latent diffusion transformer for video generation,”arXiv preprint arXiv:2401.03048, 2024. 7
work page internal anchor Pith review arXiv 2024
-
[77]
Gentron: Diffusion transformers for image and video generation,
S. Chen, M. Xu, J. Ren, Y. Cong, S. He, Y. Xie, A. Sinha, P . Luo, T. Xiang, and J.-M. Perez-Rua, “Gentron: Diffusion transformers for image and video generation,” inCVPR, 2024. 7
2024
-
[78]
Photorealistic video generation with diffusion models,
A. Gupta, L. Yu, K. Sohn, X. Gu, M. Hahn, F.-F. Li, I. Essa, L. Jiang, and J. Lezama, “Photorealistic video generation with diffusion models,” inECCV, 2024. 7
2024
-
[79]
LTX-Video: Realtime Video Latent Diffusion
Y. HaCohen, N. Chiprut, B. Brazowski, D. Shalem, D. Moshe, E. Richardson, E. Levin, G. Shiran, N. Zabari, O. Gordon et al., “Ltx-video: Realtime video latent diffusion,”arXiv preprint arXiv:2501.00103, 2024. 7
work page internal anchor Pith review arXiv 2024
-
[80]
Snap video: Scaled spatiotemporal transformers for text-to- video synthesis,
W. Menapace, A. Siarohin, I. Skorokhodov, E. Deyneka, T.- S. Chen, A. Kag, Y. Fang, A. Stoliar, E. Ricci, J. Renet al., “Snap video: Scaled spatiotemporal transformers for text-to- video synthesis,” inCVPR, 2024. 7
2024
-
[81]
Elucidating the design space of diffusion-based generative models,
T. Karras, M. Aittala, T. Aila, and S. Laine, “Elucidating the design space of diffusion-based generative models,”NeurIPS,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.