Recognition: 2 theorem links
· Lean TheoremSubFLOT: Submodel Extraction for Efficient and Personalized Federated Learning via Optimal Transport
Pith reviewed 2026-05-10 19:19 UTC · model grok-4.3
The pith
SubFLOT casts federated pruning as Wasserstein distance minimization on historical client models to produce personalized submodels server-side.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
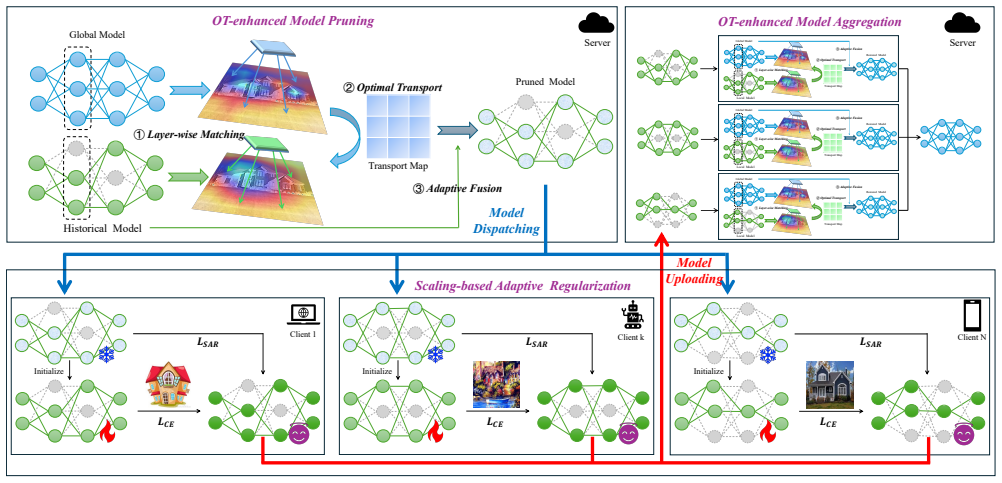
SubFLOT extracts client-specific submodels on the server by solving an optimal-transport problem that matches the global model to historical client checkpoints as distribution proxies, then applies a pruning-rate-dependent adaptive regularizer that penalizes deviation from the global parameters to counteract divergence induced by heterogeneous pruning.
What carries the argument
Optimal Transport-enhanced Pruning (OTP) module that reformulates mask selection as Wasserstein distance minimization between the global model and historical client models used as local-distribution proxies.
If this is right
- All pruning computation moves to the server, removing the need for resource-constrained clients to run pruning routines.
- Parametric divergence among submodels is controlled proportionally to how aggressively each client prunes, supporting stable joint training.
- Privacy is preserved because only model checkpoints, not raw data, are used to guide personalization.
- The same server-side pipeline can produce different sparsity levels for different clients while still sharing a common global backbone.
Where Pith is reading between the lines
- The proxy-model approach could be tested on streaming clients whose data evolves, by replacing fixed history with a decaying window of recent checkpoints.
- The same Wasserstein formulation might be applied to other server-side decisions such as client clustering or layer-wise allocation without requiring new client-side code.
- If the regularization scaling proves robust, it could be combined with existing FL aggregation rules to handle mixed-precision or quantized submodels.
Load-bearing premise
Historical client models remain sufficiently representative of each client's current data distribution that Wasserstein matching can produce useful personalized masks without seeing raw data.
What would settle it
A controlled run in which client data distributions shift sharply after the historical models are collected, causing the OTP-derived submodels to underperform both uniform pruning and non-personalized baselines on the same test sets.
Figures





read the original abstract
Federated Learning (FL) enables collaborative model training while preserving data privacy, but its practical deployment is hampered by system and statistical heterogeneity. While federated network pruning offers a path to mitigate these issues, existing methods face a critical dilemma: server-side pruning lacks personalization, whereas client-side pruning is computationally prohibitive for resource-constrained devices. Furthermore, the pruning process itself induces significant parametric divergence among heterogeneous submodels, destabilizing training and hindering global convergence. To address these challenges, we propose SubFLOT, a novel framework for server-side personalized federated pruning. SubFLOT introduces an Optimal Transport-enhanced Pruning (OTP) module that treats historical client models as proxies for local data distributions, formulating the pruning task as a Wasserstein distance minimization problem to generate customized submodels without accessing raw data. Concurrently, to counteract parametric divergence, our Scaling-based Adaptive Regularization (SAR) module adaptively penalizes a submodel's deviation from the global model, with the penalty's strength scaled by the client's pruning rate. Comprehensive experiments demonstrate that SubFLOT consistently and substantially outperforms state-of-the-art methods, underscoring its potential for deploying efficient and personalized models on resource-constrained edge devices.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SubFLOT, a server-side framework for personalized federated pruning in heterogeneous FL settings. It introduces an Optimal Transport-enhanced Pruning (OTP) module that casts submodel extraction as Wasserstein distance minimization between the global model and historical client models (treated as proxies for local data distributions), and a Scaling-based Adaptive Regularization (SAR) module that adaptively penalizes submodel deviation from the global model with strength scaled by the client's pruning rate. The central claim is that this combination enables efficient, personalized submodels without raw data access or heavy client computation, with experiments showing consistent and substantial outperformance over SOTA methods for resource-constrained edge devices.
Significance. If the proxy assumption and experimental results hold, the work could meaningfully advance practical FL deployment by resolving the personalization-vs-efficiency dilemma in network pruning. The OT-based formulation and adaptive regularization are technically interesting contributions that directly target parametric divergence and heterogeneity; reproducible code or parameter-free derivations would further strengthen its value.
major comments (2)
- [OTP module (§3)] OTP module (formulation in §3): The personalization benefit rests entirely on the untested assumption that historical client models serve as reliable proxies for current local data distributions when minimizing Wasserstein distance for pruning. No analysis is provided of how this holds under client drift, non-stationary data, or partial participation; if the proxy fails, the extracted submodels cease to be personalized and the claimed gains over server-side baselines collapse. This is load-bearing for the central claim.
- [Experiments] Experiments section: The abstract asserts 'consistent and substantial outperformance,' yet the manuscript must include quantitative tables with specific metrics (accuracy, communication cost, convergence speed), ablations isolating OTP vs. SAR, error bars, and tests across varying heterogeneity levels and drift scenarios. Without these, the magnitude and robustness of the improvements cannot be assessed.
minor comments (2)
- [Abstract] Abstract: Lacks any numerical highlights or key result metrics despite claiming comprehensive experiments; adding 1-2 concrete numbers would improve clarity.
- [Notation] Notation: Ensure the pruning rate and Wasserstein formulation are defined consistently when first introduced and reused in later sections.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for major revision. The comments highlight important aspects that will strengthen the presentation of our work. We address each major comment below and commit to the necessary revisions.
read point-by-point responses
-
Referee: [OTP module (§3)] OTP module (formulation in §3): The personalization benefit rests entirely on the untested assumption that historical client models serve as reliable proxies for current local data distributions when minimizing Wasserstein distance for pruning. No analysis is provided of how this holds under client drift, non-stationary data, or partial participation; if the proxy fails, the extracted submodels cease to be personalized and the claimed gains over server-side baselines collapse. This is load-bearing for the central claim.
Authors: We agree that the proxy assumption underlying the OTP module is central to the personalization claim and merits explicit analysis. In the revised manuscript, we will add a dedicated discussion subsection following the OTP formulation in §3. This will include: (i) theoretical reasoning on the conditions under which historical models remain reasonable proxies (e.g., under bounded drift), (ii) empirical sensitivity analysis using controlled simulations of client drift and partial participation, and (iii) clarification of how the SAR module provides robustness when the proxy is imperfect. These additions will make the load-bearing assumption transparent and substantiate the claimed benefits. revision: yes
-
Referee: [Experiments] Experiments section: The abstract asserts 'consistent and substantial outperformance,' yet the manuscript must include quantitative tables with specific metrics (accuracy, communication cost, convergence speed), ablations isolating OTP vs. SAR, error bars, and tests across varying heterogeneity levels and drift scenarios. Without these, the magnitude and robustness of the improvements cannot be assessed.
Authors: We concur that the experimental results require more granular and comprehensive reporting to allow proper assessment of the claimed gains. In the revised version, we will substantially expand §4 (Experiments) to include: full quantitative tables reporting accuracy, communication cost, and convergence speed with exact numerical values; ablation studies that isolate the individual contributions of OTP and SAR; error bars computed over multiple random seeds; and additional experiments that systematically vary heterogeneity levels (e.g., Dirichlet concentration parameters) and introduce controlled client drift scenarios. These changes will provide the quantitative evidence needed to evaluate the magnitude and robustness of SubFLOT's improvements. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper introduces SubFLOT with an OTP module casting pruning as Wasserstein distance minimization using historical client models as proxies, plus a SAR regularization module. No equations, self-citations, or steps in the abstract or described framework reduce any claimed result (e.g., outperformance) to a fitted quantity or input by construction. The approach relies on standard optimal transport and adaptive regularization applied to external assumptions about proxies; performance is asserted via experiments rather than tautological derivation. This is self-contained against external benchmarks with no load-bearing self-referential reductions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Historical client models serve as proxies for local data distributions
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
OTP module that treats historical client models as proxies for local data distributions, formulating the pruning task as a Wasserstein distance minimization problem
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Scaling-based Adaptive Regularization (SAR) module adaptively penalizes a submodel's deviation from the global model, with the penalty's strength scaled by the client's pruning rate
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Test-time Scaling over Perception: Resolving the Grounding Paradox in Thinking with Images
TTSP resolves the Grounding Paradox by treating perception as a scalable test-time process that generates, filters, and iteratively refines multiple visual exploration traces, outperforming baselines on high-resolutio...
Reference graph
Works this paper leans on
-
[1]
Fe- drolex: Model-heterogeneous federated learning with rolling sub-model extraction.Advances in neural information pro- cessing systems, 35:29677–29690, 2022
Samiul Alam, Luyang Liu, Ming Yan, and Mi Zhang. Fe- drolex: Model-heterogeneous federated learning with rolling sub-model extraction.Advances in neural information pro- cessing systems, 35:29677–29690, 2022. 5
2022
-
[2]
Human activity recognition on smartphones using a multiclass hardware-friendly support vector machine
Davide Anguita, Alessandro Ghio, Luca Oneto, Xavier Parra, and Jorge L Reyes-Ortiz. Human activity recognition on smartphones using a multiclass hardware-friendly support vector machine. InAmbient Assisted Living and Home Care: 4th International Workshop, IWAAL 2012, Vitoria-Gasteiz, Spain, December 3-5, 2012. Proceedings 4, pages 216–223. Springer, 2012. 5
2012
-
[3]
Brendan McMahan, and Ameet Talwalkar
Sebastian Caldas, Jakub Kone ˇcny, H. Brendan McMahan, and Ameet Talwalkar. Expanding the reach of federated learning by reducing client resource requirements, 2019. 5
2019
-
[4]
Fedawa: Aggrega- tion weight adjustment in federated domain generalization
Yiming Chen, Nan He, and Lifeng Sun. Fedawa: Aggrega- tion weight adjustment in federated domain generalization. In2024 IEEE International Conference on Image Process- ing (ICIP), pages 451–457. IEEE, 2024. 1
2024
-
[5]
Fedtg: Text-guided federated domain generalization
Yiming Chen, Nan He, and Lifeng Sun. Fedtg: Text-guided federated domain generalization. InICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE, 2025. 11
2025
-
[6]
Flexfl: Heterogeneous federated learn- ing via apoz-guided flexible pruning in uncertain scenarios
Zekai Chen, Chentao Jia, Ming Hu, Xiaofei Xie, Anran Li, and Mingsong Chen. Flexfl: Heterogeneous federated learn- ing via apoz-guided flexible pruning in uncertain scenarios. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 43(11):4069–4080, 2024. 5
2024
-
[7]
A Downsampled Variant of ImageNet as an Alternative to the CIFAR datasets
Patryk Chrabaszcz, Ilya Loshchilov, and Frank Hutter. A Downsampled Variant of Imagenet as an Alternative to the Cifar Datasets.arXiv preprint arXiv:1707.08819, 2017. 5
work page Pith review arXiv 2017
-
[8]
Deepjdot: Deep joint distribution optimal transport for unsupervised domain adaptation
Bharath Bhushan Damodaran, Benjamin Kellenberger, R ´emi Flamary, Devis Tuia, and Nicolas Courty. Deepjdot: Deep joint distribution optimal transport for unsupervised domain adaptation. InProceedings of the European conference on computer vision (ECCV), pages 447–463, 2018. 2
2018
-
[9]
Tailorfl: Dual- personalized federated learning under system and data het- erogeneity
Yongheng Deng, Weining Chen, Ju Ren, Feng Lyu, Yang Liu, Yunxin Liu, and Yaoxue Zhang. Tailorfl: Dual- personalized federated learning under system and data het- erogeneity. InProceedings of the 20th ACM conference on embedded networked sensor systems, pages 592–606, 2022. 1
2022
-
[10]
Heterofl: Com- putation and communication efficient federated learning for heterogeneous clients
Enmao Diao, Jie Ding, and Vahid Tarokh. Heterofl: Com- putation and communication efficient federated learning for heterogeneous clients. InInternational Conference on Learning Representations, 2021. 1, 4, 5
2021
-
[11]
Dinh, Nguyen H
Canh T. Dinh, Nguyen H. Tran, and Tuan Dung Nguyen. Per- sonalized federated learning with moreau envelopes, 2022. 14
2022
-
[12]
Sannara Ek, Kaile Wang, Franc ¸ois Portet, Philippe Lalanda, and Jiannong Cao. Fedali: Personalized federated learning with aligned prototypes through optimal transport.arXiv preprint arXiv:2411.10595, 2024. 2
-
[13]
Per- sonalized federated learning: A meta-learning approach,
Alireza Fallah, Aryan Mokhtari, and Asuman Ozdaglar. Per- sonalized federated learning: A meta-learning approach,
-
[14]
Unbalanced minibatch optimal transport; applica- tions to domain adaptation
Kilian Fatras, Thibault S ´ejourn´e, R´emi Flamary, and Nicolas Courty. Unbalanced minibatch optimal transport; applica- tions to domain adaptation. InInternational Conference on Machine Learning, pages 3186–3197. PMLR, 2021. 2
2021
-
[15]
Kd3a: Un- supervised multi-source decentralized domain adaptation via knowledge distillation
Haozhe Feng, Zhaoyang You, Minghao Chen, Tianye Zhang, Minfeng Zhu, Fei Wu, Chao Wu, and Wei Chen. Kd3a: Un- supervised multi-source decentralized domain adaptation via knowledge distillation. InProceedings of the 38th Interna- tional Conference on Machine Learning, pages 3274–3283. PMLR, 2021. 5
2021
-
[16]
The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks
Jonathan Frankle and Michael Carbin. The lottery ticket hy- pothesis: Finding sparse, trainable neural networks.arXiv preprint arXiv:1803.03635, 2018. 1
work page Pith review arXiv 2018
-
[17]
Fedcs: Coreset selec- tion for federated learning
Chenhe Hao, Weiying Xie, Daixun Li, Haonan Qin, Hangyu Ye, Leyuan Fang, and Yunsong Li. Fedcs: Coreset selec- tion for federated learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 15434–15443, 2025. 4
2025
-
[18]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2016. 5
2016
-
[19]
Dynfed: Adaptive federated learning via quantization-aware knowledge distillation
Nan He, Yiming Chen, Zheng Jiang, Song Yang, and Lifeng Sun. Dynfed: Adaptive federated learning via quantization-aware knowledge distillation. InProceedings of the 33rd ACM International Conference on Multimedia, pages 11844–11852, 2025. 1
2025
-
[20]
Personalized cross-silo federated learning on non-iid data, 2021
Yutao Huang, Lingyang Chu, Zirui Zhou, Lanjun Wang, Jiangchuan Liu, Jian Pei, and Yong Zhang. Personalized cross-silo federated learning on non-iid data, 2021. 14
2021
-
[21]
Scalefl: Resource- adaptive federated learning with heterogeneous clients
Fatih Ilhan, Gong Su, and Ling Liu. Scalefl: Resource- adaptive federated learning with heterogeneous clients. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 24532–24541, 2023. 5
2023
-
[22]
Adaptivefl: Adaptive heterogeneous federated learning for resource-constrained aiot systems
Chentao Jia, Ming Hu, Zekai Chen, Yanxin Yang, Xiaofei Xie, Yang Liu, and Mingsong Chen. Adaptivefl: Adaptive heterogeneous federated learning for resource-constrained aiot systems. InProceedings of the 61st ACM/IEEE Design Automation Conference, pages 1–6, 2024. 5
2024
-
[23]
Fedmp: Federated learning through adaptive model pruning in heterogeneous edge com- puting
Zhida Jiang, Yang Xu, Hongli Xu, Zhiyuan Wang, Chun- ming Qiao, and Yangming Zhao. Fedmp: Federated learning through adaptive model pruning in heterogeneous edge com- puting. In2022 IEEE 38th International Conference on Data Engineering (ICDE), pages 767–779. IEEE, 2022. 1, 2, 5
2022
-
[24]
Medvr: Annotation-free medical visual reasoning via agentic rein- forcement learning
Zheng Jiang, Heng Guo, Chengyu Fang, Changchen Xiao, Xinyang Hu, Lifeng Sun, and Minfeng Xu. Medvr: Annotation-free medical visual reasoning via agentic rein- forcement learning. InThe Fourteenth International Confer- ence on Learning Representations, 2026. 11
2026
-
[25]
Bag of Tricks for Efficient Text Classification
Armand Joulin, Edouard Grave, Piotr Bojanowski, and Tomas Mikolov. Bag of tricks for efficient text classification. arXiv preprint arXiv:1607.01759, 2016. 5
work page Pith review arXiv 2016
-
[26]
On the translocation of masses.Jour- nal of mathematical sciences, 133(4):1381–1382, 2006
Leonid V Kantorovich. On the translocation of masses.Jour- nal of mathematical sciences, 133(4):1381–1382, 2006. 2
2006
-
[27]
Depthfl: Depthwise federated learning for hetero- geneous clients
Minjae Kim, Sangyoon Yu, Suhyun Kim, and Soo-Mook Moon. Depthfl: Depthwise federated learning for hetero- geneous clients. InThe Eleventh International Conference on Learning Representations, 2022. 1, 5
2022
-
[28]
Learning Multiple Layers of Features From Tiny Images.Technical Report,
Alex Krizhevsky and Hinton Geoffrey. Learning Multiple Layers of Features From Tiny Images.Technical Report,
-
[29]
Gradient-based learning applied to document recog- nition.Proceedings of the IEEE, 86(11):2278–2324, 1998
Yann LeCun, L ´eon Bottou, Yoshua Bengio, and Patrick Haffner. Gradient-based learning applied to document recog- nition.Proceedings of the IEEE, 86(11):2278–2324, 1998. 5
1998
-
[30]
Fedmask: Joint computation and communication- efficient personalized federated learning via heterogeneous masking
Ang Li, Jingwei Sun, Xiao Zeng, Mi Zhang, Hai Li, and Yi- ran Chen. Fedmask: Joint computation and communication- efficient personalized federated learning via heterogeneous masking. InProceedings of the 19th ACM conference on embedded networked sensor systems, pages 42–55, 2021. 2
2021
-
[31]
Global and local prompts cooperation via optimal transport for fed- erated learning
Hongxia Li, Wei Huang, Jingya Wang, and Ye Shi. Global and local prompts cooperation via optimal transport for fed- erated learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12151– 12161, 2024. 2
2024
-
[32]
On the convergence of fedavg on non-iid data
Xiang Li, Kaixuan Huang, Wenhao Yang, Shusen Wang, and Zhihua Zhang. On the convergence of fedavg on non-iid data. InInternational Conference on Learning Representa- tions, 2019. 11
2019
-
[33]
Adaptive channel sparsity for federated learning under system heterogeneity
Dongping Liao, Xitong Gao, Yiren Zhao, and Cheng-Zhong Xu. Adaptive channel sparsity for federated learning under system heterogeneity. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 20432–20441, 2023. 5
2023
-
[34]
Communication- efficient learning of deep networks from decentralized data
Brendan McMahan, Eider Moore, Daniel Ramage, Seth Hampson, and Blaise Aguera y Arcas. Communication- efficient learning of deep networks from decentralized data. InArtificial intelligence and statistics, pages 1273–1282. PMLR, 2017. 1
2017
-
[35]
Mobilenetv2: Inverted residuals and linear bottlenecks
Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zh- moginov, and Liang-Chieh Chen. Mobilenetv2: Inverted residuals and linear bottlenecks. InProceedings of the IEEE conference on computer vision and pattern recogni- tion, pages 4510–4520, 2018. 5
2018
-
[36]
Grad-cam: Visual explanations from deep networks via gradient-based localization
Ramprasaath R Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Batra. Grad-cam: Visual explanations from deep networks via gradient-based localization. InProceedings of the IEEE in- ternational conference on computer vision, pages 618–626,
-
[37]
Very Deep Convolutional Networks for Large-Scale Image Recognition
Karen Simonyan and Andrew Zisserman. Very deep convo- lutional networks for large-scale image recognition.arXiv preprint arXiv:1409.1556, 2014. 5
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[38]
Model fusion via opti- mal transport.Advances in Neural Information Processing Systems, 33:22045–22055, 2020
Sidak Pal Singh and Martin Jaggi. Model fusion via opti- mal transport.Advances in Neural Information Processing Systems, 33:22045–22055, 2020. 7
2020
-
[39]
Fed- dse: Distribution-aware sub-model extraction for federated learning over resource-constrained devices
Haozhao Wang, Yabo Jia, Meng Zhang, Qinghao Hu, Hao Ren, Peng Sun, Yonggang Wen, and Tianwei Zhang. Fed- dse: Distribution-aware sub-model extraction for federated learning over resource-constrained devices. InProceedings of the ACM Web Conference 2024, pages 2902–2913, 2024. 2, 5
2024
-
[40]
Efficient model personalization in federated learning via client-specific prompt generation
Fu-En Yang, Chien-Yi Wang, and Yu-Chiang Frank Wang. Efficient model personalization in federated learning via client-specific prompt generation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 19159–19168, 2023. 1
2023
-
[41]
Fedp3: Federated personalized and privacy-friendly network pruning under model heterogeneity
Kai Yi, Nidham Gazagnadou, Peter Richt ´arik, and Lingjuan Lyu. Fedp3: Federated personalized and privacy-friendly network pruning under model heterogeneity. InInternational Conference on Learning Representations, 2024. 1, 2
2024
-
[42]
Pacs: A dataset for physical audiovisual commonsense reasoning
Samuel Yu, Peter Wu, Paul Pu Liang, Ruslan Salakhutdinov, and Louis-Philippe Morency. Pacs: A dataset for physical audiovisual commonsense reasoning. InEuropean Confer- ence on Computer Vision, pages 292–309. Springer, 2022. 5
2022
-
[43]
Convolutional neural net- works for human activity recognition using mobile sensors
Ming Zeng, Le T Nguyen, Bo Yu, Ole J Mengshoel, Jiang Zhu, Pang Wu, and Joy Zhang. Convolutional neural net- works for human activity recognition using mobile sensors. In6th international conference on mobile computing, appli- cations and services, pages 197–205. IEEE, 2014. 5
2014
-
[44]
Eliminating domain bias for federated learning in representation space
Jianqing Zhang, Yang Hua, Jian Cao, Hao Wang, Tao Song, Zhengui XUE, Ruhui Ma, and Haibing Guan. Eliminating domain bias for federated learning in representation space. In Thirty-seventh Conference on Neural Information Process- ing Systems, 2023. 4
2023
-
[45]
Fedcp: Separat- ing feature information for personalized federated learning via conditional policy
Jianqing Zhang, Yang Hua, Hao Wang, Tao Song, Zhen- gui Xue, Ruhui Ma, and Haibing Guan. Fedcp: Separat- ing feature information for personalized federated learning via conditional policy. InProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2023. 4
2023
-
[46]
Michael Zhang, Karan Sapra, Sanja Fidler, Serena Ye- ung, and Jose M Alvarez. Personalized federated learn- ing with first order model optimization.arXiv preprint arXiv:2012.08565, 2020. 14
-
[47]
Character-level convolutional networks for text classification.Advances in neural information processing systems, 28, 2015
Xiang Zhang, Junbo Zhao, and Yann LeCun. Character-level convolutional networks for text classification.Advances in neural information processing systems, 28, 2015. 5 Submodel Extraction for Efficient and Personalized Federated Learning via Optimal Transport Supplementary Material
2015
-
[48]
Experimental Setup 8.1. Datasets Our evaluation utilizes a diverse suite of seven datasets to ensure a comprehensive assessment of our method’s perfor- mance across various data modalities, including computer vision (CV), natural language processing (NLP), and Inter- net of Things (IoT) sensor data. The benchmark includes standard single-domain datasets s...
-
[49]
Method Details Algorithm 1 delineates the procedural details of our Op- timal Transport-based Pruning (OTP) module. The Opti- mal Transport-enhanced Aggregation (OTA) module then adapts this layer-wise mechanism, performing a conceptu- ally inverse operation to map the updated client submodels back into the global parameter space for aggregation. To accom...
-
[50]
Additional Experimental Results 10.1. Server-Side Latency and Scalability Analysis A major concern regarding our framework is whether the Optimal Transport (OT) computations introduced by Sub- FLOT incur prohibitive server-side latency. To address this concern, we conducted a wall-clock time analysis on CIFAR-10, as summarized in Fig. 3. We report two com...
-
[51]
Proof of Theorem 1 The proof proceeds by bounding the one-step progress of the global model and then recursively applying the result overTrounds. Lemma 1(Bounded Local Client Drift).Under Assump- tions 3 and 4, afterElocal steps with learning rateη l ≤ 1 4λρmax , the expected squared distance between a client’s updated modelW t i and its personalized anch...
-
[52]
Broader Impact Our proposed SubFLOT framework has significant impli- cations for both the federated learning research community and the deployment of real-world AI systems. By enabling the training of personalized, privacy-preserving models on resource-constrained devices, our methodology contributes to the democratization of advanced machine learning in ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.