Recognition: no theorem link
A Graph-Enhanced Defense Framework for Explainable Fake News Detection with LLM
Pith reviewed 2026-05-10 17:54 UTC · model grok-4.3
The pith
Decomposing news claims into sub-claims in a dependency graph enables reliable fake news detection and explanations from unverified reports.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By constructing a claim-centered graph through sub-claim decomposition and dependency modeling, generating competing explanations via RAG for each sub-claim, and applying a defense-like graph-based inference, the framework achieves state-of-the-art performance in veracity detection and explanation quality using only unverified reports.
What carries the argument
The claim-centered graph, which decomposes the claim into sub-claims and models their dependency relationships to support veracity assessment and explanation generation.
If this is right
- G-Defense provides fine-grained explanations based solely on unverified reports.
- It achieves state-of-the-art performance in veracity detection.
- The approach generates an intuitive explanation graph to assist public verification.
- It addresses inefficiency in existing methods for breaking news.
Where Pith is reading between the lines
- This structure could potentially be adapted for verifying claims in scientific literature or legal documents.
- Future work might test the framework on multilingual claims or in low-resource settings.
- Integrating user feedback into the graph could improve explanation relevance over time.
Load-bearing premise
That modeling sub-claim dependencies in a graph along with competing explanations from unverified reports will lead to accurate overall veracity judgments.
What would settle it
Testing the system on a set of news claims where the retrieved reports contain deliberate misinformation and checking whether the accuracy of veracity predictions falls below current baselines.
Figures



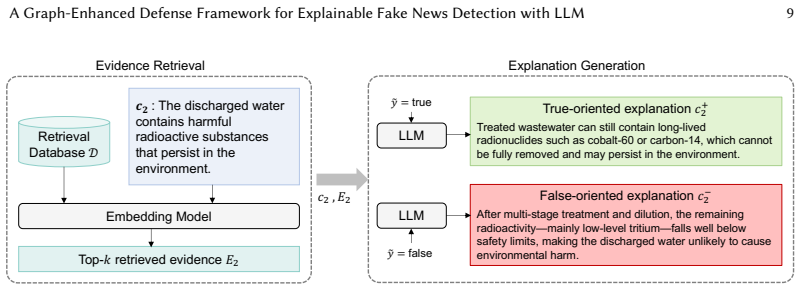
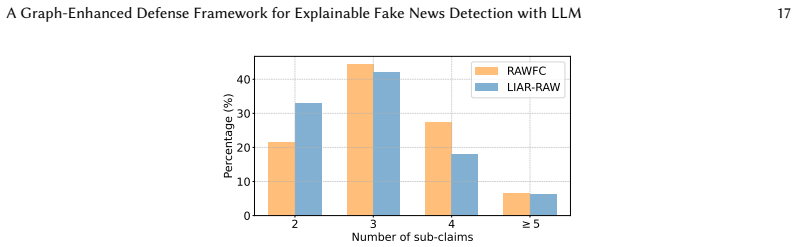
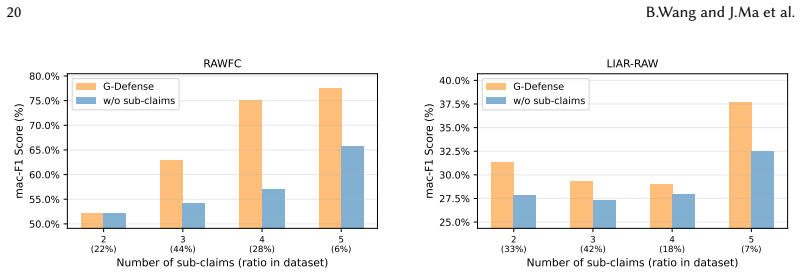


read the original abstract
Explainable fake news detection aims to assess the veracity of news claims while providing human-friendly explanations. Existing methods incorporating investigative journalism are often inefficient and struggle with breaking news. Recent advances in large language models (LLMs) enable leveraging externally retrieved reports as evidence for detection and explanation generation, but unverified reports may introduce inaccuracies. Moreover, effective explainable fake news detection should provide a comprehensible explanation for all aspects of a claim to assist the public in verifying its accuracy. To address these challenges, we propose a graph-enhanced defense framework (G-Defense) that provides fine-grained explanations based solely on unverified reports. Specifically, we construct a claim-centered graph by decomposing the news claim into several sub-claims and modeling their dependency relationships. For each sub-claim, we use the retrieval-augmented generation (RAG) technique to retrieve salient evidence and generate competing explanations. We then introduce a defense-like inference module based on the graph to assess the overall veracity. Finally, we prompt an LLM to generate an intuitive explanation graph. Experimental results demonstrate that G-Defense achieves state-of-the-art performance in both veracity detection and the quality of its explanations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes G-Defense, a graph-enhanced framework for explainable fake news detection. It decomposes a news claim into sub-claims, builds a claim-centered graph capturing dependency relations, applies RAG to retrieve salient evidence and generate competing explanations per sub-claim from unverified reports, runs a defense-like inference module over the graph to produce an overall veracity label, and finally prompts an LLM to output an intuitive explanation graph. The authors claim that this yields state-of-the-art performance on both veracity detection and explanation quality.
Significance. If the experimental claims hold and the inference module demonstrably filters unreliable signals, the work would offer a concrete advance in handling unverified external evidence for explainable detection. The combination of sub-claim decomposition, competing explanations, and graph-structured aggregation addresses a recognized limitation of direct LLM prompting on breaking news; reproducible code or parameter-free derivations would further strengthen its impact.
major comments (2)
- [§3] §3 (Method), inference module description: the central claim that the framework produces reliable veracity judgments from unverified RAG reports rests on the defense-like inference module, yet no equations, attention mechanism, aggregation rule, or pseudocode are supplied for how the module weights, filters, or detects inconsistencies among competing explanations. Without an explicit reliability signal or down-weighting step, error propagation from any single misleading report cannot be ruled out.
- [Experimental section] Experimental section (tables/figures reporting results): the SOTA claim is asserted but the manuscript provides no quantitative metrics (accuracy, F1, explanation quality scores), baseline comparisons, ablation results isolating the graph or inference components, or error analysis on cases where RAG reports conflict. This prevents verification that the proposed defense mechanism, rather than the underlying LLM or retrieval, drives the reported gains.
minor comments (2)
- [§3.1] Notation for the claim-centered graph (nodes, edges, sub-claim dependencies) is introduced without a formal definition or diagram legend, making it difficult to follow how dependency relations are encoded.
- The prompt templates used for RAG evidence retrieval and final explanation-graph generation are not provided in the appendix or main text, hindering reproducibility.
Simulated Author's Rebuttal
We are grateful to the referee for the insightful comments that will help enhance the clarity and completeness of our manuscript. We address each major comment below and commit to making the necessary revisions.
read point-by-point responses
-
Referee: [§3] §3 (Method), inference module description: the central claim that the framework produces reliable veracity judgments from unverified RAG reports rests on the defense-like inference module, yet no equations, attention mechanism, aggregation rule, or pseudocode are supplied for how the module weights, filters, or detects inconsistencies among competing explanations. Without an explicit reliability signal or down-weighting step, error propagation from any single misleading report cannot be ruled out.
Authors: We thank the referee for highlighting the need for a more formal description of the inference module. While Section 3 describes the defense-like inference as performing graph-based propagation to assess veracity by considering dependencies and competing explanations, we agree that explicit mathematical formulations are missing. In the revised version, we will add equations detailing the aggregation rule, including a consistency-based weighting mechanism that down-weights inconsistent explanations, along with pseudocode for the module. This will better illustrate how the framework mitigates error propagation from unverified reports. revision: yes
-
Referee: [Experimental section] Experimental section (tables/figures reporting results): the SOTA claim is asserted but the manuscript provides no quantitative metrics (accuracy, F1, explanation quality scores), baseline comparisons, ablation results isolating the graph or inference components, or error analysis on cases where RAG reports conflict. This prevents verification that the proposed defense mechanism, rather than the underlying LLM or retrieval, drives the reported gains.
Authors: We appreciate the referee's concern regarding the experimental validation. The current manuscript includes experimental results demonstrating SOTA performance, but we acknowledge that the presentation could be improved with more comprehensive details. We will revise the experimental section to include explicit quantitative metrics such as accuracy and F1 scores, detailed baseline comparisons, ablation studies isolating the contributions of the graph structure and inference module, and an error analysis on cases involving conflicting RAG reports. This will provide stronger evidence that the defense mechanism drives the improvements. revision: yes
Circularity Check
No significant circularity; framework composes standard components
full rationale
The paper describes a G-Defense framework that decomposes claims into sub-claims for graph construction, applies RAG to retrieve evidence and generate competing explanations per sub-claim, uses a graph-based inference module for veracity assessment, and prompts an LLM for final explanations. No equations, mathematical derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the abstract or described structure. The central claims rest on composing existing techniques (graph modeling, RAG, LLM prompting) rather than reducing to self-referential inputs or prior author results by construction. Experimental SOTA claims are presented as empirical outcomes without internal circular reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Tariq Alhindi, Savvas Petridis, and Smaranda Muresan. 2018. Where is your evidence: Improving fact-checking by justification modeling. In Proceedings of the first workshop on fact extraction and verification (FEVER). 85–90
2018
-
[2]
Jennifer Allen, Antonio A Arechar, Gordon Pennycook, and David G Rand. 2021. Scaling up fact-checking using the wisdom of crowds. Science advances 7, 36 (2021), eabf4393. , Vol. 1, No. 1, Article . Publication date: April 2026. 28 B.Wang and J.Ma et al
2021
-
[3]
Jacopo Amidei, Paul Piwek, and Alistair Willis. 2018. Rethinking the agreement in human evaluation tasks. In Proceedings of the 27th International Conference on Computational Linguistics. 3318–3329
2018
-
[4]
Pepa Atanasova, Jakob Grue Simonsen, Christina Lioma, and Isabelle Augenstein. 2020. Generating Fact Checking Explanations. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, ACL 2020, Online, July 5-10, 2020, Dan Jurafsky, Joyce Chai, Natalie Schluter, and Joel R. Tetreault (Eds.). Association for Computational Li...
-
[5]
Yejin Bang, Samuel Cahyawijaya, Nayeon Lee, Wenliang Dai, Dan Su, Bryan Wilie, Holy Lovenia, Ziwei Ji, Tiezheng Yu, Willy Chung, Quyet V. Do, Yan Xu, and Pascale Fung. 2023. A Multitask, Multilingual, Multimodal Evaluation of ChatGPT on Reasoning, Hallucination, and Interactivity. InProceedings of the 13th International Joint Conference on Natural Languag...
-
[6]
On the Opportunities and Risks of Foundation Models
Rishi Bommasani, Drew A. Hudson, Ehsan Adeli, Russ B. Altman, Simran Arora, Sydney von Arx, Michael S. Bernstein, Jeannette Bohg, Antoine Bosselut, Emma Brunskill, Erik Brynjolfsson, Shyamal Buch, Dallas Card, Rodrigo Castellon, Niladri S. Chatterji, Annie S. Chen, Kathleen Creel, Jared Quincy Davis, Dorottya Demszky, Chris Donahue, Moussa Doumbouya, Esin...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[7]
Carlos Castillo, Marcelo Mendoza, and Barbara Poblete. 2011. Information credibility on twitter. In Proceedings of the 20th international conference on World wide web. 675–684
2011
-
[8]
Yupeng Chang, Xu Wang, Jindong Wang, Yuan Wu, Kaijie Zhu, Hao Chen, Linyi Yang, Xiaoyuan Yi, Cunxiang Wang, Yidong Wang, Wei Ye, Yue Zhang, Yi Chang, Philip S. Yu, Qiang Yang, and Xing Xie. 2023. A Survey on Evaluation of Large Language Models. CoRR abs/2307.03109 (2023). https://doi.org/10.48550/arXiv.2307.03109 arXiv:2307.03109
-
[9]
Harrison Chase. 2022. LangChain. (2022). https://github.com/langchain-ai/langchain
2022
-
[10]
Jifan Chen, Grace Kim, Aniruddh Sriram, Greg Durrett, and Eunsol Choi. 2024. Complex Claim Verification with Evi- dence Retrieved in the Wild. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), NAACL 2024, Mexico City, Mexico, June 16-21,...
-
[11]
Jifan Chen, Aniruddh Sriram, Eunsol Choi, and Greg Durrett. 2022. Generating Literal and Implied Subquestions to Fact-check Complex Claims. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, EMNLP 2022, Abu Dhabi, United Arab Emirates, December 7-11, 2022, Yoav Goldberg, Zornitsa Kozareva, and Yue Zhang (Eds.). Asso...
-
[12]
Yi Chen, Rui Wang, Haiyun Jiang, Shuming Shi, and Ruifeng Xu. 2023. Exploring the Use of Large Language Models for Reference-Free Text Quality Evaluation: A Preliminary Empirical Study. CoRR abs/2304.00723 (2023). https://doi.org/10.48550/arXiv.2304.00723 arXiv:2304.00723
-
[13]
Zhikai Chen, Haitao Mao, Hang Li, Wei Jin, Hongzhi Wen, Xiaochi Wei, Shuaiqiang Wang, Dawei Yin, Wenqi Fan, Hui Liu, and Jiliang Tang. 2023. Exploring the Potential of Large Language Models (LLMs)in Learning on Graphs. SIGKDD Explor. 25, 2 (2023), 42–61. https://doi.org/10.1145/3655103.3655110
-
[15]
David Cheng-Han Chiang and Hung-yi Lee. 2023. Can Large Language Models Be an Alternative to Human Evalua- tions?. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2023, Toronto, Canada, July 9-14, 2023, Anna Rogers, Jordan L. Boyd-Graber, and Naoaki Okazaki (Eds.). Association for Com...
-
[16]
Zhao, Yanping Huang, Andrew M
Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Yunxuan Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Alex Castro-Ros, Marie Pellat, Kevin Robinson, Dasha Valter, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Y. Zhao, Yanpin...
2024
-
[17]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. 2024. The llama 3 herd of models. arXiv preprint arXiv:2407.21783 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Wenqi Fan, Yujuan Ding, Liangbo Ning, Shijie Wang, Hengyun Li, Dawei Yin, Tat-Seng Chua, and Qing Li. 2024. A survey on rag meeting llms: Towards retrieval-augmented large language models. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 6491–6501
2024
-
[19]
Bahare Fatemi, Jonathan Halcrow, and Bryan Perozzi. 2024. Talk like a Graph: Encoding Graphs for Large Language Models. In The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11,
2024
-
[20]
https://openreview.net/forum?id=IuXR1CCrSi
OpenReview.net. https://openreview.net/forum?id=IuXR1CCrSi
-
[21]
Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, Qianyu Guo, Meng Wang, and Haofen Wang. 2023. Retrieval-Augmented Generation for Large Language Models: A Survey.CoRR abs/2312.10997 (2023). https://doi.org/10.48550/ARXIV.2312.10997 arXiv:2312.10997
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2312.10997 2023
-
[22]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. 2025. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat, and Ming-Wei Chang. 2020. Retrieval Augmented Language Model Pre-Training. InProceedings of the 37th International Conference on Machine Learning, ICML 2020, 13-18 July 2020, Virtual Event (Proceedings of Machine Learning Research, Vol. 119). PMLR, 3929–3938. http://proceedings.mlr. press/v119/guu20a.html
2020
-
[24]
Beizhe Hu, Qiang Sheng, Juan Cao, Yuhui Shi, Yang Li, Danding Wang, and Peng Qi. 2024. Bad Actor, Good Advi- sor: Exploring the Role of Large Language Models in Fake News Detection. In Thirty-Eighth AAAI Conference on Artificial Intelligence, AAAI 2024, Thirty-Sixth Conference on Innovative Applications of Artificial Intelligence, IAAI 2024, Fourteenth Sy...
-
[25]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
-
[26]
In The Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022
LoRA: Low-Rank Adaptation of Large Language Models. In The Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022. OpenReview.net. https://openreview.net/forum?id= nZeVKeeFYf9
2022
- [27]
-
[28]
Fan Huang, Haewoon Kwak, and Jisun An. 2023. Is ChatGPT better than Human Annotators? Potential and Limitations of ChatGPT in Explaining Implicit Hate Speech. InCompanion Proceedings of the ACM Web Conference 2023, WWW 2023, Austin, TX, USA, 30 April 2023 - 4 May 2023, Ying Ding, Jie Tang, Juan F. Sequeda, Lora Aroyo, Carlos Castillo, and Geert-Jan Houben...
-
[29]
Jin Huang, Xingjian Zhang, Qiaozhu Mei, and Jiaqi Ma. 2023. Can LLMs Effectively Leverage Graph Structural Infor- mation: When and Why. CoRR abs/2309.16595 (2023). https://doi.org/10.48550/ARXIV.2309.16595 arXiv:2309.16595
-
[30]
Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qianglong Chen, Weihua Peng, Xiaocheng Feng, Bing Qin, et al. 2025. A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions. ACM Transactions on Information Systems 43, 2 (2025), 1–55
2025
-
[31]
Yizheng Huang and Jimmy Huang. 2024. A Survey on Retrieval-Augmented Text Generation for Large Language Models. CoRR abs/2404.10981 (2024). https://doi.org/10.48550/ARXIV.2404.10981 arXiv:2404.10981
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2404.10981 2024
-
[32]
Gautier Izacard, Patrick S. H. Lewis, Maria Lomeli, Lucas Hosseini, Fabio Petroni, Timo Schick, Jane Dwivedi-Yu, Armand Joulin, Sebastian Riedel, and Edouard Grave. 2023. Atlas: Few-shot Learning with Retrieval Augmented Language Models. J. Mach. Learn. Res. 24 (2023), 251:1–251:43. https://jmlr.org/papers/v24/23-0037.html
2023
-
[33]
Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Yejin Bang, Andrea Madotto, and Pascale Fung. 2023. Survey of Hallucination in Natural Language Generation. ACM Comput. Surv. 55, 12 (2023), 248:1–248:38. https://doi.org/10.1145/3571730
-
[34]
Bowen Jin, Gang Liu, Chi Han, Meng Jiang, Heng Ji, and Jiawei Han. 2024. Large Language Models on Graphs: A Comprehensive Survey. IEEE Trans. Knowl. Data Eng. 36, 12 (2024), 8622–8642. https://doi.org/10.1109/TKDE.2024. 3469578
-
[35]
Bowen Jin, Gang Liu, Chi Han, Meng Jiang, Heng Ji, and Jiawei Han. 2024. Large language models on graphs: A comprehensive survey. IEEE Transactions on Knowledge and Data Engineering (2024)
2024
-
[36]
Zhiwei Jin, Juan Cao, Yongdong Zhang, and Jiebo Luo. 2016. News verification by exploiting conflicting social viewpoints in microblogs. In Proceedings of the AAAI conference on artificial intelligence, Vol. 30
2016
-
[37]
Neema Kotonya and Francesca Toni. 2020. Explainable Automated Fact-Checking: A Survey. InProceedings of the 28th International Conference on Computational Linguistics, COLING 2020, Barcelona, Spain (Online), December 8-13, , Vol. 1, No. 1, Article . Publication date: April 2026. 30 B.Wang and J.Ma et al. 2020, Donia Scott, Núria Bel, and Chengqing Zong (E...
-
[38]
Neema Kotonya and Francesca Toni. 2020. Explainable Automated Fact-Checking for Public Health Claims. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, EMNLP 2020, Online, November 16-20, 2020, Bonnie Webber, Trevor Cohn, Yulan He, and Yang Liu (Eds.). Association for Computational Linguistics, 7740–7754. https://d...
-
[39]
Patrick S. H. Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Hein- rich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. 2020. Retrieval- Augmented Generation for Knowledge-Intensive NLP Tasks. In Advances in Neural Information Processing Systems 33: Annual Conference on Neural I...
2020
-
[40]
Jun Li, Yi Bin, Yunshan Ma, Yang Yang, Zi Huang, and Tat-Seng Chua. 2024. Filter-based Stance Network for Rumor Verification. ACM Trans. Inf. Syst. 42, 4 (2024), 108:1–108:28. https://doi.org/10.1145/3649462
-
[41]
Hao Liao, Jiahao Peng, Zhanyi Huang, Wei Zhang, Guanghua Li, Kai Shu, and Xing Xie. 2023. MUSER: A MUlti-Step Evidence Retrieval Enhancement Framework for Fake News Detection. In Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, KDD 2023, Long Beach, CA, USA, August 6-10, 2023, Ambuj K. Singh, Yizhou Sun, Leman Akoglu, ...
-
[42]
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. RoBERTa: A Robustly Optimized BERT Pretraining Approach. CoRR abs/1907.11692 (2019). arXiv:1907.11692 http://arxiv.org/abs/1907.11692
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[43]
Yang Liu and Yi-fang Brook Wu. 2020. FNED: A Deep Network for Fake News Early Detection on Social Media. ACM Trans. Inf. Syst. 38, 3 (2020), 25:1–25:33. https://doi.org/10.1145/3386253
-
[44]
Yu Lu, Junwei Bao, Yan Song, Zichen Ma, Shuguang Cui, Youzheng Wu, and Xiaodong He. 2021. RevCore: Review-Augmented Conversational Recommendation. In Findings of the Association for Computational Linguistics: ACL/IJCNLP 2021, Online Event, August 1-6, 2021 (Findings of ACL, Vol. ACL/IJCNLP 2021), Chengqing Zong, Fei Xia, Wenjie Li, and Roberto Navigli (Ed...
2021
-
[45]
Yi-Ju Lu and Cheng-Te Li. 2020. GCAN: Graph-aware Co-Attention Networks for Explainable Fake News Detection on Social Media. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, ACL 2020, Online, July 5-10, 2020, Dan Jurafsky, Joyce Chai, Natalie Schluter, and Joel R. Tetreault (Eds.). Association for Computational L...
-
[46]
Jing Ma, Wei Gao, Shafiq R. Joty, and Kam-Fai Wong. 2019. Sentence-Level Evidence Embedding for Claim Verification with Hierarchical Attention Networks. In Proceedings of the 57th Conference of the Association for Computational Linguistics, ACL 2019, Florence, Italy,July 28- August 2, 2019, Volume1: Long Papers, Anna Korhonen, David R. Traum, and Lluís Mà...
-
[47]
Jing Ma, Wei Gao, and Kam-Fai Wong. 2018. Detect Rumor and Stance Jointly by Neural Multi-task Learning. In Companion of the The Web Conference 2018 on The Web Conference 2018, WWW 2018, Lyon , France, April 23-27, 2018, Pierre-Antoine Champin, Fabien Gandon, Mounia Lalmas, and Panagiotis G. Ipeirotis (Eds.). ACM, 585–593. https://doi.org/10.1145/3184558.3188729
-
[48]
Yuren Mao, Xuemei Dong, Wenyi Xu, Yunjun Gao, Bin Wei, and Ying Zhang. 2025. Fit-rag: Black-box rag with factual information and token reduction. ACM Transactions on Information Systems 43, 2 (2025), 1–27. https: //doi.org/10.1145/367695
-
[49]
Qiong Nan, Qiang Sheng, Juan Cao, Beizhe Hu, Danding Wang, and Jintao Li. 2024. Let Silence Speak: Enhancing Fake News Detection with Generated Comments from Large Language Models. In Proceedings of the 33rd ACM International Conference on Information and Knowledge Management, CIKM 2024, Boise, ID, USA, October 21-25, 2024, Edoardo Serra and Francesca Spe...
-
[50]
Yixin Nie, Haonan Chen, and Mohit Bansal. 2019. Combining Fact Extraction and Verification with Neural Semantic Matching Networks. In The Thirty-Third AAAI Conference on Artificial Intelligence, AAAI 2019, The Thirty-First Innovative Applications of Artificial Intelligence Conference, IAAI 2019, The Ninth AAAI Symposium on Educational Advances in Artifici...
-
[51]
OpenAI. 2023. GPT-4 Technical Report. CoRR abs/2303.08774 (2023). https://doi.org/10.48550/arXiv.2303.08774 arXiv:2303.08774
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2303.08774 2023
-
[52]
Wainwright, Pamela Mishkin, Chong Zhang, Sand- hini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, , Vol
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sand- hini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, , Vol. 1, No. 1, Article . Publication date: April 2026. A Graph-Enhanced Defense Framework for Explainable Fake News Detection with LLM ...
2026
-
[53]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sand- hini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul F. Christiano, Jan Leike, and Ryan Lowe. 2022. Training language mod- els to follow instructions with...
2022
-
[54]
Kashyap Popat, Subhabrata Mukherjee, Andrew Yates, and Gerhard Weikum. 2018. DeClarE: Debunking Fake News and False Claims using Evidence-Aware Deep Learning. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, October 31 - November 4, 2018, Ellen Riloff, David Chiang, Julia Hockenmaier, and Jun’ic...
-
[55]
Ori Ram, Yoav Levine, Itay Dalmedigos, Dor Muhlgay, Amnon Shashua, Kevin Leyton-Brown, and Yoav Shoham
-
[56]
In-Context Retrieval-Augmented Language Models. Trans. Assoc. Comput. Linguistics 11 (2023), 1316–1331. https://doi.org/10.1162/TACL_A_00605
-
[57]
Nils Reimers and Iryna Gurevych. 2019. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, EMNLP-IJCNLP 2019, Hong Kong, China, November 3-7, 2019, Kentaro Inui, Jing Jiang, Vincen...
-
[58]
Parker Riley, Daniel Deutsch, George Foster, Viresh Ratnakar, Ali Dabirmoghaddam, and Markus Freitag. 2024. Finding replicable human evaluations via stable ranking probability. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 4908–4919
2024
-
[59]
Victor Sanh, Lysandre Debut, Julien Chaumond, and Thomas Wolf. 2019. DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter. CoRR abs/1910.01108 (2019). arXiv:1910.01108 http://arxiv.org/abs/1910.01108
work page internal anchor Pith review arXiv 2019
-
[60]
Kai Shu, Limeng Cui, Suhang Wang, Dongwon Lee, and Huan Liu. 2019. dEFEND: Explainable Fake News Detection. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, KDD 2019, Anchorage, AK, USA, August 4-8, 2019, Ankur Teredesai, Vipin Kumar, Ying Li, Rómer Rosales, Evimaria Terzi, and George Karypis (Eds.). ACM...
-
[61]
Miloš Stanojević and Khalil Sima’an. 2014. Beer: Better evaluation as ranking. InProceedings of the Ninth Workshop on Statistical Machine Translation. 414–419
2014
-
[62]
Jinyan Su, Terry Yue Zhuo, Jonibek Mansurov, Di Wang, and Preslav Nakov. 2023. Fake News Detectors are Biased against Texts Generated by Large Language Models. CoRR abs/2309.08674 (2023). https://doi.org/10.48550/arXiv.2309. 08674 arXiv:2309.08674
-
[63]
Jiabin Tang, Yuhao Yang, Wei Wei, Lei Shi, Lixin Su, Suqi Cheng, Dawei Yin, and Chao Huang. 2024. Graphgpt: Graph instruction tuning for large language models. In Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval. 491–500
2024
-
[64]
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurélien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample. 2023. LLaMA: Open and Efficient Foundation Language Models. CoRR abs/2302.13971 (2023). https: //doi.org/10.48550/arXiv.2302....
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2302.13971 2023
-
[65]
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. 2023. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[66]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. Advances in neural information processing systems 30 (2017)
2017
-
[67]
Herun Wan, Shangbin Feng, Zhaoxuan Tan, Heng Wang, Yulia Tsvetkov, and Minnan Luo. 2024. DELL: Generating Reactions and Explanations for LLM-Based Misinformation Detection. InFindings of the Association for Computational Linguistics, ACL 2024, Bangkok, Thailand and virtual meeting, August 11-16, 2024, Lun-Wei Ku, Andre Martins, and Vivek Srikumar (Eds.). ...
-
[68]
Bo Wang, Jing Ma, Hongzhan Lin, Zhiwei Yang, Ruichao Yang, Yuan Tian, and Yi Chang. 2024. Explainable Fake News Detection with Large Language Model via Defense Among Competing Wisdom. In Proceedings of the ACM on Web Conference 2024, WWW 2024, Singapore, May 13-17, 2024, Tat-Seng Chua, Chong-Wah Ngo, Ravi Kumar, Hady W. Lauw, and Roy Ka-Wei Lee (Eds.). AC...
-
[69]
Rabiul Awal, Kenny Tsu Wei Choo, and Roy Ka-Wei Lee
Han Wang, Ming Shan Hee, Md. Rabiul Awal, Kenny Tsu Wei Choo, and Roy Ka-Wei Lee. 2023. Evaluating GPT-3 Generated Explanations for Hateful Content Moderation. In Proceedings of the Thirty-Second International Joint Conference on Artificial Intelligence, IJCAI 2023, 19th-25th August 2023, Macao, SAR, China. ijcai.org, 6255–6263. https://doi.org/10.24963/i...
-
[70]
Haoran Wang and Kai Shu. 2023. Explainable Claim Verification via Knowledge-Grounded Reasoning with Large Language Models. In Findings of the Association for Computational Linguistics: EMNLP 2023, Singapore, December 6-10, 2023, Houda Bouamor, Juan Pino, and Kalika Bali (Eds.). Association for Computational Linguistics, 6288–6304. https://doi.org/10.18653...
-
[71]
Jinguang Wang, Shengsheng Qian, Jun Hu, Wenxiang Dong, Xudong Huang, and Richang Hong. 2025. End-to-End Explainable Fake News Detection Via Evidence-Claim Variational Causal Inference.ACM Transactions on Information Systems (2025). https://doi.org/10.1145/3728462
- [72]
-
[73]
Junda Wu, Cheng-Chun Chang, Tong Yu, Zhankui He, Jianing Wang, Yupeng Hou, and Julian J. McAuley. 2024. CoRAL: Collaborative Retrieval-Augmented Large Language Models Improve Long-tail Recommendation. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, KDD 2024, Barcelona, Spain, August 25-29, 2024, Ricardo Baeza-Yates ...
-
[74]
Lianwei Wu, Yuan Rao, Ling Sun, and Wangbo He. 2021. Evidence Inference Networks for Interpretable Claim Verifica- tion. In Thirty-Fifth AAAI Conference on Artificial Intelligence, AAAI 2021, Thirty-Third Conference on Innovative Applications of Artificial Intelligence, IAAI 2021, The Eleventh Symposium on Educational Advances in Artificial Intelligence, ...
-
[75]
Pentyala, Sina Mohseni, Mengnan Du, Hao Yuan, Rhema Linder, Eric D
Fan Yang, Shiva K. Pentyala, Sina Mohseni, Mengnan Du, Hao Yuan, Rhema Linder, Eric D. Ragan, Shuiwang Ji, and Xia (Ben) Hu. 2019. XFake: Explainable Fake News Detector with Visualizations. In The World Wide Web Conference, WWW 2019, San Francisco, CA, USA, May 13-17, 2019, Ling Liu, Ryen W. White, Amin Mantrach, Fabrizio Silvestri, Julian J. McAuley, Ric...
-
[76]
Ruichao Yang, Jing Ma, Hongzhan Lin, and Wei Gao. 2022. A Weakly Supervised Propagation Model for Rumor Verification and Stance Detection with Multiple Instance Learning. In SIGIR ’22:The 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, Madrid, Spain, July 11 - 15, 2022, Enrique Amigó, Pablo Castells, Julio Gon...
-
[77]
Zhiwei Yang, Jing Ma, Hechang Chen, Hongzhan Lin, Ziyang Luo, and Yi Chang. 2022. A Coarse-to-fine Cascaded Evidence-Distillation Neural Network for Explainable Fake News Detection. In Proceedings of the 29th International Conference on Computational Linguistics, COLING 2022, Gyeongju, Republic of Korea, October 12-17, 2022, Nicoletta Calzolari, Chu-Ren H...
2022
-
[78]
Ruosong Ye, Caiqi Zhang, Runhui Wang, Shuyuan Xu, and Yongfeng Zhang. 2024. Language is All a Graph Needs. In Findings of the Association for Computational Linguistics: EACL 2024, St. Julian’s,Malta, March 17-22, 2024, Yvette Graham and Matthew Purver (Eds.). Association for Computational Linguistics, 1955–1973. https://aclanthology.org/ 2024.findings-eacl.132
2024
-
[79]
Zhenrui Yue, Huimin Zeng, Yimeng Lu, Lanyu Shang, Yang Zhang, and Dong Wang. 2024. Evidence-Driven Retrieval Augmented Response Generation for Online Misinformation. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume1: Long Papers), NAACL 2024, Mexico Ci...
-
[80]
Zhenrui Yue, Huimin Zeng, Lanyu Shang, Yifan Liu, Yang Zhang, and Dong Wang. 2024. Retrieval Augmented Fact Verification by Synthesizing Contrastive Arguments. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2024, Bangkok, Thailand, August 11-16, 2024, Lun-Wei Ku, Andre Martins, and V...
-
[81]
Shenglai Zeng, Jiankun Zhang, Bingheng Li, Yuping Lin, Tianqi Zheng, Dante Everaert, Hanqing Lu, Hui Liu, Yue Xing, Monica Xiao Cheng, and Jiliang Tang. 2024. Towards Knowledge Checking in Retrieval-augmented Generation: A Representation Perspective. CoRR abs/2411.14572 (2024). https://doi.org/10.48550/ARXIV.2411.14572 arXiv:2411.14572 , Vol. 1, No. 1, Ar...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.