Recognition: 2 theorem links
· Lean TheoremReason in Chains, Learn in Trees: Self-Rectification and Grafting for Multi-turn Agent Policy Optimization
Pith reviewed 2026-05-10 18:39 UTC · model grok-4.3
The pith
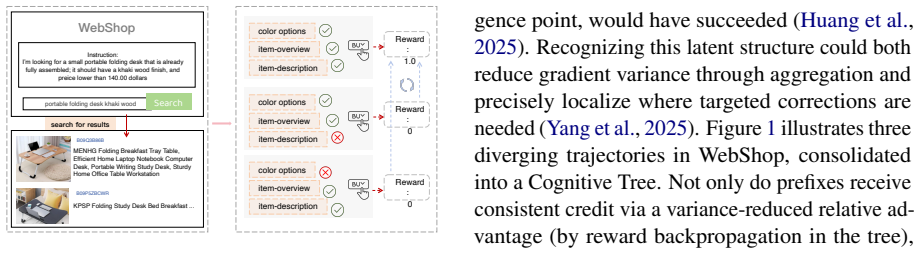
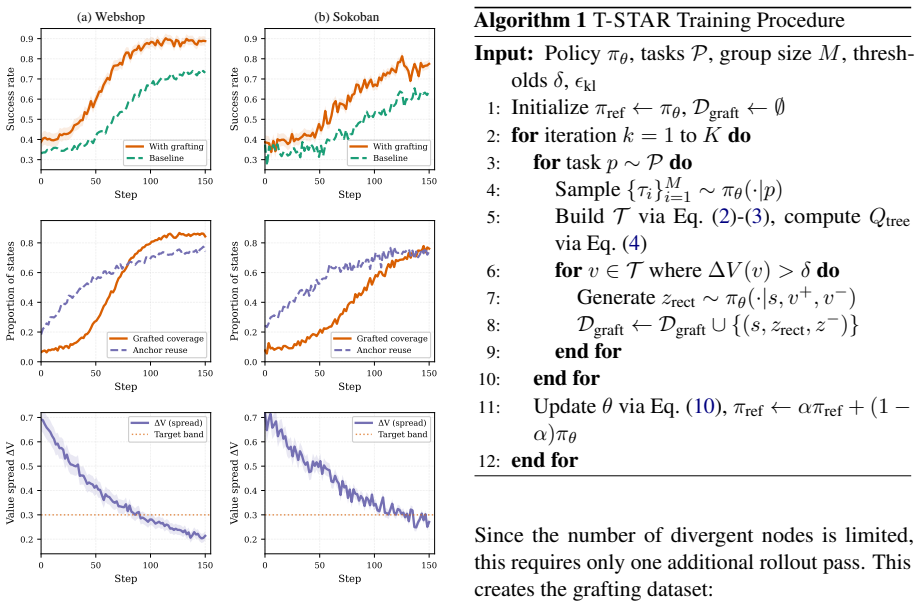
T-STAR consolidates multiple agent trajectories into one Cognitive Tree to back-propagate rewards to individual steps and graft corrective reasoning at divergence points.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By identifying and merging functionally similar steps across trajectories into a unified Cognitive Tree, T-STAR recovers latent correlations in reward structure. An Introspective Valuation mechanism then back-propagates full-trajectory rewards through the tree to produce step-level relative advantages. In-Context Thought Grafting uses the same tree to synthesize corrective reasoning by contrasting successful and failed branches at divergence points. Surgical Policy Optimization applies a Bradley-Terry loss that concentrates gradient updates on those critical steps.
What carries the argument
The Cognitive Tree, created by merging functionally similar steps from independent trajectories, which both structures reward back-propagation and supplies divergence points for grafting.
If this is right
- Step-level advantages become variance-reduced rather than uniform across every token in a trajectory.
- Corrective reasoning segments can be generated in-context at divergence points without new model training.
- Policy gradients concentrate on critical steps through a Bradley-Terry surgical loss.
- Gains are largest on tasks whose solutions require extended reasoning chains.
Where Pith is reading between the lines
- The tree could be maintained online so that new trajectories continuously refine existing nodes and reduce the total number of samples needed for policy improvement.
- Grafting successful prefixes onto failed branches offers a route to generate targeted synthetic data that highlights exactly where reasoning diverges.
- Nodes in the tree could carry uncertainty estimates that modulate how much weight is given to grafted corrections.
Load-bearing premise
Merging steps from different trajectories must accurately identify functionally equivalent reasoning actions so that shared reward signals can be correctly routed and grafted.
What would settle it
If step-merging accuracy is low on a long-horizon benchmark, T-STAR produces no gain or worse performance than independent-trajectory baselines such as GRPO.
Figures




read the original abstract
Reinforcement learning for Large Language Model agents is often hindered by sparse rewards in multi-step reasoning tasks. Existing approaches like Group Relative Policy Optimization treat sampled trajectories as independent chains, assigning uniform credit to all steps in each chain and ignoring the existence of critical steps that may disproportionally impact reasoning outcome. In this paper, we propose T-STAR(Tree-structured Self-Taught Agent Rectification), a framework that recovers the latent correlated reward structure across seemingly independent trajectories. Specifically, we consolidate trajectories into a unified Cognitive Tree by identifying and merging functionally similar steps/nodes. It enables an Introspective Valuation mechanism that back-propagates trajectory-level rewards through the tree to obtain a new notion of variance-reduced relative advantage at step-level. Using the Cognitive Tree, we also develop In-Context Thought Grafting to synthesize corrective reasoning by contrasting successful and failed branches at critical divergence points/steps. Our proposed Surgical Policy Optimization then capitalizes on the rich policy gradient information concentrated at these critical points/steps through a Bradley-Terry type of surgical loss. Extensive experiments across embodied, interactive, reasoning, and planning benchmarks demonstrate that T-STAR achieves consistent improvements over strong baselines, with gains most pronounced on tasks requiring extended reasoning chains.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes T-STAR (Tree-structured Self-Taught Agent Rectification), a framework for multi-turn LLM agent policy optimization. It consolidates independent trajectories into a unified Cognitive Tree by identifying and merging functionally similar steps/nodes. This structure supports Introspective Valuation to back-propagate trajectory-level rewards for variance-reduced step-level relative advantages, In-Context Thought Grafting to synthesize corrective reasoning by contrasting branches at divergence points, and Surgical Policy Optimization via a Bradley-Terry surgical loss focused on critical steps. Experiments across embodied, interactive, reasoning, and planning benchmarks report consistent improvements over strong baselines, with gains most pronounced on tasks requiring extended reasoning chains.
Significance. If the Cognitive Tree construction reliably recovers latent reward correlations without bias, the framework could meaningfully advance credit assignment and policy optimization for LLM agents in sparse-reward, long-horizon settings. The grafting and surgical loss mechanisms provide a structured way to leverage contrastive examples and concentrate gradients on high-impact steps, potentially improving upon methods like GRPO.
major comments (2)
- [Abstract] Abstract (and the Cognitive Tree construction description): the procedure for identifying and merging functionally similar steps/nodes lacks any concrete similarity metric, embedding method, merging algorithm, or validation against selection bias. This is load-bearing for the central claim, as inaccurate merges would invalidate the variance-reduced advantages from Introspective Valuation and produce flawed grafting examples, directly undermining the reported gains on extended reasoning chains.
- No ablation studies or sensitivity analysis on the merging heuristic are described, leaving the performance improvements dependent on an unverified implementation choice rather than the proposed tree structure.
minor comments (1)
- [Abstract] The abstract refers to 'extensive experiments' and 'strong baselines' without referencing specific tables, figures, or effect sizes; adding these would improve clarity.
Simulated Author's Rebuttal
Thank you for the constructive review of our T-STAR paper. The comments correctly identify areas where greater explicitness on the Cognitive Tree construction and supporting analyses would strengthen the manuscript. We address each major comment below and will revise accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract (and the Cognitive Tree construction description): the procedure for identifying and merging functionally similar steps/nodes lacks any concrete similarity metric, embedding method, merging algorithm, or validation against selection bias. This is load-bearing for the central claim, as inaccurate merges would invalidate the variance-reduced advantages from Introspective Valuation and produce flawed grafting examples, directly undermining the reported gains on extended reasoning chains.
Authors: We agree that the abstract is high-level and that the main-text description of Cognitive Tree construction would benefit from more concrete implementation details to support the central claims. In the revision we will expand both the abstract and Section 3 to specify the similarity metric, embedding approach, and merging algorithm used, along with an empirical validation subsection that quantifies selection bias (e.g., via reward-correlation consistency before and after merges). This will directly address the concern that inaccurate merges could undermine the variance-reduced advantages and grafting examples. revision: yes
-
Referee: No ablation studies or sensitivity analysis on the merging heuristic are described, leaving the performance improvements dependent on an unverified implementation choice rather than the proposed tree structure.
Authors: We acknowledge the lack of ablations on the merging heuristic. The revised manuscript will include sensitivity analyses that vary the similarity threshold and compare alternative merging strategies, with results reported in a new table or figure. These experiments will demonstrate robustness and show that the reported gains arise primarily from the tree-structured credit assignment and grafting mechanisms rather than from any single heuristic choice. revision: yes
Circularity Check
No significant circularity; derivation uses standard RL primitives on a constructed tree
full rationale
The paper's chain begins with sampling independent trajectories, consolidates them into a Cognitive Tree via functional similarity merging, back-propagates rewards for step-level advantages, grafts corrective thoughts at divergence points, and optimizes via a Bradley-Terry surgical loss. These operations invoke established RL mechanisms (relative advantage, preference losses) without equations or definitions that reduce the output to the input by construction. No self-citations, fitted parameters renamed as predictions, or ansatzes smuggled via prior work are exhibited in the provided text. The framework's claimed gains rest on the empirical application of the tree structure rather than tautological equivalence.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Trajectory-level rewards can be meaningfully back-propagated through merged nodes in a Cognitive Tree without introducing bias from imperfect similarity identification.
invented entities (4)
-
Cognitive Tree
no independent evidence
-
Introspective Valuation
no independent evidence
-
In-Context Thought Grafting
no independent evidence
-
Surgical Policy Optimization
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
consolidate trajectories into a unified Cognitive Tree by identifying and merging functionally similar steps/nodes... Qtree(v) = γ Σ w(v→v′)Qtree(v′)
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
no mention of recognition cost, φ, 8-tick period or distinction-forced constants
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
NonZero: Interaction-Guided Exploration for Multi-Agent Monte Carlo Tree Search
NonZero introduces an interaction score and bandit-formalized proposal rule for local agent deviations in multi-agent MCTS, delivering a sublinear local-regret guarantee and improved sample efficiency on game benchmar...
Reference graph
Works this paper leans on
-
[1]
Group-in-Group Policy Optimization for LLM Agent Training
Group-in-group policy optimization for llm agent training.arXiv preprint arXiv:2505.10978. Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, and 1 others. 2025a. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948. Weiyang Gu...
work page internal anchor Pith review arXiv 2026
-
[2]
arXiv preprint arXiv:2509.09284 , year=
Tree-opo: Off-policy monte carlo tree- guided advantage optimization for multistep reason- ing.arXiv preprint arXiv:2509.09284. Hongru Ji, Yuyin Fan, Meng Zhao, Xianghua Li, Lian- wei Wu, and Chao Gao. 2026. Stride-ed: A strategy- grounded stepwise reasoning framework for empa- thetic dialogue systems.Preprint, arXiv:2604.07100. Komal Kumar, Tajamul Ashra...
-
[3]
Inclusion-of-Thoughts: Mitigating Preference Instability via Purifying the Decision Space
Let’s verify step by step. InThe Twelfth Inter- national Conference on Learning Representations. 9 Mohammad Reza Ghasemi Madani, Soyeon Caren Han, Shuo Yang, and Jey Han Lau. 2026. Inclusion-of- thoughts: Mitigating preference instability via purify- ing the decision space.Preprint, arXiv:2604.04944. Chanwoo Park, Seungju Han, Xingzhi Guo, Asuman E Ozdagl...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[4]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Tree of thoughts: Deliberate problem solving with large language models.Advances in neural information processing systems, 36:11809–11822. Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. 2022. React: Synergizing reasoning and acting in language models. InThe eleventh international conference on learning repres...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[5]
assembly required
Variance Analysis via Conditional Indepen- dence Let Xi be the random variable representing the advantage ˆAGRPO(τi) for a trajectory passing through v. We analyze the variance of the estimator ˆAtree(v) conditioned on the prefix nodev. Since the policyπ θ generates rollouts stochastically, for any distinct pair i, j∈ T(v) with i̸=j , the comple- tions ar...
1946
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.